






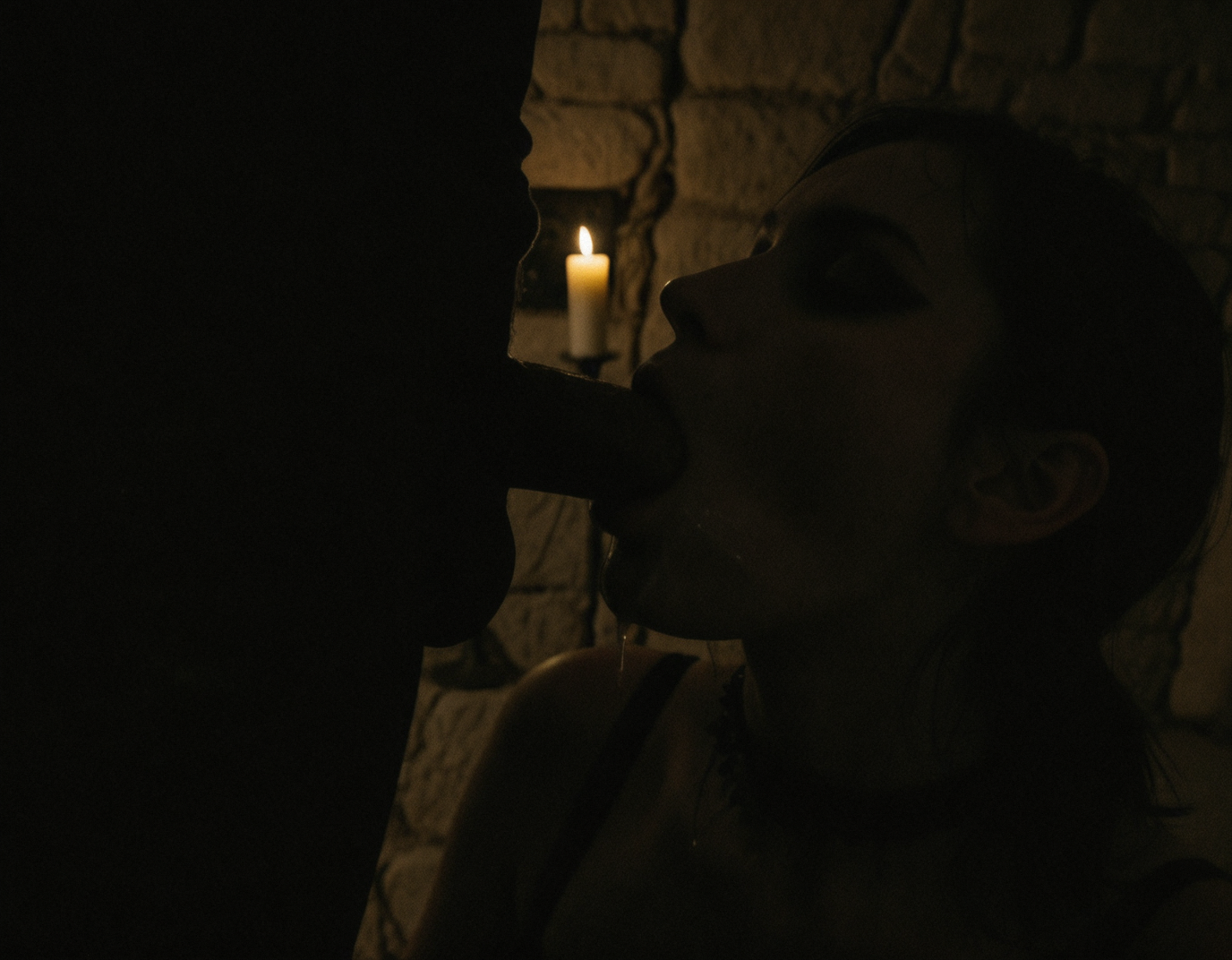










Update 19.06.2026. Lustify V9 (Zenith) IS OUT!
This is the absolute final version of Lustify built on the SDXL architecture. You can find the full changelog and a breakdown of the new features there. <----------
Recommended Workflow.
Alternative Access & Support: Outside of CivitAI's Early Access, you can get the model via my Boosty.
Just like last time, after the early access ends, there will be a 1-week period where the model is available for "on-site generation only." After that, it will become available for everyone to download.
Alternatively, you can make a direct Bitcoin (BTC) donation, just make sure to DM me after that: 1CoMZvrXtRXbz7BCzdvxifSjHqhaf1yUZs
LUSTIFY
Lustify is a photoreal checkpoint optimized for creating high-quality imagery of women in explicit/sexual scenarios. The model has been trained on a hybrid dataset, meaning it natively understands both Danbooru tags and natural language prompting.
Note: While it has a strong NSFW bias, if you guide it properly, it is fully capable of generating stunning SFW photography, objects, animals, and fantasy environments.
Crucial Points Before You Download:
NOT Pony or Illustrious-Based: This is a standard SDXL checkpoint. Do not use Pony/Illustrious LoRAs with it; they will not work correctly.
Distant Shots & Anatomy Limitations: Like 99% of SDXL models, distant shots can sometimes suffer from distorted faces or hands. This is an inherent limitation of the base technology (4 channel VAE), not the finetune. It is incredibly easy to fix using Inpainting or ADetailer. Please utilize these tools rather than reporting this as a bug.
Experimental Nature: My training workflow involves a lot of unconventional, high-risk experimentation. Because of this, some prompt combinations that worked perfectly on other checkpoints might behave differently here. If you encounter unexpected behavior, feel free to give feedback so I can look into it.
Recomended parameters:
Sampler: DPM++ 2M SDE/DPM++ 3M SDE,
Scheduler: Exponential/Karras
Steps: 30
Cfg: 2.5-4.5.
Highres.fix: upscale by 1.4-1.5, denoising ~0.4
For the distant shots of people you probably wanna use highres.fix and/or adetailer.
Also, use reasonable positive/negative prompts, shizoprompting does more harm than good (with any SDXL model).
Some tags that have a big visual impact with this model:
Camera type tags: "shot on Polaroid SX-70", "shot on Kodak Funsaver", "shot on GoPro Hero", "shot on Canon EOS 5D", "shot on Leica T".
