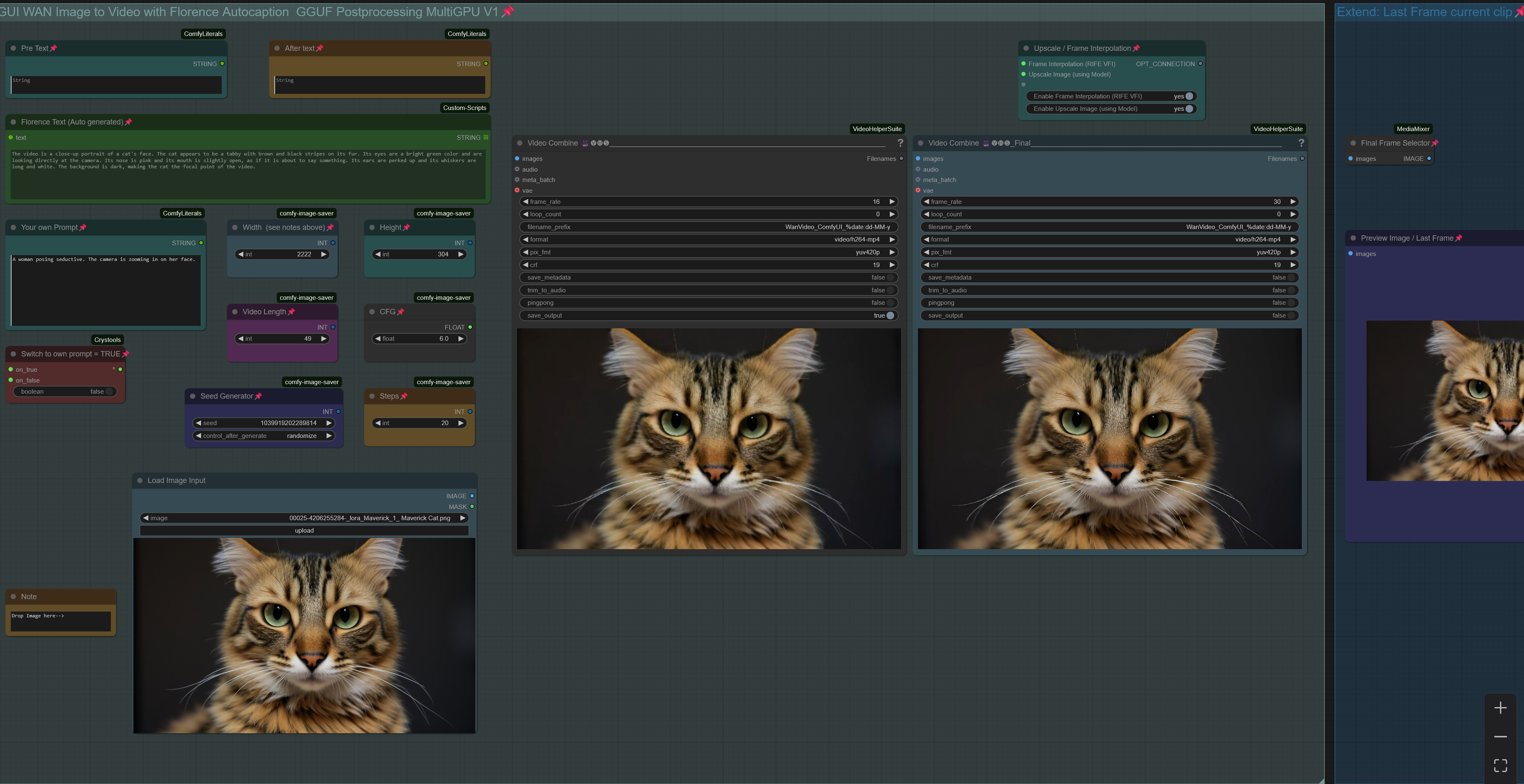
Workflow: Image -> Autocaption (Prompt) -> WAN I2V with Upscale and Frame Interpolation and Video Extension
Creates Video Clips with up to 480p resoltion (720p with corresponding model)
There is a Florence Caption Version and a LTX Prompt Enhancer (LTXPE) version. LTXPE is more heavy on VRAM
LTX Prompt Enhancer (LTXPE) might have issues with latest Comfy and Lightricks update
MultiClip: Wan 2.1. I2V Version supporting Fusion X Lora to create clips with 8 steps and extend up to 3 times, see examples posted with 15-20sec of length.
