All in One, Wan for All
We are excited to introduce our latest model to our talented community creators:
Wan2.1-VACE, All-in-One Video Creation and Editing model.
Model size: 1.3B, 14B License: Apache-2.0
If we are in Wan Day, what will it be like? 如果我们在万相世界,会是什么样子?
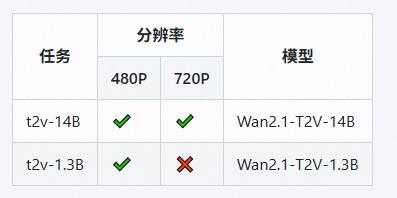
模型支持两种文本到视频模型(1.3B 和 14B)和两种分辨率(480P 和 720P)。
WAN-VACE is not a T2V model per se, but rather R(reference)2V, Can be understood as Video ControlNet for WAN , so there is no way to provide a T2V workflow. The CausVid accelerator is a distillation accelerator technology that can be used on WAN-VACE to provide 4-8 steps of accelerated generation.
WAN-VACE本身不是T2V模型,而是R(参考)2V,可以理解为WAN的视频CN,因此无法提供T2V工作流程。CausVid加速器是一种蒸馏加速技术,可用于WAN-VACE,提供4-8步加速生成。
Introduction
VACE is an all-in-one model designed for video creation and editing. It encompasses various tasks, including reference-to-video generation (R2V), video-to-video editing (V2V), and masked video-to-video editing (MV2V), allowing users to compose these tasks freely. This functionality enables users to explore diverse possibilities and streamlines their workflows effectively, offering a range of capabilities, such as Move-Anything, Swap-Anything, Reference-Anything, Expand-Anything, Animate-Anything, and more.

VACE是一款专为视频创建和编辑而设计的一体化模型。它包括各种任务,包括视频生成(R2V)、视频到视频编辑(V2V)和屏蔽视频到视频剪辑(MV2V),允许用户自由组合这些任务。此功能使用户能够探索各种可能性,并有效地简化他们的工作流程,提供一系列功能,如移动任何内容、交换任何内容、引用任何内容、扩展任何内容、为任何内容设置动画等。
About CausVid-Wan2-1:
5-16 The PERFECT solution to CausVid from Kijai (Best practices)
Wan21_CausVid_14B_T2V_lora_rank32.safetensors · Kijai/WanVideo_comfy
Through weight extraction and block separation,
KJ give us a universal CausVid LoRA in rank32 for Any 14B WAN model,
EVEN including FT models and I2V model!
Although this may not have been CausVid's initial intention, by flexibly adjusting the LoRA parameters (0.3~0.5), we have achieved unprecedented availability on home grade graphics cards!
KJ-Godlike also provides a 1.3B bidirectional inference version of LoRA export file
Wan21_CausVid_bidirect2_T2V_1_3B_lora_rank32.safetensors
same time, we also noticed that xunhuang1995 uploaded the Warp-4Step_cfg2 autoregressive version 1.3B CausVid model from: tianweiy/CausVid
