All in One, Wan for All
We are excited to introduce our latest model to our talented community creators:
Wan2.1-VACE, All-in-One Video Creation and Editing model.
Model size: 1.3B, 14B License: Apache-2.0
If we are in Wan Day, what will it be like? 如果我们在万相世界,会是什么样子?
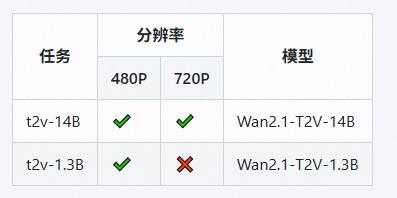
模型支持两种文本到视频模型(1.3B 和 14B)和两种分辨率(480P 和 720P)。
WAN-VACE is not a T2V model per se, but rather R(reference)2V, Can be understood as Video ControlNet for WAN , so there is no way to provide a T2V workflow. The CausVid accelerator is a distillation accelerator technology that can be used on WAN-VACE to provide 4-8 steps of accelerated generation.
WAN-VACE本身不是T2V模型,而是R(参考)2V,可以理解为WAN的视频CN,因此无法提供T2V工作流程。CausVid加速器是一种蒸馏加速技术,可用于WAN-VACE,提供4-8步加速生成。
Introduction
VACE is an all-in-one model designed for video creation and editing. It encompasses various tasks, including reference-to-video generation (R2V), video-to-video editing (V2V), and masked video-to-video editing (MV2V), allowing users to compose these tasks freely. This functionality enables users to explore diverse possibilities and streamlines their workflows effectively, offering a range of capabilities, such as Move-Anything, Swap-Anything, Reference-Anything, Expand-Anything, Animate-Anything, and more.

VACE是一款专为视频创建和编辑而设计的一体化模型。它包括各种任务,包括视频生成(R2V)、视频到视频编辑(V2V)和屏蔽视频到视频剪辑(MV2V),允许用户自由组合这些任务。此功能使用户能够探索各种可能性,并有效地简化他们的工作流程,提供一系列功能,如移动任何内容、交换任何内容、引用任何内容、扩展任何内容、为任何内容设置动画等。
About CausVid-Wan2-1:
5-16 The PERFECT solution to CausVid from Kijai (Best practices)
Wan21_CausVid_14B_T2V_lora_rank32.safetensors · Kijai/WanVideo_comfy
Through weight extraction and block separation,
KJ give us a universal CausVid LoRA in rank32 for Any 14B WAN model,
EVEN including FT models and I2V model!
Although this may not have been CausVid's initial intention, by flexibly adjusting the LoRA parameters (0.3~0.5), we have achieved unprecedented availability on home grade graphics cards!
KJ-Godlike also provides a 1.3B bidirectional inference version of LoRA export file
Wan21_CausVid_bidirect2_T2V_1_3B_lora_rank32.safetensors
same time, we also noticed that xunhuang1995 uploaded the Warp-4Step_cfg2 autoregressive version 1.3B CausVid model from: tianweiy/CausVid
相与为壹,全部在万
Best Adaptation for WAN-VACE full Models
5/15 REDCausVid-Wan2-1-14B-DMD2-FP8 Uploaded 8-15 steps CFG 1
本页面右侧下载列表,Safetensors 格式,workflow 在 Trainning data 压缩包内
The download list on the right side of this page is in Safetensors format, and the workflow is included in the Training data compressed file. The example images and videos also include workflows (yes, you can directly throw the original video files into ComfyUI and try to capture the workflow)
5/15 Aiwood WAN-ACE Fully functional workflow Uploaded
5/15 ComfyUI KJ-WanVideoWrapper have been updated
5/14 autoregressive_checkpoint.pt 1.3b Uploaded , PT UNET Loader
5/14 bidirectional_checkpoint2.pt 1.3b Uploaded , PT UNET Loader
NEW Sampler Flowmatch_causvid in KJ-WanVideoWrapper
Releases from:
⭐ leave a star⭐
[ The adaptability test results of WAN1.2 LoRAs for VACE show that about 75% of I2V/T2V LoRA weights can take effect, but the sensitivity is reduced ( try to increase the LoRA weight ,more than 100% Sometimes it can be helpful ) ]
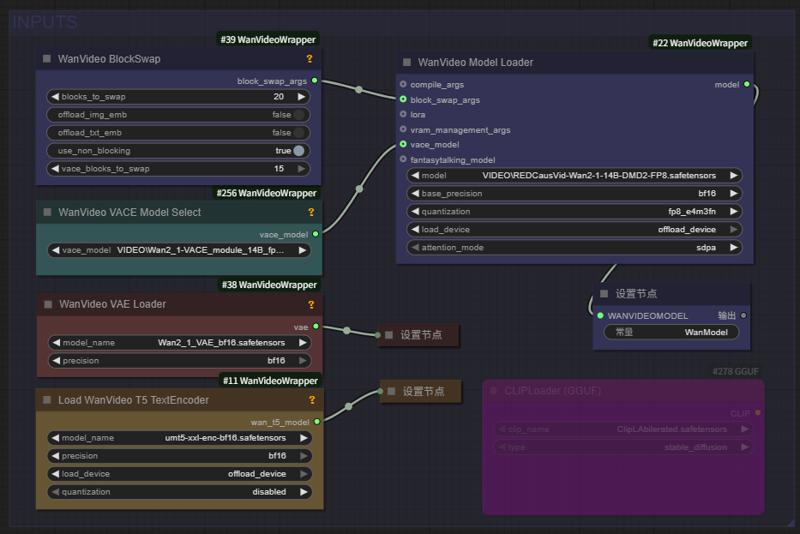
Fullview of Aiwood WAN-ACE Fully functional workflow:

source: https://www.bilibili.com/video/BV1FGE6zGEDK ⭐ leave a star⭐
 CausVid 加速器项目页 https://causvid.github.io/
CausVid 加速器项目页 https://causvid.github.io/
WAN-VACE 模型的参数和配置如下:
📌 Wan2.1-VACE provides solutions for various tasks, including reference-to-video generation (R2V), video-to-video editing (V2V), and masked video-to-video editing (MV2V), allowing creators to freely combine these capabilities to achieve complex tasks.
👉 Multimodal inputs enhancing the controllability of video generation.
👉 Unified single model for consistent solutions across tasks.
👉 Free combination of capabilities unlocking deeper creative
📌 Wan2.1-VACE为各种任务提供解决方案,包括参考视频生成(R2V)、视频到视频编辑(V2V)和屏蔽视频到视频剪辑(MV2V),允许创作者自由组合这些功能来实现复杂的任务。
👉 多模态输入增强了视频生成的可控性。
👉 统一的单一模型,实现跨任务的一致解决方案。
👉 自由组合功能,释放更深层次的创造力
WAN实时生成来了!Hybrid AI model crafts smooth, high-quality videos in seconds
The CausVid generative AI tool uses a diffusion model to teach an autoregressive (frame-by-frame) system to rapidly produce stable, high-resolution videos.