Workflow will create a clip on Input Image and extends it with up to 3 clips/sequences. It uses a colormatch feature to ensure consistency in color and light in most cases. See the notes in worflow with full details.
There is a normal version which allows to use own prompts and a version using LTXPE for autoprompting. Normal version works well for specific or NSFW clips with Loras and the LTXPE is made to just drop an image, set width/height and hit run. The clips are combined to one full video at the end.
update 16th of July 2025: A new Lora "LightX2v"has been released as an alternative to Fusion X Lora. To use, switch Lora in black "Lora Loader" node. It can create great motion with only 4-6 steps. : https://huggingface.co/lightx2v/Wan2.1-I2V-14B-480P-StepDistill-CfgDistill-Lightx2v/tree/main/loras
More info/tips & help: https://civarchive.com/models/1309065/wan-21-image-to-video-with-caption-and-postprocessing?dialog=commentThread&commentId=869306
V3.1: Wan 2.1. I2V Version supporting Fusion X Lora for fast processing
Fusion X Lora: process the video with just 8 Steps (or lower, see notes in workflow). It does not have the issues like the CausVid Lora from V3.0 and does not require a color match correction.
Fusion X Lora can be downloaded here: https://civarchive.com/models/1678575?modelVersionId=1900322 (i2V)
V3.0: Wan 2.1. I2V Version supporting Optimal Steps Scheduler (OSS) and CausVid Lora
OSS is a newer comfy core node to allow lower no. of steps with a boost in quality. Instead of using 50+ steps you can receive same result with like 24 steps. https://github.com/bebebe666/OptimalSteps
CausVid uses a Lora to process the video with just 8-10 steps, it is fast at a lower quality. It contains a Color Match option in postprocessing to cope with the increased saturation, the lora is introducing. Lora can be downloaded here: https://huggingface.co/Kijai/WanVideo_comfy/tree/main
(Wan21_CausVid_14B_T2V_lora_rank32.safetensors)
Both have a version with FLorence or LTX Prompt Enhancer (LTXPE) for Caption, can use Loras and have Teacache included.
V2.5: Wan 2.1. Image to Video with Lora Support and Skip Layer Guidance (improves motion)
There are 2 version, Standard with Teacache, Florence caption, upscale, frame interp. etc. plus a version with LTX Prompt Enhancer as an additional captioning tool (see notes for more info, requires custom nodes: https://github.com/Lightricks/ComfyUI-LTXVideo).
For Lora use, recommend to switch to own prompt with Lora trigger phrase, complex prompts might confuse some Loras.
V2.0: Wan 2.1. Image to Video with Teacache support for GGUF model, speeds up generation by 30-40%
It will render the first steps with normal speed, remaining steps with higher speed. There is a minor impact on quality with more complex motion. You can bypass the Teacache node with Strg-B
Example clips with workflow in Metadata: https://civarchive.com/posts/13777557
Info and help with Teacache: https://civarchive.com/models/1309065/wan-21-image-to-video-with-caption-and-postprocessing?dialog=commentThread&commentId=724665
V1.0: WAN 2.1. Image to Video with Florence caption or own prompt plus upscale, frame interpolation and clip extend.
Workflow is setup to use a GGUF model.
When generating a Clip you can chose to apply upscaling and/or frame interpolation. Upscale factor depends on upscale model used (2x or 4x, see "load upscale model" node). Frame Interpolation is set to increase frame rate from 16fps (model standard) to 32fps. Result will be shown in "Video Combine Final" node on the right, while the left node shows the unprocessed clip.
Recommend to "Toggle Link visibility" to hide the cables.
Models can be downloaded here:
Wan 2.1. I2V (480p): https://huggingface.co/city96/Wan2.1-I2V-14B-480P-gguf/tree/main
Clip (fp8): https://huggingface.co/Comfy-Org/Wan_2.1_ComfyUI_repackaged/tree/main/split_files/text_encoders
Clip Vision: https://huggingface.co/Comfy-Org/Wan_2.1_ComfyUI_repackaged/tree/main/split_files/clip_vision
VAE: https://huggingface.co/Comfy-Org/Wan_2.1_ComfyUI_repackaged/tree/main/split_files/vae
Wan 2.1. I2V (720p): https://huggingface.co/city96/Wan2.1-I2V-14B-720P-gguf/tree/main
Wan2.1. Text to Video (works): https://huggingface.co/city96/Wan2.1-T2V-14B-gguf/tree/main
location to save those files within your Comfyui folder:
Wan GGUF Model -> models/unet
Textencoder -> models/clip
Clipvision -> models/clip_vision
Vae -> models/vae
Tips:
lower framerate in "Video combine Final" node from 30 to 24 to have a slow motion effect
You can use the Text to Video GGUF Model, it will work as well.
