Workflow: Image -> Autocaption (Prompt) -> WAN I2V with Upscale and Frame Interpolation and Video Extension
Creates Video Clips with up to 480p resoltion (720p with corresponding model)
There is a Florence Caption Version and a LTX Prompt Enhancer (LTXPE) version. LTXPE is more heavy on VRAM
LTX Prompt Enhancer (LTXPE) might have issues with latest Comfy and Lightricks update
MultiClip: Wan 2.1. I2V Version supporting Fusion X Lora to create clips with 8 steps and extend up to 3 times, see examples posted with 15-20sec of length.
Workflow will create a clip on Input Image and extends it with up to 3 clips/sequences. It uses a colormatch feature to ensure consistency in color and light in most cases. See the notes in worflow with full details.
There is a normal version which allows to use own prompts and a version using LTXPE for autoprompting. Normal version works well for specific or NSFW clips with Loras and the LTXPE is made to just drop an image, set width/height and hit run. The clips are combined to one full video at the end.
update 16th of July 2025: A new Lora "LightX2v"has been released as an alternative to Fusion X Lora. To use, switch Lora in black "Lora Loader" node. It can create great motion with only 4-6 steps. : https://huggingface.co/lightx2v/Wan2.1-I2V-14B-480P-StepDistill-CfgDistill-Lightx2v/tree/main/loras
More info/tips & help: https://civarchive.com/models/1309065/wan-21-image-to-video-with-caption-and-postprocessing?dialog=commentThread&commentId=869306
V3.1: Wan 2.1. I2V Version supporting Fusion X Lora for fast processing
Fusion X Lora: process the video with just 8 Steps (or lower, see notes in workflow). It does not have the issues like the CausVid Lora from V3.0 and does not require a color match correction.
Fusion X Lora can be downloaded here: https://civarchive.com/models/1678575?modelVersionId=1900322 (i2V)
V3.0: Wan 2.1. I2V Version supporting Optimal Steps Scheduler (OSS) and CausVid Lora
OSS is a newer comfy core node to allow lower no. of steps with a boost in quality. Instead of using 50+ steps you can receive same result with like 24 steps. https://github.com/bebebe666/OptimalSteps
CausVid uses a Lora to process the video with just 8-10 steps, it is fast at a lower quality. It contains a Color Match option in postprocessing to cope with the increased saturation, the lora is introducing. Lora can be downloaded here: https://huggingface.co/Kijai/WanVideo_comfy/tree/main
(Wan21_CausVid_14B_T2V_lora_rank32.safetensors)
Both have a version with FLorence or LTX Prompt Enhancer (LTXPE) for Caption, can use Loras and have Teacache included.
V2.5: Wan 2.1. Image to Video with Lora Support and Skip Layer Guidance (improves motion)
There are 2 version, Standard with Teacache, Florence caption, upscale, frame interp. etc. plus a version with LTX Prompt Enhancer as an additional captioning tool (see notes for more info, requires custom nodes: https://github.com/Lightricks/ComfyUI-LTXVideo).
For Lora use, recommend to switch to own prompt with Lora trigger phrase, complex prompts might confuse some Loras.