Photography styles: "analog photo", "glamour photography", "street fashion photography", "candid photo", "amateur photo".
Lighting types: "cinematic lighting", "neon lighting", "soft lighting", "dramatic lighting", "low key lighting", "bright flash photography", "warm golden hour lighting", "radiant god rays".
Film types: "Ilford HP5 Plus", "Lomochrome color film", "Fujicolor Pro".
Photographers: Alessio Albi, Martin Schoeller, Miles Aldridge, Oleg Oprisco, Tim Walker.
Others: "film grain", "bokeh", "dreamy haze", "technicolor", "underexposed", "low quality", "lowres"
Alternatively, you can give a read to this wonderful prompting guide by PromptGeek. It has A LOT of useful tips I didn't know about even after years of using SD.
Description
Honestly, I can't recomend enough using it paired with DMD2 lora - it's both faster and fixes the small issues with faces/hands/etc. And now that NAG (Normalized Attention Guidance) exists, you can also utilize your negative prompts with it.
FAQ
Comments (423)
Showing latest 260 of 423.
As a rank beginner with maybe 16 hours experience from "starter models" and suggested stuff, this is far and away the best thing I've tried.
I've downloaded stuff that does some of the things this does, but they interact weirdly with each other or require incompatible settings and models.
This does it. Sure, it hates wearing pants. Ain't that what we're here for, though?
I'm a big fan of your work. Thank you for the continued updates.
its really great but sdxl is clearly showing his limits
Yes I tested the latest version 7 , and I must say the quality is much better more realistically, also shadows , and more details, also the women are hotter 😉 🔥 more sexy, and the backgrounds are more detailed. That's from my experience, and I cant wait till it even gets more realistically, but I dont know if that is possible with sdxl, I only use comfyui and I dont know how to train, but I enjoy this model. So thanks
fans and haters both are demanding an inpainting version of GGWP, fans would like it, haters would appreciate it, and both will be happy at the end of the day :D
anyone know the best settings to train a consistent character lora on this model?
Please train this on the Chroma model i think it would excel this !
uhhm, i created some really nice images with lustify, but as of late i really get annoyed by the anatomical flaws. some female hands and feet just look scary. a real turn-off for using this model
Love it! Any tips on making futas? It keeps coming out with the same face and the face is kind of manly.
"futanari, trap, 1girl, penis" tags were the ones used for captioning futa pictures. Use these for the initial gen and avoid using them on the facedetailer/adetailer pass.
I'm still using Automatic1111, and the upgrade from 6 to 7 using the same prompts that I was using successfully in 6 to create great images are giving me super low-quality images. What am I doing wrong? Or anything I need to update like VAE? Or is this an A1111 thing?
For me, version 7 generated images as three-color patches until I did the following: I restarted Automatic, loaded another checkpoint first, then V7, then generated a 512x512 image with a simple prompt (like "a girl"), and then everything worked.
Can anyone explain what DMD2 means here? i just see the file but i have no idea where to put it, is it textual inversion? is it something else? Using stability matrix forge ui. Please any help would be appreciated. Thank you
its a lora in this case
@daveddavies250636 thanks man
@daveddavies250636 sorry to nag you again, how to i use the shared file as a lora? i tried just putting it into my lora folder on stability matrix but i dont think im doing that right at all. Apologies for my ignorance
@medso224 ngl i had shit results with it. i've been using LCM (both sampler and lora) instead and just ignoring dmd. I'm trying 7 now since i hated the dmd experience so much.
@daveddavies250636 You will love it once you learn how it works. It's faster and produce better results. Use LCM sampler, Scheduler sgm_uniform or exponetial or kl_optimal. Between 6 to 13 steps. cfg 1. If you really need th enegative prompt you can use cfg up to 1.5. This is th esetup that works for me in Comfyui. Might also work in forge.
If you put the cfg above 1.5 it will start to over-saturate the image. Steps above 13 is just a waste of time.
@Sam_A @daveddavies250636 just to update; I've been experimenting with dmd2 now and while the typical settings it was nice and quick, but just didn't look very good and always with that 'clearly ai generated' feeling.
I strongly recommend you both try out these settings - for me it was a total game changer:
euler a and cosine sampling method combo
sampling steps: 16
the fp16 lora (personally looks much lighter on the contrast than the other one) at 0.75 weight
1.5 cfg
1024x1360
hires fix 4xultrasharp
8 hiresteps
0.4 denoise
1.5 upscale
1.8 hires cfgscale
the difference between these and whatever i could get from LCM + normal is just simply night and day. Replacing cosine with karras, sgm uniform occasionally got me nice results but on closer looks was filled with strange noise, phi is very good too.
Just to add idk about OP's file i just used this one DMD2 Speed LoRA [SDXL, Pony, Illustrious] - dmd2_sdxl_4step_lora_fp16 | Stable Diffusion XL LoRA | Civitai
@daveddavies250636 is V7 not a DMD2 model? (i also hate DMD2 lol)
V7 is epic! amazing results! its my goto model! can you please make a V7 inpaint so it will match quality for little fixes?
Thank you so much!
there would be one for v8
Inpaint ver. pleas
there would be one for v8
got it, thanks! will wait for v8 then 👍@coyotte
Hi! What's the benefit of an inpaint-specific version? I'm pretty new to this doesn't it work the same as using image-to-image, selecting the area you want to inpaint, and regenerating?
I love the model. I have melted my GPU finding a decent model for SDXL since pony doesnt do it for me, v7 might be the best in the website. In case the creator reads this, i would like to ask, any way of having more control on futas? namely body shape and d size, If its not baked in the captioning, will v8 have these in? Much love coyotte:)
for amateur pictures this is extremely good.
Love this model. It's great and is extremely powerful. But somehow for me the pictures have a palish hue. And also the face sometimes looks kinda "plasticy". Maybe it's only one me though. That's why i switch up between the new and older model, depending on what i'm doing. But it's really good at creating amateurish images!
Its true its still has a pasty look sometimes
Any chance to train the model for more advanced cards -- like 16 GB or 24 GB? Superb work. Excellent model.
