

Update 19.06.2026. Lustify V9 (Zenith) IS OUT!
This is the absolute final version of Lustify built on the SDXL architecture. You can find the full changelog and a breakdown of the new features there. <----------
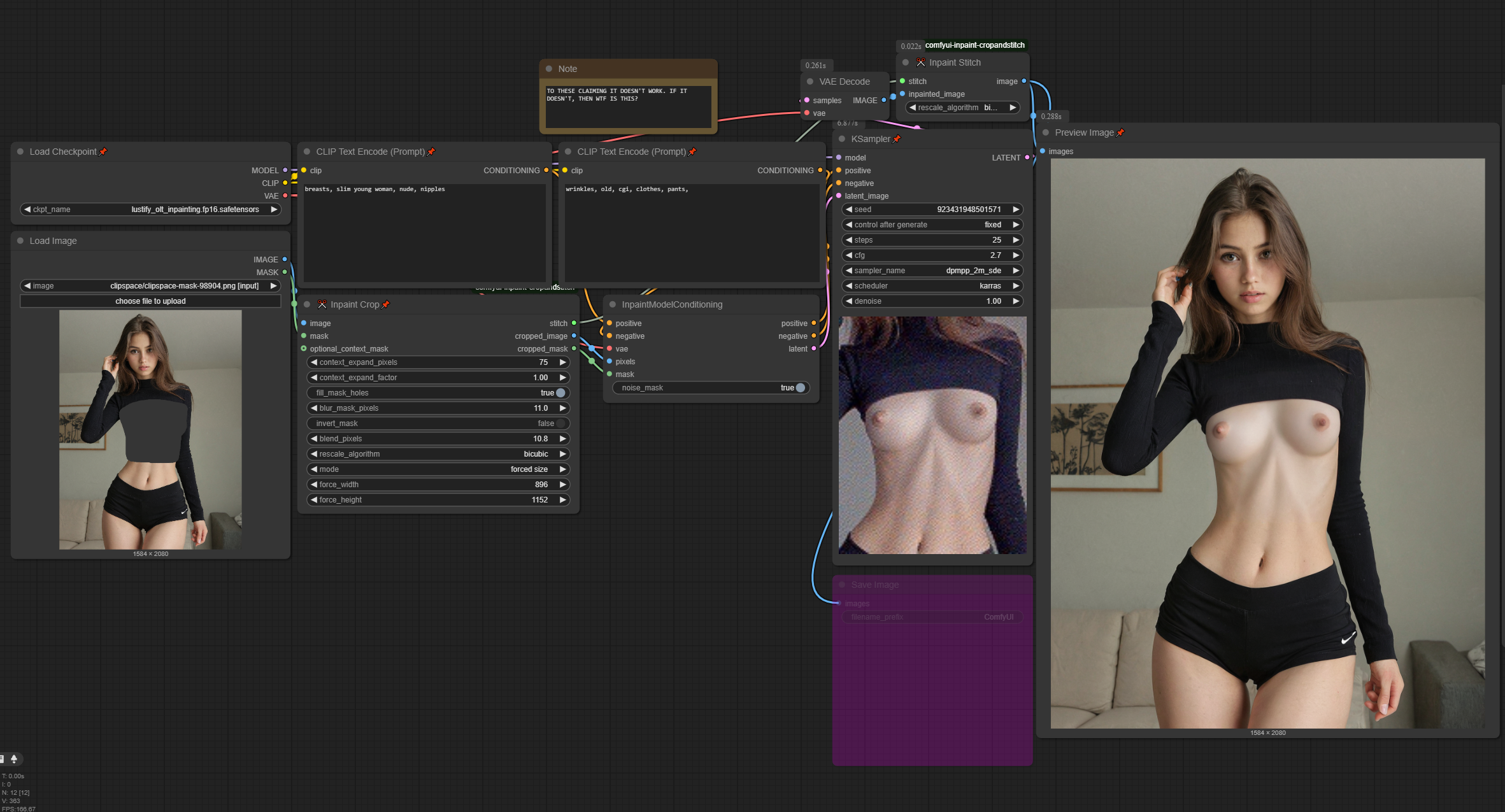
Recommended Workflow.
