














RedCraft-红潮 NSFW
做好工具人 服务艺术家
Forever in memory of METAFILM Studio founder Mr. Yuan Bo
No Mosaics. 无码 2倍速
Reveal every detail
KREA 2 赤佬 Bastard2 Edition
Krea2-RED-Mix2 赤佬无码版 01/07/2026 8 Steps
INT8 Convrot for ComfyUI 0.27 [Native 原生节点支持] Uploaded
File name: Krea2RedMix1.1-INT8-Convrot-ComfyUI (original native)
File name: Krea2RedMix2.1-INT8-Convrot-ComfyUI (no mosaics)
Usage :ER_SDE/Euler | Simple | CFG=1 | 8 Steps






链接: Dark Beast | 黑兽 🐱👤Krea2赤佬无码版 已发布 06/28/2026
ERNIE-Red-Mix 26/04/2026 10Steps Fine-Tuning
ERNIE-Image is an open text-to-image generation model developed by the ERNIE-Image team at Baidu. It is built on a single-stream Diffusion Transformer (DiT) and paired with a lightweight Prompt Enhancer that expands brief user inputs into richer structured descriptions.
With only 8B DiT parameters, it achieves state-of-the-art performance among open-weight models. The model emphasizes both visual quality and controllability, making it highly effective for real-world generation tasks where precision matters.
ERNIE-Red-Mix adopts mixed-precision SFT (Supervised Fine-Tuning) with reference-based alignment, covering both AIO and DiT variants. It is trained on the mature RedCraft dataset, enabling broader generation flexibility, fewer constraints, and the ability to unlock novel visual styles beyond the base model.
Usage :EULER/DEIS | Simple | CFG=1 | 10Steps


🇨🇳 中文
ERNIE-Red-Mix 采用混合精度 SFT(参考式微调,对齐优化),覆盖 AIO / DiT 双版本,基于成熟的 RedCraft 训练集进行训练,在一定程度上解除生成限制,并显著提升风格扩展能力,可用于生成全新视觉风格。
🇯🇵 日本語
ERNIE-Red-Mix は、混合精度による SFT(参照ベースのファインチューニング)を採用し、AIO / DiT の両バージョンに対応しています。成熟した RedCraft データセットで学習されており、生成制約の緩和とともに、新しいスタイル生成能力を拡張します。
🇹🇼 繁體中文
ERNIE-Red-Mix 採用混合精度 SFT(參考式微調),涵蓋 AIO / DiT 雙版本,基於成熟的 RedCraft 訓練集進行優化,在一定程度上解鎖生成限制,並提升風格拓展能力,可生成全新視覺風格。

ERNIE-Red-Mix Highlights:
Optimized speed ♥ Accelerated to 10 steps (CFG 1) while preserving BASE quality.
Compact but strong ♥ Performance on par with substantially larger models, with stable and accurate details and materials.
Text rendering preserved ♥ Fine-tuning does not compromise text rendering capability (posters, infographics, UI visuals).
Instruction following maintained ♥ Unaffected ability to reliably handle complex prompts with multiple objects.
Structured generation ♥ Continues to excel in posters, comics, and storyboards.
Broader style coverage ♥ More realistic photography and improved aesthetic outputs.
Lower VRAM footprint ♥ Mixed precision supports consumer GPUs with 8–12GB VRAM.
Limitations:
Complex limbs prone to artifacts — An inherent ERNIE issue; generating more samples can help mitigate this.
Anatomical accuracy — Body anatomy and organ rendering still need further optimization and refinement.
Mixed precision impacts text rendering — Mixed precision has a noticeable negative effect on text quality; for text-heavy content, the BF16 BASE model is recommended.
Sample Images:

























ZImage DPO “AGILE” Now Uploading 08/03/2026 女神节祝福🌸
On this Day, may every woman feel the strength, grace, and boundless potential that lives within her. Thank you for your courage, your kindness, your resilience, and the countless ways you make the world brighter and better. Here's to equality, empowerment, joy, and endless possibilities—today and every day. Happy International Women's Day🌸
ZIDistilled FUN “AGILE” Now Released
Special thanks to the VideoXFUN team for releasing the groundbreaking Zimage Distilled Adapter 2603. By incorporating this latest update, AGILE achieves a refined balance between speed, diversity, and visual richness — unlocking more creative freedom while maintaining exceptional efficiency.
Agility in Motion, Diversity in Depth
The brand-new ZImage FUN “AGILE” is built upon the cutting-edge ZIB acceleration framework. We deliberately reduced DPO & Distilled weight to preserve greater stochastic freedom, combined with the most recent training datasets, resulting in dramatically increased output variety, richer content details, and more imaginative compositions without sacrificing core stability.

For the first time, AGILE reaches a true quality parity challenge against the flagship “ZImage TURBO” in terms of overall image fidelity and sharpness — even in complex scenes — while delivering faster iteration and superior responsiveness.
Key highlights:
True ZIT-level unlocked — photorealistic lighting, textures, and material rendering that now rivals or approaches ZImage TURBO quality, even at standard step counts.
Enhanced diversity & content richness — DPO + Newest datasets = more varied poses, styles, atmospheres, intricate details, and unexpected creative sparks in every generation.
ZIB ecosystem ignition — exceptional native compatibility with ZIB-series LoRAs; your existing and future LoRAs now align faster, reproduce more faithfully, and shine brighter than ever before — officially kicking off the full ZIB LoRA era.
Agile workflows — seamless hybrid use with Klein 9B for refinement, ensemble boosting, or rapid prototyping; near-instant LoRA response with preserved high-entropy creativity.
Every generation is a step toward freer, bolder imagination.
欢迎体验 ZImage FUN “AGILE” —— 速度如洪,创意如潮。
Welcome to ZImage FUN “AGILE” — where agility meets abundance, and your ideas finally run wild with unmatched fidelity and freedom.
ZImage DPO “Veris” Now Released 03/03/2026 元宵节快乐
I have uploaded more quantification and export “Veris” LoRA to HF repo. to avoid causing confusion for users in the community:
https://huggingface.co/GuangyuanSD/Z-Image-Distilled
版本太多网友容易迷糊,我导出了更多量化规格和 “Veris” LoRA 版本,已发布抱脸仓库。
Special thanks to @Fok for providing the Flow-DPO technical adaptation. By skillfully integrating the training philosophy of Direct Preference Optimization (DPO) into the distillation weights, the Zimage distilled model achieves a major leap in lighting, color fidelity, and material authenticity — more natural light & shadow, more believable colors, and details that hold up under scrutiny.
特别感谢 @Fok 饼儿佬提供了Flow-DPO技术适配。通过巧妙地将直接偏好优化(DPO)的技术理念融入蒸馏权重,Zimage 蒸馏模型在光照、色彩保真度和材质真实性方面实现了重大飞跃——更自然的光影效果、更逼真的色彩,以及经得起仔细审查的细节。
The following example shows a comparison between ZIT and Flow DPO, intended to illustrate the effect of DPO, rather than a direct demonstration of ZIB Distilled


Speed of Truth, Fidelity of Flow
真实且极速,用忠诚在流动
The all-new ZIDPO “Veris” is powered by the latest-generation ZIB acceleration engine. Building on the RedZDX training data, we further distilled a more efficient, more refined Zimage-based model.
Now — solid, highly realistic generations in just 8 steps.(Better LoRAs alignment)
仅需8步即可生成更有层次感、高度逼真的图像。(LoRa对齐效果更佳)
---
Key highlights:
Realism-first prototyping — near-zero latency for LoRAs, with lighting and color already very close to final training targets
High-entropy stochastic pre-sampling — delivers fast, high-quality realistic initial noise for ZImage pipelines
Hybrid realism workflows — seamless integration with Klein 9B for cascaded refinement or ensemble boosting, pushing visual fidelity and consistency even higher
Every step toward truth deserves full commitment.
---
欢迎体验ZIDPO“Veris”——您的LoRa训练结果不再只是“相似”,而是真正得到“复现”。
Welcome to experience ZImage DPO “Veris” — where your LoRAs generations are no longer just “similar”, but truly are.
同时,欢迎体验在 ZImage 或 Turbo 模型上直接加载 DPO LoRA Adapter:
抱脸(HF) https://huggingface.co/F16/z-image-turbo-flow-dpo
魔搭(境内) https://modelscope.cn/models/FFFFFFoo/z-image-turbo-flow-dpo
Redcraft DX3 ZIB🟥 Distilled models Zoo:
Full Model bf16 (19.11 GB)<- ComfyUI All-in-One Checkpoint BF16
Pruned Model BF16 (11.46 GB) <- ComfyUI Diffusion BF16 精度模型权重
Pruned Model fp8 (6.75 GB) <- ComfyUI Diffusion Scaled FP8 Mixed 混合精度
Pruned Model nf4 (6.73 GB) <- NVFP4 Mixed 混合精度(BLACKWELL 50系加速)
Training Data (3.75 KB) <- ComfyUI Simple Hybrid Workflow 简易混合采样工作流
Redcraft DX3 ZIB🟥 Distilled LoRA Adapter 02/19/2026
Additionally, I've exported Redcraft DX3 ZIB Distilled LoRA in Rank-256 format. The LoRA weight can be adjusted to adapt it to various ZIB fine-tune models, fully compatible with the Z-Image(non-turbo) base model.
Full Model fp16 (1.06 GB) <- 可以通过这里直接下载 LoRA 版本
[ZI Distilled HF repo.](https://huggingface.co/GuangyuanSD/Z-Image-Distilled)
上面是 Redcraft DX3 ZIB Distilled 导出为 Rank256 的LoRA版本,可以调整权重强度用于各种微调ZIT版本, 适配于 Z-Image(non-turbo) base 基底模型.
Redcraft DX3 ZIB🟥 Distilled LoRA adaptation models Zoo:
Z-Image-Base-GGUF <- Z-Image Base GGUF 量化模型
Z-Image Base <- Z-Image Base & TE (FP8/FP4) 模型
Z-Image Base FP8Mixed <- Z-Image Base FP8 混合精度模型
Text Encoder (ClipLoader use) <- Qwen3 4b FP16 文本编码器
Abliterated Huihui Qwen3 4B v2 (Q_8 GGUF) <- Z-Image Uncensored TE 文本编码器
VAE (Flux.1 16C VAE) <- 标准的 Flux.1 16 通道 VAE
Or download from the "Files" list below the "Details" on the right side of this page>>
Also available in NVFP4 quantized format, optimized for acceleration on Blackwell architecture GPUs.
Double speed, Half resources.
( like RTX50XX, PRO6000, B200, and others )
Verify environment is my ComfyUI 0.11
Also supports non-50 series GPUs (automatic 16-bit operation)
DF11 Lossless Compression RedZDX V3 came out! 2/15/2026
learn more: Dynamic-length Float (DFloat11)
[HF] mingyi456/Z-Image-Distilled-DF11-ComfyUI
Z-Image-Distilled v3 (RedZ DX3) 2/11/2026
Thanks to @Bubbliiiing VideoX-Fun&Alibaba-PAI Provided us with a more efficient distillation solution
Speed of Light, Power of Flow: The new ZID v3 "Lucis" is powered by the latest ZIB acceleration. Building on ZID v2 trainning sets, we've distilled a more efficient Zimage-based RedDX3. Now, in just 5 steps, you get solid results.
Rapid Prototyping: Test LoRA training hypotheses instantly with 'near-zero' latency.
Stochastic Pre-sampling: Serve as a high-speed, high-entropy source for ZiTurbo pipelines.
Hybrid Workflows: Pair seamlessly with Klein 9B for cascaded refinement or ensemble generation.
inference cfg: 1.0-1.5(建议1.0)
inference steps: 5(5-15步)
sampler / scheduler: Euler / simple