Wan2.1based 混合AI模型在几秒钟内(9帧/秒)制作出流畅、高质量的视频
CausVid生成AI工具使用扩散模型来指导自回归(逐帧)系统快速生成稳定的高分辨率视频。
From Slow Bidirectional to
Fast Autoregressive Video Diffusion Models
CausVid https://causvid.github.io/
tianweiy (Tianwei Yin)
RedCaus/REDCausVid-Wan2-1-14B-DMD2-FP8 Uploaded / WAN-VACE14B 最佳适配
CausVid/autoregressive_checkpoint uploaded / 自回归模型基于 WAN1.3B 已收录
CausVid/bidirectional_checkpoint2 uploaded / 双向推导模型基于 WAN1.3B 已收录
Kijai/Wan2_1-T2V-14B_CausVid_fp8_e4m3fn.safetensors / HF仓库 WanVideo_comfy
⭐ leave a star⭐

licensed by Creative Commons Attribution Non Commercial 4.0
Thank you for this friend's additional comment. I was too excited last night and didn't sleep, so I stopped updating before finishing:
We’ll need to use the official Python-based inference codes
1) Clone https://github.com/tianweiy/CausVid and follow instructions to install requirements
2) Clone https://huggingface.co/Wan-AI/Wan2.1-T2V-1.3B into wan_models/Wan2.1-T2V-1.3B
3) Put the pt file inside checkpoint_folder/model.pt
4) Run inference code, python minimal_inference/autoregressive_inference.py --config_path configs/wan_causal_dmd.yaml --checkpoint_folder XXX --output_folder XXX --prompt_file_path XXX
Reddit posts about CausVid: https://www.reddit.com/r/StableDiffusion/comments/1khjy4o/causvid_generate_videos_in_seconds_not_minutes/
https://www.reddit.com/r/StableDiffusion/comments/1k0gxer/causvid_from_slow_bidirectional_to_fast/
We have tested the CausVid based on Wan1.3b version, which has incredible speed, and are currently testing the 14B version produced by lightx2v.
 LightX2V: Light Video Generation Inference Framework
LightX2V: Light Video Generation Inference Framework
Supported Model List
How to Run
Please refer to the documentation in lightx2v.
⭐ leave a star⭐
通义实验室 WAN 2.1 Model Zoo
Institute for Intelligent Computing专注于各领域大模型技术研发与创新应用。实验室研究方向涵盖自然语言处理、多模态、视觉AIGC、语音等多个领域。我们并积极推进研究成果的产业化落地。实验室同时积极参与开源社区建设,全方位拥抱开源社区,共同探索AI模型的开源开放。
Developer / Models Name / Kijai`s ComfyUI Model
RedCaus/REDCausVid-Wan2-1-14B-DMD2-FP8 Uploaded / WAN-VACE14B 最佳适配
CausVid/autoregressive_checkpoint included / 自回归模型基于 WAN1.3B 已收录
CausVid/bidirectional_checkpoint2 included / 双向推导模型基于 WAN1.3B 已收录
CausVid/wan_causal_ode_checkpoint_model testing / 自回归因果推导 测试中
CausVid/wan_i2v_causal_ode_checkpoint_model testing / 文生图模型 测试中
lightx2v/Wan2.1-T2V-14B-CausVid unqualify / 自回归模型14B AiWood实测不达标
lightx2v/Wan2.1-T2V-14B-CausVid quant unqualify / 自回归模型14B量化版 实测不达标
Wan Team/1.3B text-to-video included / 文生视频1.3B 已收录
Wan Team/14B text-to-video included / 文生视频14B 已收录
Wan Team/14B image-to-video 480P included / 图生视频14B 已收录
Wan Team/14B image-to-video 720P included / 图生视频14B 已收录
Wan Team/14B first-last-frame-to-video 720P included / 视频首尾帧 已收录
Wan Team/Wan2_1_VAE included / KiJai‘s WAN视频VAE 已收录
ComfyORG/Wan2.1_VAE included / Comfy‘s WAN视频VAE 已收录
google/umt5-xxl umt5-xxl-enc safetensors included / TE编码器 已收录
mlf/open-clip-xlm-roberta-large-vit-huge-14 safetensors included / CLIP编码器 已收录
DiffSynth-Studio Team/1.3B aesthetics LoRA 美学蒸馏-通义万相2.1-1.3B-LoRA-v1
DiffSynth-Studio Team/1.3B Highres-fix LoRA 高分辨率修复-通义万相2.1-1.3B-LoRA-v1
DiffSynth-Studio Team/1.3B ExVideo LoRA 长度扩展-通义万相2.1-1.3B-LoRA-v1
DiffSynth-Studio Team/1.3B Speed Control adapter 速度控制-通义万相2.1-1.3B-适配器-v1
PAI Team/ WAN2.1 Fun 1.3B InP 支持首尾帧 / Kijai/WanVideo_comfy
PAI Team/ WAN2.1 Fun 14B InP 支持首尾帧 / Kijai/WanVideo_comfy
PAI Team/ WAN2.1 Fun 1.3B Control 控制器 / Kijai/WanVideo_comfy
PAI Team/ WAN2.1 Fun 14B Control 控制器 / Kijai/WanVideo_comfy
PAI Team/ WAN2.1 Fun 14B Control 控制器 / Kijai/WanVideo_comfy
PAI Team/ WAN2.1-Fun-V1_1-14B-Control-Camera / Kijai/WanVideo_comfy
IIC Team/ VACE-通义万相2.1-1.3B-Preview / Kijai/WanVideo_comfy
IC ( In-Context ) Controler 多模态控制器 :
ali-vilab/ VACE: All-in-One Video Creation and Editing / Kijai/WanVideo_comfy
Phantom-video/Phantom Subject-Consistent via Cross-Modal Alignment
KwaiVGI/ ReCamMaster Camera-Controlled 镜头多角度 / Kijai/WanVideo_comfy
Digital Character 数字人 via Wan2.1 :
ali-vilab/ UniAnimate-DiT 长序列骨骼角色视频 / Kijai/WanVideo_comfy
Fantasy-AMAP/ 音频驱动数字人 FantasyTalking / Kijai/WanVideo_comfy
Fantasy-AMAP/ 角色一致性身份保留 FantasyID / Fantasy-AMAP/fantasy-id
Uncensored NSFW 解锁版本:
REDCraft AIGC / WAN2.1 720P NSFW Unlocked / forPrivate use【非公开】
CubeyAI / WAN General NSFW model (FIXED) / The Best Universal LoRA
昆仑万维发布 SkyReels based on Wan2.1
Skywork / SkyReels-V2-I2V-14B-720P / Image-to-Video / Kijai/WanVideo_comfy
Skywork / SkyReels-V2-I2V-14B-540P / Image-to-Video / Kijai/WanVideo_comfy
Skywork / SkyReels-V2-T2V-14B-540P / Text-to-Video / Kijai/WanVideo_comfy
Skywork / SkyReels-V2-T2V-14B-720P /Text-to-Video / Kijai/WanVideo_comfy
Skywork / SkyReels-V2-I2V-1.3B-540P / Image-to-Video / Kijai/WanVideo_comfy
AutoRegressive Diffusion-Forcing 无限长度生成架构
Skywork / SkyReels-V2-DF-14B-720P / Text-to-Video / Kijai/WanVideo_comfy
Skywork / SkyReels-V2-DF-14B-540P / Text-to-Video / Kijai/WanVideo_comfy
Skywork / SkyReels-V2-DF-1.3B-540P / Text-to-Video / Kijai/WanVideo_comfy
昆仑万维发布 SkyReels 视频标注模型:
Skywork / SkyCaptioner-V1 Skywork (Skywork) / Skywork/SkyCaptioner-V1