Alternative Access & Support: Outside of CivitAI's Early Access, you can get the model via my Boosty.
Just like last time, after the early access ends, there will be a 1-week period where the model is available for "on-site generation only." After that, it will become available for everyone to download.
Alternatively, you can make a direct Bitcoin (BTC) donation, just make sure to DM me after that: 1CoMZvrXtRXbz7BCzdvxifSjHqhaf1yUZs
LUSTIFY
Lustify is a photoreal checkpoint optimized for creating high-quality imagery of women in explicit/sexual scenarios. The model has been trained on a hybrid dataset, meaning it natively understands both Danbooru tags and natural language prompting.
Note: While it has a strong NSFW bias, if you guide it properly, it is fully capable of generating stunning SFW photography, objects, animals, and fantasy environments.
Crucial Points Before You Download:
NOT Pony or Illustrious-Based: This is a standard SDXL checkpoint. Do not use Pony/Illustrious LoRAs with it; they will not work correctly.
Distant Shots & Anatomy Limitations: Like 99% of SDXL models, distant shots can sometimes suffer from distorted faces or hands. This is an inherent limitation of the base technology (4 channel VAE), not the finetune. It is incredibly easy to fix using Inpainting or ADetailer. Please utilize these tools rather than reporting this as a bug.
Experimental Nature: My training workflow involves a lot of unconventional, high-risk experimentation. Because of this, some prompt combinations that worked perfectly on other checkpoints might behave differently here. If you encounter unexpected behavior, feel free to give feedback so I can look into it.
Recomended parameters:
Sampler: DPM++ 2M SDE/DPM++ 3M SDE,
Scheduler: Exponential/Karras
Steps: 30
Cfg: 2.5-4.5.
Highres.fix: upscale by 1.4-1.5, denoising ~0.4
For the distant shots of people you probably wanna use highres.fix and/or adetailer.
Also, use reasonable positive/negative prompts, shizoprompting does more harm than good (with any SDXL model).
Some tags that have a big visual impact with this model:
Camera type tags: "shot on Polaroid SX-70", "shot on Kodak Funsaver", "shot on GoPro Hero", "shot on Canon EOS 5D", "shot on Leica T".
Photography styles: "analog photo", "glamour photography", "street fashion photography", "candid photo", "amateur photo".
Lighting types: "cinematic lighting", "neon lighting", "soft lighting", "dramatic lighting", "low key lighting", "bright flash photography", "warm golden hour lighting", "radiant god rays".
Film types: "Ilford HP5 Plus", "Lomochrome color film", "Fujicolor Pro".
Photographers: Alessio Albi, Martin Schoeller, Miles Aldridge, Oleg Oprisco, Tim Walker.
Others: "film grain", "bokeh", "dreamy haze", "technicolor", "underexposed", "low quality", "lowres"
Alternatively, you can give a read to this wonderful prompting guide by PromptGeek. It has A LOT of useful tips I didn't know about even after years of using SD.
Description
You know what this is and what it is for. I know you do ;)
FAQ
Comments (137)
Hi coyotte, thank you so much for your amazing work on the last "inpainting" model—it's incredibly valuable to the community. We’ve encountered an issue when trying to use it with Fooocus, one of the most widely used interfaces for Stable Diffusion. The model seems to throw a weight shape mismatch error on load, likely due to an architecture expectation mismatch, which then leads to a failure in the denoise mask handling. If possible, a fix or Fooocus-compatible version would be deeply appreciated by many users. Thanks again for all your contributions!
Inpainting models and Fooocus aren't compatible. Fooocus has it's own inpainting modules, they just don't work together. You can't change that.
You need to either 1) Use the normal version for inpainting with Fooocus OR 2) Use it in an interface that doesn't force it's modules even when not requested (so, ComfyUI/A1111/Forge).
@coyotte Thanks for the help/feedback. I love your models, please keep going.
correct.. foocus just patches a normal sdxl model so it can inpaint, but you can also use standard illustrious models too
Hi Coyotte!, can you share your inpainting settings?. I never use inpainting models because when I tried I couldn't see any difference, maybe I was doing something wrong idk.