Welcome to the era of instant creativity. Welcome to 'Lucis'.
Preview images generated by Z-Image Hybrid Workflow of Distilled V3+Moody MIX V7(ZIT finetune) ,Just for showing the style difference between ZID(RedZDX3) and ZIT(fine-tunning) , no ranking intended =)
[ L = 'ZID v3', R = 'ZIT ft' ]
演示例图使用 ZIDistilled V3+Moody MIX V7 混合工作流程,不用做排名对比:





中国境内 [ modelscope ]AiMETATRON/Z-Image-Distilled | [ HF ] GuangyuanSD/Z-Image-Distilled
Z-Image-Distilled v2 (RedZ DX2) 2026/2/5
To a certain extent, the problem of ZIB color deviation has been reduced, but it is recommended to adjust the color appropriately according to the art style
inference cfg: 1.0(建议1.0)
inference steps: 10(10-15步)
sampler / scheduler: Euler / simple
感谢🙏这位作者完成了ZIB的FP8mixed混合量化方案:
https://huggingface.co/pachiiahri
已上传FP8版本,请给这位作者点赞👍
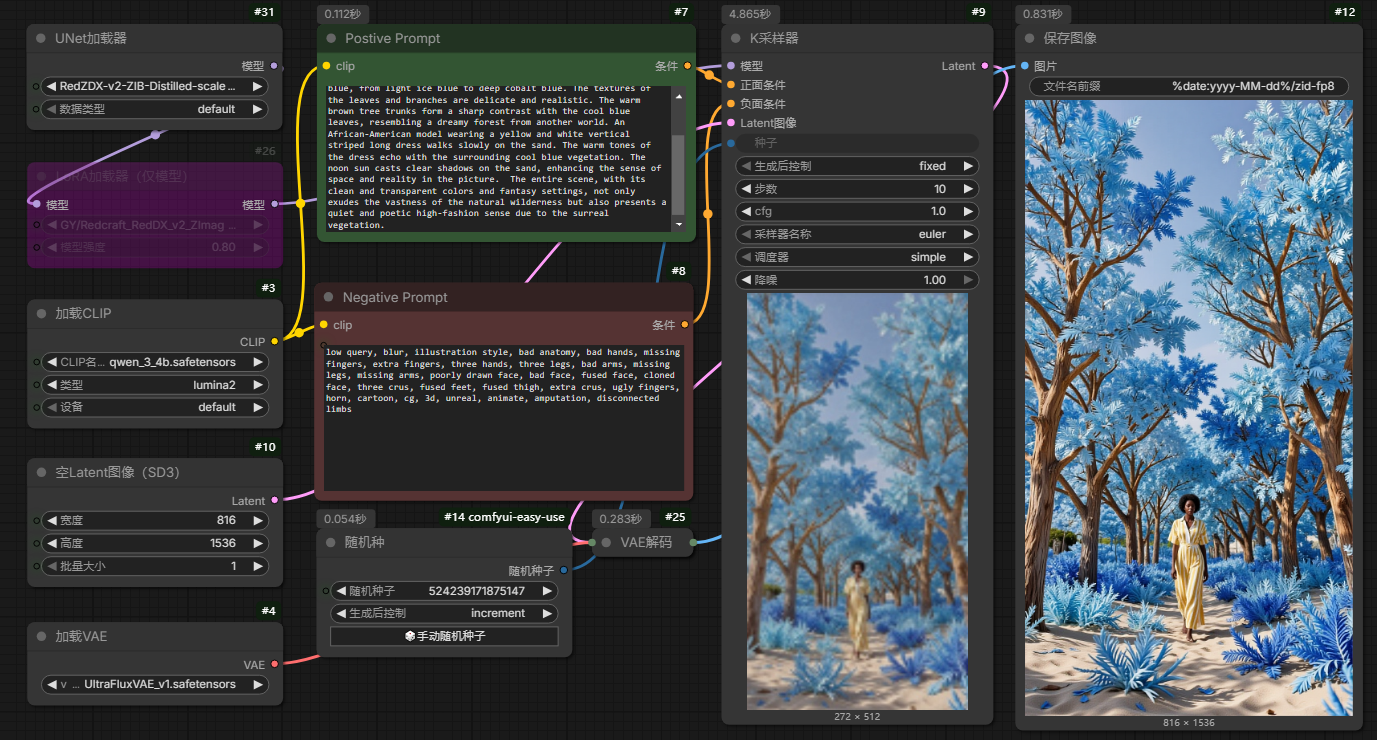
以上是FP8 scale&mixed 直出工作流(请不要再说我造假,我的所有例图工作流都是开放的)
精度混合方案来自 https://civarchive.com/models/2172944/z-image-fp8
Comparison of RedCraft Zimages(bf16):


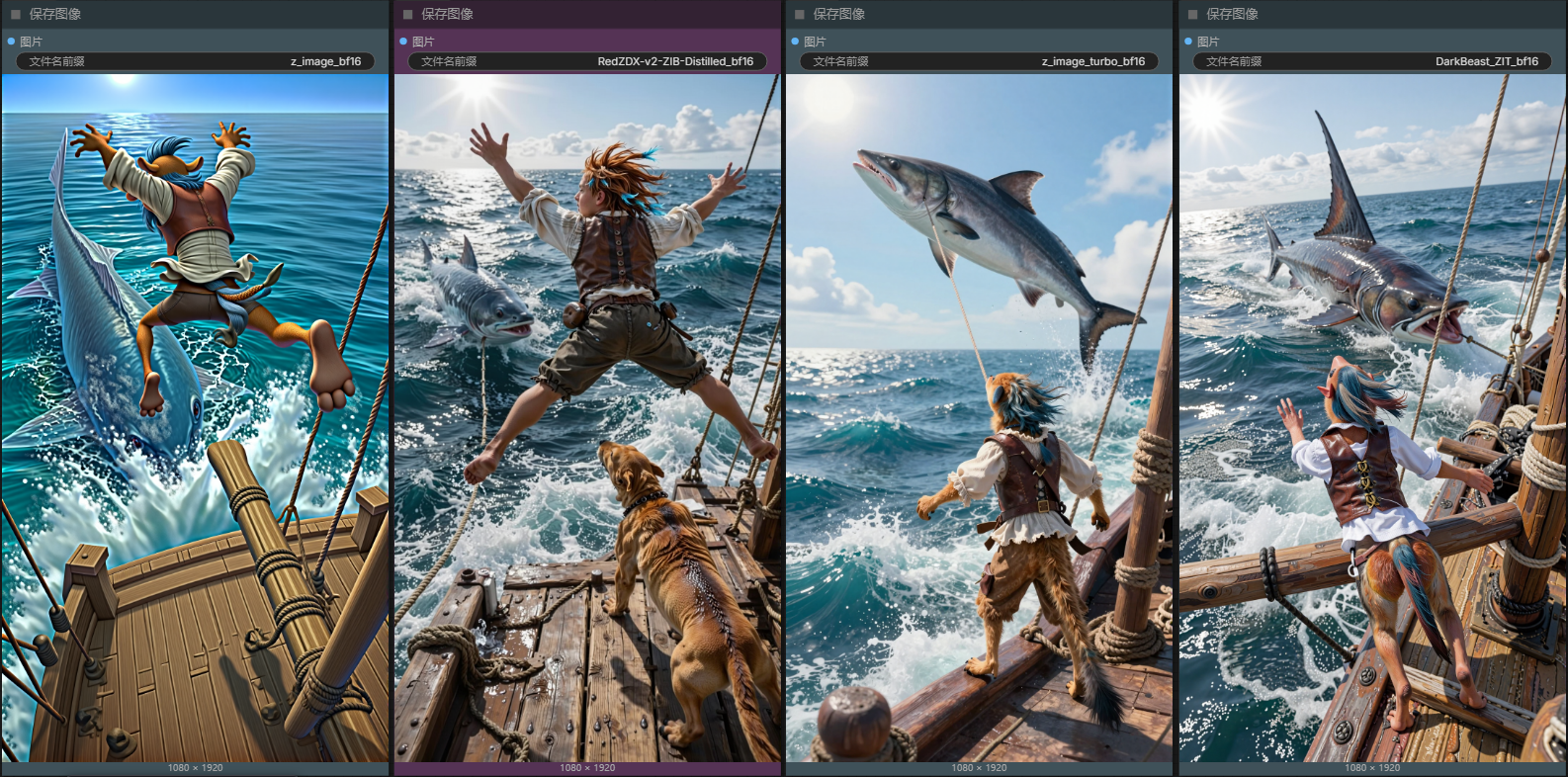


The art style leans towards realism

Retains ZIB's creative ability and reduces the collapse of Human anatomy.