Hey @coyotte , is it true you were aroused the whole time while gathering the dataset for this great model?
No, it actually gets old pretty quick
@coyotte well, I was aroused the whole time you were gathering the dataset.
@coyotte ha! Bro.. I often wonder how many pairs of different tiddies I've looked it
When is ver 8 gonna come out?
and can you make it render better and handle loras better like Juggernaut XL?
please and thank you :D
There's a demand for amateur style, there's a demand for HD look, they don't go together that well in one model. I don't know what V8 would be like yet.
@coyotte yes there's always a demand if something is good lol... lustify has very good nsfw prompt follow, is it ok if i do some merges to try and improve it?
Best bet is a 2000's dslr camera look, like Nikon d90(i use that in my prompt). Its HD and clear, but captures the amateurish look of late 2000 myspace(preinsta) pics.
@ladellyefim965 canon always had and always will have better colors :P
@coyotte you can always degrade IQ with loras, but you hardly can get it better. I'd personally go for HD. Better to aim for the stars and fail in any case. Looking forward to v8.
@coyotte HD is better IMHO because, as someone said, it is easier to trash a good picture. Your OLT model is really good, for me the best of the series.
@coyotte how about onlyfans, reddit like style with hd resolution, i wonder how much detail and resolution it can handle not talking about 4k but just real good quality images, like better eyes, lighting, is it training data images , i will donate for this again man, i like quality but mostly the images are kinda foggy is it possible to get like hd quality, there is a demand in everything but how about improvement of the resolution of the images the overall quality
I"M fucking back to make money hehe thanks bro I love you I already gave you 200 bucks so dont cry
"so dont cry" - but was I?
how much you making to be tipping 200 god damn
Im curious, where you can make money from deepfake?
great for generating stunning women and simple porn. if you want more complex images lustify gets really freaky and doesnt understand any prompt and creates ugly freakshows.
Great model as to be expected but I find it has a major problem with nationalities and ethnicities. Even some pretty common ones are just impossible to get, I wonder if they were even trained. A real shame. Otherwise great job with this one.
Hopefully v8 will be better at this.
How to close mouth to all characters in this model?
just dont write anything about mouth, or try "parted lips"/"open mouth" in negative, never had an issue like this
Bro, I'm totally new to this and the google drive link is not working, can you please reshare it? :)
If you like anal and trannies this is def the #1 checkpoint. Gl getting a d1ck inside of anything but her a-hole. Bonus, if u keep trying she'll just grow a dick.
This is not the best porn model. Try this, its an XL and Damn Illustrious merge. Lack of lighting and background, but way better at porn.
https://civitai.com/models/1685120/naturalbeauty?modelVersionId=2275581
I rarely encounter dicks , maybe try to prompt for women, girl , etc
@bravenazure298 looks really bad
Looks like google removed the DMD2 workflow, could someone or the creator reupload it? I've been using NAG with moderate success, but hasn't been reliable.
Please reshare the DMD2 workflow Google took it down, as well as the DMD2 you use too. Thanks!
can you resend the link or google removed it
i beg - please make a GGWP V7 Inpainting Version.
In the DMD2 workflow the last stage of the process is tile upscaling, but the generation is saved before this, and the tile upscale result never gets saved? Is this meant to be the case? Maybe someone can give me some insight. Thanks
I don't know what the workflow is, but you can just add a Save Image node after the tiled upscale, instead of a Preview node.
Tried using both the DMD2 and non version of your workflows and I'm getting the following error:
Error
No link found in parent graph for id [4] slot [0] clip
I see no errors in the console and none of the nodes is outlined in red, so I have no idea what is missing.
Figured it out. Somehow for both workflows the anything everywhere node for the positive and negative prompts were connected incorrectly. No idea how that happened because I just downloaded them and opened. Either way. We're good.
@_degenerativeai_ what is the correct way to connect them please?
@calevizo Below the positive and negative text encoder nodes there is an Anything Everywhere node. You will want to remove the current connection between the positive and negative prompt boxes to the anything everywhere node and then go from each conditioning connection to the anything everywhere node. positive prompt connects to the left side positive of the anything everywhere node and negative goes to negative.
just go to https://civitai.com/images/98189810
or any other image generated using this model
and look at Generation data section
click to "Other metadata comfy: 69 nodes" to copy the json of workflow for this model
after loading this workflow everything works fine fro me
i think its because of comfyui's subgraph update messing with workflows using "anything everywhere" try setting it up again that seemed to work for me, for my own workflow
Jumping from one error to the next in your WF.
KSamplerWithNAG
NAGCFGGuider.inner_sample() got an unexpected keyword argument 'latent_shapes'
Any idea?
just go to https://civitai.com/images/98189810
or any other image generated using this model
and look at Generation data section
click to "Other metadata comfy: 69 nodes" to copy the json of workflow for this model
after loading this workflow everything works fine fro me
@jexan49972548 i'm using the workflow provided by the author of this checkpoint already..
the NAG github has a PR that fixes that issue
@crombobular Working now, thank you so much!!
@Lora_Addict what exactly do you do? i'm at the pull request tab and not sure.
@A14073240735 i just did that in powershell / cmd:
cd X:\PathToYourNode\ComfyUI\custom_nodes\ComfyUI-NAG
git fetch origin pull/50/head:nag-pr50
git checkout nag-pr50
@Lora_Addict thanks a lot. i'm so clueless with this stuff XD
@crombobular legend
Just updated my comfyui and now comfyui can't find the node even after i reinstall it. Are you also getting that issue?
Do you have safe default settings for V7 using the DMD2 Lora? I don't have Comfy so I'm not able to see what you have on the workflow.
Currently doing LCM Exponential, 8 steps. HiRes Fix 1.5x, 0.35 denoise, 4 steps.
Results are good at these settings, but wanted to make sure I wasn't missing something.
i use LCM beta, CFG 1.6 and 12 steps (8 also works fine i just have this set is my workflow because noobai usually needs more), dmd lora at 0.7
@purplelady I tried dmd strenght variatons too. But cant say, its better at lower strenght and with higher cfg, than just plain 1 strenght.