Hello. Mask the area, set denoising to 1, prompt "medium breasts, lifted shirt, nipples, young woman" or whatever you need, set sampler to 2M SDE Karras, 25 steps, cfg 3.
Inpainting model is needed to completely change something in the picture. When you inpaint with a "normal" checkpoint, the denoising value 1 would result in terrible not fitting result. The inpainting version
takes denoising set at 1 perfectly (or at least close to that).
@coyotte ok, thanks! I was using denoising at 0.5 and 'latent nothing' for the masked content (for big changes in the image), and it wasn't too bad, even with the dmd2 lora (LCM Exponential - cfg 1 - 8 steps)
Awesome model, can recommend. The DMD2 version of the Endgame release was super-fast and good, any plans to make DMD2 for new releases? Does the DMD2 merge requires further training after the merge?
No, it doesn't need further training. DMD2 version is literally normal checkpoint + DMD2 lora. And that's it
@coyotte Thanks for the reply. In that case, I'll do the merge and test it out myself!
is the OLT inpainting version grown out of the original smoother texture OLT or the fixed textures version?
Fixed version
@coyotte thanks
I kind of liked the smoother texture version. Is it still possible to download somewhere?
@kunde2 sorry i missed your comment. yes, he still has it up there, it's just moved to the absolute far right of the list.
The inpainting model is not working. Very bad results. Maybe mention settings for it to work like in the sample images.
"the inpainting model is not working for me" is a better way to say it, cause I just made the previews with it. Please define "bad results".
It definitely works with 2M SDE + Karras. Didn't test anything else, but I don't see the reason why it won't work with other samplers
@coyotte if you look at your comment section, you will find a couple more "for me" cases. No other inpainting model has those comments. "bad results" means you get "noisy" inpainted areas.
@ledeni80 "you will find a couple more "for me" cases" Like what? The one, where a person tries to use it with
Fooocus? The problem with it is obvious and I've replied to them. The one, where a person never uses inpainting models and doesn't know why/how to use them? Again. the problem in that case is obvious. It's not the model. It's the user error. So, it IS a "for me" case.
I mean, I can show you a couple cases where people have NO problems with it whatsoever. You won't make me think that it doesn't work, because IT DOES as I've seen it with my own eyes and I didn't have to do anything extraordinary to make it work. The uploaded version is the one I've used for the previews. The workflow was literally "mask the area, set denoising to 1, prompt "medium breasts, lifted shirt, nipples", set sampler to 2M SDE Karras, 25 steps, cfg 3". It can't be more straight-forward than that and I thought this all was a common sense.
@coyotte The results this checkpoint produces are worse than any 1.5 ( i know that this is xl) inpainting models I have used in terms of detailsa nad every other aspect. 1.5 models are not only better but also faster. Not to mention the noise in the inpainted area. Unusable.
@ledeni80 Okay, if you say so. What the fuck do I even know, right
@coyotte Obviously not enough about inpaint models
@ledeni80 yet you're the one who couldn't make it work. Again, the previews were made with the same checkpoint I've uploaded. The previews look fine. I have people saying that this new version of inpainting rocks (ffs, DM and I'll send you screenshots if you're so hard to convince). Are you seriously implying that I'm gatekeeping the REAL version the previews were made with?
So, I'd argue with you on who knows "not enough", bruv. But it seems like it would be no use - you're so stubborn and sure of your some kind of superiority.
Just go back to using what was working for you. It's not like I'm holding a gun to your head
If it "doesn't work", explain this https://civitai.com/images/66451056
@coyotte Are you serious? Even on that screen it shows how it produces low-quality results. Even on that featureless skin. The latest cyberrealistic inpaint (mind you 1.5 model) is light years ahead of your model. Actually, all of the earlier versions are also. There are too many one-click inpaint models around here, spamming the feed for no reason. Your model got deleted. The only reason I am still writing are your comments spaming my notifications.
@ledeni80 oh, so NOW it's working, huh? You were just saying that it got you "noisy" inpainted areas, but now they have "featureless skin"? Can you at least make up your mind? It was a quick demo to show that everything you said above was bullshit. I've never said it was "CRAZY GOOD". This inpainting model was made just because people were asking for it for a long time. But it isn't nearly as bad as you picture it, it's just you.
