



















Model Introduction
This image generation model, based on Laxhar/noobai-XL_v1.0, leverages full Danbooru and e621 datasets with native tags and natural language captioning.
Implemented as a v-prediction model (distinct from eps-prediction), it requires specific parameter configurations - detailed in following sections.
Special thanks to my teammate euge for the coding work, and we're grateful for the technical support from many helpful community members.
⚠️ IMPORTANT NOTICE ⚠️
THIS MODEL WORKS DIFFERENT FROM EPS MODELS!
PLEASE READ THE GUIDE CAREFULLY!
Model Details
Developed by: Laxhar Lab
Model Type: Diffusion-based text-to-image generative model
Fine-tuned from: Laxhar/noobai-XL_v1.0
Sponsored by from:
Collaborative testing:
How to Use the Model.
Guidebook for NoobAI XL:
ENG:
https://civarchive.com/articles/8962
CHS:
https://fcnk27d6mpa5.feishu.cn/wiki/S8Z4wy7fSiePNRksiBXcyrUenOh
Recommended LoRa List for NoobAI XL:
https://fcnk27d6mpa5.feishu.cn/wiki/IBVGwvVGViazLYkMgVEcvbklnge
Method I: reForge
(If you haven't installed reForge) Install reForge by following the instructions in the repository;
Launch WebUI and use the model as usual!
Method II: ComfyUI
SAMLPLE with NODES
Method III: WebUI
Note that dev branch is not stable and may contain bugs.
1. (If you haven't installed WebUI) Install WebUI by following the instructions in the repository. For simp
2.Switch to dev branch:
git switch dev
3. Pull latest updates:
git pull
4. Launch WebUI and use the model as usual!
Method IV: Diffusers
import torch
from diffusers import StableDiffusionXLPipeline
from diffusers import EulerDiscreteScheduler
ckpt_path = "/path/to/model.safetensors"
pipe = StableDiffusionXLPipeline.from_single_file(
ckpt_path,
use_safetensors=True,
torch_dtype=torch.float16,
)
scheduler_args = {"prediction_type": "v_prediction", "rescale_betas_zero_snr": True}
pipe.scheduler = EulerDiscreteScheduler.from_config(pipe.scheduler.config, **scheduler_args)
pipe.enable_xformers_memory_efficient_attention()
pipe = pipe.to("cuda")
prompt = """masterpiece, best quality,artist:john_kafka,artist:nixeu,artist:quasarcake, chromatic aberration, film grain, horror \(theme\), limited palette, x-shaped pupils, high contrast, color contrast, cold colors, arlecchino \(genshin impact\), black theme, gritty, graphite \(medium\)"""
negative_prompt = "nsfw, worst quality, old, early, low quality, lowres, signature, username, logo, bad hands, mutated hands, mammal, anthro, furry, ambiguous form, feral, semi-anthro"
image = pipe(
prompt=prompt,
negative_prompt=negative_prompt,
width=832,
height=1216,
num_inference_steps=28,
guidance_scale=5,
generator=torch.Generator().manual_seed(42),
).images[0]
image.save("output.png")
Note: Please make sure Git is installed and environment is properly configured on your machine.
Recommended Settings
Parameters
CFG: 4 ~ 5
Steps: 28 ~ 35
Sampling Method: Euler (⚠️ Other samplers will not work properly)
Resolution: Total area around 1024x1024. Best to choose from: 768x1344, 832x1216, 896x1152, 1024x1024, 1152x896, 1216x832, 1344x768
Prompts
Prompt Prefix:
masterpiece, best quality, newest, absurdres, highres, safe,
Negative Prompt:
nsfw, worst quality, old, early, low quality, lowres, signature, username, logo, bad hands, mutated hands, mammal, anthro, furry, ambiguous form, feral, semi-anthro
Usage Guidelines
Caption
<1girl/1boy/1other/...>, <character>, <series>, <artists>, <special tags>, <general tags>, <other tags>
Quality Tags
For quality tags, we evaluated image popularity through the following process:
Data normalization based on various sources and ratings.
Application of time-based decay coefficients according to date recency.
Ranking of images within the entire dataset based on this processing.
Our ultimate goal is to ensure that quality tags effectively track user preferences in recent years.