@deyonpaarth673 honestly i just focus on cfg with it to make sure prompts get some more influence
InstantId doesn't seem to be working fine in the v7, tried changing the settings several times but while the face stays consistent, it destroys the prompt. Any recommendation?
I really like the previous Lustify checkpoints, but with v7 I am not getting any good results at all. It only works well with the DMD2 lora, but with "normal" settings, (DPM2, Karras) I am not able to get good output at all, and on same prompts that worked well on earlier checkpoints and that produced similar image compositions I am getting a completely different composition with v7. Can someone help me, I would really like to access the greatness of v7!
It's not that V7 is better or worse than V6. It has a completely different style. If you like V6, you should stick with it. I wouldn't consider V7 so much a replacement for V6, but something to use as a totally seperate tool for totally different results.
@ChillDesire I propapbly didn't express myself clearly. It is not just a different style, it is in most cases completely distorted output, not visually appealing. Same prompt that renters godd result in different styles with many other different checpoints. Sometimes there nedds to be some adjustment on cfg if the contrasts are too high, but here something else seems to be required. It is not just a different style.
@ToddPounds Maybe you need to use tools such as chatgpt. I found that this model is very sensitive to the weight of the prompt word at some times. When the weight of the prompt word such as "masterpiece" is too high (sometimes it is only 1.3), the output is all simple color blocks.
@atbgams Thanks! I find chatgpt to be very bad at the specifics, gives very strange recommendations on CFG values etc. What you are mentioning about sensitivity is very useful, thanks.
I think the anatomy and overall look is good.. bit better than last version, but main problem for me is that every image seems to put a dick in it, either futa or a man even with very strong negative prompts against - worse than previous version. It would be great to see a NSFW model with more solo and lesbian capability / training. If anyone has any tips on how to get rid of the dicks I'd really appreciate it!
Is there any way to prevent all generations from having tan lines? I am using the inpainting version and v6.
is there anything that differ when training a LoRA with this model(realistic in general) over anime models(e.g WAI)?
I can't get any LoRA's trained here to work as good as i can with anime models
Since the release of V7 I have trained 56 loras of various type using it as the base model. Not only does it make the crispiest most accurate Loras of any checkpoint I have tried, but when combing them back with V7 it is hands down the most realisitic images i have seen from any model, Flux, Qwen, Wan, Pffffffffft! .... Now finetuning the 36,000+ img dataset. Initial tests are indistinguishable from real life. This is the only checkpoint I will ever need now, Coyote, youare the checkpoint fkn masterrrrr! -- I long thought SDXL had come as far as it ever could until you dropped this abso-fkn-looot banger! How was this possible?
curious what version lustify checkpoint do you use to train?
Could you recommend some basic settings on your loras? I'm trying a face character lora with 45 images, training unet (50epochs=2250steps) and te1 (25epochs) with ProdigyPlus and 64/1 dims but I never manage to loose the artificial look or get perfect teeth...? Using V6, V7 throws crazy colors when applying any finished lora after training...
Would you consider sharing some insight into your training settings? :)
Works great as a refiner for my pony checkpoints. Takes the plastic face away and my loras faces look now like the source! Great work!
Adding extra penis to the women 😂 I could not find any solution for that
Is this normal? https://imgur.com/cHQhhnc
I don't know what i'm doing wrong, i just put the checkpoint at DMD2 with Leakcore lora. I get that as a result. Sorry if it's simple to fix, i'm still new with ComfyUI.
Update: I just had steps to 5 by default in ksampler and didn't notice. I fixed it as i raised it up in numbers.
What are the recommended settings for the adetailer?
I'm new to LUSTIFY and have a few questions: 1. Does this model understand concepts beyond the common ones (missionary, doggy style, cowgirl)? Is there a list of tags I can use with this model? 2. Can all the style tags (1 through 7) be used in the same prompt, or do I have to choose just one?
I'm using forge with this model and wan2.2 vae best results I am getting with this set up, I've tried a few others, this one is the best. I have a RTX3070
DMD2 version works great, but v7 has some problems on face details
how are yall using this my comfyui nag will not download when trying use dmd2 it gives me an error message
git clone the repo into your custom nodes folder, then go into the ComfyUI-NAG > chroma > layers.py file and change the word "chroma" to "flux" on line 5
@Chimaeraic_Generation thanks for the tip! Any idea why that word change needs to be done?
@Chimaeraic_Generation THANK U
@Chimaeraic_Generation ty!
For DMD2, what is everyone using for LCM scheduler? Hires fix settings? SD Ultimate Upscale? For Hires fix if I run LCM ddim_uniform it's extremely sensitive to steps. It's most stable at 2 steps, and low denoise of about 0.10. If I try 3+ steps it doesn't matter how low the desnoise is it will hallucinate anatomy severely.
I figured out why the steps are so sensitive. I have Hires upscale set to 0.50 instead of coyottes default 0.30 in the DMD2 workflow.
What 0.30? Denoise? it doesnt matter. Hires fix doesnt work good with distilled models or dmd2 lora.
@zaydinniklaus731 0.30x upscale not denoise. I've been using Hires fix for awhile now and it seems to add good quality details when upscaling, but it does seem to be hit or miss with DMD2. What do you recommend for upscaling? With Lustify V7 DMD2 I'm generating 1280x800 images and would like to at least do a 2x upscale.
@eros1ca Depends, what gui you use. In forge, auto1111, there is multidiffusion with tiled, simple img2img, then upscale(its manual work), not automated, like hires. For Comfy there is Supir and Seedvr, both very demanding on Vram. Or 3.rd party apps, like Topaz Gigapixel(you can download, if you know where:) and online tools.
And there is simple upscale of course, but that doenst fix anything.
Where is the DMD2 Version for Version 7
would like to at least do a 2x upscale.
That's your problem right there, the 2X upscaling. I run this model (or rather, a merged checkpoint model that is made of this + BigAsp, aka biglust) along with dmd2, LCM sampler Karras, and whe I said Iris fixed to anything other than 1.5 x it creates some pretty unsettling freak Show deformities lmao. Took me a while but I figured out that is the upscale size not the denoising that causes the deformations imo, normally I generate 1024 x 1024 with a 1.25 high res fix upscale and can run almost as many steps as I want at whatever denoising I want and it will avoid producing body horror disasterpieces haha. But when you adjust high res fix to 2x it becomes pretty much a gamble as to whether it comes out looking good or looking like something from John Carpenter's The Thing
How do you use the inpainting portion of this workflow?