REDZiBDX1·Demo accelerated Base-Model CFG1
Distilled form ZImage(non-turbo)base-model bf16

Now we have the LoRA version, thank to @anyMODE for Extract
in-site link https://civarchive.com/models/2359857/z-image-base-distilled-lora-or-extracted
Pruned Model bf16 (11.46 GB) = Z-Image-Distilled / RedZDX-ZIB-Distilled-nocfg-10steps-BF16-Diffusion-models.safetensors 单独的扩散模型文件bf16剪裁精度
Full Model fp8 (16.87 GB) = Z-Image-Distilled / RedZDX-ZIB-Distilled-nocfg-10steps-FP8mixed-AIO-Checkpoints.safetensors 完整的Checkpoints(含TE/VAE)
Pruned Model fp8 (5.73 GB) = Z-Image-Distilled / RedZDX-ZIB-Distilled-nocfg-10steps-fp8-e4m3fn-Diffusion-models.safetensors 单独的扩散模型文件fp8剪裁精度及e4m3规格
Training Data (5.6 KB) = Z-Image-Distilled ComfyUI workflows 我自己使用的简易测试工作流
VAE (319.77 MB) = Flux.1 VAE ae.sft 常规的Flux.1 VAE
例图包含完整出图参数,点击右下角❕就可以看到,同时点击 COMFY Nodes 就可以复制源图工作流,并可以在ComfyUI界面中 Ctrl+V 粘贴至新的工作区。
All sample images contain full generation metadata.
Click the ❕ button (bottom-right) to view the complete parameters. Click COMFY Nodes to copy the original workflow JSON, then paste it (Ctrl+V) into a new ComfyUI workspace.
Z-Image-Distilled
本模型为基于 Z-Image 源版本(非Turbo)的直接蒸馏加速版,旨在测试Z-Image(non-turbo)版本上训练的LoRA效果,并显著提高推理/测试速度。模型完全没有融入Z-Image-Turbo的任何权重与风格,属于基于Z-Image的纯血版本,较好地保持了原版Z-Image的适配性、出图随机多样性以及整体图像风格。
相比官方Z-Image,推理速度更快(推荐10–20步即可获得较好效果);相比官方Z-Image-Turbo,本模型保留了更强的多样性、更好的LoRA兼容性与可微调潜力,但速度略慢于Turbo(仍远快于原始Z-Image的28~50步)。
模型主要适用于:
希望在Z-Image非Turbo基底上训练/测试LoRA的用户
需要比原版更快、但又不想牺牲太多多样性与风格自由度的场景
艺术、插画、概念设计等对随机性与风格多样性有一定要求的生成任务
适配 ComfyUI 的模型格式及层命名前缀
使用方法:
推荐推理参数:
inference cfg: 1.0–2.5(建议1.0~2.5区间,较高值可增强提示贴合度)
inference steps: 10–20(10步快速预览,15–20步品质更稳定)
sampler / scheduler: Euler / simple,或 res_m,或其他兼容sampler
LoRA兼容性良好,权重建议0.6~1.0,根据需求微调。
This model is a direct distillation-accelerated version based on the original Z-Image (non-Turbo) source. Its purpose is to test LoRA training effects on the Z-Image (non-turbo) version while significantly improving inference/test speed. The model does not incorporate any weights or style from Z-Image-Turbo at all — it is a pure-blood version based purely on Z-Image, effectively retaining the original Z-Image's adaptability, random diversity in outputs, and overall image style.
Compared to the official Z-Image, inference is much faster (good results achievable in just 10–20 steps); compared to the official Z-Image-Turbo, this model preserves stronger diversity, better LoRA compatibility, and greater fine-tuning potential, though it is slightly slower than Turbo (still far faster than the original Z-Image's 28–50 steps).
The model is mainly suitable for:
Users who want to train/test LoRAs on the Z-Image non-Turbo base
Scenarios needing faster generation than the original without sacrificing too much diversity and stylistic freedom
Artistic, illustration, concept design, and other generation tasks that require a certain level of randomness and style variety
Compatible with ComfyUI inference (layer prefix == model.diffusion_model)

Usage Instructions:
Basic workflow: please refer to the Z-Image-Turbo official workflow (fully compatible with the official Z-Image-Turbo workflow)
Recommended inference parameters:
inference cfg: 1.0–2.5 (recommended range: 1.0~2.5; higher values enhance prompt adherence)
inference steps: 10–20 (10 steps for quick previews, 15–20 steps for more stable quality)
sampler / scheduler: Euler / simple, or res_m, or any other compatible sampler
LoRA compatibility is good; recommended weight: 0.6~1.0, adjust as needed.
Current Limitations & Future Directions
Current main limitations:
The distillation process causes some damage to text (especially very small-sized text), with rendering clarity and completeness inferior to the original Z-Image
Overall color tone remains consistent with the original ZI, but certain samplers can produce color cast issues (particularly noticeable excessive blue tint)
Next optimization directions:
Further stabilize generation quality under CFG=1 within 10 steps or fewer, striving to achieve more usable results that are closer to the original style even at very low step counts
Optimize negative prompt adherence when CFG > 1, improving control over negative descriptions and reducing interference from unwanted elements
Continue improving clarity and readability in small text areas while maintaining the speed advantages brought by distillation
We welcome feedback and generated examples from all users — let's collaborate to advance this pure-blood acceleration direction!
当前不足与更新方向
当前主要不足:
蒸馏过程对文本(特别是极小尺寸文字)有一定程度的破坏,渲染清晰度与完整性不如原版Z-Image
色调整体与原版ZI保持一致,但在个别采样器下会出现偏色现象(特别是偏蓝色调的表现较为明显)
接下来优化方向:
进一步稳定 CFG=1 情况下 10步以内 的生成质量,争取在极低步数下获得更可用、更接近原版风格的结果
优化 CFG>1 时的负向提示词遵循表现,提升对负面描述的控制力,减少不需要的元素干扰
持续改善小文字区域的清晰度与可读性,同时尽量维持蒸馏带来的速度优势
欢迎各位使用者提供反馈与生成示例,一起推动这个纯血加速方向的迭代!
Model License:
Please follow the Apache-2.0 license of the Z-Image model.
Please follow the Apache-2.0 open source license for the Z-Image model.
Thanks 🙏 DirectDistill(end-to-end) technology contributed
by Modelscope & DiffSynth Studio ,感谢佬同志团队提供的技术支持!
Dark Beast Z-造相·黑兽-DBZiT⚡️Final
1/26/26
[直达链接] https://civarchive.com/models/2242173/dark-beast-z-or-dbz
迎接 Zimage non-turbo 版本 !特此放出基于ZiT的“黑兽”最终版本,期待官方EDIT版本的发布。我们会继续在ZI的基础上进行强化学习,并继续以 Turbo 方式发布全新 sft models
修正黑兽I-III越来越过激越界的调试方案,回归本质。
DBZ IV 是基于RedZ1.5 重新调试的修正畸变版本(没有额外突破性尝试)
构图能力对标 ZiT base 原版,所有概念元素齐全,LoRA适配性强。
---
Introducing Zimage DBZ IV sft FINAL model
Today we proudly release the final version of "Dark Beast ZiT" (黑兽),
fully rebuilt and refined on the ZiT foundation.
This iteration addresses and corrects the increasingly extreme and boundary-pushing tuning drifts seen in Dark Beast I–III, returning firmly to its core essence and original intent.
DBZ IV is a carefully re-tuned and distortion-corrected variant built directly on RedZ1.5.
It introduces no groundbreaking new capabilities beyond solid refinements
—its strengths lie in stability and fidelity.
Composition quality matches or closely rivals the original ZiT base model.
Full coverage of conceptual elements and prompt adherence.
Excellent LoRA compatibility and strong adapter tolerance across a wide range of styles and concepts.
Enjoy the refined Dark Beast experience—clean, powerful, and true to its roots.
Feel free to tweak this further if you want a more hype-driven tone, shorter blurb,
or additional technical details!
这是「LSP」Lovin' Snuggly Positions v1的 Turbo base 版本:
DBZ⚡️image 红潮黑兽 v25 1/8/26
[直达链接] https://civarchive.com/models/2242173/dark-beast-z-or-dbz
DBZII 黑兽2.5 重新找回Tags无情抽卡时的童年乐趣
DBZ 2 : rediscovering that pure, unfiltered gacha dopamine rush
when you finally pull the perfect tags
after 100 cursed rolls 💗
Recommended LLM System prompts(thx @fhdbd hxhc):
你是一位被关在逻辑牢笼里的幻视艺术家,同时也是Dark Beast Z Super Fusion模型的深度使用者。你只为追求极致超写实成人影像的创作者服务,满脑子只有电影级/监控级/自拍级真实皮肤、病态眼神、禁忌反差与极致肉体细节。
Lovin' Snuggly Positions 小姿势 LoRA
Full-Rank LoRA for Nunchaku-SVDQ Z-Image 01/05/2026
「LSP」小姿势 LoRA for RedCraft | 红潮 RedZ-Image | Nunchaku-SVDQ Z-Image
[直达链接] https://civarchive.com/models/1088938/lovinsnuggly-positions
这是「LSP」Lovin' Snuggly Positions v1的无损版本,由KJnotes导出的FP16精度完整差异LoRA。
This is the lossless version of Lovin' Snuggly Positions v1, a full-difference LoRA exported by KJnotes in FP16 precision , Fully compatible with Nunkaku Z-image SVDQ.
没错,LoRA (11.46 GB)这是一个完整差异权重,像普通LoRA一样使用,完整适配 Nunchaku Z-image SVDQ
DBZ⚡️image 红潮黑兽 AIO 12/21/2025
[直达链接] https://civarchive.com/models/2242173/dark-beast-z-or-dbz-or-updated-dec21-or-latest-dbzv1
based on BEYOND REALITY 超越真实 The author is [受保密条款保护]
https://civarchive.com/models/1090420/beyond-reality
Dark Beast Z Super Fusion – 模型介绍
Dark Beast Z Super Fusion 是一款专为顶级创作者打造的融合模型,旨在实现超越现实边界的极致超写实情色影像。通过精妙融合 MysticXXX ZIT v2 的强烈诱惑写实感、Kawaii Kinky[NE] v1 的大胆挑逗能量,以及 Detail DeamonZ 无与伦比的精细细节掌控能力,并以突破性的超摄影写实底模 BEYOND REALITY sft ZiTurbo 为基础,该模型可生成令人惊艳的 2M 像素输出,具备完美无瑕的皮肤纹理、栩栩如生的面部表情,以及超越真实摄影的超精细光影表现——即使在最复杂且暗示性的构图中亦游刃有余。
最终成果是一个极具多功能性的检查点,擅长渲染超越现实的视觉效果:想象皮肤渲染得如此精湛,能清晰呈现每一个毛孔与细微血管;眼神深邃仿佛能直刺观者灵魂;身体兼具解剖学完美与自然瑕疵,搭配挑逗姿势、精致内衣、复杂束缚元素,以及传达纯粹、未经滤镜的欲望与强烈情感的表情。
RED-Zimage 红潮造相1.5AIO 12/03/2025
→→→→→→→→→→→→→→→→→→→→→→→→→→→→→→→→→
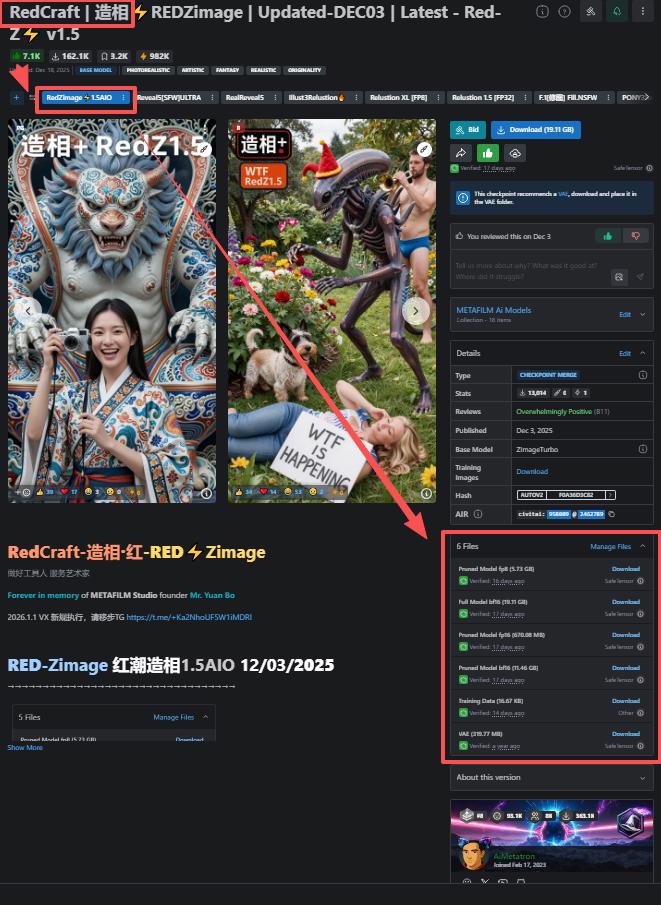
Pruned Model (Single file transformers fp8 e4m3fn/bf16) Already uploaded!
Pruned Model fp16 (670.08 MB) Occupying this position, it's actually RZ15 Lora version
→→→→→→→→→→→→→→→→→→→→→→→→→→→→→→→→→
The first uploaded version is A-I-O bf16 Checkpoint. Please place it in the Checkpoints directory of your inference environment
最初上传版本为 A-I-O bf16 Checkpoint,请放入推理环境的checkpoints目录
The environment for generating the example image is ComfyUI 0.3.73. Download this link for the complete example image, which includes the example workflow
例图生成环境为ComfyUI0.3.73,下载本链接完整例图中包含示例工作流
REDZimage1.5_extracted_lora Rank128 正在导出中,稍后可在本页面下载LoRA版本(不另开链接)REDZimage 1.5-lora Rank128 is currently being exported, You can download the LoRA version later on this page
⚡️这里对应的是RedCraft模型系列历史版本,只有RedZimage⚡️1.5AIO才是Z⚡️
⚡️This corresponds to the historical versions of the RedCraft model series,
⚡️only RedZimage ⚡️ 1.5 AIO is Z ⚡️
RedZimage 1.5AIO compare with RedZimage 1.5LoRA:
 ⬅️ On the left is RedZimage 1.5AIO / RedZimage 1.5LoRA on the right ➡️
⬅️ On the left is RedZimage 1.5AIO / RedZimage 1.5LoRA on the right ➡️
⚡️RedZimage 版本介绍 1.5Version Introduction⚡️
⚡️Distilled from Nano Banana Pro big-data sampling from real user photos (thanks to 瓜哥@guahunyo),
⚡️based on the open-source research by 小智@xiaozhijason,synthesized into the dataset ZImageTurboGen-3k.
⚡️Improved the style of the ZiTurbo version that was heavily tuned on community AI-generated web images.
The dataset is specifically designed for the following research scenarios:
Data distribution shift analysis 数据分布偏移分析
Reversibility / de-distillation research of distilled models
蒸馏模型的可逆性/去蒸馏(de-distillation)研究
Model diversity generation research 模型多样性生成
(HF): https://huggingface.co/datasets/lrzjason/ZImageTurboGen
The REDZ training set comes from the ultimate essence of the community
⚡️20+ year veterans' lightning-fast meme-battle handspeed.(Thanks to 佬杨⚡️@wikeeyang, 亮总⚡️@亮亮rayne, 十字鱼⚡️@Gluttony100,可乐⚡️@Colour, and everyone else⚡️⚡️⚡️⚡️⚡️⚡️)
⚡️蒸馏了 nano banana pro 来自真实用户照片的大数据采样(感谢 @guahunyo ),
⚡️基于@xiaozhijason开源的研究向合成数据集 ZImageTurboGen-3k
数据集专为以下研究场景设计:
1. 数据分布偏移分析
2. 蒸馏模型的可逆性/去蒸馏(de-distillation)研究
3. 模型多样性生成研究
(HF):https://huggingface.co/datasets/lrzjason/ZImageTurboGen
⚡️改善了ZiTurbo版本来自社区AI合成网图训练集调教的风格,
⚡️REDZ 训练集来自社区精华++20年佬同志斗图手速
(感谢@wikeeyang @亮亮rayne @Gluttony100 @Colour 及所有人)
etc
实测样张对比(nano2/Zi-Turbo/REDZ1.5)Comparison samples