Tiny AutoEncoder / taew2_1 safetensors / Kijai/WanVideo_comfy
A tiny distilled VAE model for encoding images into latents and decoding latent representations into images
WAN Comfy-Org/Wan_2.1_ComfyUI_repackaged
【例图页面蓝色Nodes或下载webp文件-可复现视频工作流】
Gallery sample images/videos (WEBP format) including the ComfyUI native workflow
This is a concise and clear GGUF model loading and tiled sampling workflow:
Wan 2.1 Low vram Comfy UI Workflow (GGUF) 4gb Vram - v1.1 | Wan Video Workflows | Civitai
节点:(或使用 comfyui manager 安装自定义节点)
https://github.com/city96/ComfyUI-GGUF
https://github.com/kijai/ComfyUI-WanVideoWrapper
https://github.com/BlenderNeko/ComfyUI_TiledKSampler
* 注意需要更新到最新版本的 comfyui-KJNodes GitHub - kijai/ComfyUI-KJNodes: Various custom nodes for ComfyUI update to the latest version of Comfyui KJNodes
Kijai ComfyUI wrapper nodes for WanVideo
WORK IN PROGRESS
@kijaidesign 's works
Huggingface - Kijai/WanVideo_comfy
GitHub - kijai/ComfyUI-WanVideoWrapper
主图视频来自 AiWood
https://www.bilibili.com/video/BV1TKP3eVEue
Text encoders to ComfyUI/models/text_encoders
Transformer to ComfyUI/models/diffusion_models
Vae to ComfyUI/models/vae
Right now I have only ran the I2V model succesfully.
Can't get frame counts under 81 to work, this was 512x512x81
~16GB used with 20/40 blocks offloaded
DiffSynth-Studio Inference GUI
Wan-Video LoRA & Finetune training.
DiffSynth-Studio/examples/wanvideo at main · modelscope/DiffSynth-Studio · GitHub
![]()
💜 Wan | 🖥️ GitHub | 🤗 Hugging Face | 🤖 ModelScope | 📑 Paper (Coming soon) | 📑 Blog | 💬 WeChat Group | 📖 Discord
Wan: Open and Advanced Large-Scale Video Generative Models
通义万相Wan2.1视频模型开源!视频生成模型新标杆,支持中文字效+高质量视频生成
In this repository, we present Wan2.1, a comprehensive and open suite of video foundation models that pushes the boundaries of video generation. Wan2.1 offers these key features:
👍 SOTA Performance: Wan2.1 consistently outperforms existing open-source models and state-of-the-art commercial solutions across multiple benchmarks.
👍 Supports Consumer-grade GPUs: The T2V-1.3B model requires only 8.19 GB VRAM, making it compatible with almost all consumer-grade GPUs. It can generate a 5-second 480P video on an RTX 4090 in about 4 minutes (without optimization techniques like quantization). Its performance is even comparable to some closed-source models.
👍 Multiple Tasks: Wan2.1 excels in Text-to-Video, Image-to-Video, Video Editing, Text-to-Image, and Video-to-Audio, advancing the field of video generation.
👍 Visual Text Generation: Wan2.1 is the first video model capable of generating both Chinese and English text, featuring robust text generation that enhances its practical applications.
👍 Powerful Video VAE: Wan-VAE delivers exceptional efficiency and performance, encoding and decoding 1080P videos of any length while preserving temporal information, making it an ideal foundation for video and image generation.
This repository features our T2V-14B model, which establishes a new SOTA performance benchmark among both open-source and closed-source models. It demonstrates exceptional capabilities in generating high-quality visuals with significant motion dynamics. It is also the only video model capable of producing both Chinese and English text and supports video generation at both 480P and 720P resolutions.

Description
本页面右侧下载列表13.31G Safetensors 格式,workflow 在 Trainning data 压缩包内
In the download list on the right, there are 4 files, the fourth of which is a compressed file called "training data". In CivitAI, if you really don't want to throw sample images or videos into ComfyUI to obtain workflows, you can download this compressed file and get the component nodes and sample workflows synchronized with Github.
This is a T2I model, CausVid DMD2 FT for WAN 14B,
which can be FAST generated in just 6-16 steps.
also supports input images as reference frames
也就是说,一个模型通吃所有生成场景!
That is to say, one model can handle all generated scenarios!
[ VACE technology adapted to T2V model, And VACE also supports input images as reference frames, whether at the beginning or ending frame ]
[The adaptability test results of WAN1.2 LoRAs for VACE show that about 75% of I2V/T2V LoRA weights can take effect, but the sensitivity is reduced ( try to increase the LoRA weight ,more than 100% Sometimes it can be helpful ) ]
---
这是一个T2I模型,适用于WAN 14B的CausVid DMD2 FT,只需6-16步即可快速生成。
[ VACE技术适用于T2V型号,VACE还支持输入图像作为参考帧,无论是在开始帧还是结束帧 ]
---
5/15 REDCausVid-Wan2-1-14B-DMD2-FP8 Uploaded
8-15 steps CFG 1 Best Adaptation for WAN-VACE
5/15 Aiwood WAN-ACE Fully functional workflow Uploaded
5/15 ComfyUI KJ-WanVideoWrapper have been updated
5/14 autoregressive_checkpoint.pt 1.3b Uploaded
5/14 bidirectional_checkpoint2.pt 1.3b Uploaded
---
NEW workflow Aiwood WAN-ACE Fully functional workflow
source: https://www.bilibili.com/video/BV1FGE6zGEDK ⭐ leave a star⭐
---
NEW Sampler Flowmatch_causvid in KJ-WanVideoWrapper
Releases from:
kijai/ComfyUI-WanVideoWrapper ⭐ leave a star⭐
---
项目页 https://causvid.github.io/ 🔥 多图警告!