This doesn't even show up to choose in Fooocus and in SD it produces complete garbage images. No idea how anyone got this to work at all.
Fooocus hasn't been getting updates, it's glitchy and unusable
You must use ComfyUI - it works very nice.!
ComfyUI or whatever the latest Forge fork are your best choices.
A model made by the gods
Awesome model and workflows, thanks a lot!
What is the difference between the DMD2 workflow? I'm comparing both with same seed and prompt, and I can see there is a difference, but wondering if someone can explain the benefit of each. Is it only speed and personal aesthetic preference?
Will a V7 DMD2 version be launched in near future ??
just use dmd2 lora, it won't be any different.
Did anyone launch thit model with 4 gb vram? 😅
u can launch, but it will CPU Swap 100%, 3-4 min for an image
Let's all hope and pray that Z-Image Base releases soon. Because that's what the new Lustify version will be trained on.
@coyotte hey man please, also include professional and amateur pics of the most feminine and sexy shemales, tranny, trap, crossdressers, femboy... all erect and flaccid and large and small circumcised, uncut, hairy, shaved, little hair... nice asians japanese, korean, chinese... blondies, blacks, pales, whites, please please pleaesee
@newbieAiUser that is a very challenging task. mind sharing some names? i do have quite a few already, but probably not enough to cover everything you've requested.
@coyotte yes focus on actually understand between ethnicity that would be something no other model can do. they can only do white or asian or negro, very simple
@coyotte yes I can give you a name list in some days in DM
@coyotte I sent you some, please check DM.
what is more fastest? sdxl or z-image?
@SrBig given you can fit Z-Image into your vram, Z-Image Turbo and SDXL are roughly the same. Z-Image Base, however, would be slower.
@coyotte of course its the same speed. If you have 96gb vram card, flux 2 is the same speed as sd1.5.
@asadbeksaulo470 that's not how it works at all. 1b model would ALWAYS run faster than 32b model, no matter the VRAM you have.
This is EXCITING! Glad you're still looking to train on a new base model.
Would have been better if you actually plan to make Z-Image Turbo version before the Z-Image base. Not everyone gonna able to run the base model. Z-Image Turbo is already better than SDXL in every way. It only needs NSFW.
@chrisss1 Base model most likely will have the same weight and amount of parameters. Lightning or Turbo loras will come out pretty fast, so you'll get the same speed you do have now with Turbo.
Don't get me wrong - i LOVE ZIT, but I have no interest in finetuning Turbo as it's a distilled model and that limits what you can do with it. I'd rather spend my resources on something more meaningful.
@coyotte Good to know, if there is any issue with ZIT then avoid it, we don't want limits. Not worth wasting time and resources on it.
@coyotte Ostris released De-Turbo (de-distilled) 16gb a few weeks back -- fine tuning and loras on this, what is essentially the base model, would cross with any release of an official base model, which I am not sure they will even need to releae now. Maybe why iit not been?
I have great success with loras and fine tunes, it soaks up datasets so effortlessly! And now with OneTrainer support (Using the De-Distttiled base) My RTX Pro is living the dream!
Lustify series is THE greatest SDXL checkpoint BAR NONE, its been pretty much the only model I have used since end game, well over 20,000 images generated, my attention has finnaly been diverted with the releae of Z-Image.
eeing Lustify on ZIT would make 2026! If not I am going to do my best to port it over in a "Tribute to the GOAT" version.
@ronikush hey, first of all - thanks a lot for the kind words, appreciate that!
Secondly - yeah, I've started to realise that we won't be getting Base anytime soon as well, that's why I'm preparing everything to train on what we have now (Z-Image Turbo or De-Distilled). I was going to try my luck with Turbo, but now that you've mentioned it, I might give De-Distilled a go. Thanks for bringing my attention to it. Do you personally prefer training on Turbo or De-Distilled?
@coyotte Z image base model is here ! 🔥🔥🔥
thank you
what is the best resolution ? basic question but i'm not really sure
896х1152
832х1216
1024х1024
1024х1536 will work to an extent
er what is DMD2? google is not my friend on this one
@myxlmynx ohhhh thank you!
You really killed it on this latest version, great diversity and detailed backgrounds.
thank you, glad it works for you!
"and I do a lot of dumb-crazy stuff that in theory shouldn't work."... That is some pretty awesome self-deprecating awareness. I tip my hat to you.
You you plan to release a ZIT version?
Couple of questions:
1. is there a way to generate two or more characters in the same image (with different features)?
2. Is there a way to choose the breast size and keep generating the same character with diffeent poses/situations? (everytime I change something it generates a totally new character).
1) regional prompting
2) sounds like you'd want to use character lora
@coyotte Regarding character LoRAs with these checkpoints - is it better to train them on SDXL base model or choose my favourite Lustify checkpoint and use that as the base model to train the LoRA on?
Hi, thank you for cool modes, the links to workflow in description doesn't work. I wanted to ask if I can use OLT inpainting as in workflow in images, or there's some updated version?
Just checked - the links still work. Your ISP might be blocking catbox, try opening it with VPN on
the link is not working
It does work, I've opened it right now just fine. Your ISP might be blocking access, in that case use VPN.
Any plans for Flux.2 Klein? 9b base model looks promising
I'm trying to figure out whetever it's still worth it to wait for Z-Image Base or to move on and start with Flux.
Gonna make some test training runs and the rest depends on the results.
@coyotte Looks like we might get it tomorrow, fingers crossed!
@helkingeo833 yay, we got it
@coyotte no editing :(
@bombomoo yeah, that's somewhat a deal-breaker for me.
@coyotte Any plans for ZI base or a no go, for now?
Anyone can give workflow json for the image edit?
@anonameguyman1234252 hey thanks..
@jagermister0901 https://civitai.com/models/2338958/lustifysdxlnsfwoltinpainting-workflow I updated the workflow to version 1.1 that has the updated crop and stitch nodes
2 question:
This version is better than v4 alpha?