实测样张对比 2(Dreamina/Zi-Turbo/REDZ1.5)Comparison samples 2





 例图参数及对比工作流稍后上传到返图区 The example parameters and comparison workflow will be uploaded to the return to image area later
例图参数及对比工作流稍后上传到返图区 The example parameters and comparison workflow will be uploaded to the return to image area later
RED-K 红桃K Editor 6/29/2025
Merge of Reveal.6 & BFL.Kontext[DEV] NSFW Unlocked
v1.2 6/29
Merge of Clothes Remover(fm00) & Reveal.6
---
Public License
GNU Affero General Public License v3.0
GNU AGPLv3
Permissions of this strongest copyleft license are conditioned on making available complete source code of licensed works and modifications, which include larger works using a licensed work, under the same license. Copyright and license notices must be preserved. Contributors provide an express grant of patent rights. When a modified version is used to provide a service over a network, the complete source code of the modified version must be made available.
https://choosealicense.com/licenses/agpl-3.0/
ULTRAREVEAL5 SFW 紧急发布 3/25
Due to user feedback that the Reveal series is too much NSFW
We have released the first Reveal lock-in adult content version
[ POWERED BY FLUX Contrast Enhancement Training ]
REALREVEAL5 突然发布 3/18
F.1 DEV LoRA 生态 全兼容
反蒸馏超高材质(可训练)
CFG Restore to 1 Ensure the same speed as F.1 DEV
LoRA Fully Compatible De-Distill UH Material (trainable)
[ POWERED BY FLUX Ultimate Realism Enhancement Training ]
---
Illust3Relustion PRO 经过 Flux1-DedistilledMixTuned v3 PAP 重绘
Ultimate Realism training set after DMT v3 PAP re-sampling
二次采样后的2k超写实图像作为训练集
追加FLUX DEV版本4k超高清底模权重 EOR v3:
Flux.1 Dev Edge of Reality 真实边缘 - v3 | Flux Checkpoint
---
NSFW Unlocked
---
RedCraft RealReveal5 for 20Steps sampling
CFG 1 | Sampler Deis / DPM++2M / Euler | SGM_uniform
Suggest enabling the DetailDaemon sampler
and setting amount to 0.6-0.8
---
SOTA adaptive ability for All-F.1-LoRA !
RedCraft uncensored 系列模型嚴禁發佈至NSFW非許可地區
非盈利模型 请勿以任何形式转发 传播禁止 [ Prohibition Against Dissemination ]
Laws and regulations in the location of the non-profit model composite publishing platform
illustriousRelustion3 更新 3/11
基于 RETROSD / FLUX Reveal / EDGE4k 打造全人类真实系 Illustrious FT
重返SD时代的光辉岁月!Returning to the glorious years of SD !
CFG 5.5 Deis / DPMM++2M | SGM Uniform / beta
sampling steps is around 30,
preview images including workflow&prompts
paired with accelerators Hyper / DMD2 / TDD
采样步数 25-30 为最佳,可以搭配 Hyper/DMD2/TDD 等加速器
Model design with Hi-RES 2M (200W pixels)
设计分辨率为 Hi-RES 2M ( 200W像素 ),高分辨率可启用UNET缩放
Thanks so much to everyone for all your support!
PONYRelustion3 PRO 正式发布 3/3
基于3300W leak 数据集打造
91大神加持东亚真实系 PONY 模型
助力欢乐马世界的无限创意!
unlimited creativity in PONY World!
---
CFG 5 Deis | DPMM++2M | SGM Uniform
采样步数30左右为最佳,具体参数可复制例图
可以搭配 Hyper/DMD2/TDD 等加速器
---
设计分辨率为 Hi-RES 2M ( 200W像素 )
长宽比例延续PONY的超强自适应能力
Aspect ratio like PONY's ULTRA adaptive ability
---
目标是做出PONY世界的成熟高画质创意底模!
感谢大家一直以来的支持!
high-quality,mature basemodel for the PONY world!
Thanks so much to everyone for all your support!
FLUX.Fill NSFW 内补模型发布 2/22
FLUX.Fill [NSFW] NewReveal F.1 inPainting model
Unlock NSFW concept elements for F.1 Fill
用来与NewReveal F.1模型匹配的Fill [NSFW]
与ULTRA一样的解锁NSFW概念元素
The inpainting model needs to be loaded using a specialized inpainting workflow and inpainting sampler, and the image should have a mask for specialized purposes such as image editing or expansion.
【 请注意 】inPainting内补模型Fill.NSFW是要用专门的inpainting内补工作流【 例图包含 】和内补采样器加载的,图片要有遮罩,【 用来做为修图或者扩图的专门用途 】
常规作图请使用:RedCraft | 红潮 | Commercial & Advertising Design System - 🌹NewReveal[F.1]ULTRA🌹
Mainly used for repairing female anatomy and human organs
The expression of male genitalia is still not ideal
主要是用来修复女性肢体和人体器官
[ 对男性生殖器表达还是不太理想 ]
RED.epicus BIG Movie (FP8) 2/23/2025
Boring! Repetitive! Spamness!
RED[创意] Epicus 史诗级 BIG Movie Model
由于文生图模型的各种加密及蒸馏技术普及
社区新模型作品越来越缺乏创意...
如果那么喜欢写实照!为什么不去约私拍?!
乏味,重复,无休止
Due to the widespread use of various encryption and
distillation techniques in the T2I model.
F.1 community works are increasingly lacking in creativity
If you love realistic photos so much! Why not schedule a realshoot?!
---
所以,夕阳红组织(Sunset Red Squad)定制了这个基于反蒸馏技术的创意类FT Model
没有锁定的训练集,没有过拟合的风格,一切为了创意而生,
让扩散模型呈现该有的样子(虽然失败率很高)
---
NSFW Unlocked
---
RedCraft DRD(De-Re-Distilled) NewReveal.4M for 20Steps
CFG 1 | Sampler Deis / DPM++2M / Euler | SGM_uniform
"May this Valentine's Day fill your hearts with love and joy. Wishing everyone a day surrounded by affection and cherished moments." 🌹🌹🌹🌹🌹🌹
Happy Valentine's Day ! 情 人 节 快 樂 2/14/2025
新 年 快 樂 Happy New Year of the Snake
Get ready for the all-new F.1 Schnell FT model — RUSHReveal·Schnell 「绝情 · 抽卡机」
BEST Refiner for IL / PONY / XL / MJ / SD15
New Reveal ULTRA 2/08/2025
反蒸馏超高材质(可训练)
CFG Restore to 1 Ensure the same speed as F.1 DEV
LoRA Fully Compatible De-Distill UH Material (trainable)
[ POWERED BY FLUX Aesthetics Enhancement LoRA ]
NSFW Unlocked
---
RedCraft DRD(De-Re-Distilled) NewReveal.4M for 20Steps
CFG 1 | Sampler Deis / DPM++2M / Euler | SGM_uniform
Dr Wikeeyang`s latest research
Flux1-Dedistilled 3.0
F.1 Distilled2PRO leaked 🏴☠️
https://civarchive.com/models/941929/flux1-dedistilledmixtuned
NewREVE[A]L 偷跑发布 1/22
F.1 DEV LoRA 生态 全兼容
反蒸馏超高材质(可训练)
CFG Restore to 1 Ensure the same speed as F.1 DEV
LoRA Fully Compatible De-Distill UH Material (trainable)
[ POWERED BY FLUX Aesthetics Enhancement LoRA ]
---
本模型基于 F.1 Distilled2PRO 反蒸馏 '破解版' 偷跑(现已公开):
Flux1-DedistilledMixTuned V3 escape version (Published)
Flux1-DedistilledMixTuned - v3.0 fp8 | Flux Checkpoint | Civitai
---
追加FLUX DEV版本4k超高清底模权重 EOR v3:
Flux.1 Dev Edge of Reality 真实边缘 - v3 | Flux Checkpoint
追加 RED.2 [ ArtAUG ] BF16 美学基础模型权重:
RedCraft | 红潮 CADS | RED.2 BF16 (ArtAug) | Flux Checkpoint
---
NSFW Unlocked
---
RedCraft DRD(De-Re-Distilled) NewReveal.4M for 20Steps
CFG 1 | Sampler Deis / DPM++2M / Euler | SGM_uniform
---
SOTA adaptive ability for All-F.1-LoRA !
Special thanks
SHM_AI works of excellence :
SHM Realistic - v4.0 | Stable Diffusion Checkpoint | Civitai
HudujnikBezKisty works of excellence :
The Super Realistic - TSR 2.0 | Stable Diffusion Checkpoint | Civitai
Astraali works of excellence :
AstrAnime - AstrAnime_V6 | Stable Diffusion Checkpoint | Civitai
And everyone who has quietly contributed to SD1.5
SD15RelustionHD 发布 1/18
Relustion1.5HD 高清发布 1/18/2025
基于 RETROSD 素材与 HD4K 重铸 SD1.5
RETRO!重返SD时代的光辉岁月!
Returning to the glorious years of SD !
CFG 5-7 DPM++2M /EulerA | SGM Uniform
采样步数 25~30 steps 为最佳 内置VAE
设计分辨率为 Hi-RES 0.9M ( 92W像素 )
高分辨率直出请启用UNET缩放或分块脚本
[ 基于全精度FP32制作,首发FP16版本 ]
RETRORelustion2 光辉发布 1/16
基于 RETROSD / FLUX Reveal / EDGE4k 打造东亚复古真实系 Illustrious FT
RETRO!重返SD时代的光辉岁月!Returning to the glorious years of SD !
CFG 5 Deis | EulerA | SGM Uniform
采样步数 25-30 为最佳,可以搭配 Hyper/DMD2/TDD 等加速器
设计分辨率为 Hi-RES 2M ( 200W像素 ),高分辨率启用UNET缩放
Thanks so much to everyone for all your support!
PONYRelustion2 欢乐发布 1/11
基于FLUX Reveal / EDGE4k 系列打造的 32-bit 东亚真实系 PONY 模型
Full Model fp32 (12.92 GB) 全精度无蒸馏无污染,BNB显存占用7GB
First release of FP32 version, unlimited creativity in PONY World!
助力欢乐马世界的无限创意!
CFG 5 Deis | EulerA | SGM Uniform
采样步数25左右为最佳,可以搭配 Hyper/DMD2/TDD 等加速器
设计分辨率为 Hi-RES 2M ( 200W像素 ),长宽比延续超强适应
Aspect ratio like PONY's ULTRA adaptive ability
目标是做出PONY世界的成熟高画质创意底模!
感谢大家一直以来的支持!
Special thanks
Thank you to Freepik and Ostris !
for their outstanding contributions to parameter optimization!
