





I have trained Flux Dev on my SDXL dataset and merged loras, correcting anatomy censorship and excessive bokeh/blurred backgrounds.
V12 - Merge with SRPO model and some loras, a bit cleaner looking than previous models, might want to use some grain loras if you want that amateur look.
I think not as good at NSFW so might want to use my lora for that: https://civarchive.com/models/652791/jibs-flux-nipple-fix
Jib Mix Flux v8-Flash! SVDQuant-4bit
Update 06/04/2025 - NOW WITH CONTROLNET AND NATIVE LORA SUPPORT!
This new SVDQuant format currently requires ComfyUI and an Nvidia 2000 series+ GPU.
I recommend;
Guidance scale = 2.5-3.5
Sampler = dpmpp_2m.
Scheduler = Sgm_uniform, Beta or Custom Stigmas.
This model is a new format that is a little tricky to first get setup but it is worth it as you can make flux images super fast (5 seconds on a 3090, 2.5 sevonds on a 4090 and 0.8 seconds on 5090! at 10 steps) ,
You need to install the nunchaku project following the instructions there.
and the nunchaku ComfyUI custom nodes to get it to work.
Download and unzip the archive from Civitai to: \comfyui.git\app\models\diffusion_models\jib-mix-svdq\
This is the Nunchaku workflow I am using: https://civarchive.com/models/617562
Thanks a lot to theunlikely for running the Quantization which takes an H100 GPU 6 hours!
Unfortunately, it seems the NSFW capabilities are reduced by the quantisation but can be bought back with my NSFW Lora you need to use the Nunchaku lora loader in the node pack and it will auto convert the lora for use the first time (and optionally can be saved).
There is currently a size limit above 2 million pixels 1024 x 2048 that causes a crash in ComfyUI, so if you get that lower your gen/upscale resolution, The Developers say a fix will be released this week.
Jib Mix Flux Version 8 AccentuEight
Much better Skin texture than Jib Mix Flux V7 but without the bad Flux Lines of Jib Mix V6.
NSFW anatomy is slightly lacking so I have uploaded a separate NSFW model that has very slightly reduced details / artstyles or loras can be used.
The V8 Pruned Model nf4 (6.33 GB) model is actually the Q4_0.gguf
The V8 Pruned Model bf16 (11.84 GB) model is actually the Q8_0.gguf
15/04/2025 - The new fp16 version of V8 provides very slightly better details and anatomical and image consistency, if you have the VRAM for it....
Jib Mix Flux Version 8 AccentuEight NSFW
Better female anatomy with a slight loss in skin details.
The V8 NSFW Pruned Model nf4 (6.33 GB) model is actually a Q4_0.gguf
Jib Mix Flux Version 7.8 Clear Text Focus
This version focuses on having more readable text generation.
The Skin texture may not be generally as realistic as Jib Mix v6 or v7.
It has less nipple flashing through clothes.
The 2000s Analog Core @0.6 weight, removes some of the plastic Fluxness of this merge without hurting the text.
Jib Mix Flux Version 7.2 Pixel Heaven
7/7.2 mainly fixes "Flux Line" caused by merging some effected lora's, this has caused some drop in photo realism but an increase in drawn/concept ability and general details.
It also tones down obsessive amounts of freckles (especially red freckles).
The V7.2 Pruned Model nf4 (6.33 GB) model is actually the Q4_0.gguf
The V7.2 Pruned Model bf16 (11.84 GB) model is actually the Q8_0.gguf
Jib Mix Flux version 7 PixelHeaven - beta
The main change is it removes "Flux lines" that plagued V6 and the original Flux Dev to some extent.
It may be overdoing freckles a lot but I wanted to see what people think of it. hence the Beta name.
I really recommend using Movie Portrait Lora on quite a high weight for a less plastic look, but I couldn't merge it into the model as in testing it was a Lora that can cause "Flux Lines"
Jib Mix Flux Version 6.1 Real Pix Fixed
6.1 mainly tries to fix small stubby hands or massively distorted hands/arms.
(If you still have problems with hands and you are using a low step count around 8 then increasing the step count usually fixes it alternatively applying a low weight (< 0.10) of the Hyper Flux lora pretty much always fixes hands, although you may find it lowers details).
V6.1 is more realistic on the CFG / more natural faces.
I think it actually does art/cartoon styles a bit better than the original v6 as well.
The V6.1 Pruned Model nf4 (6.33 GB) model is actually the Q4_0.gguf
The V6.1 Pruned Model bf16 (11.84 GB) model is actually the Q8_0.gguf
V6 still has the most detailed backgrounds in my testing.
The V6 Pruned Model nf4 (11.84 GB) model is actually Q8_0.gguf
The V6 Pruned Model bf16 (6.33 GB) model is actually a Q4_0.gguf
Jib Mix Flux Version 5 - It's Alive:
Improved photorealism. (Less likely to default to painting styles)
Fixed issues with wonky text.
More detailed backgrounds
Reconfigured NSWF slightly
fp8 V4 Canvas Galore:
better fine details and much better artistic styles, and improved NSFW capabilities.
fp8 V3.0 V3.1 - Clarity Key
I initially uploaded the wrong model file on the 21/10/2024, it was very similar but the new file since 22/10/2024 has slightly better contrast and was used for the sample images.
