














Sponsorship:
For sponsorship, please contact us on Discord. Your support helps us grow and improve future work.
Buy Custom Models:
If you're interested in buying a LoRA model, contact us—we can get it done in a short time.
Vision Realistic Flux dev fp8 Model Overview
I'm excited to share my latest model, Vision Realistic Flux
We all know the original Flux model is already one of the best out there, so further fine-tuning might seem unnecessary—honestly, I thought it could be a waste of time. However, I did notice a few issues, like occasional blurry images that didn’t make sense, and skin tones that weren’t quite right, especially when aiming for realistic results. So, I decided to tackle those problems. While I'm not completely satisfied with every detail, the improvements are definitely noticeable—better handling of NSFW content, brighter images, and far fewer blur issues.
Is this model better than the original Flux?
Not necessarily, but in some cases, like photorealism, it does perform better. Ultimately, it depends on your taste and what you're looking for.
How I Made This Model:
I trained some LoRA models and then merged them with the Flux dev fp8 model. During this process, I made a few optimizations. The model now has CLIP and VAE baked in, so you don’t need to use separate versions.
How to Use This Model:
You can run this model on ComfyUI. I’ve only had time to test it on ComfyUI, so if you try it on something else, I’d love to hear about your experience in the comments.
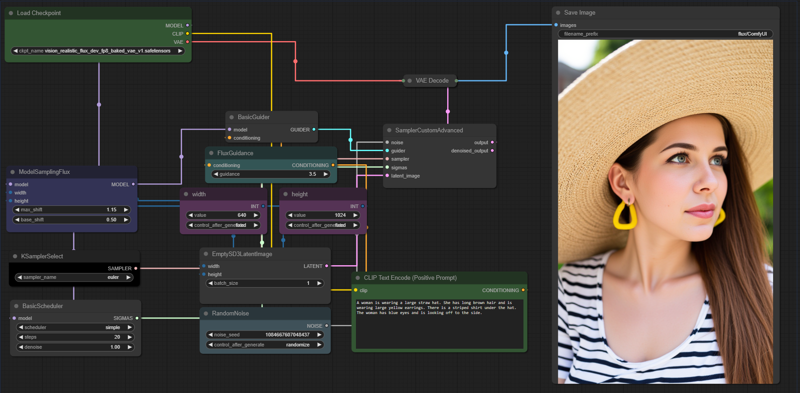
Quick Parameters for ComfyUI:
VAE: Already baked in
Sampler: Euler
Scheduler: Simple
Sampling Steps: 20
CFG Scale: 1
===========================================================
Vision Realistic
I am excited to present my latest Realistic checkpoint model based on SD3M. This model has undergone over 100k+ training steps, ensuring high-quality output.
About This Model:
This is a Photo Realistic model, capable of generating photorealistic images. No trigger words are needed. The model is designed to produce high-detail, high-resolution images that closely mimic real-life photographs.
Configuration Used for Training:
GPU: A6000x2
Dataset: A mix of 5k stock photos and my own dataset
Batch Size: 8
Optimizer: AdamW
Scheduler: Cosine with restarts
Learning Rate (LR): 1e-05
Epoch: Target of 300 epochs
Captioning: WD14 and BLIP mix
Important: Avoid including NSFW-related/mature words in your prompts. Doing so may result in unreliable image outcomes. Also, avoid using too long prompts as smaller prompts work better on SD3.
