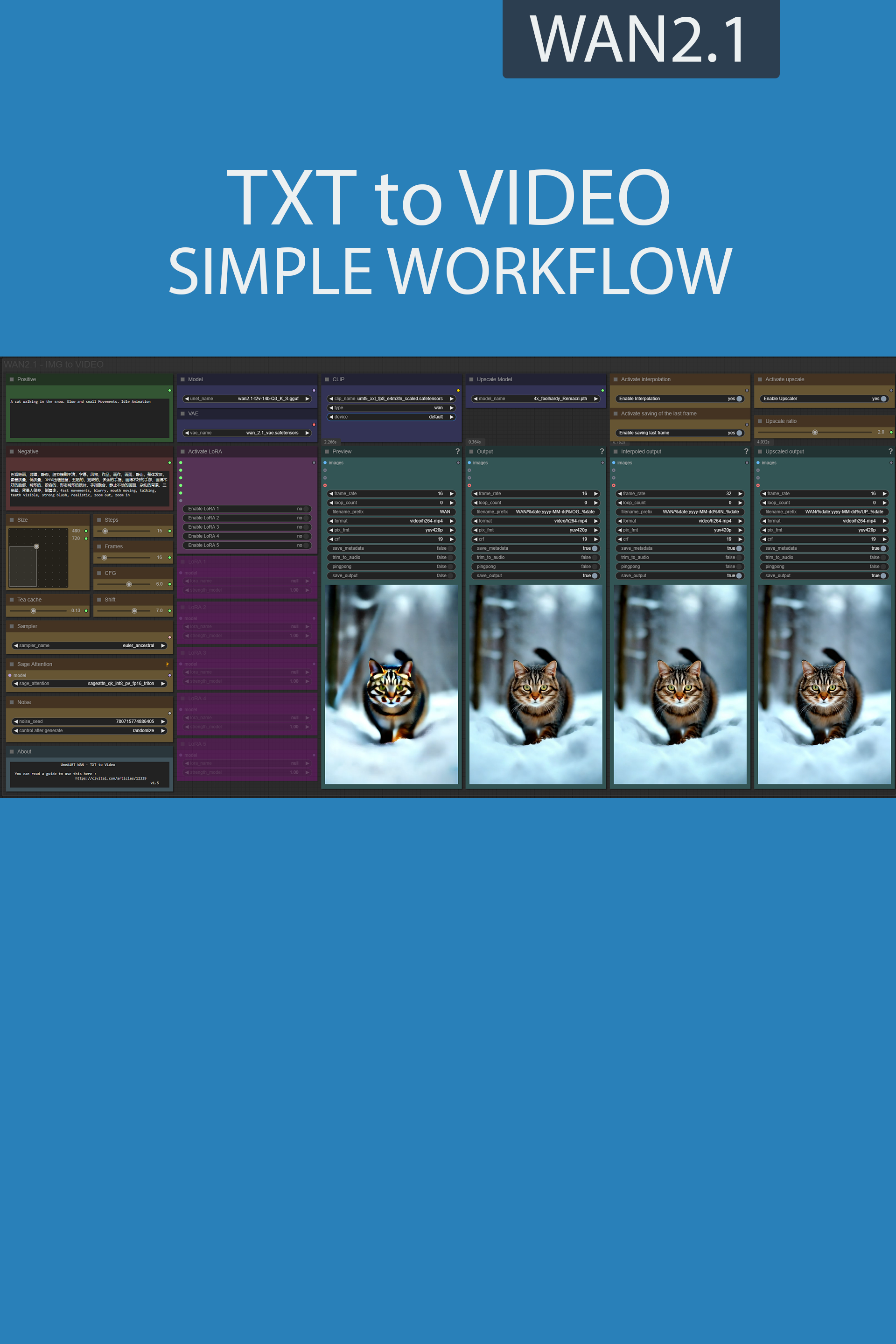
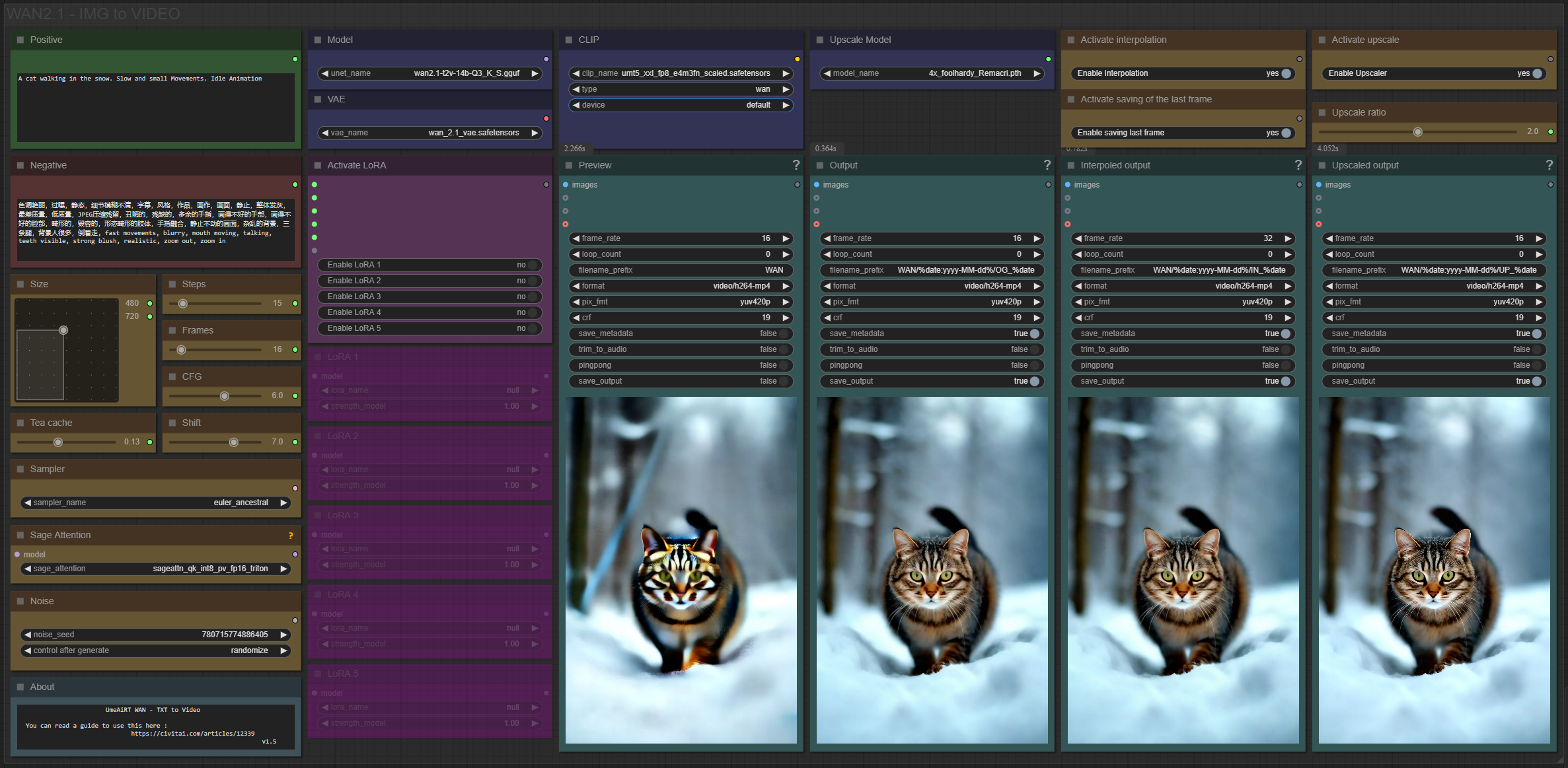
✨ WAN2.1 — Text to video — Simple Workflow
A clean, all-in-one WAN text-to-video workflow built entirely with the UmeAiRT Toolkit for ComfyUI.
Only 12 nodes. No spaghetti wires. Just load your model, write your prompt, and hit generate.
⚠️ IMPORTANT — Nodes 2.0 Required
This workflow is built for the Nodes 2.0 (Vue) interface of ComfyUI. If you don't enable it, the workflow may have display problems.
How to activate Nodes 2.0:
Open ComfyUI
Go to Settings (⚙️ icon, bottom-left)
Find "Use Nodes V2 (Vue)" and toggle it ON
Refresh the page
Load the workflow
If you prefer the classic interface, check out my Legacy version of this workflow instead (link).
🎯 Features
Text-to-Image generation
Automatic download of models in auto version
Built-in SeedVR2 upscaler — high-quality tiled upscaling (toggleable on/off) Slower than a classic upscaler, but significantly better quality
Full metadata embedding — your images are saved with all generation parameters, ready for online publishing and remixing
3 LoRA slots — with individual on/off toggles and strength control and you can connect as many other lora modules to each other for as many LoRA as you want.
📦 Custom Node Required
Only one custom node to install:
Install via ComfyUI Manager (search "UmeAiRT") or use the UmeAiRT Auto-Installer.
The Toolkit packages everything internally — upscaler, face detailer, metadata saver. No other custom nodes needed.
📂 Files you need (in manual version)
For base version
T2V Model: fp16, fp8
In models/diffusion_models
For GGUF version
T2V Quant Model: Q8, Q5, Q3
In models/diffusion_models
Common files :
CLIP: umt5_xxl_fp8_e4m3fn_scaled.safetensors