BTW, im getting this error when i try to use the non-dmd workflow
Cannot read properties of undefined (reading 'workflow')
Hi, I have a question, using SD with A1111 (web ui 10.2.1) on Runpod I have perfect results, but when it's on local (newest version) the eyes are always off, melting or weird. Is that normal ? The Checkpoint can't handle the newest version of SD ? TIA for your help
I was skeptical at first, with this one, couldn get any good results, but now I agree, this model is truly a masterpiece!
Thank you!
one of my favorites. just wish it had more..deepthroat 😅
Hi. I'm getting the next error:
InpaintModelConditioning
GET was unable to find an engine to execute this computation
I'm using ComfyUI Zluda with an AMD card.
for anyone new to this page, the model you actually probably want is to the far right on the list - the original OLT.
May I ask why you say that?
@j48268505237 most resolution flexibility, best image quality overall, best prompt adherence, it's just better. the "fixed textures" version works better if you're staying low resolution but once you are upscaling or doing a hires.fix pass the downside tradeoffs from the fixed textures show themselves. most people are upscaling
@shapeshifter83 even better than V7? I dont see any notes for improvements that are changed for V7 listed? Thanks!
@l2l111170 v7 was a bit divisive when it came out. v7 has better prompt adherence and more overall capability but an undeniably diminished visual quality. what we need is one more pass by coyotte to bring some of OLT's visual quality to GGWP's model IQ
How do I get the upscale working. Everything else works great. As soon as i turn on tile upscale it wont run. I have the models loaded. Haven't used the inpainting yet tho either.
How do you move from a generated image into video with this model? I assume using WAN 2.2. Any step by step or pre built workflows?
Yes, Wan 2.2. Any workflow that suits your needs and resources would do.
This model is okay for doing amateur photos, but if you want hard NSFW you'll need loras. Idk why, but this model can't do c*m properly.
hold my beer
The greatest checkpoint ever made. Been using it since first release 70,000+ images - then V7 took photo realistic GOATism, the results I get MOG every model.
Only now with the Z-Image release has LV7 not been a daily feature, However I still keep coming back as there are certain images that Lustify is more realisitic.
The dream is Lustify Z-Image.
There was no other choice than to painstankingly go through the arhcives, collected 20k of the most photo realistic Lustify images from our collection
As we speak our RTX Pro Workstation is hammering anunofficial Lustify Z-Image Base. Hoping and praying eith every epoch"
I think you shouldn't call that model "Lustify Z-Image Base", unofficial or not. It's not affiliated with me in any way. Why don't you just call it something else to avoid any confusion? :)
Which app should I use to generate videos with the v7? I used Fooocus with v5 endgame checkpoint, worked ok, but now I want to try out videos.
None of the version are for video. You probably got confused by the users sharing videos in the gallery - the initial images were made in Lustify, then turned into the video with Wan 2.2
I dragged the json into my comfyUI workflow, it prompted me to download 8 missing requirements.
However, when I try to run the prompt I get this error:
SyntaxError: Unexpected non-whitespace character after JSON at position 4 (line 1 column 5)
New to comfyUI, can anyone help? Thank you!
JSON file may be broken formattingwise. One of the nodes could be broken.. any of these. Try getting a decent LLM to write you a custom JSON file in the format that ComfyUI uses. It's what worked for me. Simple inpainting, lora for extra details but not really needed cause this ones pretty good on its own.
This is the best inpainting checkpoint that worked for my needs.. Thanks my guy! Other ones were really bad, or just didn't work at all, but this one gives such natural results with very little work.. I made an AI create a workflow JSON put the model in and it just works. Fucking brilliant man!
Thank you, glad it works for you that well!
Can you send me workflow i have problems with this new ComfyUI version
Things are not comparable
waaaay too many weird deformations, too bad
If only you've shared your prompt/settings/workflow so that I could help you figure out what's wrong
this is the greatest checkpoint ever! on a regular basis I am checking for a new update or see what the creator is up to.
I have tried so many, none come close to this one.
I have filled a 2 tb hard drive just with sdxl checkpoints. if I could keep one, its this one
Hello, thanks a lot for the kind words - it means a lot to me!
Regarding what I'm up to - I'm trying to tame klein 4b currently and port Lustify to it. I also have a new SDXL version with native highres generation in mind (like 1280x1536 and even higher with a first pass) and obviously improved visual quality.
Hey @coyotte ! First off thanks for all the hard work you've put into this. It's gotten me into a new hobby that's been lots of fun to explore.
One question that's been nagging me for a little bit is why, in the NAG/DMD2 workflow you created, does my workflow error out when I include an ipadapter facID after the LoRAs and into AE? After trying to troubleshoot with Gemini and GPT, I've just determined that I had had to choose one over the other (which is a bummer, because otherwise I have things running really well!) Are they trying to sit at the same seat of the table sort of thing? Is there anything I could try and do to get them to work together in the same workflow?
Lastly, should I stick with GGUF or utilize OLT? Do you have any opinion as to another experienced users advice in including a contrast node at negative to run a higher cfg or DMD2 LoRA weight? Thoughts on using fp16 AND fp8 DMD2 at lower weights?
I know this is a lot of silly questions for a newb like myself, but any advice would be super helpful from the man himself. Thank you!
Had some trouble making your workflow work with this. Especially since It was my first time on ComfyUI but goddamn the results are insane. Freaking love it. Just wish it was slightly easier to create SFW in the same style it got a tendency to really REALLY want to show boobs lmao
I tried to use the DMD2 workflow, but I do not get it to work. Installed missing nodes etc. But directly after hitting run i get:
Error
Cannot read properties of undefined (reading 'output')
It's the custom scripts below the first two CLIPs. It's output got broken (due to whatever) and wasn't linked anywhere, and can't be linked (at least in my updated Comfy). Had to reroute manually from CLIP Encode to KSamplers.
It is almost a year passed since OLT was released. It will stay in AI history for me as greatest SDXL checkpoint of all time, true original one. And it still deliver exceptional quality with proper settings.
Just want to give my respect to @coyotte for it and LUSTIFY! series in general. True legend.