Quick Guide and Parameters:
Clip Encoder: Not required
VAE: Not required
Sampler: dpmpp_2m
Scheduler: sgm_uniform
Sampling Steps: 25+
CFG Scale: 3+
For better results, try using ComfyUI
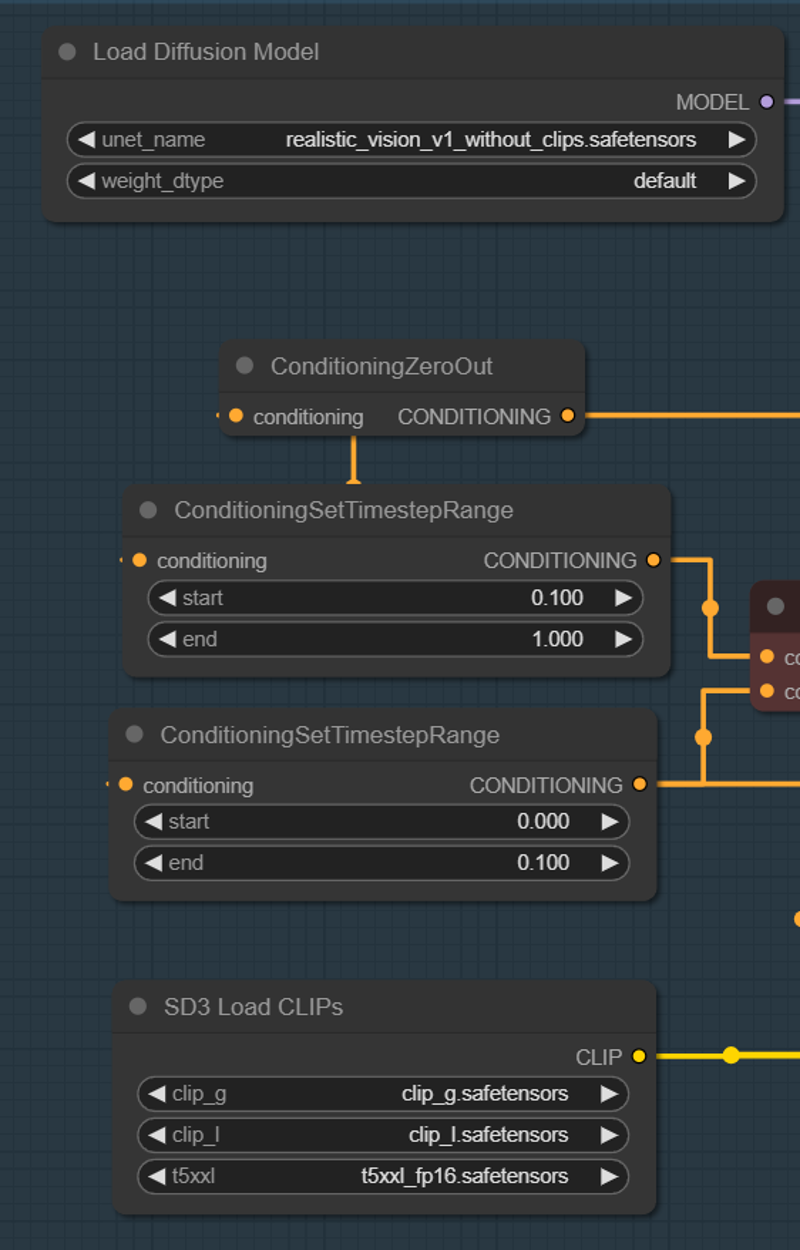
If you download the version without CLIP, please follow these guidelines:
This version won't work like a normal SD3M model. You must load the model using 'Load Diffusion Model.'
You can use all SD3M text encoders that come with it.
You need a VAE. Download it and place it in the VAE folder:
ComfyUI\models\vae.Place the model in the UNet folder:
ComfyUI\models\unet.
Note:
This is not a merged or modified model. It is the original Realistic Vision fine-tuned model. Some users have been spreading incorrect information in the model's comment section. If you have any questions or want to know more, join my Discord server or share your thoughts in the comment section. Thank you for your time.
Description
FAQ
Comments (30)
why fp8?
Make q8 which is much closer to fp16
The flux version does look much clearer than base, but it doesn't seems to work with loras as well as the base or other fine tunes I have tried.
@psspsspsspssspss May I ask where you tried it ComfyUI or Forge UI? If you used Forge UI, I recommend trying it with ComfyUI. From my experience, it works well with ComfyUI.
@Ai_Art_Vision Alright gave it a whirl in comfy and it works much better. Thanks for the tip :)
Hands down, this is the best photorealistic Flux model I've seen to date - and I've tested them all.
Visually, the model is not bad, but the understanding of the prompt is at the level of SDXL. I hope the author will fix this shortcoming in the future.
@lizirginart980 Thanks for the feedback! I’m aware of that, and I’m working on it. It will take some time, but I’ll do my best to improve it.
Its too soft compared to stock flux, sharpness suffered
@Ai_Art_Vision consider using a modern VLM like GLM-4V, MiniCPM, CogVLM2, JoyCaption or Florence 2
Well done, great model.
I'm very interested in knowing how to merge loras to flux models. It's not easy to find information on this. (especially when you have bad English like me).
I would really like to do my own experiments on flux
@Error666 It’s actually pretty easy to merge ckpt/LoRAs with flux models if you’re familiar with ComfyUI. Here’s how you can do it:
1/- In ComfyUI, find the 'ModelMergeFlux' node.