Percentile RangeQuality Tags> 95thmasterpiece> 85th, <= 95thbest quality> 60th, <= 85thgood quality> 30th, <= 60thnormal quality<= 30thworst quality
Aesthetic Tags
TagDescriptionvery awaTop 5% of images in terms of aesthetic score by waifu-scorerworst aestheticAll the bottom 5% of images in terms of aesthetic score by waifu-scorer and aesthetic-shadow-v2......
Date Tags
There are two types of date tags: year tags and period tags. For year tags, use year xxxx format, i.e., year 2021. For period tags, please refer to the following table:
Year RangePeriod tag2005-2010old2011-2014early2014-2017mid2018-2020recent2021-2024newest
Dataset
The latest Danbooru images up to the training date (approximately before 2024-10-23)
E621 images e621-2024-webp-4Mpixel dataset on Hugging Face
Communication
QQ Groups:
427280545
677964513
852429527
914818692
635772191
870086562
Discord: Laxhar Dream Lab SDXL NOOB
How to train a LoRA on v-pred SDXL model
A tutorial is intended for LoRA trainers based on sd-scripts.
article link: https://civarchive.com/articles/8723
Utility Tool
Laxhar Lab is training a dedicated ControlNet model for NoobXL, and the models are being released progressively. So far, the normal, depth, and canny have been released.
Model link: https://civarchive.com/models/929685
Model License
This model's license inherits from https://huggingface.co/OnomaAIResearch/Illustrious-xl-early-release-v0 fair-ai-public-license-1.0-sd and adds the following terms. Any use of this model and its variants is bound by this license.
I. Usage Restrictions
Prohibited use for harmful, malicious, or illegal activities, including but not limited to harassment, threats, and spreading misinformation.
Prohibited generation of unethical or offensive content.
Prohibited violation of laws and regulations in the user's jurisdiction.
II. Commercial Prohibition
We prohibit any form of commercialization, including but not limited to monetization or commercial use of the model, derivative models, or model-generated products.
III. Open Source Community
To foster a thriving open-source community,users MUST comply with the following requirements:
Open source derivative models, merged models, LoRAs, and products based on the above models.
Share work details such as synthesis formulas, prompts, and workflows.
Follow the fair-ai-public-license to ensure derivative works remain open source.
IV. Disclaimer
Generated models may produce unexpected or harmful outputs. Users must assume all risks and potential consequences of usage.
Participants and Contributors
Participants
L_A_X: Civitai | Liblib.art | Huggingface
li_li: Civitai | Huggingface
nebulae: Civitai | Huggingface
Chenkin: Civitai | Huggingface
Euge: Civitai | Huggingface | Github
Contributors
Narugo1992: Thanks to narugo1992 and the deepghs team for open-sourcing various training sets, image processing tools, and models.
Onommai: Thanks to OnommAI for open-sourcing a powerful base model.
V-Prediction: Thanks to the following individuals for their detailed instructions and experiments.
adsfssdf
madmanfourohfour
Community: aria1th261, neggles, sdtana, chewing, irldoggo, reoe, kblueleaf, Yidhar, ageless, 白玲可, Creeper, KaerMorh, 吟游诗人, SeASnAkE, zwh20081, Wenaka~喵, 稀里哗啦, 幸运二副, 昨日の約, 445, EBIX, Sopp, Y_X, Minthybasis, Rakosz, 孤辰NULL, 汤人烂, 沅月弯刀,David, 年糕特工队,
Description
A new version of traditional-para training that supports concepts around img count 150 (styles and chars), there have been 22 epoch of training on 12.7 million images so far.
This is still an intermediate version and can be run using the traditional A1111 Webui, meanwhile A1111 promises to support all versions of NoobAI XL (including the v-pred version) in the main branch these days
V-pred version and epsilon-pred version are still on the Laxhar Lab's to do schedule
This release is already a mid-late version that supports the concept of actual count numbers over 100, and even some characters with only 50 count! If there are characters and styles you like that meet the criteria but are not supported, it's probably because the actual data has not been collected, and Laxhar Lab welcomes your feedback to make the model better!ミ(・・)ミ
We hope you like this 75% version, and we plan to release 100% of the EPS-Ver next month, and at the same time begin development work on the full version of the V-pred release.
FAQ
Comments (169)
我喜欢你
好多新角色 ,冲冲冲
我喜欢你
太强了!!!
curious if you have plans to create it using SD 3.5.?
full e621 dataset let's freakin go
Can you update this for the Civitai generator?