Abstract
Current video diffusion models achieve impressive generation quality but struggle in interactive applications due to bidirectional attention dependencies. The generation of a single frame requires the model to process the entire sequence, including the future. We address this limitation by adapting a pretrained bidirectional diffusion transformer to an autoregressive transformer that generates frames on-the-fly. To further reduce latency, we extend distribution matching distillation (DMD) to videos, distilling 50-step diffusion model into a 4-step generator. To enable stable and high-quality distillation, we introduce a student initialization scheme based on teacher's ODE trajectories, as well as an asymmetric distillation strategy that supervises a causal student model with a bidirectional teacher. This approach effectively mitigates error accumulation in autoregressive generation, allowing long-duration video synthesis despite training on short clips. Our model achieves a total score of 84.27 on the VBench-Long benchmark, surpassing all previous video generation models. It enables fast streaming generation of high-quality videos at 9.4 FPS on a single GPU thanks to KV caching. Our approach also enables streaming video-to-video translation, image-to-video, and dynamic prompting in a zero-shot manner.
⚠️ This repo is a work in progress. Expect frequent updates in the coming weeks.
@inproceedings{yin2025causvid,
title={From Slow Bidirectional to Fast Autoregressive Video Diffusion Models},
author={Yin, Tianwei and Zhang, Qiang and Zhang, Richard and Freeman, William T and Durand, Fredo and Shechtman, Eli and Huang, Xun},
booktitle={CVPR},
year={2025}
}
@inproceedings{yin2024improved,
title={Improved Distribution Matching Distillation for Fast Image Synthesis},
author={Yin, Tianwei and Gharbi, Micha{\"e}l and Park, Taesung and Zhang, Richard and Shechtman, Eli and Durand, Fredo and Freeman, William T},
booktitle={NeurIPS},
year={2024}
}
@inproceedings{yin2024onestep,
title={One-step Diffusion with Distribution Matching Distillation},
author={Yin, Tianwei and Gharbi, Micha{\"e}l and Zhang, Richard and Shechtman, Eli and Durand, Fr{\'e}do and Freeman, William T and Park, Taesung},
booktitle={CVPR},
year={2024}
}
Acknowledgments
CausVid implementation is largely based on the Wan model suite.⭐ leave a star⭐
FAQ
Comments (180)
why pt format?
Because it is currently only running in a standalone environment on Pytorch, no Safetensors file is provided. Please wait a moment
@METAFILM_Ai That's not a valid reason to use a .pt file. Nothing prevents you from loading a safetensor file in a standalone environment.
Kijai uploaded a safetensor, https://huggingface.co/Kijai/WanVideo_comfy/blob/main/Wan2_1-T2V-14B_CausVid_fp8_e4m3fn.safetensors
@lym0 Thx,我的版本也更新了 RED-CausVid(NSFW),权重比KJ的低一些,避免过曝。6-15步
Thx, My version has also been updated with RED CasVid (NSFW), which has a lower weight than KJ to avoid overexposure. 6-15 steps
where is the workflow?
For CausVid, I believe there isn't ComfyUI support yet.
We’ll need to use the official Python-based inference codes
1) Clone https://github.com/tianweiy/CausVid and follow instructions to install requirements
2) Clone https://huggingface.co/Wan-AI/Wan2.1-T2V-1.3B into wan_models/Wan2.1-T2V-1.3B
3) Put the pt file inside checkpoint_folder/model.pt
4) Run inference code, python minimal_inference/autoregressive_inference.py --config_path configs/wan_causal_dmd.yaml --checkpoint_folder XXX --output_folder XXX --prompt_file_path XXX
EDITED: I haven’t tested this myself yet, just gathered the information from the GitHub repo and Reddit post.
Reddit posts about CausVid: https://www.reddit.com/r/StableDiffusion/comments/1khjy4o/causvid_generate_videos_in_seconds_not_minutes/
https://www.reddit.com/r/StableDiffusion/comments/1k0gxer/causvid_from_slow_bidirectional_to_fast/
Because it is currently only running in a standalone environment on Pytorch, no Safetensors file is provided. Please wait a moment
This is a T2I model, CausVid DMD2 FT for WAN 14B, which can be FAST generated in just 6-16 steps. ( VACE technology adapted to T2V model, And VACE also supports input images as reference frames, whether at the beginning or ending frame)这是一个T2I模型,适用于WAN 14B的CausVid DMD2 FT,只需6-16步即可快速生成。(VACE技术适用于T2V型号,VACE还支持输入图像作为参考帧,无论是在开始帧还是结束帧)也就是说,一个模型通吃所有生成场景!That is to say, one model can handle all generated scenarios!
@lym0 工作流已经上传并且支持ComfyUI下的加速推理,KJ完成了新的采样器,现在只需要6-15步
The workflow has been uploaded and supports accelerated inference under ComfyUI. KJ has completed the new sampler, which now only requires 6-15 steps
@METAFILM_Ai where was it uploaded, this explanation is confusing as all hell
@rocky533 I guess he meant this? https://github.com/kijai/ComfyUI-WanVideoWrapper/tree/main/example_workflows Indeed it is confusing -_-
In the download list on the right, there are 4 files, the fourth of which is a compressed file called "training data". In CivitAI, if you really don't want to throw sample images or videos into ComfyUI to obtain workflows, you can download this compressed file and get the component nodes and sample workflows synchronized with Github.
Can you add instructions on how we use this with Comfy or Swarm? I have no idea what to download and what to put where
Because it is currently only running in a standalone environment on Pytorch, no Safetensors file is provided. Please wait a moment
@METAFILM_Ai Aighty. I'll wait for it to be more consumer friendly to use. Thanks for the reply
询问GPT 表示T5有问题 用官方T5好像不行 一定要用你们家的 但Hugging Face的载点已经没了 想请问哪里有办法下载 谢谢(How to solve the following error?)
Error(s) in loading state_dict for T5: size mismatch for shared.weight: copying a param with shape torch.Size([256384, 4096]) from checkpoint, the shape in current model is torch.Size([32128, 4096]).
可以試試這個fork
https://huggingface.co/Kaoru8/T5XXL-Unchained
之前也有解決過類似的問題,印象中還要覆蓋ComfyUI/comfy/text_encoders/t5_config_xxl.json的參數,有可能記錯,請先備份後再試。
@lym0 谢谢前辈回答 我把t5xxl-unchained-f16.safetensors放进了text_encoders资料夹里面 也是一样
不好意思再追加一个问题 Unet加载器有什麽特别需求吗? 我点执行还会显示UNETLoader'conv_in.weight'
@lym0 这是WAN的贴,所以不是T5的问题,而且RedCraft没有破解的T5也是完全一样用。WAN模型配置的其实是umT5,也就是谷歌未校准的生raw版本,根据工作流实现的不同,还分为ComfyORG原生所需的版本: Comfy-Org/Wan_2.1_ComfyUI_repackaged at main 和Kijai节点所需的版本:Kijai/WanVideo_comfy at main
@hyhv80435107 主要是要根据工作流不同要区分KiJai和ComfyOrg的原生版本
@METAFILM_Ai 感謝糾正,確實搞混了。也試過RedCraft沒破解的T5一樣能生成nsfw内容。
I can't seem to get the autoregressive model to not run out of memory, are you using >24gb?
