
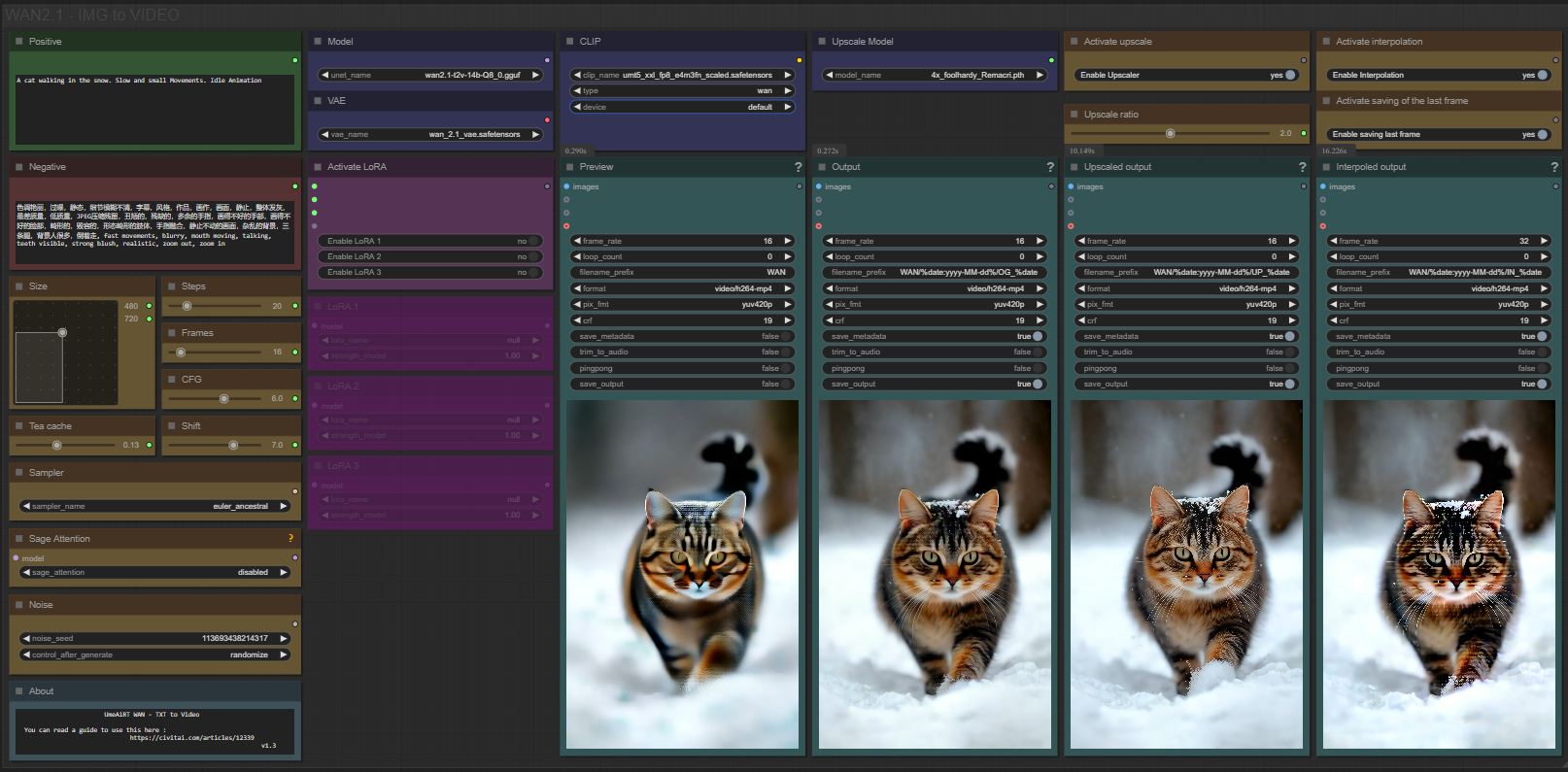
✨ WAN2.1 — Text to video — Simple Workflow
A clean, all-in-one WAN text-to-video workflow built entirely with the UmeAiRT Toolkit for ComfyUI.
Only 12 nodes. No spaghetti wires. Just load your model, write your prompt, and hit generate.
⚠️ IMPORTANT — Nodes 2.0 Required
This workflow is built for the Nodes 2.0 (Vue) interface of ComfyUI. If you don't enable it, the workflow may have display problems.
How to activate Nodes 2.0:
Open ComfyUI
Go to Settings (⚙️ icon, bottom-left)
Find "Use Nodes V2 (Vue)" and toggle it ON
Refresh the page
Load the workflow
If you prefer the classic interface, check out my Legacy version of this workflow instead (link).
🎯 Features
Text-to-Image generation
Automatic download of models in auto version
Built-in SeedVR2 upscaler — high-quality tiled upscaling (toggleable on/off) Slower than a classic upscaler, but significantly better quality
Full metadata embedding — your images are saved with all generation parameters, ready for online publishing and remixing
3 LoRA slots — with individual on/off toggles and strength control and you can connect as many other lora modules to each other for as many LoRA as you want.
📦 Custom Node Required
Only one custom node to install:
Install via ComfyUI Manager (search "UmeAiRT") or use the UmeAiRT Auto-Installer.
The Toolkit packages everything internally — upscaler, face detailer, metadata saver. No other custom nodes needed.
📂 Files you need (in manual version)
For base version
T2V Model: fp16, fp8
In models/diffusion_models
For GGUF version
T2V Quant Model: Q8, Q5, Q3
In models/diffusion_models
Common files :
CLIP: umt5_xxl_fp8_e4m3fn_scaled.safetensors
in models/clip
VAE: wan_2.1_vae.safetensors
in models/vae
Speed LoRA: lightx2v_T2V_14B_cfg_step_distill_v2_lora_rank64_bf16.safetensors
in models/loras
ANY upscale model:
Realistic : RealESRGAN_x4plus.pth
Anime : RealESRGAN_x4plus_anime_6B.pth
in models/upscale_models
Description
Bugfix: Cleared the cache after generation to limit bugs during upscaling
Added: Frame interpolation, saving the last frame, model shifting
FAQ
Comments (7)
Great workflow, works well right out of the box. Thank you for posting this.
A great workflow as always, it's my go to for Text to Video with Wan and works really well. It is very well laid out and very adjustable to cover most peoples needs and systems.
The added guide you have produced also raises it to another level in my opinion at least.
Sometimes I get slightly distorted faces with full body videos, so maybe a facedetailer or face swap node will help me there I'm just not sure how to add it.
Also is it possible to add a wildcard node at the start somewhere to help with random inspiration?
Hey, amazing work as always, i do have an issue though, if anybody has a solution i would appreciate sharing!
using the txt to video workflows, tried multiple versions, i just get random noise on a black background, using everything exactly as the image in the workflow and going step by step according to the guide except the model since i have 4070 with 12gb of ram so i took the smaller model
here an example of the outputs i get:
https://imgur.com/a/55y3JDY
edit: img to video does work without issue
It's because you are using a Image to video model in a text to video workflow.
You can download T2V model here : city96/Wan2.1-T2V-14B-gguf at main
@UmeAiRT I feel stupid now XD
Thank you!
@UmeAiRT I was about to ask the same thing. It looks like the Quant Model in the description of this page is the I2V, rather than the T2V model. Thanks for answering, though!
@DiffusionGuru I modified the link 2 days ago and it was a bad copy and paste, everything is corrected now.