Is there a database or a list of the artists with whom this checkpoint has been trained? @L_A_X
和 nai3 差不多,建议看这个300画风法典:单画师类
I have a question. There are cases where Danbooru tags and e621 tags are different but have the same meaning, for example, ‘1girl’ and ‘female’, or ‘furry female’ and ‘female anthro and kemono’. During training, were both tags trained together, or were tags with the same meaning consolidated into Danbooru format?
神中神!
他妈的强大
An awesome model, with data of some Nikke characters (would be good if u can add more), hope you can add characters of metal gears or others videogames characters as well
Btw, I noticed that used the word "sensitive",in your prompts, does that token works like the ones with pony like rating_Safe rating explicit etc?
他妈的吊
早知道 还是noobai
Love it :)
剛才測試了一下,0.5版在NSFW的表現上比新的0.75感覺好一點。不知道其他人覺得如何
画风串用起来可能没上一版稳定
keep making finetunes of illust, dethrone pony from the nr1 hentai model!
Feels like 0.75 degraded from 0.5 in some areas. Anatomy is generally slightly worse (limbs blending together/extra fingers and toes). Artists are a mixed bag, some improved, others look worse than in earlier epochs, but all feel more unstable. Hope these shortcomings are just a result of the TE training this time around and that we aren't seeing a "ponyfication" of the model by the e621 dataset.
for a certain character i like, i honestly cant tell if its undertrained or overbaked with how awful the quality is in every attempt at a gen, compared to even older models for sdxl and pony it falls behind pretty harshly.
I agree. Unfortunate.
For those who feel 0.75 is not as good as 0.5 try this merge version.
Sorry but I noticed that 0.75 is just worst than 0.5.
Something happened and it's wrong.
Unfortunately the quality seems to have gone way down with the 0.75 version...
drop the usage of e621 when training, it uglifies the model
They hated him because he told the truth.
0.5 had e6 in it too lmao, are you sure your prompting isn't just bad? Aesthetic finetuning can always be done once the model's training has finished and all the knowledge is there.
*Shit on the table.
"Why are you complaining bro. You can always clean your table later."
@Konan Literally just learn to prompt. Complaining about it giving you shit just because you can't use it is quite moronic. Every model is shit if you don't use it right (which you've clearly shown you don't do), this is no different. Furry haters are so delusional.
@Konan Skill issue
@upscaleanon537 Checking your profil I think you can teach me how to prompt plz.
@Ligmanese I know :(
@Konan Lol, going with the typical "ur profile" because you're too much of a brainlet.
Did it occur to you to check the upload date of the stuff on my profile? TWO YEARS AGO LOL.
You have brain damage and it shows.
Quality made a huge bump! Artists look more accurate too :D
Keep up the good work!
Have to question this. Every X/Y plot I've done compared with 0.5 has been worse.
In the case I tested, the style of version 0.75 is just further away from the base model of illustriousXL: Kohaku XL-Beta. So yes, 0.75 started to have its own default painting style. 0.5 just hasn't entered the style change yet, and some people may prefer 0.5. On the other hand, 0.75 obviously performs better in some rare concepts such as: guro, tragedy, suggestive composition, etc. At the same time, it also has some bad limbs, but the overall quality has surpassed the official nai i think. I'm very much looking forward to version 1.0. Let's go!good job!
Strongly implore the finetuners to drown out negative feedback here. The model to the trained eye is still moving in a better direction and I would hate to see the current trajectory disrupted. And no, this isn't coming from someone that only prompts one half of the dataset.
Judging by the pictures on your profile, you're not exactly gifted with a sense for aesthetics and should maybe sit this one out.
@scythesaint99 He is right though :)
@scythesaint99 Imagine judging someone for gens they made HALF A YEAR AGO LMAO
For all you know, they could be genning 10x better stuff by now.
Also you have 0 pictures on your profile, hypocrite.
@scythesaint99 Do you really think that is a gotcha, those are outputs from 1.5 models that were begrudgingly put up because the models needed preview images. AND dating back more than a year ago at this point. The 0.75 "degradation" is entirely a end user issue with how they are prompting the model. The model simply is anticipating longer more fleshed out prompts as the e621 side of the dataset generally has more verbose tagging compared to Danbooru. Thus the model's median prompt length has increased. Users should be building descriptive prompts to begin with. (keyword: control) With sufficiently detailed prompts, outputs between 0.5 and 0.75 are nearly identical. It's only low-effort short prompts that have degraded by any quantifiable degree. And that crowd of prompters aren't happy about it. They want to prompt less than a handful of tags and have the model autocomplete the rest of it without any further thought or input.
