

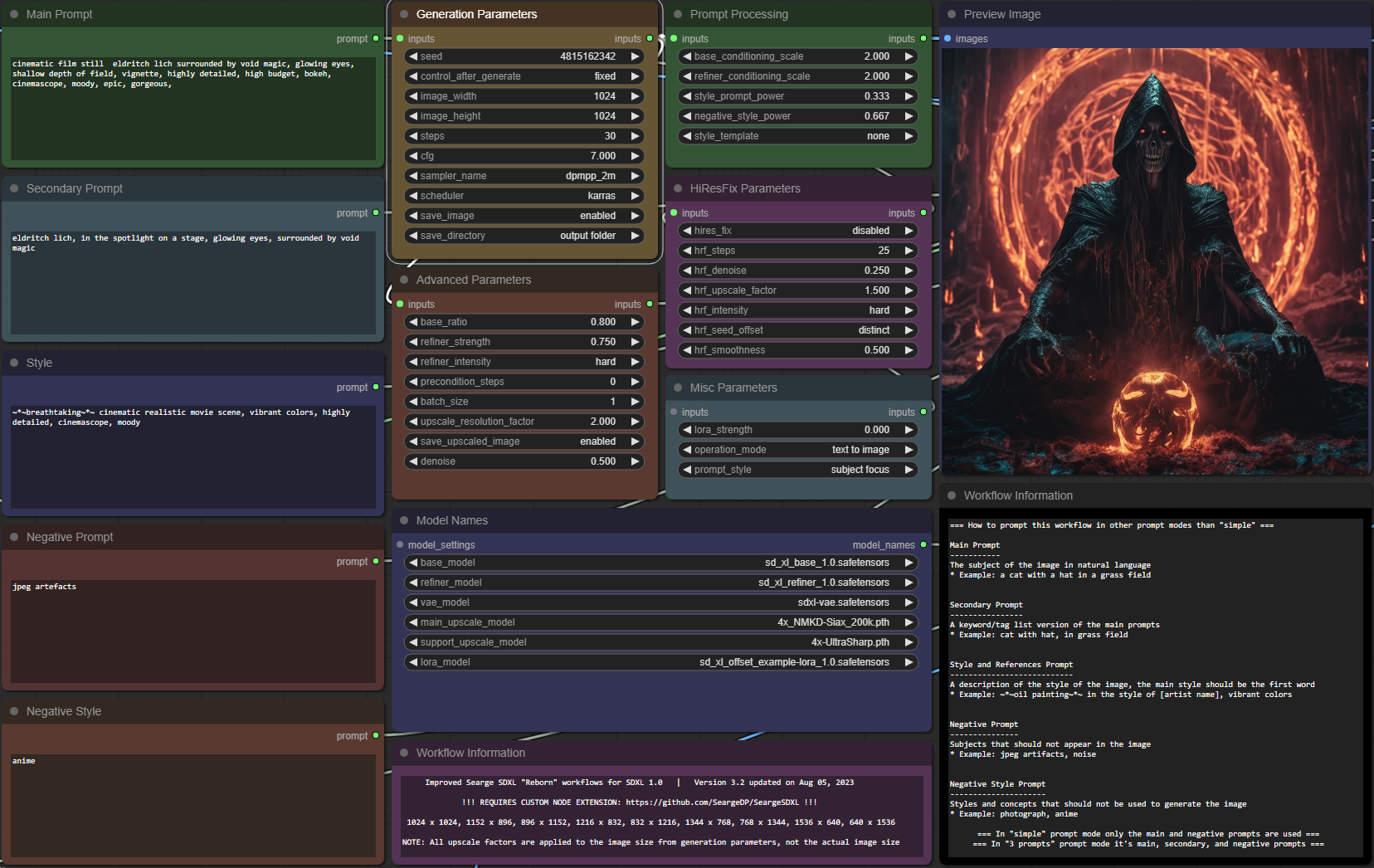
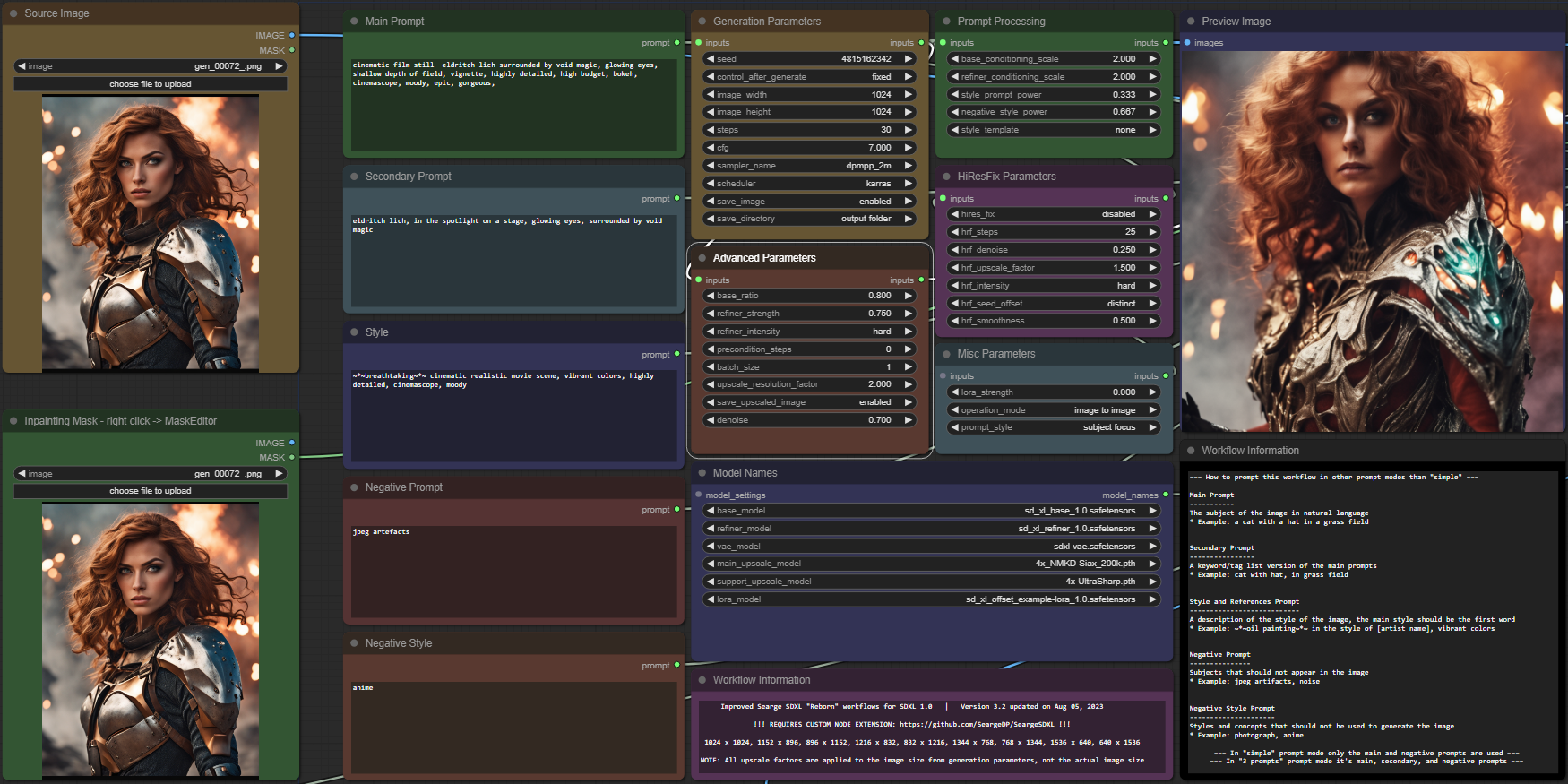
Searge-SDXL: EVOLVED v4.3.2
Version 4.x is here.
I made a convenient install script that can install the extension and workflow, the python dependencies, and it also offer the option to download the required models.
Please read the install instructions in the readme file for more information about the install script and how to use it.
Description
Some custom nodes for ComfyUI and an easy to use SDXL 1.0 workflow. A detailed description can be found on the project repository site, here: Github Link
Installing
Detailed install instruction can be found here: Link to the readme file on Github
Usage Notes
The workflow is in the workflow folder, please load it from the JSON files to make sure you are using the latest versions of it.
The images in the examples folder have workflows embedded.