相与为壹,全部在万
Best Adaptation for WAN-VACE full Models
5/15 REDCausVid-Wan2-1-14B-DMD2-FP8 Uploaded 8-15 steps CFG 1
本页面右侧下载列表,Safetensors 格式,workflow 在 Trainning data 压缩包内
The download list on the right side of this page is in Safetensors format, and the workflow is included in the Training data compressed file. The example images and videos also include workflows (yes, you can directly throw the original video files into ComfyUI and try to capture the workflow)
5/15 Aiwood WAN-ACE Fully functional workflow Uploaded
5/15 ComfyUI KJ-WanVideoWrapper have been updated
5/14 autoregressive_checkpoint.pt 1.3b Uploaded , PT UNET Loader
5/14 bidirectional_checkpoint2.pt 1.3b Uploaded , PT UNET Loader
NEW Sampler Flowmatch_causvid in KJ-WanVideoWrapper
Releases from:
⭐ leave a star⭐
[ The adaptability test results of WAN1.2 LoRAs for VACE show that about 75% of I2V/T2V LoRA weights can take effect, but the sensitivity is reduced ( try to increase the LoRA weight ,more than 100% Sometimes it can be helpful ) ]
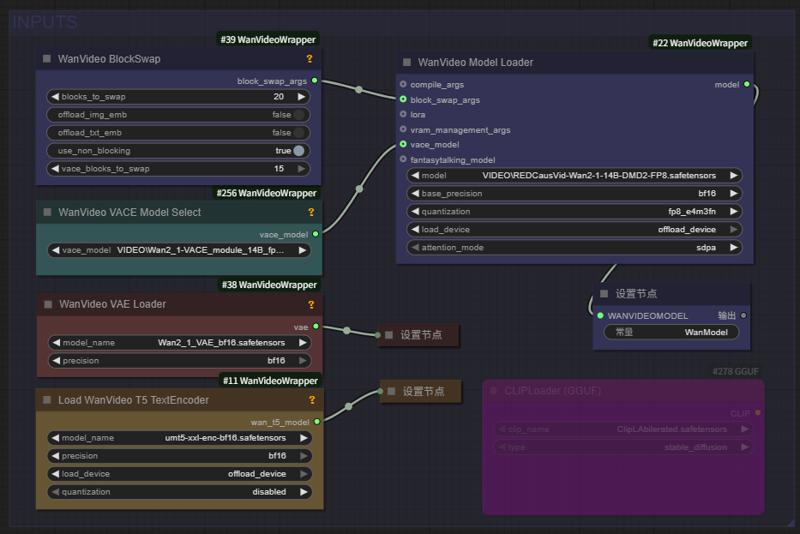
Fullview of Aiwood WAN-ACE Fully functional workflow:

source: https://www.bilibili.com/video/BV1FGE6zGEDK ⭐ leave a star⭐
 CausVid 加速器项目页 https://causvid.github.io/
CausVid 加速器项目页 https://causvid.github.io/
WAN-VACE 模型的参数和配置如下:
📌 Wan2.1-VACE provides solutions for various tasks, including reference-to-video generation (R2V), video-to-video editing (V2V), and masked video-to-video editing (MV2V), allowing creators to freely combine these capabilities to achieve complex tasks.
👉 Multimodal inputs enhancing the controllability of video generation.
👉 Unified single model for consistent solutions across tasks.
👉 Free combination of capabilities unlocking deeper creative
📌 Wan2.1-VACE为各种任务提供解决方案,包括参考视频生成(R2V)、视频到视频编辑(V2V)和屏蔽视频到视频剪辑(MV2V),允许创作者自由组合这些功能来实现复杂的任务。
👉 多模态输入增强了视频生成的可控性。
👉 统一的单一模型,实现跨任务的一致解决方案。
👉 自由组合功能,释放更深层次的创造力
WAN实时生成来了!Hybrid AI model crafts smooth, high-quality videos in seconds
The CausVid generative AI tool uses a diffusion model to teach an autoregressive (frame-by-frame) system to rapidly produce stable, high-resolution videos.