2/- Load your flux model using the 'Diffuser Model Loader' along with the 'CLIP Loader' if your model doesn’t have a baked CLIP. Otherwise, you can use the 'Checkpoint Loader.
3/- For merging, load your checkpoint and LoRA into 'MergeModelFlux Input 1.'
4/- checkpoint into 'MergeModelFlux Input 2.'
5/- Then, connect the output of 'MergeModelFlux' to 'Save Checkpoint Model.'
6/- Load vae to 'Save Checkpoint Model.'
Try different LoRA weights and experiment to figure out what works best for u
@Ai_Art_Vision Wow so simple ! thank you very much !
please upload unet version only, thanks
@RizhanZaradi Done🤝
Who woulda think, finally, the flux generated female face without annoying square jaw and a dimple on chin!
Also, can it generate a small breast? The basic flux model can't, I'm wondering if this model can do it.
Flux is not working. I am using the workflow. model weight dtype torch.float8_e4m3fn, manual cast: torch.float32
model_type FLUX
WARNING: No VAE weights detected, VAE not initalized.
!!! Exception during processing!!! cannot access local variable 'dtype_t5' where it is not associated with a value
Do I need to use the full version in combination with the provided workflow? If so maybe the default model download should be the full version.
This is just the UNET. You need to load the CLIP and VAE separately using the standard Flux workflow.
@Grumblebutt what's a clip. is there a good tutorial for a flux workflow?
@thetodd2022349 ATM it is the wild west. But if you want to run this model the easy way. On the right side there are 2 files, download the bigger one (Full Model fp8). If you do not have Comfyui installed, install it. Than download the workflow in the description of this model, load the workflow inside your comfyui workspace. You should be good to go...
Is it gender balanced? Diverse people? Diverse ages?
Nobody cares!
There wont be all fantasy genders, but as far as i have tested, there are many different males and females in any race. You do not even need to mention a race, but a country is good enough (but dont expect for example to have dark skinned when you write "turkish", you still need some description to get the wanted skin color in many cases).
@Ascendant_Stoic dude wth is wrong with you
@kaivanbi922 @kaivanbi922 ya, I don't need every single race, it's not some social justice thing.
Just if this is a generalist tune, and not just a "20 year old slender white girl" model, then I want to be able to do a lot with it. A fat old Scottish woman with a red beard, or a Russian gypsy kid playing accordion etc...
I basically want to know is it a generalist tune, or a "fit pretty young women portrait generator"
@kunde2 Sick and tired of entitled "social justice" brats and political correctness garbage, it's so tiresome, insipid and stupid.
Janet did clarify their question wasn't about social justice nonsense, so whatever.
@Ascendant_Stoic ya, again, it's not a political thing; I also hate that garbage.
But a lot of finetunes suck; they're just young white women, which is fine if that's what you want, but don't call it a generalist finetune. A generalist finetune should have everything. People 0-99 years old, fat people, anorexic people, bodybuilders, ugly people, good looking people. People in all states of dress and undress.
If it's actually diverse it would in fact be very non-PC.
Why is this model listed as SD3?
There's a version that's SD3. The more recent versions are Flux.
This is falsely tagged as Checkpoint Trained. It should be a Checkpoint Merged.
Thank you for this fine-tune but please update your description as it contains multiple confusing and contradicting informations.
> I trained some LoRA models and then merged them with the Flux dev fp8 model.
> It is the original Realistic Vision fine-tuned model.
So is it a Lora merge or a fine-tuned model?
> Realistic checkpoint model based on SD3M
> Also, avoid using too long prompts as smaller prompts work better on SD3.
> This version won't work like a normal SD3M model.
> You can use all SD3M text encoders that come with it.
So is it a Stable Diffusion 3 checkpoint or a Flux-Dev checkpoint?
> CFG Scale: 3+
default flux workflows don't use CFG scale. do you mean FluxGuidance?
> <workflow json>
What is this workflow and what is "3D Cartoon Vision"?
> <Workflow image> unet_name realistic_vision_v1
> It is the original Realistic Vision fine-tuned model.
The original [Realistic Vision](https://civitai.com/models/4201) is a popular SD1 model by SG_161222. How are you affiliated the original model and author?
Details
Files
Available On (1 platform)
Same model published on other platforms. May have additional downloads or version variants.