How to use this workflow
Here is an amazing Youtube video that Nerdy Rodent made about version 3.4 of the workflow. Many things have changed in v4.0 but the basics still apply. And while you are watching it, don't forget to subscribe to the channel.
Link to the Nerdy Rodent video
Updates
What's new in v4.3.2?
This is a minor update to make the workflow and custom node extension compatible with the latest changes in ComfyUI.
What's new in v4.3.1?
This is a minor update to make the workflow and custom node extension compatible with the latest changes in ComfyUI.
What's new in v4.3?
This update added support for FreeU v2 in addition to FreeU v1.
New Features
Support for FreeU v2 has been added and is included in the v4.3 workflow
Added more presets for FreeU and a selector to switch between v1 and v2
Updated the example images to embed the v4.3 workflow
What's new in v4.2?
This update contains bug fixes that address issues found after v4.0 was released.
Bug Fixes
A recent change in ComfyUI conflicted with my implementation of inpainting, this is now fixed and inpainting should
work again
New Features
Support for FreeU has been added and is included in the v4.2 workflow
Note: the images in the example folder are still embedding v4.1 of the workflow, to use FreeU load the new
workflow from the.jsonfile in theworkflowfolder
What's new in v4.1?
This update contains bug fixes that address issues found after v4.0 was released.
Bug Fixes
The high resolution latent detailer was not properly set up in the processing pipeline and did nothing
The debug printer node was broken - I didn't notice that because it was not connected in any of the v4.0 workflows
A bug related to generating with batch sizes larger than 1 has been fixed, it's now working properly
Other Changes
The images in the
examplesfolder have been updated to embed the v4.1 workflow
What's new in v4.0?
A complete re-write of the custom node extension and the SDXL workflow
Highly optimized processing pipeline, now up to 20% faster than in older workflow versions
Support for Controlnet and Revision, up to 5 can be applied together
Multi-LoRA support with up to 5 LoRA's at once
Better Image Quality in many cases, some improvements to the SDXL sampler were made that can produce images
with higher qualityImproved High Resolution modes that replace the old "Hi-Res Fix" and should generate better images
... many more things, too many to mention them all here
Description
What's new in v3.4?
Minor tweaks and fixes and the beginnings of some code restructuring, nothing user should notice in the workflows
Preparations for more upcoming improvements in a compatible way
Added compatibility with v1.x workflows, these have been used in some tutorials and did not work anymore with newer versions of the extension
(backwards compatibility with v2.x and older v3.x version - before v3.3 - is unfortunately not possible)
FAQ
Comments (112)
It’s really tough
Incredibly effective and good user experience with this workflow despite the complexity. Serge I'm wondering if I'm doing image2image wrong because my images don't seem to change much even with high denoise.
Nice results. Thank you for the workflow!
But I would love to have the prompts you wrote for this "Man in 1940s style" picture.
You can download this file and load it into Comfy (with my extension installed) and you should see all the settings and prompts: https://cdn.discordapp.com/attachments/870294910249603143/1138445005145509959/gen_00030_.png
{kind=link}
@searge Thanks man, great picture and result.
I receive and error when running the default prompt:
Prompt outputs failed validation
ImageUpscaleWithModel: - Required input is missing: image ImageUpscaleWithModel: - Required input is missing: image SeargeInput4: - Value not in list: vae_model: 'sdxl-vae.safetensors' not in ['diffusion_pytorch_model.fp16.safetensors', 'diffusion_pytorch_model.safetensors', 'sdxl_vae.safetensors']
Any ideas?
Are you using an older workflow? The latest version is in the workflow folder. And make sure to download and copy the required models listed in the readme file.
@searge Same here, using new workflow .json. There are two input image nodes. Put images in them and i get same error. Where are proper instructions?
You have to right click and draw the mask. Then the sdxl-vae.safetensors VAE, i have it but i got the same error as you, the node in the middle called MODEL NAMES, select the sdxl-vae.safetensors manually, then it ran.
Oh I see, the file names do not match, one uses a dash, the other one an underscore in the name. Just select the correct vae in the models list and it should work.
@searge It is making some interesting results, but the source image and inpaint mask image seem to have no effect.