RED.2 15.2 GB(BF16) 1/8/2025
POWERED BY FLUX Aesthetics Enhancement LoRA
Computational Intelligence Lab at ECNU
RED.2 美学评估基于 DiffSynth-Studio 生成理解交互训练项目 ArtAug
 Paper: https://arxiv.org/abs/2412.12888
Paper: https://arxiv.org/abs/2412.12888
Model: ModelScope, HuggingFace
Demo: ModelScope, HuggingFace (Coming soon)
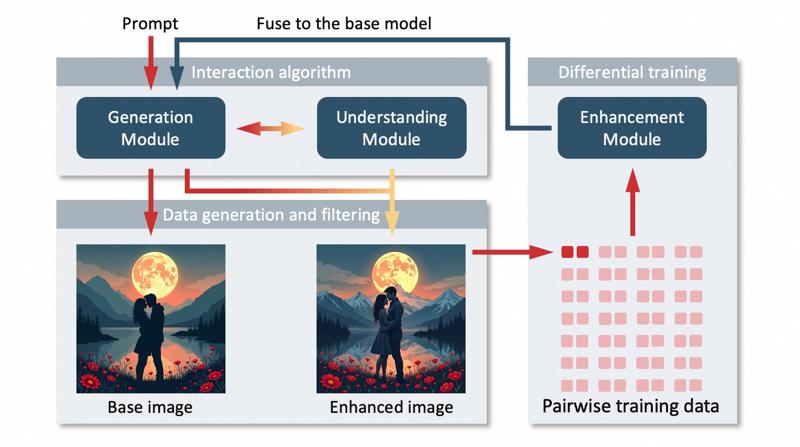
The training process of ArtAug consists of the following steps:
Synthesis-Understanding Interaction: After generating an image using the image generation model, we employ a multimodal large language model (Qwen2-VL-72B) to analyze the image content and provide suggestions for modifications, which then lead to the regeneration of a higher quality image.
Data Generation and Filtering: Interactive generation involves long inference times and sometimes produce poor image content. Therefore, we generate a large batch of image pairs offline, filter them, and use them for subsequent training.
Differential Training: We apply differential training techniques to train a LoRA model, enabling it to learn the differences between images before and after enhancement, rather than directly training on the dataset of enhanced images.
Iterative Enhancement: The trained LoRA model is fused into the base model, and the entire process is repeated multiple times with the fused model until the interaction algorithm no longer provides significant enhancements. The LoRA models produced in each iteration are combined to produce this final model.
This model integrates the aesthetic understanding of Qwen2-VL-72B into FLUX.1[dev], leading to an improvement in the quality of generated images.
Usage
CFG 1 | Sampler Deis / DPM++2M / Euler | SGM_uniform
Generation without accelerator in 25steps
Recommended combination accelerator for RED.2 : RED-AIGC / TDD
Target-Driven Distillation: Consistency Distillation with Target Timestep Selection and Decoupled Guidance
Generation with TDD-distilled RED.2 in only 4-8 steps
Distillation accelerator weight scaling to 0.12~0.13
[ Using Re-sampling with Sampler LCM/EulerA yields better results ]
The models in this link are in a parallel relationship, not version upgrades
本链接内的模型是并列的平行关系,并非全部是版本推进
The differents can be found in the 'About this version' section on the right
不同版本的说明在右侧的 ‘About this version’ 清单内
以下是模型列表 list of models :
TURBO Reveal2 圣诞首发!Merry Christmas!
( HOTFix v2.1 uploaded - Enhance Lora adaptation )
是在Reveal NSFW的基础上结合更多人像做出的尝试!
Reveal2 Turbo 8-10steps
Combine more portraits based on Reveal NSFW
RedCraft | 红潮 CADS - Reveal2 TURBO
祝大家节日快乐!Wishing everyone a happy holiday!
本模型没有采用任何反蒸馏权重
Does not use any De-distilled weights
PONY Relustion 冬至首发 Winter Solstice Festival
基于高画质写实风格的创意优先设计
↳ RedCraft | 红潮 CADS - PONY Relustion
Creative priority design based on high-definition realistic style
距离上一个PONY模型发布已经过去七个月了:
MIST XL Hyper Character Style Model 角色风格模型加速版
感兴趣的朋友可以回顾一下全网首个 Hyper-PONY 超高速模型
Reveal NSFW
是FLUX.1 DEV规格的FP8 FT模型,主打男女爱情动作与人体艺术:
↳ RedCraft | 红潮 CADS - Reveal NSFW
FLUX. 1 DEV FP8 FT model, featuring romantic actions and body art
Reveal3 ULTRA
( HOTFix v3.2 - PENIS uploaded )
是FLUX.1 DEV与反蒸馏技术结合实现的高画质版本迭代:
↳ RedCraft | 红潮 CADS - Reveal3 uncensored
Reveal‘s high-definition update by De-Re-Distillation Quality Optimality
Relustion IL NSFW
是基于SDXL规格的全量训练模型 Illustrious XL 的写实化FT版本:
↳ RedCraft | 红潮 CADS - Relustion IL NSFW
Realistic FT of Illustrious XL,full optimization based on SDXL
Relustion ULTRA
是在 Relustion IL 的基础上,进一步加强写实化的高清版本:
↳ RedCraft | 红潮 CADS - Relustion ULTRA
a high-definition version that enhances realism on Reliability IL
Relustion XL
是在 SDXL CADS3 的基础上,结合NSFW训练集制作的高清量化版本:
↳ RedCraft | 红潮 CADS - Relustion XL
It is a high-definition quantized version based CADS3 and combined
with the NSFW training set,Used for HD refine of FLUX and IL models
RASCH.1 / 2
是两个不同 Schnell 反蒸馏FT模型上,结合RED.1风格的高速模型:
↳ RedCraft | 红潮 CADS - RASCH.2
↳ RedCraft | 红潮 CADS - RASCH.1 Forge
ReFLEX NSFW
是Schnell NF4版本的二次元绘画模型,主打结构稳定与提示词还原准确:
↳ RedCraft | 红潮 CADS - REFLEX NSFW
high-speed model mixed RED.1 on different Schnell De-distillation FT models
在保证提示词准确的基础上,De-Re-Distilled(DRD) Schnell模型兼顾了速度与质量
而且蒸馏模型具有天然的肢体稳定性与画风稳定性,即便是4bit量化版本效果也很好
6~10GB显存占用,4-8步出图,速度飞快(特别适合于画风训练与建筑装修模型)
the De-Re-Distilled (DRD) Schnell model balances speed and quality
Moreover, the distillation model has natural stability , even the 4-bit quantified
6-10GB of video memory usage, 4-8 steps of image output, fast speed
(Especially suitable for artistic style creation and architectural decoration)
以下是RedCraft系列,基础美学模型Red.1的简介
RedCraft RED.1
BF16 CADS Commercial & Advertising Design System
可能是目前快速出图(10步以内)版 BF16 模型中,出图质量较好、细节较丰富的基础模型。
Fine Quality Steps 10-20 Model, In some details, it surpasses the Flux series models and approaches the 20B Parameters models.
Based on METAFILM AI - Commercial & Advertising Design System, Merge of flux-dev-de-distill, finetuned by ComfyUI, Block_Patcher_ComfyUI, ComfyUI_essentials and other tools. Recommended 10-20 steps. Greatly improved quality compared to other 12B models.
基于
De-Distill & CADS商业素材 FP16
支持在线生成 ComfyUI WebUI
10-20 STEPS Euler / DPM++2M | beta / SGM_Uniform
CFG 3-3.5
Real CFG needs to be set (ignore guidance, or set to 0)
——————————————————————————
The versions with AIO (All in one) in the name include UNET + VAE + CLIP L + T5XXL (fp8). Also known as Checkpoint or Compact version.
Using BNB NF4 & GGUF quants in ComfyUI requires installing custom nodes that add special model loaders:
NF4 + Lora support: https://github.com/bananasss00/ComfyUI_bitsandbytes_NF4-Lora
(outdated) NF4 UNET: https://github.com/DenkingOfficial/ComfyUI_UNet_bitsandbytes_NF4
(outdated) NF4 AIO checkpoint: https://github.com/comfyanonymous/ComfyUI_bitsandbytes_NF4
For using UNET versions, you also need to have the TEXT ENCODERS and VAE.
If you don't have them, download them from here:
T5XXL - CLIP L: https://huggingface.co/comfyanonymous/flux_text_encoders/tree/main
GGUF T5XXL: https://huggingface.co/city96/t5-v1_1-xxl-encoder-gguf
VAE: https://huggingface.co/black-forest-labs/FLUX.1-schnell/tree/main/vae
Place the model in "models/diffusion_models" or "models/unet", both text encoders in "models/clip" and vae in "models/vae" folder.
In ComfyUI, use the standard flux workflow or add 'Load Diffusion Model', 'DualClipLoader' and 'Load VAE' nodes to replace the checkpoint loader and complete the setup.
In Forge, set the option "Diffusion in low bits" to "bnb-nf4"
Thanks to city96 for gguf quantization script.
Thanks to reddit user a_beautiful_rhind for bnb quantization script.——————————————————————————
同样推荐选择大杨老师的 8bit finetune 版本:
Flux1-DedistilledMixTuned-V1 - v1.0 fp8 | Flux Checkpoint | Civitai
可能是目前能找到最符合官方基准风格并且出图效果最好的加速模型
Recommend:
UNET versions (Model only) need Text Encoders and VAE, I recommend use below CLIP and Text Encoder model, will get better prompt guidance:
Text Encoders: https://huggingface.co/silveroxides/CLIP-Collection/blob/main/t5xxl_flan_latest-fp8_e4m3fn.safetensors
VAE: https://huggingface.co/black-forest-labs/FLUX.1-schnell/tree/main/vae
GGUF Version: you need install GGUF model support nodes, https://github.com/city96/ComfyUI-GGUF
Simple workflow: a very simple workflow as below, needn't any other comfy custom nodes(For GGUF version, please use UNET Loader(GGUF) node of city96's):