This version Improves detail levels and has a more cinematic feel like the original flux dev.
reduced the "Flux Chin"
Settings - I use a Flux Guidance of 2.9
Sampler = dpmpp_2m.
Scheduler = Beta or Custom Stigmas.
FP8 V2 - Electric Boogaloo: Better NSFW and skin/image quality.
Settings:
I find the best settings are a guidance and 2.5 and a CFG of 2.8 (although CFG does slow down the generation).
When using Loras these values may/will change.
Version: mx5 GGUF 7GB v1
This is a quantized version of my Flux model to run on lower-end graphics cards.
Thanks to @https://civarchive.com/user/chrisgoringe243 for quantizing this, it is really good quality for such a small model.
There are larger-sized GGUF versions available here: https://huggingface.co/ChrisGoringe/MixedQuantFlux/tree/main
for mid-range graphics cards.
Version 2 - fp16:
For those with high Vram Cards who want maximum quality I have created this merge with the full fp16 Flux model. if you "only have 24GB of Vram" you will need to force the T5 text encoder onto the CPU/System RAM with this force node on this pack: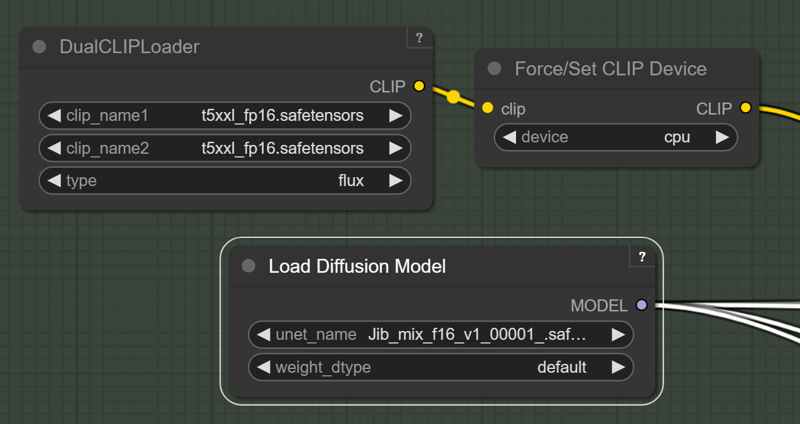 https://github.com/city96/ComfyUI_ExtraModels
https://github.com/city96/ComfyUI_ExtraModels
Those people waiting for a smaller quantized model I am still looking into it.
Version 2:
Merged in 8 Step Hyper Lora and some others.
Settings:
I like a Guidance of 2 and 8-14 steps.
Resolution: I like a around 1280x1344
Version 1 : brings some of the benefits and look of SDXL with the massive prompt adherence benefits of Flux.
Settings:
I like a Guidance of 2 and 20-40 steps.
Description
Best quality fp16 Flux version of Jib Mix Flux
FAQ
Comments (20)
How long / how much money would it take to train a BigASP stlye checkpoint for Flux?
@J1B Just to be clear, does the fp16 version also include the 8 step Hyper Lora?
Nevermind, looks like it converges fine on 8 steps.
No, I wanted it to be maximum quality. Although I didn't really notice the 8 step hyper degrading the quality at all on the other version, I may added another fp16 file with it merged in as not sure you can load any loras without running out of vram with this one.
@Grumblebutt Oh I hadn't even tried it. odd though.
@J1B Actually, I take that back about it converging on 8 steps. It does leave some artifacts and a little bit of body horror. It does great on 20 steps. If I add the Hyper Lora at 0.16 strength then it also does great on 8 steps.
Also, FYI, I only have a 16GB card and have no problems running it with the added Hyper Lora. It does just squeak by at 15.5GB but never goes over the VRAM limit.
Start saving for a high VRAM card, Imaging how much Vram people will need when Blackforest release their SOTA video model as opensource.
1) Welcome to Flux, not really meant to be ran locally (pretty much built to run in a CUDA render farm) 🤷♂️
2) Use "sd webui forge", so you can tell it to only use x amount of video memory and offload rest to cpu/ram, this way you can play with a 12gb model on 8gb gpu or whatever
why train loras and bake them in instead of doing a finetune?
Using Lora's slows down the generation quite a lot and uses more vram, also lora use is very limited when using optimisations like TensorRT (hoping something like that will come out for Flux soon).
i created gguf models for others to download ;)
for people with 8gb of vram
Thanks, I will test these. Maybe not the best place to upload them as it is going to take over 4 hours to download as it throttles after 5GB.
I just get an error with these models that I don't get when using other Flux Quants
"Error occurred when executing CLIPTextEncode: size mismatch, got input (77), mat (77x768), vec (1)"
Do you have a Workflow to use with anything special in it?
@J1B i just used the gguf comfyui stuff, just like any other gguf model Node Name: UNET Loader (GGUF)
@pkmngotrnr I can use other .GGUF models just fine, it is just those 2 that are throwing errors, maybe they got corrupted in the upload or something.
A range of optimized GGUF versions...
Please upload v5 thanks.
@Mopantsu Yeah, I have been trying to create a quantized GGUF format model for a while but the instructions are not that detailed, or I am doing something wrong and I cannot get it to work, I will keep trying.
@Mopantsu It took all me free Credits on Chat GPT, Claude and Co-pilot as well as my 4 year Computing Degree, but I managed to get Python to build me a Q4 GGUF model of Version 5 and have uploaded it now.