This is a T2I model, CausVid DMD2 FT for WAN 14B, which can be FAST generated in just 6-16 steps. ( VACE technology adapted to T2V model, And VACE also supports input images as reference frames, whether at the beginning or ending frame)这是一个T2I模型,适用于WAN 14B的CausVid DMD2 FT,只需6-16步即可快速生成。(VACE技术适用于T2V型号,VACE还支持输入图像作为参考帧,无论是在开始帧还是结束帧)也就是说,一个模型通吃所有生成场景!That is to say, one model can handle all generated scenarios!
NO,VACE+CausVID+SwapperBlock, The minimum required video memory is only 10G, but it is recommended to use 16GB+
Feedback
This is a T2I model, CausVid DMD2 FT for WAN 14B, which can be FAST generated in just 6-16 steps. ( VACE technology adapted to T2V model, And VACE also supports input images as reference frames, whether at the beginning or ending frame)这是一个T2I模型,适用于WAN 14B的CausVid DMD2 FT,只需6-16步即可快速生成。(VACE技术适用于T2V型号,VACE还支持输入图像作为参考帧,无论是在开始帧还是结束帧)也就是说,一个模型通吃所有生成场景!That is to say, one model can handle all generated scenarios!
已测试,CausVid是目前为止最快的wan2.1 14b模型!
下载safetensors(约13.4Gb),用comfyUI native流程加载。
【参数】
step:3
cfg:1
sample:euler - normal
【测试结果】
512x384 25帧,采样器用时8-18s(4070Ti)
Where is "REDCausVid-Wan2-1-14B-DMD2-FP8"? It says 'uploaded' but I cannot find the download anywhere.
I second that question. Also, does this work I2V? I've tried on default or custom I2V workflows but it doesn't seem to work this way.
It's lying quietly in the download list on the right, it's been like this since 30 hours ago, the 13.31GB download link in "Safetensors" format (because the system will change the name automatic)
@terrosaurx This is a T2I model, CausVid DMD2 FT for WAN 14B, which can be FAST generated in just 6-16 steps. ( VACE technology adapted to T2V model, And VACE also supports input images as reference frames, whether at the beginning or ending frame)这是一个T2I模型,适用于WAN 14B的CausVid DMD2 FT,只需6-16步即可快速生成。(VACE技术适用于T2V型号,VACE还支持输入图像作为参考帧,无论是在开始帧还是结束帧)
也就是说,一个模型通吃所有生成场景!
That is to say, one model can handle all generated scenarios!
它静静地躺在右边的下载列表中,自30小时前以来一直是这样的,13.31GB的下载链接采用“Safetensors”格式(因为系统会自动更改名称)
@METAFILM_Ai It's the same model? The model I download from there is named 'onTHEFLYWanAIWan21VideoModel_causvid14bVACE', which is not the model named in the workflow.
@ralphtandy the system change the model name
@ralphtandy is this the model RED CausVid -Wan2-1 -14B- DMD2-FP8」? Can anyone tell it?
Kijai made a lora version that works with image to video / any 14B wan finetune:
https://huggingface.co/Kijai/WanVideo_comfy/blob/main/Wan21_CausVid_14B_T2V_lora_rank32.safetensors
Just use at 0.5 weight or so, set CFG to 1, use flowmatch_causvid scheduler, and use like 4 steps
Just saw it, looking forward to the full blooded version of VACE with ComfyUI native support from!
This lora makes everything almost perfect now! Dropped from 190 seconds of generation to 90 s (720p upscaled). Thanks for the tip!
The current version of this page is made through CausVid original PT and WAN2.1 14B, in fact, I also like to use the KJ split model weight + LoRA combination, which is indeed more flexible. However, I am still looking forward to the native VACE support of ComfyUI, and a separate accelerated version of VACE has been made (the reason why it has not been released is that I am waiting for the component upgrade of ComfyUI and the official VACE workflow) 05/18 Today, ComfyUI announced the support of the model, but the VACE component is still a beta version, and there are still some problems that need to be solved.
当前页面这个版本是通过CausVid原版PT和WAN2.1 14B制作的,其实我现在也喜欢用KJ拆分的模型权重+LoRA组合,这样确实更灵活。不过对于ComfyUI的原生VACE支持还是充满期待,并且已经制作好了单独的VACE加速版(没有发布的原因是在等ComfyUI的组件升级和官方VACE工作流)05/18 今天ComfyUI公告了模型的支持,但是组件依旧是beta版本,还有一些问题需要解决。
Where is the workflow...
Why is this sooooo confusing...
The download list on the right side of this page , and the workflow is included in the Training data compressed file. The example images and videos also include workflows (yes, you can directly throw the original video files into ComfyUI and try to capture the workflow)
@METAFILM_Ai Thank you, i advise adding this to the description. No one is going to think to download training data for the workflow. Thanks for the response.
I use 4090 and take the sample workflow "AIWOOD_vace 全功能...", but it reports allocation on device and out of cuda, I don`t know why?Can someone help, or give a workflow...Thanks a lot!
RuntimeError: CUDA error: out of memory
CUDA kernel errors might be asynchronously reported at some other API call, so the stacktrace below might be incorrect.
For debugging consider passing CUDA_LAUNCH_BLOCKING=1
Compile with TORCH_USE_CUDA_DSA to enable device-side assertions.
Hello, try not to exceed 480x720 in spawn size, and adjust the spawn number between 33-81. If the size and time are set relatively high, you need to open a 20-30 block swap. Generally speaking, 16~24GVRAM is a better configuration to generate this size, if you want to directly generate a larger size resolution, or generate 81 frames or more at a time, you need a 32G~80G GPU model. (Imagine video generation is actually a batch of dozens of images generated at the same time, and the size and number of images are very stressful on the VRAM!) )
你好,生成尺寸尽量不要超过480x720,生成数量在33-81之间调整。如果尺寸和时间都设置比较高的话,就要打开20-30的块交换。一般来说16~24GVRAM是能生成这个尺寸的较好配置,如果要想直接生成更大尺寸的分辨率,或者一次生成81帧甚至更多,就需要32G~80G的GPU型号。(想象一下视频生成其实就是一个批次同时生成几十张图片,尺寸和数量对VRAM的压力都非常大!)
@METAFILM_Ai is not my torch or cuda version wrong?I try both cu12.8 and cu12.6, but in vain,btw,i can understand chinese,thks for reply,I will try it tomorrow,
@METAFILM_Ai i have no change with the sample workflow,but can't work
@zczcg 因为工作流在加载模型的地方,我默认没有打开 block swapping. 帧数和分辨率,如果同时开到比较高,还是需要10-30的块交换才可以跑起来。随时监控系统的显存占用情况。
I find the reason,Virtual memory is set too small. I have set up 7000mb,is really Virtual memory important?
