✨ WAN2.1 — Text to video — Simple Workflow
A clean, all-in-one WAN text-to-video workflow built entirely with the UmeAiRT Toolkit for ComfyUI.
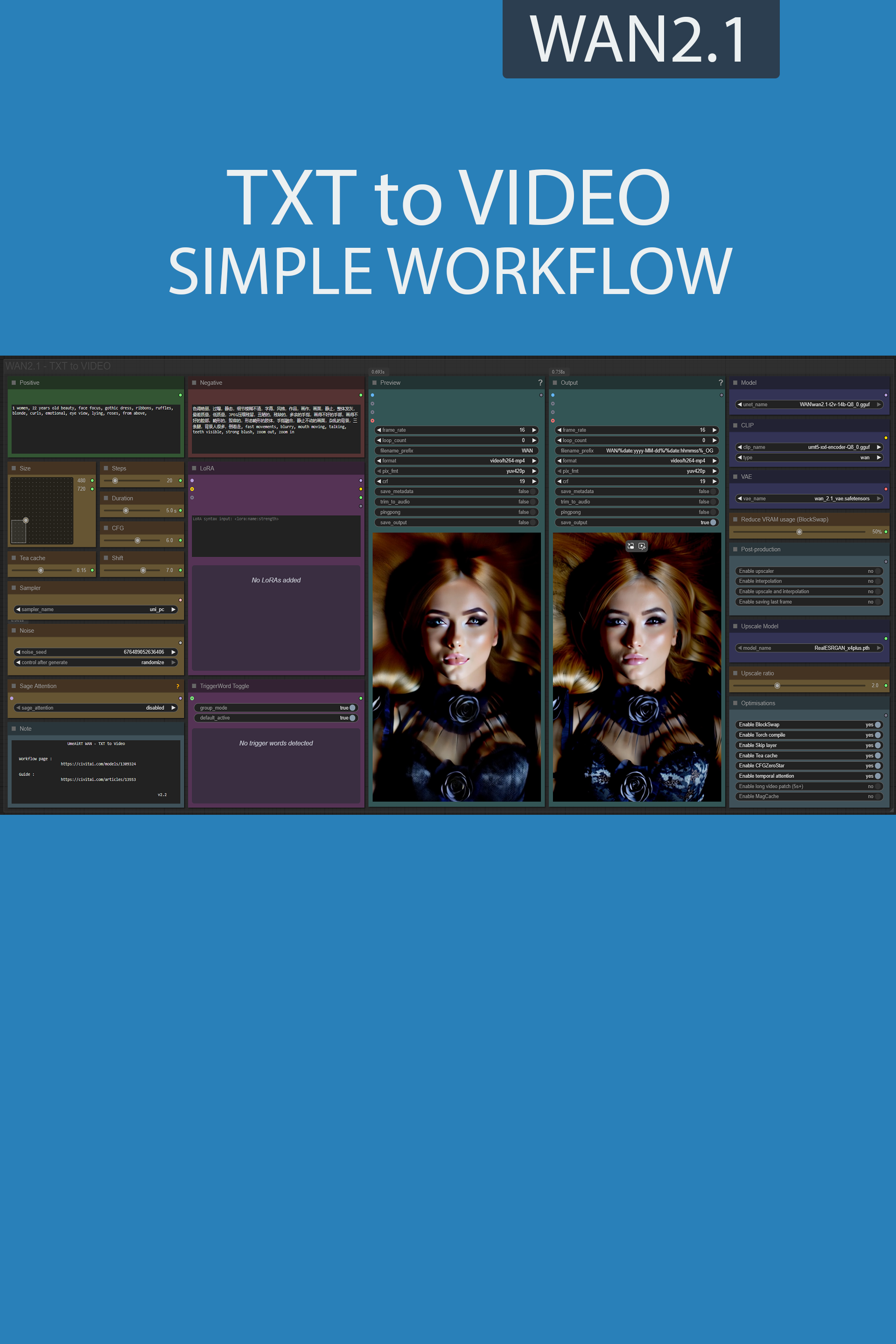
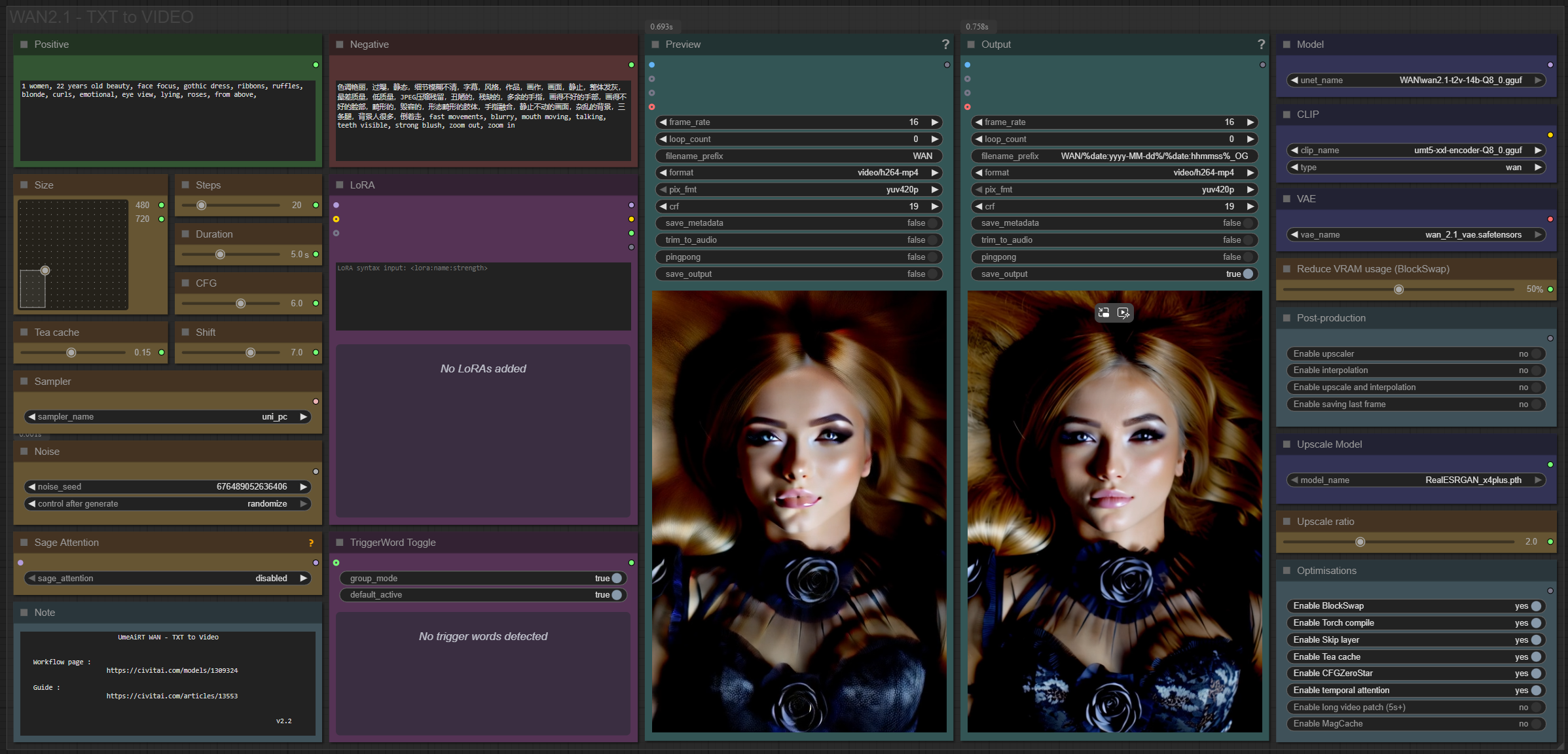
Only 12 nodes. No spaghetti wires. Just load your model, write your prompt, and hit generate.
⚠️ IMPORTANT — Nodes 2.0 Required
This workflow is built for the Nodes 2.0 (Vue) interface of ComfyUI. If you don't enable it, the workflow may have display problems.
How to activate Nodes 2.0:
Open ComfyUI
Go to Settings (⚙️ icon, bottom-left)
Find "Use Nodes V2 (Vue)" and toggle it ON
Refresh the page
Load the workflow
If you prefer the classic interface, check out my Legacy version of this workflow instead (link).
🎯 Features
Text-to-Image generation
Automatic download of models in auto version
Built-in SeedVR2 upscaler — high-quality tiled upscaling (toggleable on/off) Slower than a classic upscaler, but significantly better quality
Full metadata embedding — your images are saved with all generation parameters, ready for online publishing and remixing
3 LoRA slots — with individual on/off toggles and strength control and you can connect as many other lora modules to each other for as many LoRA as you want.
📦 Custom Node Required
Only one custom node to install:
Install via ComfyUI Manager (search "UmeAiRT") or use the UmeAiRT Auto-Installer.
The Toolkit packages everything internally — upscaler, face detailer, metadata saver. No other custom nodes needed.