I'm a first time user of ComfyUI and I am truly overwhelmed by your complex workflow. Will it be possible to do a video step-by-step tutorial for dummies please? Would really appreciate it very much! 🙏🏼🙏🏼
I tested SIMPLE text to image and it took 12mins with my RTX3060Ti, while my simpler workflow did it in 1min. is that normal? https://i.imgur.com/ca1UwXx.jpeg
My original intention was also to put myself (I inserted an input image) in front of skyscrapers, but it became a stickman instead.
{kind=link}
Nerdy Rodent made video about the workflow: https://www.youtube.com/watch?v=_Qi0Dgrz1TM
for vae: sdxl_vae vs sdxl-vae is that a different file?? I renamed the existing one to match.
If the file names do not match, you can also click on the VAE field in the Model List box and select the correct file.
COpied Workflow 1
Queued Prompt
Got Error
Prompt outputs failed validation SeargeInput4: - Value not in list: vae_model: 'sdxl-vae.safetensors' not in ['realisticVisionV51_v51VAE.safetensors', 'sdxl_vae.safetensors'] SeargeSDXLSampler: - Return type mismatch between linked nodes: sampler_name, SAMPLER_NAME != ['euler', 'euler_ancestral', 'heun', 'dpm_2', 'dpm_2_ancestral', 'lms', 'dpm_fast', 'dpm_adaptive', 'dpmpp_2s_ancestral', 'dpmpp_sde', 'dpmpp_sde_gpu', 'dpmpp_2m', 'dpmpp_2m_sde', 'dpmpp_2m_sde_gpu', 'ddim', 'uni_pc', 'uni_pc_bh2'] - Return type mismatch between linked nodes: scheduler, SCHEDULER_NAME != ['normal', 'karras', 'exponential', 'simple', 'ddim_uniform']
Are you using the latest .json file from the workflow folder? This is a common error when using an older version of the workflow.
I believe I am, but will double check. I resolved the first error by making a copy of "sdxl_vae.safetensors" and changing the _ to a -. Will update you on the two type mismatch errors...
I had the 3.2 version loaded. I loaded 3.4 but got additional errors so I re-installed your custom node, did a git pull, fixed the errors I received re .js files, and now it works. Thanks!!!
Modes: how to change to different modes? Like simple, please??
Nerdy Rodent made this great video that explains it all: https://www.youtube.com/watch?v=_Qi0Dgrz1TM
Great Workflow! But I'm having trouble adding more loras to that.
You can just chain more in the model loading sections, scroll a bit down and then left from the main UI area
hallo...
this is happend when running the .bat. newest versiion and all requirements on place?! what is to happend?
Lutz
No idea. If you have issues, report it on the Github page for this extension, please
Mind blowing. I love it all. If only it embedded the meta data in the final PNG it would be perfect.
It should embed the metadata, nothing in the workflow or extension is preventing it. Are you using the latest version of ComfyUI? And if you are already up-to-date, make sure you are not running it with the "no metadata" flag in the batch file.
@searge Hello. Thanks so much for your response. It seems like I talked out of turn. I will have a look at what you suggested. This workflow is phenomenal. I am sure everyone appreciates your effort as much as I do.
It's impressive ! I was just wondering if we can use multiples loras, and how ?
For now you would have to manually chain more loras where I'm currently loading the lora that's supported by the workflow by default.
hi, absolute great work on the workflow for comfyui its really helpfull for us who isnt familiar to this UI to start using comfy.
i just want to ask, are you gonna implement controlnet to this workflow ? if not. can this model added a controlnet node manually ?
thanks in advance and fantastic work mr. searge
Thanks you, glad to hear you are enjoying it. Controlnet is planned for the future, right now I'm waiting for it to be released "properly" for SDXL first.
@searge thank you for the quick reply, okay cant wait for it to release properly then. have a great day
Is it possible to disable the refiner? Right now it is the biggest RAM/VRAM problem I have. If I switch models I always have to restart comfy... My current workaround is specifying an old 2G 1.5 model as I don't really need the refiner anyway.
Thanks for a great WF!
It's planned for a future version
Great Workflow Searge ! But I'm having trouble at the end of the prompt execusion.