in models/clip
VAE: wan_2.1_vae.safetensors
in models/vae
Speed LoRA: lightx2v_T2V_14B_cfg_step_distill_v2_lora_rank64_bf16.safetensors
in models/loras
ANY upscale model:
Realistic : RealESRGAN_x4plus.pth
Anime : RealESRGAN_x4plus_anime_6B.pth
in models/upscale_models
Description
Bugfix : upscaling node
Add : Change of execution order between interpolation and upscaling, really independent and better optimized.
FAQ
Comments (9)
What's new in 1.4? I dont see anything in description?
You dont see the about this version text in CIVITAI?
Add layer skip for improved video quality (less visual glitch, sharper image, better hair and hand detail).
Ok, thanks, Yea I just tried 1.4 it is working fine. but honestly don't remember any issues with glitching in 1.3
@trashkollector175 You can see difference here : Dramatically enhance the quality of Wan 2.1 using skip layer guidance : r/StableDiffusion
But yes depending on your settings and model, you may not have had any problems.
@UmeAiRT Awesome, you are doing great work.. I pretty much am using all your workflows.. love it.
@trashkollector175 Thanks !
The Chinese text in the negative input:
bright colors, overexposed, static, blurred details, subtitles, style, artwork, painting, picture, still, overall gray, worst quality, low quality, JPEG compression residue, ugly, incomplete, extra fingers, poorly drawn hands, poorly drawn faces, deformed, disfigured, deformed limbs, fused fingers, still picture, cluttered background, three legs, many people in the background, walking backwards,
Are you sure what TeaCache working correctly in 1.5 Ver? Why I dont see Teacache message in terminal window? In 1.4 it send messages...
and it works slowly than 1.4 IMHO
working fine here.