Hey. Thank you for your work! I tried the NON-DMD2-Workflow. But I get an error message: "can't access property "output", res is undefined" Do you have an idea how to fix this?
It's the custom scripts below the first two CLIPs. It's output got broken (due to whatever) and wasn't linked anywhere, and can't be linked (at least in my updated Comfy). Had to reroute manually from CLIP Encode to KSamplers.
Hey, thanks for the model. Big fan.
Anyway, did you use the workflow recently in Comfy? I'm getting errors like other folk and I'm wondering if it's maybe using some nodes that weren't update to the new Comfy nodes? Any ideas?
Okay, I got it.
It's the custom scripts below the first two CLIPs. It's output got broken (due to whatever) and wasn't linked anywhere, and can't be linked (at least in my updated Comfy). Had to reroute manually from CLIP Encode to KSamplers.
Hey bro! Is it possible to train a LORA character at your checkpoint?
It is, I'm currently trying it out. Can't help with any settings though, but I can give you this tip: every single SDXL LoRA I've trained I thought was a big failure because everything was a big mess, and yesterday - just for testing - I've tried them with the LCM/DMD2 workflow and... most of them turn out to be usable this way. Sure, you might lose a tiny bit of likness but in my opinion it's worth it.
I recommend training through Prodigy on Pony Diffusion V6 XL models, or I prefer PonyRealism VAE23. Two separate datasets. Face with 15 repetitions per photo. Body with 10 repetitions per photo. 15 epochs, but 10 is enough if the datasets total 150+ photos. The result is excellent in 90% of cases.
@d2449384447 did you get better results with training on Pony based models and then applying the LoRA back on Lustify? I always got better results with training on the model I want to use the LoRA on.
With two separate LoRAs, how does your workflow work then? First pass for body, then face inpaint with face LoRA? Or just connect two LoRAs and go for it?
I recently trained for Lustify, and while 2 pass KSampler gives me alrighty- results I still prefer applying a yolo face inpain with another KSampler on a small denoise.
@d2449384447 in my experience, training on pony v6 is valid, if you want to train a "pony face." If you're training a character with a normal correct face on a pony model, then only train on Everclear. For realistic use (generate) models like cyberrealistic pony. Also, most of hyperrealistic pony checkpoints break proportions and faces; they're overtrained and difficult to use with characters loras accurately. For most cartoony pony finetunes that lora should work normal, except base pony. Regarding SDXL, this topic is about SDXL; its advantages are realistic, natural bodies and proportions. I tried training on Lustify ggwp and use on it, and the result was okay, but I prefer generate on Lustify Endgame; I like this checkpoint better, although it has its drawbacks. For Endgame, I train loras on Biglust v1.6 checkpoint. It works very well. Training on a very similar model but on a different one allows you to slightly filter out the "parasitic styles" that eat into the lora during training, but the lora remains accurate enough for use. SDXL and pony loras are very difficult to combine and I highly recommend against using them together.
@DRZ3000 cool, we're in a Lustify thread so that's why I was kinda confused when you recommended Pony. I'm currently training and using on GGWP, but I'll definitely try the train on BigLust and use on Endgame combo. Thanks for the chat.
@gonzalo_983 I train all character LoRAs with two datasets. They are connected immediately during training. I use OneTrainer. The point is that the model should prioritize capturing the face from the face dataset, and avoid taking the face from the body dataset. I don't use masks because it's time-consuming and troublesome. If the face dataset has, say, 10 repetitions per photo, then the body dataset is reduced by a third, that is, 6-8. This rule works for all models without exception. Additionally, this method is good because with one face I can change body sets on new LoRAs very quickly.
Greatest model of all
I now check or the 300th time to see if there is a new version
Something new might come out soon :)
@coyotte At last! I didn't dare to IM you out of fear your account might be abandoned.. :-)
@coyotte That would be sick! I would love to try out a beta as well if thats an option
Gentlemen, get your engines started...
I'm novice in this matter, so I'm sorry possible stupid question, in description here written that this model isn't ILLUSTRIOUS-BASED, but in 147f5i recommended workflow used illustrious checkpoint and illustrious loras why? if illustrious shouldn't be used, what should be used?
Because he recommends the same DMD2 workflow for both his Illustrious based model and this; he probably saved when testing Illustrious and uploaded. Just switch the model to this one, apply DMD2 SDXL Lora and voila.
ohhh, @gonzalo_983 is right. @n1c0s947 Thanks for pointing it out, that is a huge oversight on my end! Will fix that with an upload of the new lustify version. The workflow needs some clean-up anyway
@coyotte Thank you in advance
gooner nerd full send! my wishlist for the final version of lustify:
- better handling of sheer/see-through fabrics and/or mesh/fishnet
- a re-injection of some original SDXL knowledge or new knowledge of persons/faces (i know that's taboo and can't be acknowledged even if it happens behind the scenes)
- better nipples, more prompt obedience with nipple variations (long_nipples, etc) and nipple-related tags (visible covered_nipples bumps aka "pokies")
- better prompt adherence with crotch-related anatomy or scene (cleft_of_venus / innie, long_labia, deep_penetration, etc)
- pov prone_bone knowledge (legs_together adherence)
- an improvement of general visual quality from GGWP
- makeup/hair related prompt adherence
"Final" as in "final SDXL" version? Because it's not like I'm planning to end the series. If anything, I'm about to start posting way more then I used to, just not SDXL.
Your points are valid, most of them are already being taken care of with the current training run.
Innie/outie pussies should be promptable if the model grasps the difference. I've manually tagged them on about 500 pics. Could've used more, but this will do as well.
Visual quality is definitely improved. It's also capable of 1536 res gen natively.
Sheer fabric should be better. Fishnets, hopefully, too, but they are tricky.
@coyotte impatiently hopping from one foot to the other
How to use with dmd2lora cfg sampler scheduler? Steps etc..
CFG 1
LCM sampler, Karras/Exponential/Sgm Uniform scheduler.