E:\...\ComfyUI_windows_portable\ComfyUI\nodes.py:1269: RuntimeWarning: invalid value encountered in cast
img = Image.fromarray(np.clip(i, 0, 255).astype(np.uint8))
E:\...\ComfyUI_windows_portable\ComfyUI\custom_nodes\SeargeSDXL\searge_sdxl_sampler_node.py:359: RuntimeWarning: invalid value encountered in cast
img = Image.fromarray(np.clip(i, 0, 255).astype(np.uint8))
E:\...\ComfyUI_windows_portable\python_embeded\lib\site-packages\torch\_utils.py:776: UserWarning: TypedStorage is deprecated. It will be removed in the future and UntypedStorage will be the only storage class. This should only matter to you if you are using storages directly. To access UntypedStorage directly, use tensor.untyped_storage() instead of tensor.storage()
return self.fget.__get__(instance, owner)()
Prompt executed in 388.86 seconds. But the images are always black.
Thanks for your response.
I'm getting the unknown node types error. How can I solve it?
I added this model to my custom nodes folder but that didn't seem to help: https://civitai.com/models/19625
You don't need those custom nodes, you need the custom nodes that are included in this project. Follow the instructions in the readme file to install everything properly.
@searge Thanks for your reply Searge. I followed the instructions; ran "git clone https://github.com/SeargeDP/SeargeSDXL.git" inside "custom_nodes" and restarted ComfyUI but it didn't work.
Whenever I load the json file "Searge-SDXL-Reborn-v3_4" is says:
"When loading the graph, the following node types were not found:"
---
The reason I installed that extension is because I saw written in bold: "Installing the custom nodes extension for ComfyUI is necessary to use the workflow without errors about unknown node types."
Cany is out in safetensors, are you planning to add controller soon?
Btw, what you are doing is awesome. Soon Comfy will become more user friendly than automatic ))
Yes, controlnet support is planned for a future update. But I can't tell how soon it will be ready, have to experiment with it first to see how to best incorporate it into the workflow.
Anyone else getting black images in output?:-(
There is an issue on the Github bugtracker for this prooject. You should check if anything that was suggested in there works and otherwise add a comment to that issue that you are also encountering the problem.
Hi!
1. I already switched batch_size to 4 in Advanced Parameters - why is it that I'm still getting 1 preview per queue?
2. I'm regularly getting deformed eyes with txt2img. how to prevent that? sample image & prompts as attached:
https://i.imgur.com/sSRQwiT.png
{kind=link}
https://i.imgur.com/DlOk5OI.png
https://i.imgur.com/xcubujf.png
3. in the default simple txt2img flow, assuming I get an image I love, how do I run just the upscale model without triggering everything else (i.e. new generation again)?
{kind=link}
{kind=link}
1. I think by default Comfy only shows the first image of a larger batch size and you can switch between all 4 in the preview node.
2. It depends on the prompt and seed how well eyes look in generated images. I also recommend to go light on the negative prompts with SDXL, maybe even start with an empty negative, to see if that changes anything. The hires-fix option is also great to improve the output, doesn't always work, but on average I get better results.
3. You should just be able to connect the "jumper" below the main UI to enable the upscaler and if you didn't change anything else it should not re-generate everything else again.
is this workflow only working with sdxl model?
Yes, right now this workflow is explicitly designed for use with SDXL models.
Comfuyi is something I don't dare to touch because of its tangled wires, but you've made everything easier, Thank you for your contributions to the Civic community, always be your fan ^^ xx
Glad to hear that you like it. Hiding the spaghetti from users who just want to make pretty images is one of the goals of this project.
alway get an error like this
Prompt outputs failed validation ImageUpscaleWithModel: - Required input is missing: image ImageUpscaleWithModel: - Required input is missing: image SeargeSDXLSampler: - Return type mismatch between linked nodes: sampler_name, SAMPLER_NAME != ['euler', 'euler_ancestral', 'heun', 'dpm_2', 'dpm_2_ancestral', 'lms', 'dpm_fast', 'dpm_adaptive', 'dpmpp_2s_ancestral', 'dpmpp_sde', 'dpmpp_sde_gpu', 'dpmpp_2m', 'dpmpp_2m_sde', 'dpmpp_2m_sde_gpu', 'ddim', 'uni_pc', 'uni_pc_bh2'] - Return type mismatch between linked nodes: scheduler, SCHEDULER_NAME != ['normal', 'karras', 'exponential', 'simple', 'ddim_uniform']
Are you using the latest .json file (v3.4) from the workflow folder?