V2.0: Wan 2.1. Image to Video with Teacache support for GGUF model, speeds up generation by 30-40%
It will render the first steps with normal speed, remaining steps with higher speed. There is a minor impact on quality with more complex motion. You can bypass the Teacache node with Strg-B
Example clips with workflow in Metadata: https://civarchive.com/posts/13777557
Info and help with Teacache: https://civarchive.com/models/1309065/wan-21-image-to-video-with-caption-and-postprocessing?dialog=commentThread&commentId=724665
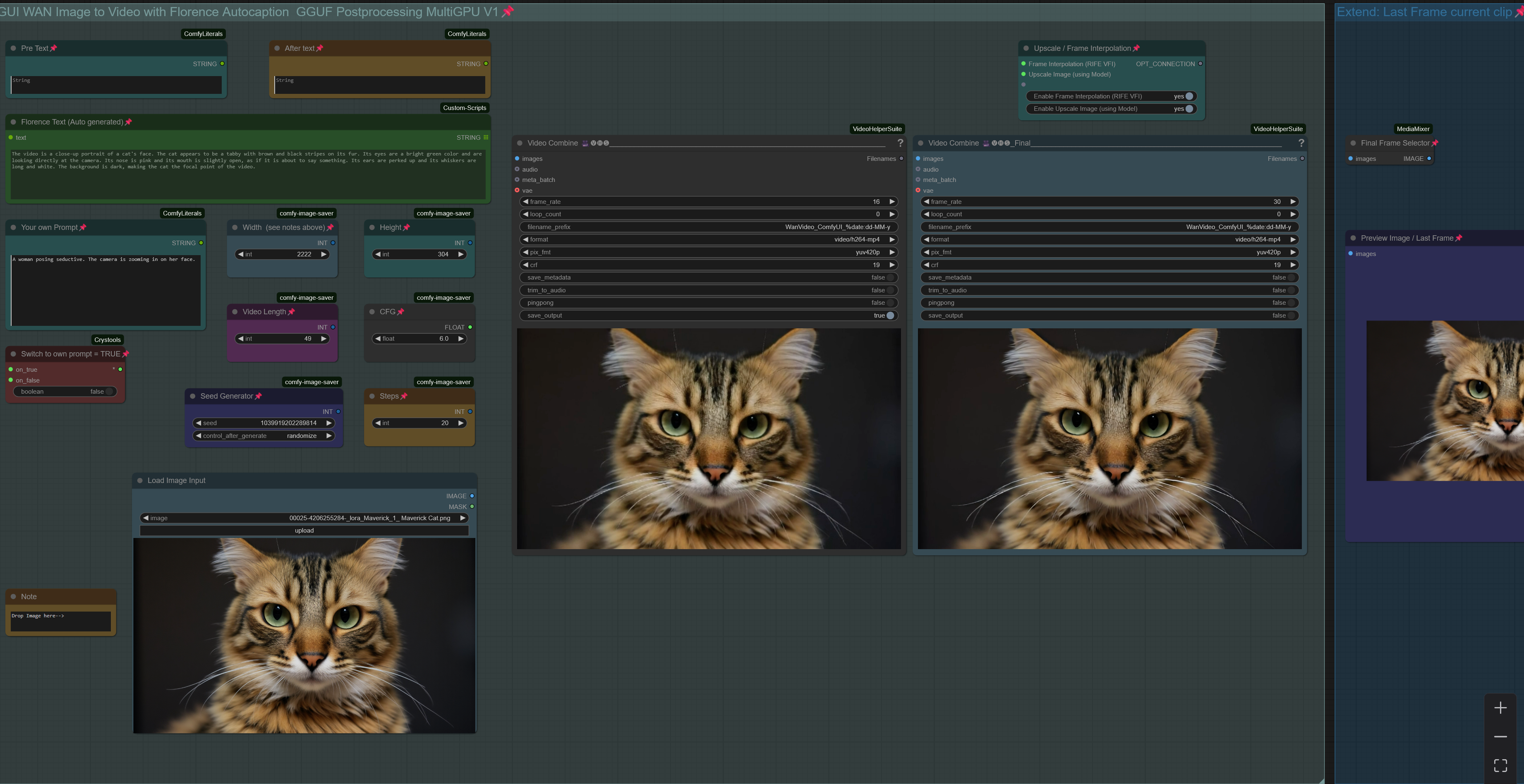
V1.0: WAN 2.1. Image to Video with Florence caption or own prompt plus upscale, frame interpolation and clip extend.
Workflow is setup to use a GGUF model.
When generating a Clip you can chose to apply upscaling and/or frame interpolation. Upscale factor depends on upscale model used (2x or 4x, see "load upscale model" node). Frame Interpolation is set to increase frame rate from 16fps (model standard) to 32fps. Result will be shown in "Video Combine Final" node on the right, while the left node shows the unprocessed clip.
Recommend to "Toggle Link visibility" to hide the cables.
Models can be downloaded here:
Wan 2.1. I2V (480p): https://huggingface.co/city96/Wan2.1-I2V-14B-480P-gguf/tree/main
Clip (fp8): https://huggingface.co/Comfy-Org/Wan_2.1_ComfyUI_repackaged/tree/main/split_files/text_encoders
Clip Vision: https://huggingface.co/Comfy-Org/Wan_2.1_ComfyUI_repackaged/tree/main/split_files/clip_vision
VAE: https://huggingface.co/Comfy-Org/Wan_2.1_ComfyUI_repackaged/tree/main/split_files/vae
Wan 2.1. I2V (720p): https://huggingface.co/city96/Wan2.1-I2V-14B-720P-gguf/tree/main
Wan2.1. Text to Video (works): https://huggingface.co/city96/Wan2.1-T2V-14B-gguf/tree/main
location to save those files within your Comfyui folder:
Wan GGUF Model -> models/unet
Textencoder -> models/clip
Clipvision -> models/clip_vision
Vae -> models/vae
Tips:
lower framerate in "Video combine Final" node from 30 to 24 to have a slow motion effect
You can use the Text to Video GGUF Model, it will work as well.