@METAFILM_Ai 我找到原因了,剛剛我把虛擬記憶體從7000mb拉到70000就解決問題了,虛擬記憶體有這麼重要嗎?不太懂。4090不就有24gb可以用了,而且我去看資源監控器,頂多專屬gpu記憶體也只有吃18/24GB,根本沒吃滿,是設定問題嗎,換句話說,他根本使用虛擬記憶體去補足的
@zczcg to be honest it is not. Problem is resolution. If you go higher resolution, VRAM fill be filled and it would like to use more ram where it is virtual ram. If you set your settings optimal, you won't be needing virtual ram whatsoever.
@Reelai Thanks for replying!! And how to set settings optimal?
Where is the workflow?
In the training data folder. Took me a while to find as well lol
sorry, but you can notice that the lora of WAN publishes workflow and other components like this, and I thought it was a habit xD
@METAFILM_Ai I didn't know that, it's hard to find if you're not used to it. But thanks for the work you guys put into these models, it's very much appreciated
For me there is just a download button, no training data....
@anno314 Right side. Below the "details" section. Above the "about this version" section
ok guys i am sorry, i am browsing this page for an hour now and cant find the training data to download.....
it's on the right, below the "details" section
@notme123123 isn't that just the model link? I am also too blind to see it
@NoMoreRice
https://civitai.com/models/1295569?modelVersionId=1781040
you can find Training Data (8.9 MB)
@NoMoreRice First, click on the CausVid14B model at the top, right below the main title of this page. Then, look below the "details" section on the right side of the page, there are four files there. One is called "training data", that's where the workflow is
hey guys, i see in other comments that it's screw up their comfyui, is it really worth it compared to the original WAN checkpoint ? is there a real differene ? thanks
Nothing different outside of the fact that some chinese pieces of shit keep wasting peoples time with a base model uploaded in their own way.
WAN-VACE is not a T2V model per se, but rather R(reference)2V, Can be understood as Video ControlNet for WAN , so there is no way to provide a T2V workflow. The CausVid accelerator is a distillation accelerator technology that can be used on WAN-VACE to provide 4-8 steps of accelerated generation.
WAN-VACE本身不是T2V模型,而是R(参考)2V,可以理解为WAN的视频CN,因此无法提供T2V工作流程。CausVid加速器是一种蒸馏加速技术,可用于WAN-VACE,提供4-8步加速生成。
Can someone please explain to me what this is, and why it differs from the original Wan 2.1 model? I've tried reading through the description but it's so complex that I can't get my pea sized brain to figure it out.
I want to know that too
Honestly I think there is nothing different in terms of I2V. Just a complex workflow that makes 0 sense to any human brain compared to 99% of workflows. And the latest seems to give 0 fucks about any input image in any other workflow. Short answer seems to be this is just a waste of time to download. Idk maybe if you are some autistic nerd that only understands 0's and 1's maybe there is some difference but to anyone else. This just seems to be a waste of time. Hell they dont even say if vace is FP8 or FP16, like how is this being prompted lol. Chinese Trash with some data center farm pushing this garbage to the front.
WAN-VACE is not a T2V model per se, but rather R(reference)2V, Can be understood as Video ControlNet for WAN , so there is no way to provide a T2V workflow. The CausVid accelerator is a distillation accelerator technology that can be used on WAN-VACE to provide 4-8 steps of accelerated generation.
WAN-VACE本身不是T2V模型,而是R(参考)2V,可以理解为WAN的视频CN,因此无法提供T2V工作流程。CausVid加速器是一种蒸馏加速技术,可用于WAN-VACE,提供4-8步加速生成。
According to their claim, This model is faster and has more fluid movements than the vanilla model.
WAN-VACE is not a T2V model per se, but rather R(reference)2V, Can be understood as Video ControlNet for WAN , so there is no way to provide a T2V workflow. The CausVid accelerator is a distillation accelerator technology that can be used on WAN-VACE to provide 4-8 steps of accelerated generation.
WAN-VACE本身不是T2V模型,而是R(参考)2V,可以理解为WAN的视频CN,因此无法提供T2V工作流程。CausVid加速器是一种蒸馏加速技术,可用于WAN-VACE,提供4-8步加速生成。
Can this workflow be changed to so can select the target resolution? I really dont want a resolution of 800x234. Do you know what I mean. I tried using the crop but it didnt help. Basically let me select the final resolution.
Of course, it's okay to change the resolution, and sample workflow (used as a demonstration) that can be modified to your desired production process.
The animation is not smooth. What is causing this? the characters are very jittery.
Then you need to add frame interpolation to add the transition effect and smooth, if the actions not well expressed, you can improve it with lora and controlNet.
this workflow sometimes hangs at 0%. Possibly when resolution is too high. I also can't stop the workflow. Hitting the X repeatedly will not stop the threaad. This means I have to restart the server.
In this case, the total number of pixels or the total number of frames generated exceeds the carrying capacity of the VRAM (explosion of VRAM), because ComfyUI rarely has OoM (out of memorys), and when the shared graphics memory occupies a lot of CPU processing, the system will be completely stuck. Reduce the total number of pixels generated and the total number of frames appropriately. Generally speaking, devices of 24G and below will be better to use the equivalent of 0.2M pixels and less than 81 frames. 这种情况是因为总像素数量或者总的生成帧数,超出了VRAM的承载能力(爆显存),因为ComfyUI很少出现OoM(out of memorys)的情况,共享显存在占用大量CPU处理的时候,系统就会完全卡住。请适当降低总生成像素数以及总帧数。一般来说24G及以下的设备,使用等效0.2M的像素和低于81帧来生成,会比较好。
The way to optimize VRAM usage is to enable block swapping technology, and place some of the model's layers in the shared video memory for swapping. From low-resolution generation to high-resolution repaints, many players prefer to create previews at very low resolution, and then zoom in and repaint with the 1.3B model (which is a smart thing to do). Of course, there are many ways to redraw, it can be an upscale model, or other video models, or i2i models, or chunked redraw schemes, which are very many ways, and you need to find a suitable one. 优化VRAM占用的办法是开启块交换技术,将部分模型的层放置在共享显存中做交换。从低分辨率生成到高分辨率重绘,很多玩家喜欢用很低的分辨率先生成预览,然后再用1.3B模型进行放大重绘(很聪明的做法)。当然重绘的方法有很多种,可以是upscale模型,也可以是其他视频模型,或者是i2i模型,或者是分块式重绘方案,这有非常多的方式,需要找到适合自己的。
@METAFILM_Ai thnx for the response.
YYDS !!! 龙银币变成罗马银币
现在Comfy内置的工作流正在更新中,5/20 中午我得到运营的消息说修改了参考帧的输入方式,多参考帧的过度不会像现在这么生硬了,我们等Comfy平台的正式发布吧!
@METAFILM_Ai 我生硬了
Absolute Trash.
Yeah, any emotion that doesn’t do anything positive is pretty much junk.
how long does it usually take to render a video?
v2v, i2v,t2v?