@searge oh no,detailed process like this
1: I click load button in regular comfyui window,
2: import image (custom_nodes\SeargeSDXL\example\Searge-SDXL-reborn.png) ,by the way, any image from that example folder
3: it seems ok now, then I click <queue prompt> button,
4: this error always appear
I have the same error, using 3.4, I checked with procmon and under the hood this results in a Python Buffer overflow when reading the image.
Please do NOT import from the example images, those contain outdated workflow versions. Load the .json file from the workflow folder.
@searge done that, but still same error, also removed and added image input nodes, still same error.....
@searge that's ok when I don't import example images
Hello!
Thanks for this great tool !
I want to use it for the contest, but the generation data is not showing.. how can I get this data?
Thanks and sorry if this a silly question.
Regards!
That's something CivitAI needs to solve on their side. They've already commented on it somewhere else and said that their backend is currently not parsing complex workflows like this one properly.
@searge thank you for the response.
Is it possible somehow to generate the same image in 3 different different ratios?
For example, once the main image is done, use it to generate a copy in 2:3 and another copy in 9:16.
Right now that's not easily possible. Even with the same seed, prompt, and parameters, images generate differently based on the selected aspect ratio.
One option would be to generate the image and upscale it, then crop 2 versions with these aspect ratios.
@searge got it, thanks! Not sure if upscaling and cropping can do the job without cutting important elements because of the ratio difference. I was thinking about out-painting and then cropping, but couldn't do it properly with img2img yet.
32GB ram (and 4090) and I run out of ram with the default settings (worked when I set upscale to 0 but I'd rather be able to disable it directly than load and not use it). It's also hard to disable things like VAE or Refiner from the presented UI.
Do you have any plans to add support for multiple LoRAs to this workflow? I love what you've got here, but a lot of my workflows in A1111 utilize multiple LoRAs. Unless I'm missing something, the entry I see for LoRA only accepts one name.
Is it possible to load prompts from a Gsheet or .txt file automatically?
ComfyUI is getting super laggy when I put too many generations on queue. For now I can schedule up to 100 without freezing hard.
By the way, thanks for this work-flow, I'm starting to get some really decent results.
Interesting idea, I'll consider it and see if that could be done
How do we handle a checkpoint that has its VAE burned into it? I don't see an option that in your Model Names section. I would rather not use a standalone VAE for checkpoints that already have their own.
In the section "Model Loading", a bit down and to the left from the main UI, you can connect the VAE output from the base mode with the re-route node named "vae"
@searge It would be outstanding if you could build that switch into your next version. Maybe just add an to the Model Names node for "Use Model VAE: Yes/No" and then disable the current "model_vae" option if Yes has been selected.
Man i feel stupid but i kind of dont get why loras wont work, i tried changing the prompt style to 3 Prompts & changed the lora_model but the loras dont affect the image...
Did you change the lora strength in misc parameters?
load 3.4.json , error display: not found Node: ImageBlend , ImageScale
If you use the ComfyUI-Manager, you should be able to "Install Missing Custom Nodes"
https://civitai.com/models/71980?modelVersionId=133010
https://github.com/ltdrdata/ComfyUI-Manager
ImageBlend and ImageScale are default nodes in ComfyUI. There has been issues in the past with another node extension removing them, so if you use other custom node extensions, please try with only this one (disable the other extensions temporarily) to see if it's an issue with my extension or another one that's installed.
Alright Loras don't work, they can't. I don't know much but from what I see in that network, the Lora flow doesn't go anywhere : https://i.imgur.com/HPegaWF.png
{kind=link}
Yeah, it works. The workflow is only setup to use one LoRA at this time, though. I actually modded his workflow to incorporate three more LoRAs that I use for all of my images. So, I know it works.
@97Buckeye ok stupid mistake : I forgot the lora strength!! xDD
...but I got only bad results. The weighting seem different and at some point it doesn't change the output, there's tons of parameters in there... I think that workflow is too hard for me
@97Buckeye Can you kindly share your custom workflow json? would be highly appreciated. Also did you also try to mod and include the new controlnets too?
This is amazing! I'm only starting with ComfyUI and this is a real game changer for me. I was about to give up but then i came across this workflow. Thank you for creating and sharing it with us. Really appreciated.
Only one thing i cant figure out, where is toggle/location for changing 3 Prompts/Simple prompt mode ?