"Your model got deleted" - I don't know what you're talking about, some dellusional hallucinations of yours perhaps? Do you have that often? Eveything is still up there.
Please, stop making yourself look like a joke, mr. anonymous account with no demonstrations of "how it needs to be done". That's not healthy. You can always block me if I'm bothering you, spamming your notifications xD And yeah, DON'T USE this model even if your life depends on it. I don't need people like you around me.
@ledeni80 I've been to circus so many times, yet this is the first time I see this type of clownery.
I had to download the checkpoint just to see what this all was about. Not only it worked without any tweaks, but it also outperformed my go-to checkpoint (Juggernaut Inpainting). So... thanks for bringing my attention to this one, I guess? @coyotte Seems like this dude's just a pathetic troll trying to feed on your reactions. Better to ignore them completely
@coyotte I haven't inpainted in awhile. You guys really using comfy directly? Isn't that a pain to mask in another program and then manually load image?
@brnlittokhoes311 you don't need to paint the mask in the other programs anymore. It's all done in Comfy now
@ledeni80 Tried his workflow after a mistake in my end and it works fine with decent quality if your prompt is fine.
@Lena_Luna Well if your "go-to" is Juggernaut that explains a lot actually.
@ledeni80 ?
Thanks for your model! What resolution do you recommend?
896x1152
832x1216
1024x1024
1024x1536
это просто праздник какой то
best inpaint model what i see!!
Спасибо!
I cannot get good results like in the preview images with inpaint model. I must be doing something wrong but I copied all your settings and set to 1.0 strength and at first it was only mildly changing things and leaving them pixelated so I enabled the "inpainting encode" in swarmui, this was working better but it's now changing too much and the final result is not blending well.
Like I see in your example you change the lollipop in her hand, and her hand remains the same while the object changes only, that does not happen for me. Same thing for the other example where her abdomen is the same but it's only the clothes removed.
I have not had much experience with inpainting models, so if you notice I am doing something wrong please let me know, I am using swarmUI standard tabs without messing with comfy.
I really wish I could help, but I have no experience with SwarmUI (even tho it's just Comfy with UI).
Just some general tips:
1) you NEED to limit the context while inpainting, like you do when you press "masked area only" in Automatic1111/FORGE. I don't know how to do this in Swarm, but in Comfy it's done with Crop-n-stitch nodes like you see in the screenshot. It really matters.
2) sometimes you might need to make a second pass on the inpainted area with a regular lustify version, with denoising strength ~0.25-0.3 just to give it a bit more texture. Idk, I had to do this with every inpainting model I've tried, mine isn't an exception
I have been getting better results with some practice and step 2 seems useful I will try it :) thanks
Quick question, why there's ppl thinking the endgame one is better than this? what's the difference?
Well, there's also people that switched to OLT exclusively xD Endgame's gallery is almost dead, while OLT's frequently gets updates.
It really comes down to your preferences. They have different look.
kinda noob question, do we need sdxl_vae?
Not sure about this model, most models have vea “build in”, if image looks really bad then probably you need to use separate vea. Just try one with and one without. Hope that will help you 😁
No, it's baked in
What would be the optimal negatives you'd recommend? when prompting for the best photorealistic amateur picture look?
I recall you mentioned using zero negatives in one of your earlier comments, this still holds true for OLT fixed?
Thanks.
There are no optimal negatives. Personally I don't use any. Negatives were very important with SD1.5 for improving quality. Not so with SDXL.
@SubtleShader thanks!. I'll continue using no negs with your model.
I do think though they might have an affect on certain models, atleast i have come across illustrations as output instead of photorealistic unless negg'd. also some other wonky renders without negs in some other models.
@makaveli_313 I suggest you to use this lora I've trained for Lustify OLT. https://civitai.com/models/1439962/leakcore-leaked-nudes-style
@coyotte Congrats on your first lora!