If video output shows strange artifacts on the very right side of a frame, try changing the parameter "divisible_by" in node "Define Width and Height" from 8 to 16, this might better latch on to the standard Wan resolution and avoid the artifacts.
see this thread if you face issues with LTX Prompt Enhancer: https://civarchive.com/models/1823416?dialog=commentThread&commentId=955337
Last Frame: If you face issues finding the pack for that node: https://github.com/DoctorDiffusion/ComfyUI-MediaMixer
Full Video with Audio example:
Description
Wan Image2Video, creating multiple clips from one Image with clip extension
(Normal Version for own prompts and LTXPE version for autoprompt)
FAQ
Comments (39)
wow. this is amazing
Some Tips and help with the MultiClip Version to create longer Clips by extending:
- Clips with less camera movement work best. Use term "(The camera remains on the act:1.1)" (or "...remains on character", etc.) in your prompt
- NSFW Clips with Loras (see seperate thread with links to useful Loras): Use the normal Version and set the first sequences for the action and set the last sequence to show the "happy ending"
- the final combining of clips can use a lot of system ram (not vram), you can also bypass "Image Batch Multi" +"Video combine final "node in global section and save individual clips by setting "save_output" in "Video combine" node within the local sequence sections. Then stitch them together with a video editor like Davinci Resolve (free).
- You can go for more than 4 extensions by right-click the last frame in any of local sequence and select "Send to workflow/current workflow" so it can start over from that frame.
- If any extended sequence is not meeting your desired output, just right-click the last frame node from the previous sequence, select "Send to workflow/current workflow" so it can start over from that frame and you can adjust parameters like seed or prompt.
- LTXPE Version does not realy help with NSFW "action" clips, as the instruct model of LTXPE is a bit censored and WAN does not realy create good NSFW clips without Loras. Use the normal Version with Loras for that purpose. Nude clips are no issue with LTXPE tho. LTXPE works great for just dropping an image and let the model do the rest.
- The new LightX2v Lora creates great clips with just 4-6 steps. The default colormatch settings might be too strong for that lora, so I am using a "ramp up": Sequence 01 = Strength 0.0, Sequ. 02 = Strength 0.4, Sequ. 03 = Strength 0.6. Regarding no. of steps, I have the first sequence with 6 steps and remaining with 4 steps.
When you say "Right-click the last frame node from the previous sequence", what do you mean exactly? I tried looking but can't see anything that gives the "Send to workflow/current workflow" dialogue?
@explicit123 each sequence has a node "Preview Image / last frame" in blue on the very right. If you right-click, then "send to workflow/current workflow" supposed to appear. A new workflow will appear with the selected last frame as the global image, so you can continue from there.
@tremolo28 hey man great work its working nice! got one problem, when i try to unbypass and make the 4th sequence, the final video only combining the first 3 sequences . any idea what i'm doing wrong?
Edit: found it just need to bypass the 4x___ instead of 3x___ :)
vAnN47 I love how you always find a solution by yourself before I can even answer :)
I had an error that is probably because i don't have enough vram.
(
Expected all tensors to be on the same device, but found at least two devices, cuda:0 and cpu! (when checking argument for argument index in method wrapper_CUDA__index_select)
Show ReportHelp Fix This
Find Issues
)
How do I fix this? I have 16 gigs of ram.
Hi, it is related to LTX Prompt enhancer, when u have less than 16gb of Vram. check this thread: https://civitai.com/models/1309065?modelVersionId=1998473&dialog=commentThread&commentId=730386
Someone found a manual fix.
thanks
Hi, I can't find where to load a lora in the multiclip workflow? (not fusionX, but any nsfw lora)
Hi, the purple nodes in global view are the loaders for any lora per sequence. Those are bypassed by default, there is a bypass node to activate them.
tremolo28 thanks for the fast reply, seems to be working now! but there's still learning curve so i'll try different things :)
i don't understand, when i launch it it ends immediately and outputs the original pic at the bottom
Check models. I found that FusionX lora path was incorrect. I chose it again and WF start working.