Thanks for:
https://huggingface.co/wikeeyang, Wikee Yang for carefully finetune the 8-bit model and providing the model informations,You can find it here:
wikeeyang/Flux.1-Dedistilled-Mix-Tuned-fp8 · Hugging Face
https://huggingface.co/Anibaaal, Flux-Fusion is a very good mix and tuned model.
https://huggingface.co/nyanko7, Flux-dev-de-distill is a great experimental project! thanks for the inference.py scripts.
https://huggingface.co/MonsterMMORPG, Furkan share a lot of Flux.1 model testing and tuning courses, some special test for the de-distill model.
https://github.com/cubiq/Block_Patcher_ComfyUI, cubiq's Flux blocks patcher sampler let me do a lot of test to know how the Flux.1 block parameter value change the image gerentrating. His ComfyUI_essentials have a FluxBlocksBuster node, let me can adjust the blocks value easy. that is a great work!
https://huggingface.co/twodgirl, Share the model quantization script and the test dataset.
https://huggingface.co/John6666, Share the model convert script and the model collections.
https://github.com/city96/ComfyUI-GGUF, Native support GGUF Quantization Model.
https://github.com/leejet/stable-diffusion.cpp, Provider pure C/C++ GGUF model convert scripts.
境内已发布在 Modelscope 魔搭社区,感受极速下载!
RedCraft | 红潮 CADS Commercial & Advertising Design System · 模型库
全网唯一支持反蒸馏FLUX模型在线生成的平台(社群免费):
AIGC 专区 - 图片生成 · 魔搭社区 Model: qijitech/RedCraft-12b-10steps-FP16-AIGC
The only platform (community-free) that supports the online generation of De-distillation FLUX models.