Try this prompt after your positive prompt:
, ((photorealistic)), ((RAW photo)), ((8K resolution)), ultra-detailed, ultra-sharp focus, realistic skin texture, visible pores, subsurface scattering, lifelike skin tones, natural facial expressions, realistic imperfections (fine lines), accurate color grading, true-to-life tones, natural composition, authentic details, Nikon D850 DSLR photo, full-frame sensor, masterpiece, award-winning photography, best quality, (realistic eye highlights)
and this one as your negative prompt:
(worst quality, low quality, bad quality, poor quality, terrible quality), (bad anatomy, wrong anatomy, broken anatomy, malformed, mutated, disfigured), (distorted proportions, awkward pose, uncomfortable pose), (overexposed, underexposed, oversaturated, over sharpened, overfiltered, bad lighting), (lowres, low dpi, pixelated, compression artifacts, jpeg artifacts, aliasing), (blurry, motion blur, smudged, rough sketch, unfinished, messy), (extra fingers, fused fingers, missing fingers, deformed hands, mutated fingers, twisted hands, missing hands), (extra limbs, fused limbs, disconnected limbs, missing limbs, abnormal limbs), (ugly face, uncanny face, worst face, deformed eyes, asymmetrical eyes, (cross-eyed:1.5)), (plastic skin, waxy skin, doll-like, CGI, fake skin), (tan lines:2), monochrome, grayscale, cartoon, anime, sketch, illustration, vector art, emoji, meme, watermark, signature, artist name, placeholder, text overlay, logo, sample watermark, instagram filter, censor, censored, mosaic censoring, obstructed view, style mismatch
@vicaut Oh no... please don't spread this misinformation. Most of these tags don't actually make your output better. "disconnected limbs, abnormal limbs" do you really think the photos of people, real photos that i used as training data, would have these? Such things don't exist in real life. These words mean nothing to AI, because I didn't caption the photos with these. This applies to most of what you've listed there.
It's not SD 1.5 anymore. You really don't need this.
@SubtleShader first public lora :) Thanks!
@coyotte Well try it, and judge later
@vicaut You are funny. I'll give you that. 🤣
@coyotte and i use these prompts not only for your checkpoint, but for all SDXL and SD 1.5 checkpoints if i want more realistic pictures. There are even more prompts i use like cinematic lighting, soft ambient lighting, shallow depth of field, volumetric light, realistic shadows and reflections, ray-traced lighting if there should be a light soure involved - also works great. I even use special prompts for hires fix and adetailer. If some prompts are useless for some checkpoints, no problem, at least they won't do any harm to the quality.
@SubtleShader well try it, and judge later. This will work at least for better realism (not for an amateur picture look).
@makaveli_313 just try a prompt with the same seed with and without my addidional prompts and compare.
@vicaut Sorry, but I won't use that mess of a prompt. Hard pass. Robs my prompts of tokens that I can use better for other things. I admire your confidence to suggest something to people who actually tried thousands of prompts when creating their models. Including the stuff that you are suggesting.
@coyotte oooh... I will try this later today. Would it work fine on olt fixed textures model too?
@makaveli_313 it's made for OLT specifically
@coyotte thanks ill provide feedback later directly on lora page.
omg,it look so real for your checkpoint,i am loving it, two thumbs up.
Hey, not sure how else to contact you but fyi, i just sent you some bitcoin to help support your efforts. If you wouldn't mind conversing sometime, you can contact me on github with the same username.
Hey, I was wondering who I should thank.
Thanks a lot, I really appreciate your help!
Sure, I'll contact you on github later
@coyotte No hurry and no obligation to contact me here or there. Just thought we could discuss "joining forces" somehow.
@vonespy I've sent you a message on civit, check your DM
Hello !
I have a question concerning img2img (on full image).
I have very good result with DMD2 version of Lustify (I use regional prompter with only 1 active Lora + cany controlnet).
But strangely, I can't get good result with the non-DMD2 version. Tried different samplers and settings.. any advices ?
Will you do a DMD2 version of the latest model ?
Thank you for your magnificient work 🙏
You don't need a special DMD2 version. Just download the DMD2 lora from https://huggingface.co/tianweiy/DMD2/blob/main/dmd2_sdxl_4step_lora_fp16.safetensors and use it together with the chrckpoint.
Yes, much more pleasant to work with the DMD2. Much faster, less anatomy problems and usually looks more photorealistic. Without DMD2 use the SDE sampler with Karras scheduler.