Maybe I'm doing something wrong, but I load the 3.4version Json, I click generate with everything as base and it works just fine...
BUT as soon as I change the base_model to for example AnythingV5 it just doesn't work...
Here is the error:
Error occurred when executing SeargeSDXLPromptEncoder: list indices must be integers or slices, not str File "F:\AI\ComfyUI\ComfyUI_windows_portable\ComfyUI\execution.py", line 151, in recursive_execute output_data, output_ui = get_output_data(obj, input_data_all) File "F:\AI\ComfyUI\ComfyUI_windows_portable\ComfyUI\execution.py", line 81, in get_output_data return_values = map_node_over_list(obj, input_data_all, obj.FUNCTION, allow_interrupt=True) File "F:\AI\ComfyUI\ComfyUI_windows_portable\ComfyUI\execution.py", line 74, in map_node_over_list results.append(getattr(obj, func)(**slice_dict(input_data_all, i))) File "F:\AI\ComfyUI\ComfyUI_windows_portable\ComfyUI\custom_nodes\SeargeSDXL\modules\prompting.py", line 70, in encode tokens1["l"] = base_clip.tokenize(pos_l)["l"]
Any ideas?
Great workflow! Have been using it for a bit now. One problem: I'm REALLY missing FaceDetailer but for some reason your set-up seems to be not compatible. I get a really long error message and can't find any help online. Anyone have an idea?
Error occurred when executing FaceDetailer:
mat1 and mat2 shapes cannot be multiplied (154x2048 and 1280x768)
I've not used face detailer, so I don't really know why it causes this issue. I'm planning to look into it for a future update.
is it possible to implement ControlNet into this workflow as well ?
That is planned for a future version
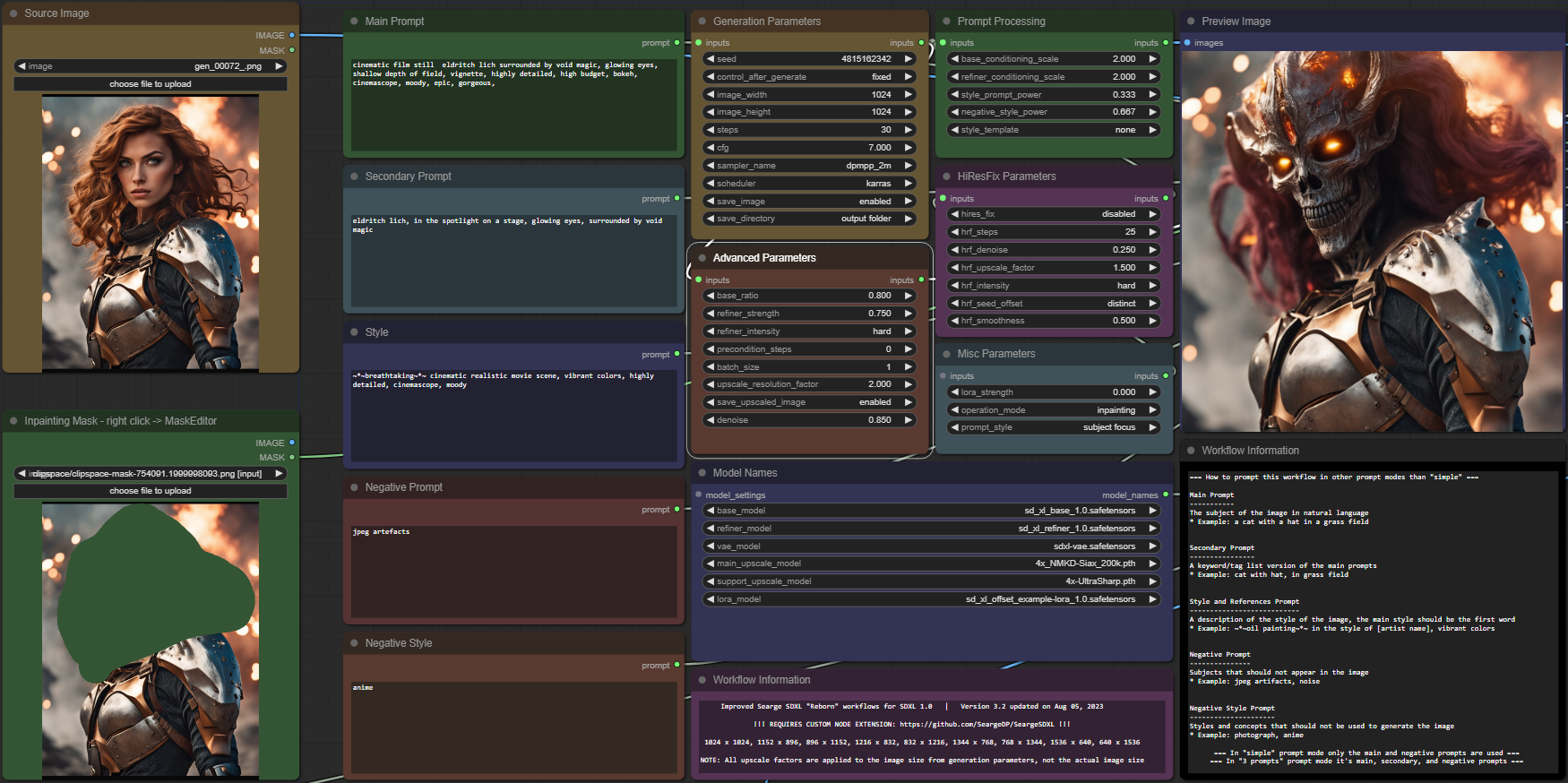
I'm trying to inpaint a damaged photo using inpainting mode and a mask over the damaged area, but it just blurring a bit the edges of the mask, any suggestions how to make it work properly?
Did you try different values for the denoise parameter?
@searge yeah I'm having a lot of trouble with the inpainting as well. It seems to just really want to generate the same thing that is masked out. I tried different denoise settings, different prompts, putting the masked content in negative prompt (in my case sky & clouds) and I just couldn't make it work.
Otherwise this workflow is crazy powerfull btw, I am totally blown away with how well it understands prompts and how versitalie the style prompt is!
@searge Yeah I have tried to change the parameters, it just changes a little bit the edge where the masked damaged missing pieces of the photos are.
It looks cool, but it's sort of useless; Lora's don't work, and you can only use one?