In the case of using the CausVid accelerator, it takes about 50~80 seconds for i2v (reference frame) generation of 5 seconds with 81 frames , equivalent pixel about 0.2M. The ControlNet mode of V2V increases the preprocessing time, and everything else is the same as that of I2V. The inpainting method of V2V is slightly slower, about 90~180 seconds. The VACE cannot be directly used with T2V (if used as a replacement for the 14B 720PT2V model, the quality will not be better than the original). 在使用CausVid加速器的情况下,对于5秒81帧的i2v(参考帧)生成来说,0.2M 左右的等效像素,大概需要50~80秒。V2V的ControlNet方式,增加了预处理时长,其他与I2V一样。V2V的inpainting方式,速度略慢,大概需要60~120秒。VACE是无法直接使用T2V的(如果作为14B 720PT2V模型的替代,质量不会比原本的更好)
The above conclusion is made on 16~24GB video memory (3090, 4070, 4090) level GPU, if it is on a device with 48~80GB video memory (6000Ada, L40S, A100-H100), the efficiency will be improved a lot. At present, the most suitable GPU for WAN and WAN-VACE is 5090 32GB, which is beyond doubt, and it is not a recommendation, but in line with the law of development. 以上结论是在16~24GB显存(3090、4070、4090)级别GPU得出的,如果是在48~80GB显存(6000Ada、L40S、A100-H100)的设备上,效率会提高很多。当前最适合WAN及WAN-VACE的GPU是5090 32GB,这是毋庸置疑的,并不是在做推荐,而是符合发展规律。
37 years with a GPU from 1970. 10 seconds with a GPU of 2050.
Your question is meaningless, especially since you don't tell what's your hardware...
@METAFILM_Ai thank you, much apreciated
@METAFILM_Aisounds like its going to render quite quickly then, im used to older methods that took ~5 min for an ~80 frame video
1 frame/s rate is insane with a 4090/4070
@SD_AI_2025 mate, fk off with your bs attitude
your better option is to keep quit
its fast, but you loose alot of details in the images? or is it my workflow?
CausVid does lose a lot of detail if the number of steps is less than 4 (I usually turn on 4-10 steps). For VACE, if the range of motion expression using LoRA alone is not enough, you can add the controller references supported by VACE: Depth, Pose, Colormap, or use the dynamic mask inpainting of the reference video to improve the motion performance. CausVid 如果步数小于4,确实是会丢失很多细节(我一般会开启4-10步)。对于VACE,如果单纯使用LoRA的动作表达幅度不够,可以增加VACE支持的控制器参考:Depth、Pose、Colormap,或者利用参考视频的动态遮罩 inpainting 来改善动作表现。
hello, can you please post a working Workflow?? the the ones included here are confusing
Is it possible for someone to provide a simple workflow for txt2vid using causvid? I am finding it difficult to utilize the different workflows. Using the base txt2vid wan workflow is still slow with the causvid. I am assuming this is because of the scheduler not being present.
WAN-VACE is not a T2V model per se, but rather R(reference)2V, Can be understood as Video ControlNet for WAN , so there is no way to provide a T2V workflow. The CausVid accelerator is a distillation accelerator technology that can be used on WAN-VACE to provide 4-8 steps of accelerated generation.
WAN-VACE本身不是T2V模型,而是R(参考)2V,可以理解为WAN的视频CN,因此无法提供T2V工作流程。CausVid加速器是一种蒸馏加速技术,可用于WAN-VACE,提供4-8步加速生成。
@METAFILM_Ai Thank you for the clarifying information, I really appreciate it. Also, thank you for your hard work. Do you happen to know of a workflow for t2v, that can generate fast videos like causvid? Thank you in advance.
@guppysb Then let's put the VACE aside first, and load the CausVid LoRA with a weight ratio of 0.2~0.5 on any WAN 14B T2V model, which can play an accelerated role. CFG should be set to 1, and the number of sampling steps should be 4~10
Help. How do I prevent letters and banners from appearing that look like ads?
It's time for life and death...Civitai
I like the workflow. It pretty much shows what vace is capable of. However, the start to end image flow is very time consuming and brightens the image. Is that normal?
Can we have this for Forge?
What about https://github.com/lllyasviel/FramePack ?
Forge has nothing to do with video AI.
FramePack is for Hunyuan.
Any way to improve movement with this model? For some reason all my videos are barely moving since switching to this.
Since using VACE ive notived the videos barely has any movement. I think it may be due to the fact im using the LORA to speed things up, which requires CFG1.
hey with when i activate loras with this it completely ignores the image, anyone know a fix?
Does the Causevid14b(vace) model have causevid built into the model? Or do we still need to use the lora?
Is there any other way to get the workflow? I wasn't able to get it through the link since it requires chinese login
Its in the training data download, in the files drop down
I have 16 GB of V-Ram and a 3 second video with
Kijai-Wan2.1-I2V-14B-480P
takes for me around 30 minutes. Is that normal?
I assume it's normal. My 3090 (24 GB VRAM) usually creates a video of around 81 frames (5 segs) with I2V-14B-720P in 12-18 minutes - depending of used LoRAs and a lil bit of luck - with use of SLG, Sage Attention and TeaCache. I carefully check that all the model and inference result stay in the VRAM, because if even a lil piece is allocated in the RAM (DDR4 @ 3600), gen time skyrockets for around 3 times.
I'm using the Q4_K_S gguf model and generate a 5 second video at 768x384 with 30 steps in about 10 minutes (20s/it) on my laptop 4080 12Gb VRAM. This is without Teacache and Torch. I do have sageattention enabled and I'm using the UnetLoaderGGUFDisTorchMultiGPU to offload to RAM.
@funscripter627 can you upload your workflow?
I can't find the work flow.. Can someone link a direct link to it? I've searched high and low and I don't see it.
Its in the training data download, in the files drop down
rocky533 the only thing I see in the file drop down is Pruned Model fp8 (15.83 GB) which is top right corner, I am rather lost haha
if you download any of the example videos below the model title and drag the video into ComfyUI the workflow is contained in the videos already, and it will deploy into your ComfyUI session.. I did it and it worked for me
For me step 4 isn't clear
4) Run inference code, python minimal_inference/autoregressive_inference.py --config_path configs/wan_causal_dmd.yaml --checkpoint_folder XXX --output_folder XXX --prompt_file_path XXX
Where do I put this, because on the folder where I put the model.pt it gives an error.
Comfyui > checkpoints
I don't understand. What do I have to do to install Kajai 720p? The guide is VERY unclear; it doesn't include a workflow and doesn't tell me what to download or where to put it. It's very confusing. Can someone help me?