Wan2.1based 混合AI模型在几秒钟内(9帧/秒)制作出流畅、高质量的视频
CausVid生成AI工具使用扩散模型来指导自回归(逐帧)系统快速生成稳定的高分辨率视频。
From Slow Bidirectional to
Fast Autoregressive Video Diffusion Models
CausVid https://causvid.github.io/
tianweiy (Tianwei Yin)
RedCaus/REDCausVid-Wan2-1-14B-DMD2-FP8 Uploaded / WAN-VACE14B 最佳适配
CausVid/autoregressive_checkpoint uploaded / 自回归模型基于 WAN1.3B 已收录
CausVid/bidirectional_checkpoint2 uploaded / 双向推导模型基于 WAN1.3B 已收录
Kijai/Wan2_1-T2V-14B_CausVid_fp8_e4m3fn.safetensors / HF仓库 WanVideo_comfy
⭐ leave a star⭐

licensed by Creative Commons Attribution Non Commercial 4.0
Thank you for this friend's additional comment. I was too excited last night and didn't sleep, so I stopped updating before finishing:
We’ll need to use the official Python-based inference codes
1) Clone https://github.com/tianweiy/CausVid and follow instructions to install requirements
2) Clone https://huggingface.co/Wan-AI/Wan2.1-T2V-1.3B into wan_models/Wan2.1-T2V-1.3B
3) Put the pt file inside checkpoint_folder/model.pt
4) Run inference code, python minimal_inference/autoregressive_inference.py --config_path configs/wan_causal_dmd.yaml --checkpoint_folder XXX --output_folder XXX --prompt_file_path XXX
Reddit posts about CausVid: https://www.reddit.com/r/StableDiffusion/comments/1khjy4o/causvid_generate_videos_in_seconds_not_minutes/
https://www.reddit.com/r/StableDiffusion/comments/1k0gxer/causvid_from_slow_bidirectional_to_fast/
We have tested the CausVid based on Wan1.3b version, which has incredible speed, and are currently testing the 14B version produced by lightx2v.
 LightX2V: Light Video Generation Inference Framework
LightX2V: Light Video Generation Inference Framework
Supported Model List
How to Run
Please refer to the documentation in lightx2v.
⭐ leave a star⭐
通义实验室 WAN 2.1 Model Zoo
Institute for Intelligent Computing专注于各领域大模型技术研发与创新应用。实验室研究方向涵盖自然语言处理、多模态、视觉AIGC、语音等多个领域。我们并积极推进研究成果的产业化落地。实验室同时积极参与开源社区建设,全方位拥抱开源社区,共同探索AI模型的开源开放。
Developer / Models Name / Kijai`s ComfyUI Model
RedCaus/REDCausVid-Wan2-1-14B-DMD2-FP8 Uploaded / WAN-VACE14B 最佳适配
CausVid/autoregressive_checkpoint included / 自回归模型基于 WAN1.3B 已收录
CausVid/bidirectional_checkpoint2 included / 双向推导模型基于 WAN1.3B 已收录
CausVid/wan_causal_ode_checkpoint_model testing / 自回归因果推导 测试中
CausVid/wan_i2v_causal_ode_checkpoint_model testing / 文生图模型 测试中
lightx2v/Wan2.1-T2V-14B-CausVid unqualify / 自回归模型14B AiWood实测不达标
lightx2v/Wan2.1-T2V-14B-CausVid quant unqualify / 自回归模型14B量化版 实测不达标
Wan Team/1.3B text-to-video included / 文生视频1.3B 已收录
Wan Team/14B text-to-video included / 文生视频14B 已收录
Wan Team/14B image-to-video 480P included / 图生视频14B 已收录
Wan Team/14B image-to-video 720P included / 图生视频14B 已收录
Wan Team/14B first-last-frame-to-video 720P included / 视频首尾帧 已收录
Wan Team/Wan2_1_VAE included / KiJai‘s WAN视频VAE 已收录
ComfyORG/Wan2.1_VAE included / Comfy‘s WAN视频VAE 已收录
google/umt5-xxl umt5-xxl-enc safetensors included / TE编码器 已收录
mlf/open-clip-xlm-roberta-large-vit-huge-14 safetensors included / CLIP编码器 已收录
DiffSynth-Studio Team/1.3B aesthetics LoRA 美学蒸馏-通义万相2.1-1.3B-LoRA-v1
DiffSynth-Studio Team/1.3B Highres-fix LoRA 高分辨率修复-通义万相2.1-1.3B-LoRA-v1