MultiClip workflow
Error : missing String node type, for Global prompt (text input box). Which custom node to be installed ?
Thanks.
Hi, text box for "Global Prompt" is from ComfyLiterals pack, see comfy manager or direct link: https://github.com/M1kep/ComfyLiterals
Is it possible to add Multiple WAN lora to one sequence? This would allow a lot more movement creativity
should work to just daisy chain another purple Lora loader node "LoraLoaderModelOnly".
When you select an exisiting loader node and Strg+C it, then hit shift + Strg +V, it pastes another node that is already connected with correct Input, then just connect the output to an exisiting lora loader´s input, voila 2 loaders in a chain.
@tremolo28 -- I never knew that... Lol thank you
My videos are way over corrected. Oversaturated, too sharp, blurry, and etc. I'm not sure what to do.
make sure resolution is at 480p. When using the LightX2v lora, lower the colormatch strength. Default settings are for Fusion Lora, that requires more color match strength.
Thanks for the really nice workflow.
One question tho, where is the final video? I created 4 sequences and activated only the "combine 4" and bypassed both the others. But I don't see the final video anywhere in the workflow or in the output folder.
Hi, make sure the "save_output" is set to "true" in final video combine node
@tremolo28 it is set to "true", but there is nothing in the output folder. Also should the be a node in the workflow that shows the combined video? Only in the temp folder are the sequence videos and start pictures. But also not the combined one. The prompt is finished after the last sequence, so it appears that no combing takes place.
Thanks for your help and your work!
@plastikjava yes, there is a node on the right of the global gui for the final combined video. The clip is saved in the usual output folder. Does the video combine work for for you with other workflows? Do you have ffmpeg installed?
@tremolo28 I didn't have ffmpeg installed, but apparently the problem was, that I didn't have the upscale model 😶🌫️ now everything is working as intended. Thank you very much for your help! One small question, how can I change the seed?
@plastikjava to change the seed, update the purple Seed generator node within each sequence
@tremolo28 hey, two more questions, if I may, first, can I use the powerlora loader for the 4 sequences and just don't connect the "clip" in- and output, and second, do you have an idea why the "it" of the 4 sequences ist so different, as an example the first seq has 43s, the second 20, the third 132 and the forth 72?
@plastikjava Hi, never tried powerloader, but you can just replace a lora loader node and see if it works. I dont get your second question tho, what do you mean with "it" and those values?
@tremolo28 I meant iterations per second (I think it means). Basically how long it takes per sequence to finish. It's wildly different from 4 minutes to 12 (in one workflow of 4 sequences)
@plastikjava got it. For me it takes for 480p clip around 20 seconds per iteration/step with 16gb vram and 64gb ram. The values are stabil. Maybe with different vram/ram setup, comfyui needs to juggle more data between ram and vram, but thats just an assumption
@tremolo28 yeah maybe, but some of the time the generation speed for every sequence is nearly identical, so I don't know.
But thanks for all your help 🙏
@tremolo28 hey, thanks again for this workflow and all your help! I have another question: how do you get the excellent character cosistency in your uploaded videos? in my videos, by the 4th sequence, the face of the person has often times shifted and is not even close to the face of the 1st sequence... the cm ref image global is true (i guess it means color match?) any tips on how to maintain the face consitency? Thanks
@plastikjava Hi, face consistency and provided the face is always in frame throughtout the sequences, depends a bit on the Loras used, some Loras alter faces, as well the different LightX versions might have an impact. If a face gets out of frame in i.e. sequence 1 and returns into frame in sequence 2, there is no consistency, as the context does not carry over. If a face gets in and out of frame within same sequence, the context is still there. Yes, CM means color match.
@tremolo28 ok thanks, sometimes it is better, but often times its not so consistent. Is it somehow possible, that you can in every sequence refer to the start image, as well as the last frame of the previous sequence, so that wan has "more information" about the character? :)
@plastikjava Wan I2V can only handle 1 input image, but I think Wan Vace can handle first frame, last frame, maybe this works better regarding consistency, but I never used that.
Hey thanks for the workflow it looks good. Just one question: does it work with quantized models or need the full models?
Hi, it is setup to load GGUF models with a Unet Loader node, but you can simply replace it with a checkpoint loader node to load i.e. an fp8 model.