Its in the right by the creators name it says where you put the text encoders etc, when you go to hugging face those creators list where to put the files as well. usually models go in diffusion models or checkpoints, while gguf go into unet. But you can also use control+F for find and search the word "folder". Also check the civitai articles section they have guides how to do everything, usually made by the same model and lora creators
Do you have a 24gb card? If not then you might want to look at the 480p models possibly even gguf
Thanks for replying :D, yes, I read that on the right there is that section, but I couldn't understand what specific things to download and where to put them, specifically, since many files have almost the same name and I don't know which one to choose, if I had a workflow, I could specifically search for files by name, but there isn't one. I have an RTX 3090, I read in a previous reply that it can make 5-second videos in 15 minutes at 720p
@tomasvillarrealfederco536 First of all, I agree with you the guide is an absolute mess. It's extremely hard to follow for people with limited experience. But the workflow is provided, it's on the right side of the screen where it list the models and a training data package. The workflow is within the training data.
how do i use this in my workflow?
The guide is not clear for me.
I have a 9070xt 16gb ram, what i should download, i see many models, but not a description about the differences...
Somebody can help me?
With 16GB vram, I'd use the Q4_K_M quant version. As a "quick" rule, the larger the file, the better the inference results, but the higher requirements of the GPU.
I use the wan q6 models with 12gb vram...though its nvidia. Always worth a try to find your ceiling with your set up.
I get 6 minute generation time with 16gb vram using the 720p Q3_K_S gguf model at 560x1024, 12steps, 16 fps, and 81 length. My optimizations are teacache, sageattention (gl installing sage on windows) and using causvid lora. 400x720 takes like 3 minutes
bhopping do you happen to have a rtx4060ti ?
1015 4070 ti su
Sorry to ask but I'm confused. May I ask which model should be put under WanVideo Model loader and Vace model loader? Also, is it the same for REDCausVid-Wan2-1-14B-DMD2-FP8 & onTHEFLYWanAIWan21VideoModel_causvid14bVACE? Thanks
same questions, hope somebody with better knowledge can help.
Can somebody point me to a simple I2V workflow that supports Lora with this model? I spent a whole day, but couldn't get any lora to work with the workflow in the training data :(
Or what's the best way to incorporate lora into the default workflow in the Training Data?
CLIPVisionLoader
ERROR: clip vision file is invalid and does not contain a valid vision model.
I hope somebody would write a clear explanation how to install these. I get all models to run except this one giving error after error.
The fix is to use the wan video wrapper node to load clip vision for wan. The wan video wrapper is part of the kijai wan video wrapper node pack. Delete your current clip vision node, and when you drag the "clip vision" rope from your clipvision encode node, it will give you the choice of "load wan video clip text encoder" as a node choice all the way on the bottom of the list (usually).
Got it to work using one of the created I2V video's below and direclty putting it in comfy and then loading the vae, clipvision, clip and model in comfyui.
I've done this with an image, but not with a video. How did you do it? Workflow metadata appears to not save to .m4a files (videos) downloaded from this page.
@megaman11 try another video perhaps. I tried it with a video (just the ones under the model´s title) and it worked for me.. e.g. the topless Chinese woman vid
hi, how did you do upscale?
I use topaz video AI that's a separate application but the nodes that ppl include in their workflows are still good, you can look up wan upscale workflows on this site and yoink their nodes and put it in your workflow
Will this model work inside of SwarmUI?
What even is this? A finetune or just the regular WAN models with workflows attached? The description is not helpful
Seconded. I have a working Wan2.1 i2v, t2v, and VACE workflows without this... what does this add?
i can seem to download 3 missing nodes i dont know why its not downloading them does someone know why or how to fix ?
LayerMask: SegmentAnythingUltra V3
LayerMask: LoadSegmentAnythingModels
Fast Groups Bypasser (rgthree)
is there an English guide/video on how to use this workflow? sry im a noob
is it a lora or diffusion model?
Look at the size, man lol. Ain't no loras that are 15 gigs lmao.
I am very confused... This is just WAN + VACE and causvid lora, right?
Getting a video of a black screen.
text encoder: umt5-xxl-fp8-e4m3fm.safetensors
vae: wan_2.1_vae.safetensors
shift: 8.0
sampler: lcm
denoise: 1.0
steps: 8
'Files' dropdown for me only shows "1 File": Pruned Model fp8 (15.83 GB). The Training data referenced in the guide, where the workflow can be found, appears to be absent on this model page.
can wan do pov views?
do a search for wan lora. you'll find plenty of them to choose from.
So what exactly does it do better than the normal wan2.1? And you can't be bothered to address the questions as I see unanswered questions from a whole month?
Seem to be great but I can't find the workflow.
It works, but I don't understand what the purpose of this lora is.
There is no guide or manual. Description looks like generated by AI.
This should be reported as a scam.
So. Where is the workflow for kijai-Wan2.1-I2V-14B??
I tried your workflow and it put an unbearable preview of the frames at the bottom of the monitor, can you explain to me how to remove it because it is unbearable and takes up my work space?
Geez man. At least attempt to learn the program before you make it sound like the Uploader's fault that you don't know the basics of the software. Click the red "X" on the right of the image feed to make it dissapear. Press the "Show image feed" button on the top right of your screen to make it appear.
@jazgalaxy581 And don't comment if you don't know, the button you're talking about is grayed out. If I hover over it with the mouse, the lock icon appears (a circle with a slanted red bar). There's no red X; it's put that bar in all my workflows. Anyway, it was in the options and I managed to remove it. The button you're talking about wasn't there because it was set to "hidden" by default. If we don't know the situation, we shouldn't jump to arbitrary conclusions.
after testing this model Based on Wan 2.1 I see that it is really long to generate a video of 5s compare to modern Wan 2.2 is faster for better quality
model 480p Here is the video I just made 4s it's not terrible as a result 30 mn :(
I'm having a stroke reading that description. What is this again? Is the author trying to help noobs? Because I think this article would be counter-productive and cause more confusion.
It absolutely does. I have no idea what I'm reading.
An even more confusing explanation that makes it harder to understand - this is truly awful. It seems informative, but offers no help at all.
Definitely works, and works well. Waiting on Wan2.2 upgrade!
They're just reuploads
Hi, sorry to bother, can you please post any workflow working with this model?? The ones included here are so confusing
this is absolutely the same models with the ones repackaged by comfy and kijai. you just reposted them here. you are making this very confusing as if these are some finetune models made by your team. what a f**king disgrace!
why the name onthefly? these are just all base models without lightning lora or any boost lora baked in. it's not fast at all.
Details
Files
onTHEFLYWanAIWan21VideoModel_causvid14bVACE.safetensors
Mirrors
onTHEFLYWanAIWan21VideoModel_causvid14bVACE.safetensors
onTHEFLYWanAIWan21VideoModel_causvid14bVACE.safetensors
onTHEFLYWanAIWan21VideoModel_causvid14bVACE.safetensors
onTHEFLYWanAIWan21VideoModel_causvid14bVACE.safetensors
onTHEFLYWanAIWan21VideoModel_causvid14bVACE.safetensors
onTHEFLYWanAIWan21VideoModel_causvid14bVACE.safetensors
onTHEFLYWanAIWan21VideoModel_causvid14bVACE_trainingData.zip
Mirrors
Available On (2 platforms)
Same model published on other platforms. May have additional downloads or version variants.