DiffSynth-Studio Team/1.3B ExVideo LoRA 长度扩展-通义万相2.1-1.3B-LoRA-v1
DiffSynth-Studio Team/1.3B Speed Control adapter 速度控制-通义万相2.1-1.3B-适配器-v1
PAI Team/ WAN2.1 Fun 1.3B InP 支持首尾帧 / Kijai/WanVideo_comfy
PAI Team/ WAN2.1 Fun 14B InP 支持首尾帧 / Kijai/WanVideo_comfy
PAI Team/ WAN2.1 Fun 1.3B Control 控制器 / Kijai/WanVideo_comfy
PAI Team/ WAN2.1 Fun 14B Control 控制器 / Kijai/WanVideo_comfy
PAI Team/ WAN2.1 Fun 14B Control 控制器 / Kijai/WanVideo_comfy
PAI Team/ WAN2.1-Fun-V1_1-14B-Control-Camera / Kijai/WanVideo_comfy
IIC Team/ VACE-通义万相2.1-1.3B-Preview / Kijai/WanVideo_comfy
IC ( In-Context ) Controler 多模态控制器 :
ali-vilab/ VACE: All-in-One Video Creation and Editing / Kijai/WanVideo_comfy
Phantom-video/Phantom Subject-Consistent via Cross-Modal Alignment
KwaiVGI/ ReCamMaster Camera-Controlled 镜头多角度 / Kijai/WanVideo_comfy
Digital Character 数字人 via Wan2.1 :
ali-vilab/ UniAnimate-DiT 长序列骨骼角色视频 / Kijai/WanVideo_comfy
Fantasy-AMAP/ 音频驱动数字人 FantasyTalking / Kijai/WanVideo_comfy
Fantasy-AMAP/ 角色一致性身份保留 FantasyID / Fantasy-AMAP/fantasy-id
Uncensored NSFW 解锁版本:
REDCraft AIGC / WAN2.1 720P NSFW Unlocked / forPrivate use【非公开】
CubeyAI / WAN General NSFW model (FIXED) / The Best Universal LoRA
昆仑万维发布 SkyReels based on Wan2.1
Skywork / SkyReels-V2-I2V-14B-720P / Image-to-Video / Kijai/WanVideo_comfy
Skywork / SkyReels-V2-I2V-14B-540P / Image-to-Video / Kijai/WanVideo_comfy
Skywork / SkyReels-V2-T2V-14B-540P / Text-to-Video / Kijai/WanVideo_comfy
Skywork / SkyReels-V2-T2V-14B-720P /Text-to-Video / Kijai/WanVideo_comfy
Skywork / SkyReels-V2-I2V-1.3B-540P / Image-to-Video / Kijai/WanVideo_comfy
AutoRegressive Diffusion-Forcing 无限长度生成架构
Skywork / SkyReels-V2-DF-14B-720P / Text-to-Video / Kijai/WanVideo_comfy
Skywork / SkyReels-V2-DF-14B-540P / Text-to-Video / Kijai/WanVideo_comfy
Skywork / SkyReels-V2-DF-1.3B-540P / Text-to-Video / Kijai/WanVideo_comfy
昆仑万维发布 SkyReels 视频标注模型:
Skywork / SkyCaptioner-V1 Skywork (Skywork) / Skywork/SkyCaptioner-V1
Tiny AutoEncoder / taew2_1 safetensors / Kijai/WanVideo_comfy
A tiny distilled VAE model for encoding images into latents and decoding latent representations into images
WAN Comfy-Org/Wan_2.1_ComfyUI_repackaged
【例图页面蓝色Nodes或下载webp文件-可复现视频工作流】
Gallery sample images/videos (WEBP format) including the ComfyUI native workflow
This is a concise and clear GGUF model loading and tiled sampling workflow:
Wan 2.1 Low vram Comfy UI Workflow (GGUF) 4gb Vram - v1.1 | Wan Video Workflows | Civitai
节点:(或使用 comfyui manager 安装自定义节点)
https://github.com/city96/ComfyUI-GGUF
https://github.com/kijai/ComfyUI-WanVideoWrapper
https://github.com/BlenderNeko/ComfyUI_TiledKSampler
* 注意需要更新到最新版本的 comfyui-KJNodes GitHub - kijai/ComfyUI-KJNodes: Various custom nodes for ComfyUI update to the latest version of Comfyui KJNodes
Kijai ComfyUI wrapper nodes for WanVideo
WORK IN PROGRESS
@kijaidesign 's works
Huggingface - Kijai/WanVideo_comfy
GitHub - kijai/ComfyUI-WanVideoWrapper
主图视频来自 AiWood
https://www.bilibili.com/video/BV1TKP3eVEue
Text encoders to ComfyUI/models/text_encoders
Transformer to ComfyUI/models/diffusion_models
Vae to ComfyUI/models/vae
Right now I have only ran the I2V model succesfully.