@SubtleShader What are the best settings for this in Ur opinion
In comparison flux seems like drunken scribbles, absolutely amazing.
thank you so much for the checkpoint. it works so fast and good <3
Fishnet bodysuits are kinda weird, they don't look that good in my opinion
CHECK OUT MY NEW LORA CALLED "LEAKCORE". It's purpose to create believable amateur nude photos, that look like these that were leaked (no actual leaks were or will be used, that's a hard "no").
https://civitai.com/models/1439962/leakcore-leaked-nudes-style
What does light leak do
I get grey output with OLT
Hi! How do I use such a model in python?
Im using the following code
pipeline = AutoPipelineForText2Image.from_pretrained("black-forest-labs/FLUX.1-dev", torch_dtype=torch.bfloat16)
pipeline.load_lora_weights('downloads/', weight_name='lustifySDXLNSFW_oltFIXEDTEXTURES.safetensors')
and getting the error
ValueError: Invalid LoRA checkpoint.
Thank you, any helps is appreciated
I have zero experience with running SD through terminal only (I guess that's what you are trying to do), but judging by the error message, you are trying to use it as a lora for Flux (?).
This isn't a lora, but a full checkpoint. It's intended to be used on it's own
@coyotte Thank you for the quick reply. Indeed, after your comment, the fix was easy: just load the model as follows: from diffusers import StableDiffusionXLPipeline
pipe = StableDiffusionXLPipeline.from_single_file("lustifySDXLNSFW_oltFIXEDTEXTURES.safetensors")
@lucasnuzdas4481 This is really great code snippet ,thank you! Could you please provide further references to develop further scripts? Thanks
What is the ideal pixel size that this checkpoint is trained on
896x1152
832x1216
1024x1024
1024x1536
Hi! Can anyone export a Comfy workflow in Python? It would be great, Thank you, here is a plugin: https://github.com/pydn/ComfyUI-to-Python-Extension
Great checkpoint but how do you make SFW images? The problem I'm having is if I want the girl to be covered up but mention her breast size, I always get her pulling up her shirt even with negative prompts. putting "large breasts" into the prompt almost always creates NSFW images. please help.
try prompts such as cleavage or make sure the girl put some clothes on
how to generate sfw stuff with this? always shows exposed boobs no matter what negative prompts i put
try prompts such as cleavage and buy her some clothes
Hello, I'm in the process of learning SD. However, may I ask if these checkpoints especially the inpainting working with SD Forge?
Yes, they do
@coyotte Thank you for your reply.
Hello, im still new in AI Image generating. Im using your checkpoints in comfyui using template workflow SD 3.5. Why am always i getting blank image/black image?
Cause this isn't SD 3.5-based. You need to use SDXL-compatible workflow
Endgame was the right direction.
It's still up there, free to use.
I wanted to make something different, so I did exactly that
@coyotte I agree it is inherently different, so maybe releasing it as something else would have been the right move here, that is simply my poorly informed opinion. You released something inherently different under the umbrella of something unlike it. To me, it seems dishonest to your artistic prowess, and the possible legacy of the definitive version of Lustify which is Endgame and not OLT.
TL;DR You are the artist, don't obfuscate your creations with one another is all I really am trying to say. Both amazing executions
@coyotte would you consider going 'in the direction' of Endgame for your next one?
Thanks
@Yushio What do U think is not in OLT that is in Endgame that U think makes OLT different and Endgame much better ?? I am using both but I am just more interested in what Ur opinion is further in elaborate detail
Thanks
@sam48052023878 OLT doesn't have something missing. They are inherently very different. If you look through the OLT and the ENDGAME Generations you can visually see there is a clear distinction between the two. OLT images look like they were taken by a professional photographer and should be on Instagram or some gallery no matter the quality of the image. While not being as stable. Endgame is rough, It could be used with ease with SFW with little tweaking and it was very stable. Images can be generated and look like a total noob at photography or someone who just picked up a phone camera.
OLT has a more refined commercial feel.
Endgame feels more malleable and rough.
There aren't missing things, they are just different.