@zatochu people are extremely lazy and are incapable of reading a few manuals to see how to properly prompt. Most of these issues is dumb people who prompt without even using any artists. Of course it's shit when the prompts are basically "1girl, standing". It's gonna be shit regardless of model. It's just that this version is less finetuned for garbage prompts.
@zatochu Curious how all defenders of the current epoch have copious amounts of furry artwork on their profiles. Almost as if they are the only ones profiting from the inclusion of e621 data in the TE training.
@scythesaint99 And? The team behind NoobAI decided on their own to include the entirety of e621 in the model's training dataset. Why do you think that is?
@zatochu The inclusion of e621 obviously worked as long as the TE was frozen. For 0.75 the TE was trained and it resulted in degradation. Users are now rightfully voicing their concerns and you try to undermine that with blanket "skill issue" statements. Kinda reminds me of Lykon when SD3 launched.
If the new model spits out worse gens using the same prompts that were used on an older version of it, that's definitely not a good sign no matter how you look at it.
@scythesaint99 Source on them unfreezing the TE? Or it being frozen to begin with? I'd love a link. I fail to see any benefit of training the entirety of e621 with a frozen TE, what would it even be learning? What would be "working"? That's a lot of compute to be expending with no clear purpose.
@zatochu It was mentioned by euge on the artiwaifu discord. Either ask him directly or ask for a server invite and check old messages.
i think the model is an improvement, i havent seen any regressions beyond what i would consider normal seed to seed variance that you just correct for by tweaking here and there. my gigachad lora had a significant boost effect to contrast in many of my gens, which leads me to believe aesthetic issues if any are ripe for specific lora tuning with much less pain than in say pony
This version is probably better for inpainting but it's an absolute bullet to the brain for intricate artstyle mixes compared to 0.5
This model is definitely an improvement over the 0.5 version, the artist styles are improved, the criticisms I believe are coming from people who don't know how to use the model correctly with proper quality tags, keep it up!
It is entirely that. The only degradation to outputs occur with shorter low-effort prompts. When prompting with sufficiently long prompts, outputs between 0.5 and 0.75 are identical.
@zatochu If the new model spits out worse gens using the same prompts that were used on an older version of it, that's definitely not a good sign no matter how you look at it.
@poefgwjorh Can you explain why it's happening? Or is it just "they added data and content I don't care for and it must be at fault."
@zatochu It's been long known that you are not supposed to finetune an already aesthetically-aligned model because that just dilutes the effect of the said aesthetic alignment. In this case, most of e621 art looks like utter trash with cartoonish taste to it (read: pony) and it's definitely less appealing from the aesthetic perspective than most of the danbooru dataset, it definitely brings the aesthetic quality down (which is average of both datasets). The good-looking furry art exists, aruurara for example, but the overwhelming majority of art on e621 is pure SLOP, and this is a huge problem, don't pretend it doesn't exist.
@poefgwjorh Maybe you should get in contact the model authors directly and tell them how badly they messed up then. Maybe offer yourself up to help them work on it. Though being less snide, or maybe more snide. That still sounds like a prompting issue where users don't know how to meaningfully drive a model aesthetically in the right direction. This isn't Pony where you don't have artist tags.And there's plenty of boilerplate tags that are REAL tags that can be placed in the negative prompt. Opposed to the nonsense that is "text,watermark,bad anatomy, bad proportions, extra limbs, extra digit, extra legs, extra legs and arms, disfigured, missing arms, too many fingers, fused fingers, missing fingers, unclear eyes,watermark,username" where a large number of these tags don't even register because the NLP has been trained out of the TE and tags like "extra digit, extra legs, extra X" were never Booru or E621 tags to begin with and they will have less and less effect the further the TE goes away from interpreting natural language.
@zatochu You've been told multiple times that the same prompts should not looks worse on the updated version of a model. You are either deliberately trolling or just conveniently trying to bend the narrative. I assume the model authors aren't kids and can figure out what to do on their own.
@poefgwjorh If they aren't kids and they can figure things out for themselves, why are you spouting rhetoric that more or less expresses they made a huge mistake that should have been "common knowledge."
@zatochu There's no simple way to finetune an aligned model, or at least I'm not aware of it. I'm sure they realize what they are doing if they decided to base off of illustrious instead of something like cosxl.