Can't get frame counts under 81 to work, this was 512x512x81
~16GB used with 20/40 blocks offloaded
DiffSynth-Studio Inference GUI
Wan-Video LoRA & Finetune training.
DiffSynth-Studio/examples/wanvideo at main · modelscope/DiffSynth-Studio · GitHub
![]()
💜 Wan | 🖥️ GitHub | 🤗 Hugging Face | 🤖 ModelScope | 📑 Paper (Coming soon) | 📑 Blog | 💬 WeChat Group | 📖 Discord
Wan: Open and Advanced Large-Scale Video Generative Models
通义万相Wan2.1视频模型开源!视频生成模型新标杆,支持中文字效+高质量视频生成
In this repository, we present Wan2.1, a comprehensive and open suite of video foundation models that pushes the boundaries of video generation. Wan2.1 offers these key features:
👍 SOTA Performance: Wan2.1 consistently outperforms existing open-source models and state-of-the-art commercial solutions across multiple benchmarks.
👍 Supports Consumer-grade GPUs: The T2V-1.3B model requires only 8.19 GB VRAM, making it compatible with almost all consumer-grade GPUs. It can generate a 5-second 480P video on an RTX 4090 in about 4 minutes (without optimization techniques like quantization). Its performance is even comparable to some closed-source models.
👍 Multiple Tasks: Wan2.1 excels in Text-to-Video, Image-to-Video, Video Editing, Text-to-Image, and Video-to-Audio, advancing the field of video generation.
👍 Visual Text Generation: Wan2.1 is the first video model capable of generating both Chinese and English text, featuring robust text generation that enhances its practical applications.
👍 Powerful Video VAE: Wan-VAE delivers exceptional efficiency and performance, encoding and decoding 1080P videos of any length while preserving temporal information, making it an ideal foundation for video and image generation.
This repository features our T2V-14B model, which establishes a new SOTA performance benchmark among both open-source and closed-source models. It demonstrates exceptional capabilities in generating high-quality visuals with significant motion dynamics. It is also the only video model capable of producing both Chinese and English text and supports video generation at both 480P and 720P resolutions.

Description
Comfy-Org/Wan_2.1_ComfyUI_repackaged
Wan 2.1 repackaged for ComfyUI use. For examples see: https://comfyanonymous.github.io/ComfyUI_examples/wan
---
Wan 2.1 Models
Wan 2.1 is a family of video models.
---
Files to Download
You will first need:
Text encoder and VAE:
umt5_xxl_fp8_e4m3fn_scaled.safetensors goes in: ComfyUI/models/text_encoders/
wan_2.1_vae.safetensors goes in: ComfyUI/models/vae/
---
Video Models
files go in: ComfyUI/models/diffusion_models/
These examples use the 16 bit files but you can use the fp8 ones instead if you don’t have enough memory.
---
Workflows
---
Text to Video
files (put it in: ComfyUI/models/diffusion_models/). You can also use it with the 14B model.
---
Image to Video
Note this example only generates 33 frames at 512x512 because I wanted it to be accessible, the model can do more than that. The 720p model is pretty good if you have the hardware/patience to run it.
FAQ
Comments (60)
Is it possible for you to create GGUF versions?