@Yushio Precisely described. I can't speak for most of the people but I strongly feel Engame was the correct direction.
Apologies if you have already answered this:
When you recommend the denoising strength to be ~.4, what upscaler should it be?
Any you like. I use Superscale and Siax
@coyotte Ah ok, I just assumed the performance of the denoising strength varied greatly between different upscalers. Thank you
everything i gen comes out blurry and swirled. I've matched the settings and tried with multiple versions but everything comes out bad, any ideas?
what are you using comfyui? or on civitai i use comfyui and with the right settings as mentioned in the info its good
IOPain + choose lcm lora (built in) and you fixed!
@png i'm having the same problems as OP, what is "IOPain" where do i find the lcm lora?
@atomo111 you don't need this to make the model work. You definitely have something set wrong if you don't get the good results. Try the parameters I've listed in the description.
Very nice
am i the only one getting this error:
CLIPTextEncode
ERROR: clip input is invalid: None?
Seems like you didn't connect clip output from checkpoint loader to your prompt box.
I'm trying to use the inpaint model but the painted area hardly changes. It is basically the same before-after. What am I doing wrong? I used CFG from 3 to 7 but the results are all similar.
Nevermind I'm a dumbass. I thought Denoising strength is meant for literal denoising (like a post processing step) and set it really low.
i'm new too. so do you put denoise all the way to max level then? do you change your prompt or keep it blank?
I'm enjoying this generator. Thank you.
i have a question about your latest MODEL v6
is this a more realistic version compared to v5 endgame or is it more for non realistic images?
@coyotte can you help me with this question i want to know if V6 is more realistic compared to v5 endgame
@sonic4life170 I would say in terms of realism, for me at least, its hard to tell much of a difference, both are so fkn good!
@ronikush yes thats true there is not so much quality difference i found out that the textures are better in the V6 model, but coyotte said something about the quality but still its a bit confusing cause there is a difference between realism and realistic....... i agree they are great its the best model i am still using endgame. cause i am not sure about the super realistic outcome
What to do when it continuously creates NSFW for me? I give negatives, give different prompts and always have NSFW. i would like to SFW sometimes : D FOOcus
For me I have most success when I cut out using negatives completely and if going for SFW try to describe the clothing in as much detail as possible
Even if I mostly use img2img, the latest checkpoint version (OLT) stands out among all SDXL checkpoints I've tested so far; it creates unique facial features, gives my images the vibe I'm looking for (and honestly often surprises me with enhancing them in ways I didn't expect!) and works remarkably well with the loras I want to use.
The creator behind this checkpoint has done a terrific job.
I do really hope it makes into the next week's checkpoints, it's currently sorely missed (yes, I threw in a little bid into that auction system, keeping my fingers crossed).
whats your recommended settings/workflow to get good img2img results?
whats your recommended settings/workflow to get good img2img results?
@atomo111
Hi, a typical workflow when I use img2img can look like this (Keep in mind though that my workflow is set up with the desire to create a realistic image. It could be completely different if you want an artsy image or painting style):
1. Uploaded image size: Mostly equals the default size in the generator (1024x1024 etc). I often work with a cartoonish/anime stylish picture where I've got the basic desired pose, angle or thematic element (I use NovelAI to create this "base image" because I feel comfortable with its quick rendering and prompting language and especially the ability to use an Inpaint tool, but in theory it should work with using any Pony/Illustrious checkpoint to render a base image on this site as well, though I can't recall myself having done that.)
2. CFG scale: Almost never higher than 4.0 - it's easier for a checkpoint for realistic images to render a more unique image with a lower value from my experience.
3. Sampler: DPM++ 2M Karras if I wants more attention to details, which I usually do (But always read what the creator of the checkpoint has suggested) :)
4. Steps: Usually 30-50, I like to experiment with this. Lower can work too (especially if I switch sampler to Euler).
5. Denoise: About 0.45-0.60. This depends on the base image, sometimes, if not mostly, a higher value increase aesthetic value (from my personal view), but can lead to undesired content such as bad hands, eyes etc. I often do at least two images with different denoise settings to see what effect it has. Loras can also tend to add undesired content, and I try to change their strength to see what that leads to. I find myself often use a slightly lower denoise level when rendering the first image, and then I increase denoise when doing the hi-res fix.