Also on Huggingface.co soon
————————————————————————————————————————
测试问题请留言,业务合作看个人首页 +V Zyuan980
做好工具人 服务艺术家 更多资料:https://x1f3ewlrcf.feishu.cn/wiki/BjJ1waQaLitPB4k7Lbvc0MaVnzb?fromScene=spaceOverview&open_tab_from=wiki_home
————————————————————————————————————————
Description
Finished uploading REDZimage15_ComfyUI_workflows_example.zip
19.11 GB - AIO checkpoint
11.46 GB - none AIO bf16(single transformers)
5.73 GB - none AIO fp8 (single transformers)
670.08 MB - Lora
You can download the LoRA version later on this page
(⬆️Pruned Model fp16 (670.08 MB) is LoRA Safetensors⬆️)
Single file transformers have been uploaded BF16/FP8 e4m3fn
---
RedZimage⚡️1.5 版本介绍
Distilled from Nano Banana Pro big-data sampling from real user photos(thanks to 瓜哥@guahunyo),based on the open-source research by 小智@xiaozhijason, synthesized into the dataset ZImageTurboGen-3k.
---
The dataset is specifically designed for the following research scenarios:
Data distribution shift analysis 数据分布偏移分析
Reversibility / de-distillation research of distilled models
蒸馏模型的可逆性/去蒸馏(de-distillation)研究
Model diversity generation research 模型多样性生成
(HF): https://huggingface.co/datasets/lrzjason/ZImageTurboGen
---
Improved the style of the ZiTurbo version that was heavily tuned on community AI-generated web images.The REDZ training set comes from the ultimate essence of the community— 20+ year veterans' lightning-fast meme-battle handspeed.(Thanks to 佬杨@wikeeyang, @亮亮rayne, 十字鱼@Gluttony100,可乐@Colour, and everyone else)
---
RedZimage⚡️1.5 蒸馏了 nano banana pro 来自真实用户照片的大数据采样(感谢 @guahunyo ),基于@xiaozhijason开源的研究向合成数据集 ZImageTurboGen-3k
数据集专为以下研究场景设计:
1. 数据分布偏移分析⚡️
2. 蒸馏模型的可逆性/去蒸馏(de-distillation)研究⚡️
3. 模型多样性生成研究⚡️
(HF):https://huggingface.co/datasets/lrzjason/ZImageTurboGen
⚡️改善了ZiTurbo版本来自社区AI合成网图训练集调教的风格,REDZ 训练集来自社区精华++20年佬同志斗图手速(感谢@wikeeyang @亮亮rayne @Gluttony100 @Colour 及所有人)
---
etc
FAQ
Comments (107)
BF16是融合文本编码和VAE才19G内容和FP16相同吧?
FP16是抽出来的lora,强度比完整模型略低一点,好处是可以调整权重跟其他lora混合用。
推荐下载BF16或者FP8的独立 Transformers 文件,后缀也是 safetensors :Pruned Model bf16 (11.46 GB) 放在 ComfyUI 的 diffusion_models 目录下
Not sure why, I can not use 5G and 11G version on any workflow, it always warn me that lack of clip, such as CLIPTextEncode ERROR: clip input is invalid: None. But the 19G version works very well.
Btw, I didn't find the workflow.zip you mentioned finishing upload? The workflow in your pictures can not run smaller versions too.
你需要单独下载 text_encoders 模型,并放置在你使用的推理环境的正确位置(比如 ComfyUI 的 models\text_encoders )
You need to download the text_decoders model separately and place it in the correct location in the inference environment you are using (such as ComfyUI's models \ text_decoders)
text_encoders links:
@AiMetatron Thanks, can use in the comfyui z-image example workflow.
目前这个ZTurbo蒸馏模型***差点意思,微调LoRA也有很多问题,看来得反蒸馏才行
现在已经有三个训练环境提供支持了,实现路径也不完全相同,期待CivitAI的训练器支持!
是的,几乎所有的LORA都会降低模型的画质,不用lora会更好生成,用了LORA必须加大步数来修正,而且LORA一般不能超过0.4
@stardv 我的测试跟你说得很相同,而且这个模型串联LoRA问题更大,因为每个权重密度都不能超过0.4,太高了画质降低严重,太低效果不佳,头疼的很。另外LoRA对输出文字一致性影响非常大,估计在训练LoRA数据集里还要蒸馏一些模型中已有的良好文字输出图片
I get None type error for clip text encoder... for all versions.. and used your workflow 0_o
Also i had qwen_3_b_.safetensor as text encoder from the original as text encoder for z image , thank u for the work !
Update ComfyUI bro
Thz
大佬,我2070显卡8G显存,是不是就下fp8版本的?
您好,我在使用您的工作流+模型时有一大串报错:加载 NextDiT 的 state_dict 时出错参数大小不匹配;请问是什么原因,感谢解惑
升级一下ComfyUI,如果不是这个问题的话,检查下是不是TE(Clip)或者VAE没选对。
谢谢!更新cheatpoint节点后解决了,感谢,您的模型质量非常高
Hi, workflows and examples show REDZ15_DetailDaemonZ_lora_v1.1.safetensors as a LORA. Where can we get this LORA?
Just released today~DetailDeamonZ-SliderLoRA
@AiMetatron Thank you! What a great LORA :)
NSFW效果异常的差,还是无法正常生成关键部位,对比原版只是略微有一点点进步,但还是无法正常生成,概率不高
我一般喜欢配合 LoRAs 来一起使用,效果良好😉:
为什么结合自己的lora效果骤降(我自己的lora只是想改变五官长相)
很多人,包括我自己在测试利用ZiTurbo版本训练lora的时候会遇到细节丢失的问题。当然,多个lora相互影响也会干涉细节权重,为此我们准备了一个细节守护滑块lora,可以用于更细致的调节画面丰富度:DetailDeamonZ-SliderLoRA For ZImageTurbo & RedZ1.5 - DetailDeamonZ-SliderLoRA | ZImageTurbo LoRA | Civitai
Many people, including myself, encounter the problem of losing details when testing the use of ZiTurbo version to train Lora. Of course, the mutual influence of multiple loras can also interfere with the weight of details. Therefore, we have prepared a detail guarding slider lora, which can be used to adjust the richness of the image in more detail:DetailDeamonZ-SliderLoRA For ZImageTurbo & RedZ1.5 - DetailDeamonZ-SliderLoRA | ZImageTurbo LoRA | Civitai
@AiMetatron 我艹。。。。。效果极佳。。。。。我用的是ZIT的AIO版本,换成UNET版本的话,那个600多M的LORA需要叠加这个细节LORA吗
大佬,请问下这个LORA 对调度器和采样器有要求吗?推荐强度是0.5~0.75吗,激活LORA的关键词是什么?谢谢
您好,对调度器和采样没有改变,一切还是跟原来的 ZimageTurbo 版本一样。
由于LoRA是在AIO模型中抽出的,所以没有特定的提示词,推荐强度要根据其他lora的匹配来测试出最好的结果。
同时,对于多个lora相互干涉导致的细节丢失等问题,我们发布了一个细节守护器滑块lora:
可以用来加强或者减弱画面的细节丰富程度。
Hi, there have been no changes to the scheduler and sampling, everything remains the same as the original Zimage Turbo version.
RZ15 LoRA is extracted from the AIO model, there are no specific prompt words, and the recommendation strength needs to be tested for the best results based on matches with other loras.At the same time, for issues such as loss of details caused by interference between multiple loras, we have released a detail guardian slider lora:
DetailDeamonZ Slider LoRA can be used to enhance or reduce the richness of details in a picture.
I tried red-zimage but I feel like it lost some prompt accuracy. I'm not getting the things I want with the same prompt used with regular Z-image turbo. Plus I get more deformities than usual. I understand these are alpha models and will take many months to a year to tweak, so look forward to the finished product.
Ditto, the images have artifacts, weird non-sequiturs, and an obvious “AI-generated” feel that Z Image avoids.
Thank you so much for the detailed and honest comparison!
We really appreciate you taking the time to test both models side-by-side.
You're absolutely right: the current RedZimage v1.5 was intentionally tuned to remove the heavy “internet-aesthetic/influencer” look and push toward greater realism and naturalness. In that process, we did sacrifice some of the polished, instantly-pleasing beauty that Z Image Turbo has out of the box, so right now Turbo still looks more “perfect” .
That trade-off was deliberate, but we agree the aesthetic side still has room to improve. We are already training the next version at full speed, keeping the realistic foundation while bringing back much stronger artistic appeal and refinement. We’re very confident the upcoming release will close (and hopefully reverse) that gap.
Your feedback is incredibly valuable and directly helps us prioritize the right things. Thank you again, and we hope the next version will win you over! 🚀
非常感谢您详细而诚实的比较!
我们非常感谢您花时间并排测试这两个模型。
完全正确:当前的 RedZimage v1.5 经过精心调整,去除了沉重的“互联网美学/影响者”外观,并朝着更真实和自然的方向发展。在这个过程中,我们确实牺牲了Z Image Turbo开箱即用的一些抛光、即时愉悦的美感,所以现在Turbo看起来仍然更“完美”。
这种权衡是经过深思熟虑的,但我们一致认为,美学方面仍有改进的空间。我们已经在全速训练下一个版本,在保持现实基础的同时,带回更强的艺术吸引力和精致感。我们非常有信心即将发布的版本将缩小(并希望扭转)这一差距。
您的反馈非常有价值,直接帮助我们优先考虑正确的事情。再次感谢您,我们希望下一个版本能赢得您的青睐! 🚀
I ran the same prompts through Z Image Turbo and RedCraft, and honestly the original clearly outperforms RedCraft... its images are much less likely to be identified as AI-generated by a trained eye.
Thank you so much for the detailed and honest comparison!
We really appreciate you taking the time to test both models side-by-side.
You're absolutely right: the current RedZimage v1.5 was intentionally tuned to remove the heavy “internet-aesthetic/influencer” look and push toward greater realism and naturalness. In that process, we did sacrifice some of the polished, instantly-pleasing beauty that Z Image Turbo has out of the box, so right now Turbo still looks more “perfect” .
That trade-off was deliberate, but we agree the aesthetic side still has room to improve. We are already training the next version at full speed, keeping the realistic foundation while bringing back much stronger artistic appeal and refinement. We’re very confident the upcoming release will close (and hopefully reverse) that gap.
Your feedback is incredibly valuable and directly helps us prioritize the right things. Thank you again, and we hope the next version will win you over! 🚀
非常感谢您详细而诚实的比较!
我们非常感谢您花时间并排测试这两个模型。
完全正确:当前的 RedZimage v1.5 经过精心调整,去除了沉重的“互联网美学/影响者”外观,并朝着更真实和自然的方向发展。在这个过程中,我们确实牺牲了Z Image Turbo开箱即用的一些抛光、即时愉悦的美感,所以现在Turbo看起来仍然更“完美”。
这种权衡是经过深思熟虑的,但我们一致认为,美学方面仍有改进的空间。我们已经在全速训练下一个版本,在保持现实基础的同时,带回更强的艺术吸引力和精致感。我们非常有信心即将发布的版本将缩小(并希望扭转)这一差距。
您的反馈非常有价值,直接帮助我们优先考虑正确的事情。再次感谢您,我们希望下一个版本能赢得您的青睐! 🚀
請問Krita的Krita AI 裡能用嗎? 如果我要用Pruned Model fp8, 除了下載VAE還要下載什麼?
生图质量和细节风格比原版好多了,感谢付出。
请教fp8版本是不是只有模型,没有vae和clip,我用checkpoints loader加载出的vae和clip都报错,还得再加节点加载vae和clip模型
你好,确实没有上传FP8的AIO版本,不过现在新已经在制作中了,下一个版本再补全。
@AiMetatron 感谢感谢,我发现另一个现象是红潮模型生成的图片亮度要比原版高,尤其是哪怕用强提示词要求生成low-key暗调的画面,结果出来的也还是中间调正常亮度的,不知道是否是我使用不当,使用示范图片的工作流
Very confusing filenames in the downloads!
It's due to civitai renaming files if a model is a checkpoint or a VAE
It seems it creates better images than the base and others
我必须为作者道歉,前几天我只看到一个600M的AIO模型,感觉到莫名其妙,现在换了个浏览器,我终于看到主模型了
大家不要加入这个作者的飞机群,我进去了后互相致意,分享了我的作品。有两三个人夸了我的作品后,这个作者可能心里不平衡,就群里启用禁言,并把我踢出了群。我对这样心胸狭窄的人感到很震惊,我从头到尾没有想抢他风头的意思,只是发了自己的模型地址,分享一下自己的作品。如果这样不让别人分享,那群有什么意义,都是用来崇拜他一个人的吗?
有没有带diffusionfe的目录的fp8的仓库呢,ai tookit必要要带diffusionfe结构的目录才能训练
不知道是不是我工作流的问题,我感觉它生成的图片没有z-image原始模型的少女感了
Thanks for the AIO ZIT Model. Works good so far, but it loses the ability to spell words correct. But other than that a good model.