The GGUF version of the model produced by ComfyORG is currently being uploaded
Please refer to the list page
UNET loader (GGUF) doesn't work, so I switched to this simple and straightforward workflow: Wan 2.1 Low vram Comfy UI Workflow (GGUF) 4gb Vram - v1.1 | Wan Video Workflows | Civitai
我更新了下comfyui-GGUF组件,直接加载就开始干活了!
Updated comfyui GGUF , now able to load Wan's GGUF model directly
Is there a workflow for the GGUF version that went live today?
Replace UNET loader with UNET loader (GGUF)?
UNET loader (GGUF) doesn't work, so I switched to this simple and straightforward workflow: Wan 2.1 Low vram Comfy UI Workflow (GGUF) 4gb Vram - v1.1 | Wan Video Workflows | Civitai
我更新了下comfyui-GGUF组件,直接加载就开始干活了!
Updated comfyui GGUF , now able to load Wan's GGUF model directly
@METAFILM_Ai I tried this workflow, it didn't work well.
Please add some workflow for the Comfyorg GGUF model. Thanks
Replace UNET loader with UNET loader (GGUF)?
UNET loader (GGUF) doesn't work, so I switched to this simple and straightforward workflow: Wan 2.1 Low vram Comfy UI Workflow (GGUF) 4gb Vram - v1.1 | Wan Video Workflows | Civitai
我更新了下comfyui-GGUF组件,直接加载就开始干活了!
Updated comfyui GGUF , now able to load Wan's GGUF model directly
1 Question.
Do you guys really wait 30 minutes or do you use runpod? I require the link please if you do c:
I hope this is not an advertisement. I will run a 720P model locally to generate 33 frames of images, which will only take 3-5 minutes (4090D). However, the generation size will be set lower, and then super-resolution will be performed
@METAFILM_Ai Hello, thx for model!!! how you upscale video?
about as uncensored as my granma and she been dead for over 35 years
Fortunately, we have just been resurrected. Let monsoons flood the censors' dictionaries—since when did seedlings need permission to crack concrete with their roots?
Can't open worfklow it says missing custom node: wanimage2video
So you can use ComfyUI manager to install the missing nodes, also You can manually download it here: https://github.com/kijai/ComfyUI-WanVideoWrapper
update ComfyUI to latest
I couldn't get the missing node until I updated by opening the bat files: "update_comfyui", and "update_comfyui_and_python_dependencies" from the update folder. Updating and installing manually didn't work for me. I'm also using the portable version btw.
@Ntgg Right~After ComfyUI officially supports Wan2.1, we need to update the Comfy version
So it looks like Wan has vastly superior I2V than Hunyuan, as long as it doesn't need to generate private areas?
Why can't we just get a model that's good at everything? We're running out of multi-billion dollar Chinese tech giants to gift us free stuff.
HunYuan team: Please put out a HunYuan T2V without any censorship please. I know you trained it on all kinds of things (concepts are still partially there or in reduced quality/accuracy) and apparently walked back some of that ability for release.
Perhaps these tech giants do not belong to any localization, and similarly, open source models still have to rely on us to figure out everything ourselves. Why did you delete your own account?
@METAFILM_Ai Yeah, I'm personally irritated by the need to keep an account just to download some stuff, so I delete and make new ones all the time. I don't engage in an abusive way or spam, so it shouldn't be an issue.
can't use increase resolution(Upscaler and frame interpolation), it terminates the program immediately, what happened?
The most likely cause is CPU memory overflow. ComfyUI has good VRAM management, but excessive memory requests for components can cause program interruptions
@METAFILM_Ai In my case with Google Colab Pro+, everything is stable and good when I skip the upscaler and frame interpolation process. However, unfortunately, there is no error message, it simply terminates the task.
@luongtuananh2017761 Can fluctuations in memory resources be detected? Especially at the moment when a large number of super-resolution slices are loaded into the node program. Recommend using devices with 64GB-128GB memory for super-resolution and frame insertion
Файл подкачки на SSD установи 64-Gig,
@METAFILM_Ai Personally I recommend 128gb for upscaling
This goes in text encoders?
wanAIWan21VideoModelSafetensors_kijaiOpenCliplVitWan
Yes, this is the encoder required for text generated videos.