📂 Files you need (in manual version)
For base version
T2V Model: fp16, fp8
In models/diffusion_models
For GGUF version
T2V Quant Model: Q8, Q5, Q3
In models/diffusion_models
Common files :
CLIP: umt5_xxl_fp8_e4m3fn_scaled.safetensors
in models/clip
VAE: wan_2.1_vae.safetensors
in models/vae
Speed LoRA: lightx2v_T2V_14B_cfg_step_distill_v2_lora_rank64_bf16.safetensors
in models/loras
ANY upscale model:
Realistic : RealESRGAN_x4plus.pth
Anime : RealESRGAN_x4plus_anime_6B.pth
in models/upscale_models
Description
Interface adjustment :
The frames slider is replaced by a duration slider in seconds,
removed the interpolation ratio slider,
All models files are now in the main window.
Backend :
reduction of the number of custom nodes from 12 to 8,
improvement of the automatic prompt function with the replacement of 8 words like "image" or "drawing" by video to avoid making static videos,
added clip loader in GGUF version.
New "Post-production" menu.
Rollback on native upscaler.
New model optimisation :
Temporal attention for improve spatiotemporal predictive.
RifleXRoPE reduce bugs on videos longer than 5s. This allows you to increase the maximum video length from 5s to 8s.
MagCache,
Blockswap.
FAQ
Comments (1)
v2.2 works pretty well. I think my only complaint is that the lora loader is a bit of a pain to fiddle with, (having to type it in instead of just selecting from a dropdown) but other than that.. works pretty great.