




Please see our Quickstart Guide to Stable Diffusion 3.5 for all the latest info!
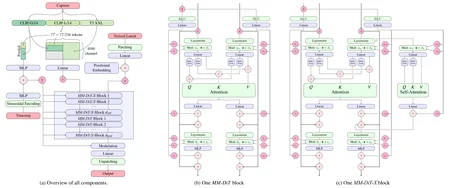
Stable Diffusion 3.5 Medium is a Multimodal Diffusion Transformer with improvements (MMDiT-x) text-to-image model that features improved performance in image quality, typography, complex prompt understanding, and resource-efficiency.
Please note: This model is released under the Stability Community License. Visit Stability AI to learn or contact us for commercial licensing details.
Model Description
Developed by: Stability AI
Model type: MMDiT-X text-to-image generative model
Model Description: This model generates images based on text prompts. It is a Multimodal Diffusion Transformer (https://arxiv.org/abs/2403.03206) with improvements that use three fixed, pretrained text encoders, with QK-normalization to improve training stability, and dual attention blocks in the first 12 transformer layers.
License
Community License: Free for research, non-commercial, and commercial use for organizations or individuals with less than $1M in total annual revenue. More details can be found in the Community License Agreement. Read more at https://stability.ai/license.
For individuals and organizations with annual revenue above $1M: please contact us to get an Enterprise License.
Implementation Details
MMDiT-X: Introduces self-attention modules in the first 13 layers of the transformer, enhancing multi-resolution generation and overall image coherence.
QK Normalization: Implements the QK normalization technique to improve training Stability.
Mixed-Resolution Training:
Progressive training stages: 256 → 512 → 768 → 1024 → 1440 resolution
The final stage included mixed-scale image training to boost multi-resolution generation performance
Extended positional embedding space to 384x384 (latent) at lower resolution stages
Employed random crop augmentation on positional embeddings to enhance transformer layer robustness across the entire range of mixed resolutions and aspect ratios. For example, given a 64x64 latent image, we add a randomly cropped 64x64 embedding from the 192x192 embedding space during training as the input to the x stream.
These enhancements collectively contribute to the model's improved performance in multi-resolution image generation, coherence, and adaptability across various text-to-image tasks.
Text Encoders:
CLIPs: OpenCLIP-ViT/G, CLIP-ViT/L, context length 77 tokens
T5: T5-xxl, context length 77/256 tokens at different stages of training
Training Data and Strategy:
This model was trained on a wide variety of data, including synthetic data and filtered publicly available data.
For more technical details of the original MMDiT architecture, please refer to the Research paper.
Usage & Limitations
While this model can handle long prompts, you may observe artifacts on the edge of generations when T5 tokens go over 256. Pay attention to the token limits when using this model in your workflow, and shortern prompts if artifacts becomes too obvious.
The medium model has a different training data distribution than the large model, so it may not respond to the same prompt similarly.
We recommended to sample with Skip Layer Guidance for better struture and anatomy coherency.
Description
FAQ
Comments (21)
Why the file has the same name as SD 3.5 Large? Would be more convenient if models followed some naming and version conventions TBH.
Who tested it ? What are the results of what speed ? Write a comparison
This is great IMO. Not noticeably less performant hardware-wise than the original SD3 Medium, and also it supports up to 1440x1440 resolution right out of the box!
Workflow doesn't really work out of the box, given the filenames. Why not put out a workflow that uses the actual filenames you link too? Wouldn't that make sense?
can someone help me? When I want to load the SD 3.5 M with the models and workflow, an error occurs clips are in the clip loader (Error occurred when executing CheckpointLoaderSimple: Error(s) in loading state_dict for OpenAISignatureMMDITWrapper:)
LG Dominik goyke
Anyone got a guide for using 3.5 Medium on Forge? There was an update last night that gave compatibility I believe.
Let the training begin! finally unmolested medium! a model most people can afford to fine tune.
What are the VRAM requirements?
Initial impression out of the box is just meh. The good news is that it is compact and superfast on a 4090. Results are not as great out of the box IMO as FLUX. However, as a lump of clay to be trained; exciting amount of potential here.
+Loads Fast.
+Generates fast (27second for 25steps).
+Quality is good.
+Can't wait for community fine tune.
+Vram friendly (6.6GB was used for me on a 3060ti).
+Can do text even tho i used t5-v1_1-xxl-encoder-Q5_K_M.gguf, which can get better if you use t5xxl_fp8_e4m3fn or better.
~if you are using comfyui, they say SLG implementation helps with hands etc...
Medium works better for me than the Large model. It took me 15 tries just to write 'SD 3.5 Medium.' It’s still not quite on par with Flux, but otherwise, it's fine.
It'd be great to get this in the generator. Preferably with hi-res-fix!
What I noticed in my attempts today is the issue with extra fingers – that definitely needs improvement. Also, the text generation in some images has worsened the quality. Even when using negative prompts or adding skipLayerGuidanceSD3, the results aren’t quite as good. Lots of work ahead for you.
FYI, using the ModelSamplingSD3 + Skip Layer Guidance nodes with the same settings used by SAI in one of their official example workflows helps immensely with anatomy (and like various other things, including text in some cases).
I'd be interested in hearing if anyone is planning on or already working on a finetune of SD35M. I'm figuring out LoRA and DoRA parameters for my own datasets (that I'm eager to share with y'all), but SD35M has a lot of anatomy anomalies, it would be great if the community could pull a SD15 or SDXL and fix 'em :)
Somebody want to explain why the Pruned model was uploaded as the main model?
i made this for you guys: SD3.5M-Booster | enhancing & fixing - v1.0 | Stable Diffusion LoRA | Civitai
I hope you are as happy with it as I am ;)
I'm having trouble with the clips for the workflow if someone can help me. Where are they and why can't i find the safetensors?
Tip: Euler Ancestral actually does work fine with SD 3.5 Medium (using the Normal or Beta schedulers) and gives great results for photographic stuff at around 7.0 CFG, in comparison to Euler SGM Uniform and whatnot.
dead
Details
Files
stableDiffusion35_medium.safetensors
Mirrors
stableDiffusion35_medium.safetensors
stableDiffusion35_medium.safetensors
sd3.5_medium.safetensors
sd3.5_medium.safetensors
sd3.5_medium.safetensors
sd3.5_medium.safetensors
sd3.5_medium.safetensors
sd3.5_medium.safetensors
sd3.5_medium.safetensors
sd35m.safetensors
sd3.5_medium.safetensors
sd3.5_medium.safetensors
sd3.5_medium.safetensors
sd3.5_medium.safetensors
sd3.5_medium.safetensors
sd3.5_medium.safetensors
sd3.5_medium.safetensors
sd3.5_medium.safetensors
sd3.5_medium.safetensors
sd3.5_medium.safetensors
sd3.5_medium.safetensors
sd3.5_medium.safetensors
sd3.5_medium.safetensors
Available On (1 platform)
Same model published on other platforms. May have additional downloads or version variants.