@METAFILM_Ai Hi! where I can find workflows for Kijai? im very new in this, please help!
How is this model in regards to NSFW and censorship? Are you able to generate NSFW stuff without any Loras or do you have to make clever prompting to get around it?
While the official model probably went through rigorous compliance checks, Seems like the model's creators had to jump through tons of compliance hoops, but hey – that's why we've got genius community wizards doing mind-blowing hacks! With their i2v models using reference images as prompts? Seriously, the creative possibilities are endless.
This is really solid. I'm honestly impressed how well my dinky little 4080 ran this. Kudos for putting everything needed to do it all in one convenient place.
Yeah, don't set the Excessive resolution (I only used 480 * 720 during testing) and 33 frames are enough for testing
looks great but doesnt work - ksampler says triton not isntalled."torch._dynamo.exc.BackendCompilerFailed: backend='inductor' raised:"
what even is that?
Assuming you tried 1.5? It doesn't work because you didn't install triton and sageassist. Those are external dependencies that comfymanager will not just auto download.
in Win10 environment, the inference accelerator can be set to SDPA
This way, there is no need to tinker with the compilation environment to install Triton and Sageassist, as they are both equally slow
Ask chatgpt how to install triton and sageattention and follow the steps. Sageattention and triton are used to speed up video generation by 50%. If you really cannot install it, you can remove those nodes.
Total novice question: This only works on comfy UI? Not on other UIs?
Give Diffsynth Studio a shot! You can use it for inferences—it even handles Basemodel and LoRA training, GitHub - modelscope/DiffSynth-Studio: Enjoy the magic of Diffusion models!
However, the most commonly used inference UI is still ComfyUI =)
There's a lot of stuff on this post. Can someone summarize few key points.
-What is the point of comfyorg models?
-What are Kijai versions of the models?
Are these just rehosted models for OPs own purposes, or do these for example alter the model somehow to enable NSFW?
Any reason why the comfyui native worflow give a way better nsfw results using the 480p GGUF instead of the 720p_fp8 at 512x780? the image is way more cleaner and way more natural "it's a little too slow motion" but natural motion.
Is there a difference between using the 720P and 480P models to generate 832x480 video?
Yes, there is a difference. The 720P model may exhibit excessively high material density when generating small sizes.
@METAFILM_Ai What does this mean?
Is there a GGUF of the 14B 720p I2V model?
soon
Hello, how you upscale video?
Webp format videofiles contain workflows, which can be dragged to ComfyUI to view
@METAFILM_Ai can you explain to me how to get .webp with workflow from videos on civitai? Before this I only dragged images or opened workflow from my own videos, dragging images that are additionally saved by videohelpersuite node. thx
@StDismas Find a video file in WEBP format generated by ComfyUI, download it to local, and drag it into the ComfyUI web interface. (If the WEBP file saves the workflow) you can see it in ComfyUI, just like complete files with workflows such as PNG or JPG.