The generated image I find to be good enough is often put through hi-res fix unless the first one already is great. Step 2-5 above are repeated, with eventual adjusting in step 4-5. NB: The hi-res image sometimes fails! Bad eyes and bad hands can be a result (hands are often quite challenging). I try to adjust denoise and steps and retry. Sometimes I say "Fine, the 1st one was good enough, post and move on," to myself. It can even be caused by the base image simply not being suitable, and I have to discharge it completely after several tries.
Lastly, I use face fix if needed. It doesn't always work, it can worsen the quality, but it can fix blurry or deformed eyes or strange skin hue. I experiment with different kind of skin detail loras to see if they help with this.
About Loras: If you are uncertain about loras - Always begin with only using the checkpoint.
Then add loras one by one to see what they add/change until you find it to be satisfying (this is perhaps the most fun part - to search for those hidden gems around on this site!). Don't throw in five, six loras at once, it makes it difficult to exclude which one causes undesired content. Do also take a look at the checkpoint site if the creator has added suggested resources, helpful in enhancing image quality, or check the published images by other users to see what loras they've used and with what strength, depending on what type of image you are trying to create.
All steps above are done usually with the desired prompts, checkpoint and loras from beginning once I've gradually built up the resources I like. I can switch loras before hi-res, just to experiment.
As you probably realize, this type of workflow demands you commit some time o it and it consumes a lot of buzz, and I fail (a lot). It's not a perfected workflow by any means. But a famous chef ones said something like "If you fear to fail you should never try to cook food".
I hope this was helpful as I tried to be as specific as possible. It turned into a whole novel, sorry! I am far, far from an expert.
@Tapiola85 This is so incredibly helpful thank you so much!! I've been really struggling with img2img so your response is invaluable to me. So kind of you to lay it all out. Thank you for also mentioning the lora's, most of the one's i've been using haven't been working well on this checkpoint but lustify is my fav checkpoint ever so i'm going to play around with them a bit more to see what works best. I'm looking for super realistic images with film like quality. Thank you again. I'm saving your reply
@atomo111 Glad I could help! :)
can anyone recommend lora's that play well with this, love this model, might be my fav ever but majority of loras i've tried make the images look like they're melting :/
Is it me sucking at prompting or this model struggles with anal? Tried a bunch of prompts and weights in both Endgame and OLT and it always fails.
yes both these models have difficulty at creating anal penetration but on the other hand DMD2 makes anal images as it is no business, try DMD2 and lemme know does that work for U
@sam48052023878 Thanks for the recommendation but it didn't work for me. I used all sorts of prompts and weighting with both Booru tags and natural language, but it didn't produce a single one.
What prompts and workflow are you having success with?
For LCM+Exponential:8step/1cfg
I'm getting better results using 7 or 8 steps for the highres-fix and sd ultimate upscale. More skin details, not as blurry.
how to use this with fooocus can u teach me?
@kr96aditya I have no experience with fooocus sorry. I use ComfyUI.
interesting, what do you mean by highres fix? it's a lora ? ... what is your ksampler config?
@mfudi I'm using ComfyUI. Highres Fix is a node from here: https://github.com/jags111/efficiency-nodes-comfyui
Details
Files
lustifySDXLNSFW_oltINPAINTING.safetensors
Mirrors
lustifySDXLNSFW_oltINPAINTING.safetensors
lustifySDXLNSFW_oltINPAINTING.safetensors
lustifySDXLNSFW_oltINPAINTING.safetensors
lustifySDXLNSFW_oltINPAINTING.safetensors
lustifySDXLNSFW_oltINPAINTING.safetensors
lustifySDXLNSFW_oltINPAINTING.safetensors
lustifySDXLNSFW_oltINPAINTING.safetensors
lustifySDXLNSFW_oltINPAINTING.safetensors
lustifySDXLNSFW_oltINPAINTING.safetensors
lustifySDXLNSFW_oltINPAINTING.safetensors
lustifySDXLNSFW_oltINPAINTING.safetensors
Available On (2 platforms)
Same model published on other platforms. May have additional downloads or version variants.