4-8 steps
@coyotte which resolution good for dmd2
I want to create real girls , lustify is okay but the faces are sometimes like they need the yellow bus, how can i make high resolution faces with fscedetailer, what are the best settings
you could use my new workflow, it has everything set up at "best settings" (at least what I consider as such)
For the next version i would love to see, higher resolution faces, and mouths , detailed skin texture, no missing hands or bad fingers, no deformed eyes, more natural girls, curvy, skinny, better lighting, shadows, real looking women, chicken wings, 4 fries, cola . I might donate with bitcoin again but lets see some new version
One more question please, why if I use cfg more than 2.5 in this workflow tjya84.json colors of the image become almost poisonous bright?
Because you're not supposed to use CFG bigger than 1 with DMD2 lora
@coyotte Thank you very much for answer, so recommended parameters in the description relate only for NON-DMD2, is it correct?
@n1c0s947 yes.
For DMD2 lora you should use LCM + Karras/Exponential/SGM uniform, CFG 1, 4-8 steps
does training this kind of content desensitize you? I'm picturing the hours upon hours of analyzing and captioning the training images. I would probably need long breaks between model training to make my wee wee work again.
It used to, yes. Nowadays when I work on the model, my mind learned to switch into the "work" mode. I look at the pics purely from the techical point of view.
Worth to mention, though, surely a better part of the analyzing and training is automated, at least to some degree? Manual inspection is merely a sample of the whole? Or am I off here? @coyotte
@Bobsmokey I wish. I manually review and edit ~70-75% of the data. I could say "fuck it" and make everything 100% automated, from parsing images to captioning, but the end result would be horrible to my standarts.
where do i download the workflow? the link isnt working for me
Probably your ISP is blocking catbox. Use VPN.
I have turned my VPN both on and off and it will not download or even reach that site either way.
Will a standard SD XL trained lora work with this? Or do I need to train a lora directly on this checkpoint, is that even possible?
Some SDXL Loras "work" but to maintain the quality of the checkpoint I suggest training a lora directly on this checkpoint. Especially if it's a character lora.
So far I have tried to train a couple of character face Loras on the checkpoint but the results are bad...
@helkingeo833 Any recommendation regarding steps or lr? My experience up to 5000 steps is that is not enough to overcome the conditioning of the model!
V8 SDXL Lustify drops this weekend. Native 1536 resolution support, multiple new concepts, and significantly improved quality. A huge amount of work has gone into this version.
I feel like I'm just one step away from creating THE ULTIMATE NSFW SDXL checkpoint. I hate overhyping, but this version is insane - it’s truly the APEX of my work so far.
I’ll also be posting a usage guide, a full tag list, and some technical details regarding the training process.
I can't wait, thank you for all your work.
You are amazing. Thank you!
👀
You did it. Son of a bitch, you did it! 😁
Just got v 8 through your boosty and your workflow. The quality is insane, I think I found my new favourite model - the sharpness and textures are even better than in OLT! Thank you for your work, I especially liked the fact that 1536 resolution is now supported. This is the first SDXL checkpoint to achieve that, I think?
TLDR: it 100% worth it's money.
Thank you for your kind words xD I'm glad it works that well for you!
No, it's not the first one, it's the second one. @SubtleShader did it before me, although he goes a very different path with his checkpoints
Details
Files
lustifySDXLNSFW_ggwpV7.safetensors
Mirrors
lustifySDXLNSFW_ggwpV7.safetensors
lustifySDXLNSFW_ggwpV7.safetensors
lustify-ggpwp.safetensors
lustifySDXLNSFW_ggwpV7.safetensors
lustifySDXLNSFW_ggwpV7.safetensors
SDXLNSFW.safetensors
lustifySDXLNSFW_ggwpV7.safetensors
lustifySDXLNSFW_ggwpV7.safetensors
lustifySDXLNSFW_ggwpV7.safetensors
SDXLNSFW.safetensors
SDXLNSFW.safetensors
lustifySDXLNSFW_ggwpV7.safetensors
lustifySDXLNSFW_ggwpV7.safetensors
lustifySDXLNSFW_ggwpV7.safetensors
lustifySDXLNSFW_ggwpV7.safetensors
SDXLNSFW.safetensors
SDXLNSFW.safetensors
CinematicStyle-v1.safetensors
SDXL_REALISTIC_lustifySDXLNSFW_ggwpV7.safetensors
lustifySDXLNSFW_ggwpV7.safetensors
lustifySDXLNSFW_ggwpV7.safetensors
lustifySDXLNSFW_ggwpV7.safetensors
SDXL.safetensors
NSFW.safetensors
lustifySDXLNSFW_ggwpV7.safetensors
lustifySDXLNSFW_ggwpV7.safetensors
lusSDXL.safetensors
lustifySDXLNSFW_ggwpV7.safetensors
SDXLNSFW.safetensors
lustifySDXLNSFW_V7.safetensors
lustifySDXLNSFW_ggwpV7.safetensors
lustifySDXLNSFW_ggwpV7.safetensors
lustifySDXLNSFW_ggwpV7.safetensors
lustifySDXLNSFW_ggwpV7.safetensors
Lustify SDXL NSFW V7.safetensors
lustifySDXLNSFW_ggwpV7.safetensors
lustifySDXLNSFW_ggwpV7.safetensors
lustifySDXLNSFW_ggwpV7.safetensors
lustifySDXLNSFW_ggwpV7.safetensors
lustifySDXLNSFW_ggwpV7.safetensors
LUSTIFY.safetensors
lustifySDXLNSFW_ggwpV7.safetensors
lustifySDXLNSFW_ggwpV7.safetensors
lustifySDXLNSFW_ggwpV7.safetensors
lustifySDXLNSFW_ggwpV7.safetensors
lustifySDXLNSFW_ggwpV7.safetensors
lustifySDXLNSFW_ggwpV7.safetensors
lustifySDXLNSFW_ggwpV7.safetensors
lustifySDXLNSFW_ggwpV7.safetensors
lustifySDXLNSFW_ggwpV7.safetensors
lustifySDXLNSFW_ggwpV7.safetensors
lustifySDXLNSFW_ggwpV7.safetensors
lustifySDXLNSFW_ggwpV7.safetensors
lustifySDXLNSFW_ggwpV7.safetensors
lustifySDXLNSFW_ggwpV7.safetensors
lustify-ggpwp.safetensors
Available On (2 platforms)
Same model published on other platforms. May have additional downloads or version variants.