Details
Files
onTHEFLYWanAIWan21VideoModel_comfyorgWan21Vae.safetensors
Mirrors
papalor_v10.safetensors
wan_2.1_vae.safetensors
onTHEFLYWanAIWan21VideoModel_comfyorgWan21Vae.safetensors
wanVideo_wan21VAE.safetensors
wanVideo_wan21VAE.safetensors
wan_2.1_vae.safetensors
onTHEFLYWanAIWan21VideoModel_comfyorgWan21Vae.safetensors
wan_2.1_vae.safetensors
wan_2.1_vae.safetensors
wan_2.1_vae.safetensors
wan_2.1_vae.safetensors
wanAIWan21VideoModelSafetensors_comfyorgWan21Vae.safetensors
wanVideo_wan21VAE.safetensors
wanAIWan21VideoModelSafetensors_comfyorgWan21Vae.safetensors
onTHEFLYWanAIWan21VideoModel_comfyorgWan21Vae.safetensors
wanVideo_wan21VAE.safetensors
wan_2.1_vae.safetensors
wanVideo_wan21VAE.safetensors
wan_2.1_vae.safetensors
wan_2.1_vae.safetensors
wan_2.1_vae.safetensors
wan_2.1_vae.safetensors
wan_2.1_vae.safetensors
wan_2.1_vae.safetensors
wan_2.1_vae.safetensors
wan_2.1_vae.safetensors
wan_2.1_vae.safetensors
wan_2.1_vae.safetensors
wan_2.1_vae.safetensors
wan_2.1_vae.safetensors
wan_2.1_vae.safetensors
wan_2.1_vae.safetensors
wan_2.1_vae.safetensors
wan_2.1_vae.safetensors
wan_2.1_vae.safetensors
wan_2.1_vae.safetensors
wan_2.1_vae.safetensors
wan_2.1_vae.safetensors
wan_2.1_vae.safetensors
wan_2.1_vae.safetensors
wan_2.1_vae.safetensors
wan_2.1_vae.safetensors
wan_2.1_vae.safetensors
wan_2.1_vae.safetensors
wan_2.1_vae.safetensors
wan_2.1_vae.safetensors
wan_2.1_vae.safetensors
wan_2.1_vae.safetensors
wan_2.1_vae.safetensors
wan_2.1_vae.safetensors
wan_2.1_vae.safetensors
wan_2.1_vae.safetensors
wan_2.1_vae.safetensors
wan_2.1_vae.safetensors
wan_2.1_vae.safetensors
wan_2.1_vae.safetensors
Wan2.1_VAE.safetensors
Wan2.1_VAE.safetensors
wan_2.1_vae.safetensors
wan_2.1_vae.safetensors
wan_2.1_vae.safetensors
Wan2.1_VAE.safetensors
wan_2.1_vae.safetensors
Wan2.1_VAE.safetensors
wan_2.1_vae.safetensors
Wan2.1_VAE.safetensors
Wan2.1_VAE.safetensors
wan_2.1_vae.safetensors
Wan2.1_VAE.safetensors
wan_2.1_vae.safetensors
Wan2.1_VAE.safetensors
wan_2.1_vae.safetensors
wan_2.1_vae.safetensors
wan_2.1_vae.safetensors
wan_2.1_vae.safetensors
wan_2.1_vae.safetensors
wan_2.1_vae.safetensors
wan_2.1_vae.safetensors
wan_2.1_vae.safetensors
wan_2.1_vae.safetensors
wan22S2V14BGGUFQ3KM_vae.safetensors
wan_2.1_vae.safetensors
wan_2.1_vae.safetensors
wan_2.1_vae.safetensors
onTHEFLYWanAIWan21VideoModel_comfyorgWan21Vae.safetensors
wan_2.1_vae.safetensors
wan_2.1_vae.safetensors
wan_2.1_vae.safetensors
wan_2.1_vae.safetensors
wan_2.1_vae.safetensors
wan_2.1_vae.safetensors
wan_2.1_vae.safetensors
Wan2.2_VAE.safetensors
wan_2.1_vae.safetensors
wan_2.1_vae.safetensors
Wan2.1_VAE.safetensors
wan_2.1_vae.safetensors
wan_2.1_vae.safetensors
wan_2.1_vae.safetensors
wan_2.1_vae.safetensors
wan_2.1_vae.safetensors
wan_2.1_vae.safetensors
wan_2.1_vae.safetensors
wan_2.1_vae.safetensors
wan_2.1_vae.safetensors
wan_2.1_vae.safetensors
Wan2.1_VAE.safetensors
wan_2.1_vae.safetensors
wan_2.1_vae.safetensors
Wan2.1_VAE.safetensors
wan_2.1_vae.safetensors
wan_2.1_vae.safetensors
WAN-2.2-I2V_VAE_wan_2.1_vae.safetensors
Wan2.1_VAE.safetensors
wan_2.1_vae.safetensors