If you don't like it or don't see a use for it, just use one of the many alternative workflows available. Or make your own.
Loras work, once you set their strength to higher than 0.0 and multi lora support will come to a future update.
@searge No need to take it personally. Just addressing its major flaw.
This is already the best workflow around. But you already know what will make this the GOAT workflow, Searge. We're (im)patiently waiting for the Controlnet and multiple LORA support update. Please end this blueballs lmao.
I'm working on the next update for the workflow that will at least include multi lora support. If controlnet is already included in the next update or the following one will depend on multiple factors, the most important being if I can find a good way to integrate it before the self imposed deadline for the update release.
@searge Here's to hoping you'll be able to manage it. Godspeed and thank you for the superb effort!!
@searge same here, also can't wait for your controlnet update! Thanks for all your work, best workflow around. Speed and quality!
This is the best workflow anyone has ever created! Congratulations on your success, you're like a hero here! I thought for a long time whether to post this comment here, but boy you deserve recognition. Just please add the ability to use multiple LORAs at once and ControlNet.
Multi-LoRA and Controlnet are coming to a future update of the workflow
Does enabling Hires Fix influence the upscale quality? If so, I could then choose a x4 upscale directly for a better quality instead of doing a x2 Highres fix and then manually having to feed that into an upscaler to do another x2.
The hires fix can add and refine details in your image. The upscaler will just take the image you generated and produce a higher resolution version of it.
You can use both, the hires fix and upscaler, in my workflow. Just enable hires fix and connect the "jumper" for the upscaler below the main UI of the workflow. It will then take the hires-fixed image and upscale it.
@searge Thank you! In your opinion, does the combo highres fixed+ upscale produce a more detailed image than just a direct upscale in your workflow?
Extremly new guy here. Installed this. Getting the error first run through on Texttoimg
Prompt outputs failed validation ImageUpscaleWithModel: - Required input is missing: image ImageUpscaleWithModel: - Required input is missing: image SeargeInput4: - Value not in list: vae_model: 'sdxl-vae.safetensors' not in ['sdxl_vae.safetensors']
You have to click on the name of the VAE file in the workflow and select the correct file. That should solve this issue.
@searge Thank you , newbie.