If video output shows strange artifacts on the very right side of a frame, try changing the parameter "divisible_by" in node "Define Width and Height" from 8 to 16, this might better latch on to the standard Wan resolution and avoid the artifacts.
see this thread if you face issues with LTX Prompt Enhancer: https://civarchive.com/models/1823416?dialog=commentThread&commentId=955337
Last Frame: If you face issues finding the pack for that node: https://github.com/DoctorDiffusion/ComfyUI-MediaMixer
Full Video with Audio example:
Description
WAN 2.2. TI2V 5b GGUF Model support
FAQ
Comments (39)
for NSFW do i need the original photo to contain nudity? If i prompt a photo for NSFW it just ignores and does something else non NSFW.
am i missing anything?
Well, in general I2V is best for keeping the original content but just animating it. i.e., it's not great, nor really meant for, changing a lot of the base content. Recommend you use Flux Fill to change the source image to your NSFW liking then do I2V.
If LTX Prompt Encancer from experimental tab is causing issues (Error: "Expected all tensors..."), see below thread for solution, might occur with <16gb vram:
https://civitai.com/models/995093?modelVersionId=1511863&dialog=commentThread&commentId=727932
more infos: https://civitai.com/models/995093?modelVersionId=1511863&commentId=722660&dialog=commentThread
Sometimes result like in slow motion. How can i fix this or is it normal behaviour?
P.S. Hope to see your version of TextToVideo
agree, sometimes the output looks like slomo. Did not try it, but assume the following could help: add text to negative prompt (i.e. "slow motion") or increase framerate in Final Video combine node from 30 to maybe 40.
Text to Video is next on my list :)
turns out, the workflow works as well as Text to Video by just using the T2V GGUF model: https://huggingface.co/city96/Wan2.1-T2V-14B-gguf/tree/main
@tremolo28 Ha! So what should i do? Just disable image input and use personal prompt?
@GrandpaFrost just load the t2v video model and use own prompt or insert an image and let florence do the job.
@tremolo28 Hmmm i have loaded, "wan2.1-t2v-14b-Q5_K_M.gguf"
and getting
"Unexpected architecture type in GGUF file, expected one of flux, sd1, sdxl, t5encoder but got 'pig'"
For example i use "wan2.1-i2v-14b-480p-Q4_K_M.gguf" for i2v
So which one i need to download?
@GrandpaFrost yes, this model should work: "wan2.1-t2v-14b-Q5_K_M.gguf", I used Q4, but shouldnt matter. Anyway, you might need to have an input image in the workflow, even if you use an own prompt.
@tremolo28 with wan2.1-t2v-14b-Q4_K_M.gguf it worked.
Im trying to add your Workflow via "resources" button but recently it stops to show there. However in some post i was able tu put it there. Did you encounter this and maybe have a solution?
I load/save workflows just from the default directory
Praying WAN comes to Stable. Comfy seems to require a copy of my checkpoints and LoRAs and I can't keep doubling 6.4GB.
Modify the "extra_model_paths.yaml" file located into ComfyUI folder and point the respective models and loras path location to your Stable Diffusion models/loras folder. I also pointed the VAE, ControlNet models and such this way
I have my own setup that works without any problems. I tried yours and like other extended setups it says - mat1 and mat2 shapes cannot be multiplied (154x768 and 4096x5120). Can someone please advise me how to solve this problem? Thank you very much
Sorry, my fault, I don't use scaled CLIP model. But it help me more understanding system. Thank you very much for your work.