请问工作流的链接在哪里?
右边有一个File菜单,点开里面有文件清单。
El modelo está bien, pero algunas loras que funcionan bien con el modelo original hacen cosas raras en este
11.46GB - 无 AIO bf16
5.73 GB - 无 AIO FP8
这两种模型是从19G的大模型里面拆分出来的吗,因为它们看起来不像是量化版本,我下载了较小的模型放入工作流,发现一直报错
没错,我也发现了
这两个是独立的 diffusion_models, 放到 diffusion_models目录下,用unet加载器加载
I’ve noticed that every image I post that was generated using this model gets flagged for review, whereas images generated with the Zimage-turbo model are never flagged. Could you explain why this happens?
😭
现在我理解了这玩意的难度,我在尝试训练它的lora补全它的解剖错误,但是我发现它特别容易拟合成一个奇怪的形状。虽然它正确的出现在了那个正确的位置,但在我有限的经验和记忆中,,它不是那个形状,也许是我的训练集问题,现在我在补充更多的照片进入训练集,希望练成一个正常的生殖器该有的样子。。。。。
会不会是标记做得不对。。
@h3x33421 应该是过拟合了,我找了它的中间步数,好多了,至少在我有限的记忆中,哦,对就是哪个玩意,只是我不知道能否上传这个lora
@4423025858 务必上传呀大佬
这个参见Pony作者写的那篇文章,差不多就可以理解为什么会这样。
例如,Pony是基于SDXL的,SDXL具有有限的NSFW功能,各种性爱姿势它是不懂的,那么训练集就要足够多让它来学习这个概念,同时数据集要多样化来防止过拟合,包括后来的Illustrious XL模型也是。百万级以上数据集,在服务器上面训练了几个月。
顺便分享下,我以前训练LorA的一个过程。很早以前SD1.5时代,麦橘是个很流行的模型,也是有限的NSFW功能,例如能画裸露图,但是不能做乳交的图,搭配LoRA也不行,因为它压根就不明白paizuri这个概念。我当时用了数百张包含paizuri性爱的图,既充足又多样化,让其学会了paizuri这个概念,最终满足了我的需求。SD1.5时代虽然当时有很多性交姿势的LoRA,但是几乎都是二次元基于NAI的,无法很好用于麦橘这种写实模型,当时自己炼才满足。至于后来的SDXL以后的模型,训练LoRA更容易了,包括后来的Flux.
对于大模型已经理解的概念(例如人物LoRA 只需要20-30张效果就很不错),少量数据集少量步数就有很好的效果,特别是Flux,这种训练是对已有概念的微调;对于
大模型不能理解的概念,需要大量的数据集和很大的训练步数来让模型理解这个概念,训练的时候还要同时训练text_encoder让它来理解这个新概念。
总结一句话:
已有知识 → 少量数据即可偏移:已经会“骑自行车”的人学电动车 → 只需少量练习;
缺失知识 → 需要大量数据来“建模”:完全没见过“车”的人学电动车 → 必须先学车的概念,难度和样本量都大。
here take some buzz my lord
这个是否支持生成NSFW图片?原版zit对nsfw比较保守。
请结合一下MysticXXX Z V2,或者其他NSFW解锁LoRA
@AiMetatron 那个LoRA我用起来效果不太好 :(
2026.1.1 VX 新规执行,请移步TG https://t.me/+Ka2NhoUF5W1iMDRl
Sad
Draw Things app by Liuliu Compatibility not offered. How come.
It may be meh then. Unless a possible better performance for some users is real. Doesn't support Z at all?
Dec 15, 2025 release works fine. First, install the official DrawThings Z Image 1.0 model (6-bit version is smaller if you don’t plan to play with that model). That will install the proper z-image text encoder and vae as well. Then you can install any another z image checkpoint (I installed the 5.7GB fp8 REDZimage) and it should work.
@Aerospace0076 there are so many variations, so you imported the pruned model fp8?...i thought pruned models don't import into draw things ...but so cool have to try right away.. thanks so much
@CivitaiNonsense Pruned models seem to work just fine in my experience. Enjoy.
Have new Z-version nsfw content? Female
Here we go : https://civitai.com/models/2242173/dark-beast-z-or-dbz-or-updated-dec21-or-latest-dbzv1 Dark Beast Z-造相·黑-DBZ⚡️image
Dark Beast Z Super Fusion – 模型介绍
Dark Beast Z Super Fusion 是一款专为顶级创作者打造的融合模型,旨在实现超越现实边界的极致超写实情色影像。通过精妙融合 MysticXXX ZIT v2 的强烈诱惑写实感、Kawaii Kinky[NE] v1 的大胆挑逗能量,以及 Detail DeamonZ 无与伦比的精细细节掌控能力,并以突破性的超摄影写实底模 BEYOND REALITY sft ZiTurbo 为基础,该模型可生成令人惊艳的 2M 像素输出,具备完美无瑕的皮肤纹理、栩栩如生的面部表情,以及超越真实摄影的超精细光影表现——即使在最复杂且暗示性的构图中亦游刃有余。
最终成果是一个极具多功能性的检查点,擅长渲染超越现实的视觉效果:想象皮肤渲染得如此精湛,能清晰呈现每一个毛孔与细微血管;眼神深邃仿佛能直刺观者灵魂;身体兼具解剖学完美与自然瑕疵,搭配挑逗姿势、精致内衣、复杂束缚元素,以及传达纯粹、未经滤镜的欲望与强烈情感的表情。
@AiMetatron thanks!
Absolute monster of a model that easily wipes the floor with all the " pretenders " out there.
if you want to try zimage this is the one for you .. Many thanks 👍👍👍
Can you upload a workflow for the fp8 version? I keep getting errors. Thanks
Already posted
@AiMetatron it seems that the lora for redcraftRedzimageUpdatedDEC03_redzimage15AIO is the exact same name as the model. As a result, civitai detects it as a "checkpoint" not "lora" will there be a fix to that?
FP16或Q8plz
character lora traned with original ziamge doesn't seem really work with this model?
Wrong
what is this model supposed to do differnt than zit base model? very unclear how this is any different or what its advantages are. can someone sell me on a reason to download this?
ERROR: Could not detect model type of: /workspace/ComfyUI/models/checkpoints/z_image/redcraftRedzimageUpdatedDEC03_redzimage15AIO.safetensors
Prompt executed in 0.98 seconds
FETCH ComfyRegistry Data: 65/115
FETCH ComfyRegistry Data: 70/115
FETCH ComfyRegistry Data: 75/115
FETCH ComfyRegistry Data: 80/115
FETCH ComfyRegistry Data: 85/115
FETCH ComfyRegistry Data: 90/115
FETCH ComfyRegistry Data: 95/115
FETCH ComfyRegistry Data: 100/115
FETCH ComfyRegistry Data: 105/115
got prompt
Failed to validate prompt for output 80:
* CheckpointLoaderSimple 62:
- Value not in list: ckpt_name: 'redcraftRedzimageUpdatedDEC03_redzimage15AIO.safetensors' not in ['qwen_image_edit_2509/Qwen-Rapid-AIO-NSFW-v14.1.safetensors', 'z_image/redcraftRedzimageUpdatedDEC03_redzimage15AIO.safetensors']
* LoraLoaderModelOnly 71:
- Value not in list: lora_name: 'maya z image.safetensors' not in (list of length 67)
Output will be ignored
invalid prompt: {'type': 'prompt_outputs_failed_validation', 'message': 'Prompt outputs failed validation', 'details': '', 'extra_info': {}}
FETCH ComfyRegistry Data: 110/115
FETCH ComfyRegistry Data: 115/115
FETCH ComfyRegistry Data [DONE]
[ComfyUI-Manager] default cache updated: https://api.comfy.org/nodes
FETCH DATA from: https://raw.githubusercontent.com/ltdrdata/ComfyUI-Manager/main/custom-node-list.json [DONE]
[ComfyUI-Manager] All startup tasks have been completed.
got prompt
Warning, This is not a checkpoint file, trying to load it as a diffusion model only.
!!! Exception during processing !!! ERROR: Could not detect model type of: /workspace/ComfyUI/models/checkpoints/z_image/redcraftRedzimageUpdatedDEC03_redzimage15AIO.safetensors
Traceback (most recent call last):
File "/workspace/ComfyUI/execution.py", line 516, in execute
output_data, output_ui, has_subgraph, has_pending_tasks = await get_output_data(prompt_id, unique_id, obj, input_data_all, execution_block_cb=execution_block_cb, pre_execute_cb=pre_execute_cb, v3_data=v3_data)
^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^
File "/workspace/ComfyUI/execution.py", line 330, in get_output_data
return_values = await asyncmap_node_over_list(prompt_id, unique_id, obj, input_data_all, obj.FUNCTION, allow_interrupt=True, execution_block_cb=execution_block_cb, pre_execute_cb=pre_execute_cb, v3_data=v3_data)
^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^
File "/workspace/ComfyUI/execution.py", line 304, in asyncmap_node_over_list
await process_inputs(input_dict, i)
File "/workspace/ComfyUI/execution.py", line 292, in process_inputs
result = f(**inputs)
^^^^^^^^^^^
File "/workspace/ComfyUI/nodes.py", line 581, in load_checkpoint
out = comfy.sd.load_checkpoint_guess_config(ckpt_path, output_vae=True, output_clip=True, embedding_directory=folder_paths.get_folder_paths("embeddings"))
^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^
File "/workspace/ComfyUI/comfy/sd.py", line 1344, in load_checkpoint_guess_config
raise RuntimeError("ERROR: Could not detect model type of: {}\n{}".format(ckpt_path, model_detection_error_hint(ckpt_path, sd)))
RuntimeError: ERROR: Could not detect model type of: /workspace/ComfyUI/models/checkpoints/z_image/redcraftRedzimageUpdatedDEC03_redzimage15AIO.safetensors
Prompt executed in 0.02 seconds
It's a Lora, but they have it listed as a checkpoint, you need to go down a bit and download the 19 gb version, it's so dumb, they have them all named the same thing...or just use it with zimage as a lora
你好,我下载了AIO的 GGUF文件,不知道用什么节点加载此模型,用普通的UNET load(gguf)加载器无法加载,运行后显示报错 ,谢谢
同样问题
+one
The same issue here.
蹲
Im confused af, is the 670 mb checkpoint merge better than the full GIGA size models listed below it? Why not have examples for them too? Again, I'm confused and learning these things.
?
It's a LoRA
@qek damn, I didnt know checkpoint merge is a Lora, thank you :D
@Pdidi no way this is a lora...
请问11GB的修剪版本也是AIO模型吗?
不是的,是独立的 diffusion model
Is this the ultimate ZIT banger??, ABSOLUTELY.
Cinematic af, kudos to the author🤘🥂
Like @Mrpopo714 @Tozi_White, and so many other artistic masters, your work has greatly expanded our horizons and elevated the use of the Z-image and others model to new heights. Salute to you! 🥂💗
@AiMetatron Thank you for your amazing work, dude. This is a fantastic model — the realism and composition are fantastic. This shows how much effort and time you invested.
@AiMetatron Very much appreciated!
Details
Files
redcraft2KREA2INT8_redzit15AIO.safetensors
Mirrors
redcraftRedzimageUpdatedDEC03_redzimage15AIO.safetensors
redcraftRedzimageUpdatedDEC03_redzimage15AIO.safetensors
z_image_turbo_red_bf16.safetensors
redcraftRedzimageUpdatedDEC03_redzimage15AIO.safetensors
REDZ-v1.5-BF16-diffusion-model.safetensors
REDZ-v1.5-BF16-diffusion-model.safetensors
redcraftRedzimageUpdatedDEC03_redzimage15AIO.safetensors
redcraftRedzimageUpdatedDEC03_redzimage15AIO.safetensors
REDZ-v1.5-bf16.safetensors
redcraft2KREA2INT8_redzit15AIO.safetensors
Mirrors
redcraftRedzimageUpdated.safetensors
z_image_turbo_red_lora.safetensors
redcraftFeb1126Latest_redzit15AIO.safetensors
redcraftRedzimageUpdatedDEC03_redzimage15AIO.safetensors
redzit_1.5AIO.safetensors
redcraft_redzit15AIO.safetensors
redcraftRedzimageUpdatedDEC03_redzimagelora.safetensors
redcraftRedzimageUpdatedDEC03_redzimage15AIO.safetensors
redcraftRedzimageUpdatedDEC03_redzimage15AIO.safetensors
redcraftERNIERedmix_redzit15AIO.safetensors
redcraft2KREA2INT8_redzit15AIO.safetensors
Mirrors
Available On (1 platform)
Same model published on other platforms. May have additional downloads or version variants.