Today i have an error:
DownloadAndLoadFlorence2Model
Unrecognized configuration class <class 'transformers_modules.Florence-2-large.configuration_florence2.Florence2LanguageConfig'> for this kind of AutoModel: AutoModelForCausalLM. Model type should be one of AriaTextConfig, BambaConfig, BartConfig, BertConfig, BertGenerationConfig, BigBirdConfig, BigBirdPegasusConfig, BioGptConfig, BlenderbotConfig, BlenderbotSmallConfig, BloomConfig, CamembertConfig, LlamaConfig, CodeGenConfig, CohereConfig, Cohere2Config, CpmAntConfig, CTRLConfig, Data2VecTextConfig, DbrxConfig, DiffLlamaConfig, ElectraConfig, Emu3Config, ErnieConfig, FalconConfig, FalconMambaConfig, FuyuConfig, GemmaConfig, Gemma2Config, Gemma3Config, Gemma3TextConfig, GitConfig, GlmConfig, GotOcr2Config, GPT2Config, GPT2Config, GPTBigCodeConfig, GPTNeoConfig, GPTNeoXConfig, GPTNeoXJapaneseConfig, GPTJConfig, GraniteConfig, GraniteMoeConfig, GraniteMoeSharedConfig, HeliumConfig, JambaConfig, JetMoeConfig, LlamaConfig, MambaConfig, Mamba2Config, MarianConfig, MBartConfig, MegaConfig, MegatronBertConfig, MistralConfig, MixtralConfig, MllamaConfig, MoshiConfig, MptConfig, MusicgenConfig, MusicgenMelodyConfig, MvpConfig, NemotronConfig, OlmoConfig, Olmo2Config, OlmoeConfig, OpenLlamaConfig, OpenAIGPTConfig, OPTConfig, PegasusConfig, PersimmonConfig, PhiConfig, Phi3Config, PhimoeConfig, PLBartConfig, ProphetNetConfig, QDQBertConfig, Qwen2Config, Qwen2MoeConfig, RecurrentGemmaConfig, ReformerConfig, RemBertConfig, RobertaConfig, RobertaPreLayerNormConfig, RoCBertConfig, RoFormerConfig, RwkvConfig, Speech2Text2Config, StableLmConfig, Starcoder2Config, TransfoXLConfig, TrOCRConfig, WhisperConfig, XGLMConfig, XLMConfig, XLMProphetNetConfig, XLMRobertaConfig, XLMRobertaXLConfig, XLNetConfig, XmodConfig, ZambaConfig, Zamba2Config.
Rlated post:
Cool, another update breaking custom nodes…. Anyway according to the linked thread, a fix seems to be in progress.
any fix for this yet??
@CaulShivers Apperently not i just turn noff nodes to bypass them. There is other problem. after recent updates video Generations taking longer again. Manager showing that my GPU all used but temp is not rising up as much as it was before.
@tremolo28 Temporary FIX
https://github.com/kijai/ComfyUI-Florence2/issues/135
I was able to get it working using the steps to replace "AutoModelForCausalLM" with "AutoModelForSeq2SeqLM" as mentioned in the below comment.
I also tried to downgraded transformers (python -m pip install --upgrade transformers==4.49.0) as they suggest but I don't believe that actually did anything for me (I think it failed to downgrade actually).
https://github.com/kijai/ComfyUI-Florence2/issues/134#issuecomment-2745372425
@Quackquack I use StabilityMatrix, so i used CMDline from "...\StabilityMatrix\Packages\ComfyUI\venv\Scripts" folder. it worked for me. Thnx for sharing man.
They fix it.
I love your workflows. I've been following your posts since the LTX models. Your workflows are always working, even though I only have 12GB of video memory.)))
thanks, mate
finally made my first Wan music video, It is me and the lads.
Anyone can resolve it? Missing Node Types: WanImageToVideo, i update comyfui version,but it already can't solved
WanImageToVideo is a comfy core node.. You might be on an outdated comfy version.
Current version (March 27th):
ComfyUI: v0.3.27-6-g3661c833
(2025-03-26)
Manager: V3.31.8
@tremolo28 i have solved my problem,thanks a lot!
@zczcg how did you resove the problem - my manager can not find the missing nodes
@cbm27 You must update your comfyui,\ComfyUI_windows_portable\update\update_comfyui.bat here
It is very good. It would be great to add Loras and Seageattention
Great workflow, I also would like to know where/how to add loras?
might release an update this weekend for Lora support.
For now you could add a "LoraLoaderModelOnly" node and place it after unet loader and add the lora trigger word to Pre- or After text node. Just tried that with the "squish" Wan lora and it worked.
Awesome Thank you! I tried something similar but it wasn't working. I'll give it a go. Do you think multiple loras would work?
@3rdny467 think it would work to daisy chain the Lora loaders, but might be an overkill to use 2+ Video Loras.