Pretty excellent for a step up, though it seems to lack quality/have some mishaps when using DPM++ when compared to Euler A. Might be personal set up issues, but aside from the usual artifacts that might appear, the knowledge has improved to a decent liking.
Express myself that something seems off with 0.75 compared to 0.5.
Get jumped on by furry posters. 🤔
I tried the model personally elsewhere, and to be fair 0.5 is still better than 0.75, I assume that because of e621 tags that poisoned the model, I hope it will be reworked or fixed because i'd rather use 0.5 than the final version.
e621 :)
Come on bros, let's keep it civil! Instead of staying at each other's throat we should encourage the devs to improve the model!
Would this be better than ArtiWaifu?
The 0.75 looks worse than the 0.5, the artist's style I used has deteriorated a bit, especially the eyes.
I have seen many comments saying that the 0.75 model is worse than 0.5. But in my experience, this model is much better than 0.5. I noticed that this model knows styles and characters much better and the overall visual quality is much higher. It is worth noting that I use strong positive and negative prompts. I guess the original Illustrious was trained on the aesthetic dataset at the end, and because of that, Illustrious does not need the aesthetic prompts as much. Probably, NoobAI 0.75 lost the default aesthetic knowledge from Illustrious, and because of that, it now needs different prompts. But as I said, I did not notice any degradation in quality because I always use strong aesthetic prompts. Here they are
Psitive: masterpice, best quality, YOUR_PROMPT, by ARTIST_NAME
Negative: lowres, (worst quality, low quality, bad anatomy, bad hands:1.3), abstract, signature
CFG: 10
Steps: 30
Sampler: Euler
Please try these aesthetic prompts. I'm also very curious about what you get with them, so it would be great if you could tell about your results in the comments
Please post your example images
@Korewaai Okay, I'll do it a little later
yeah, idk what the other comments are talking about. my only guess is that they just happened to find styles that they liked the less accurate look of and are disappointed that they don't look the same any more. 0.75 is far better in my experience. as far as illustrious v0.1 goes, it was not trained on an aesthetic dataset.
which vae you are using?
@PM786 i either use the baked in vae or the one from madebyolin that fixed fp16 depending on which ui i'm running at the time since i have the madebyolin one set as default for SDXL in any non-comfy based ui's that i use
@nubby thank you & what do you recommend for A111?
Earlier I wrote that I didn't notice any degradation in the quality of the NoobAI-Epsilon075, but after longer testing I have to admit that this model has some anatomy issues in some cases. I decided to do a simple merge that fixes this problem. And from what I can tell, this merge came out pretty good. I created this merge for myself, but I decided to let you play with it, maybe you will like it too NoobaiCyberFix
P.S. I just noticed that version 1.0 is out. This version seems to have the same problems, so probably I'll make a second version of this merge soon
e621太丑了恶心
I like ver 0.75, I have noticed this model is better at doing backgrounds than ver 0.5, it still doesn't follow colors 100% but maybe my prompts are not as clean as I think they are.
I kinda wish the database of characters was a bit more updated, at least it has a good database for WuWa characters. But that is a bit out of control, official artstyles are still good looking, some did lose a bit of accuracy, but not a huge change.
After playing a bit with it, I like it, not a big improvement or change from ver 0.5, but its good that you guys leave different versions available, that way people can pick what they want, keep up the great work!
0.75 seems to break or deteriorate some styles that worked perfectly on 0.5, however it's still a solid improvement overall and many styles seem to actually be better.
With that said, rip to my favourite colorful cartoon / chibi artist, and rip to eye details.
Hopefully the final version will be the best of them all !
Don't wanna look too whiny but I agree with the others that 0.75 seem to have degraded a bit compared to 0.5.
0.75 is better than 0.5, it's the TE that is broken or has something weird. 0.75 UNET + 0.5 CLIP works better than 0.5 for me.
It's actually just necessary stage to get the model out of the local minima lol
Yes, I know; I suppose it's like v prediction. Even if the TE is unstable at this moment, the UNET is stable, so using a 0.5 TE with 0.75 UNET works better than using 0.5 directly.
This format is working really well for me with the 0.75 TE:
Positive: (masterpiece, best quality, good quality:1.1), absurdres, 1girl...
Negative: (worst quality, normal quality), censored, bad anatomy, jpeg artifacts, lowres, (artist name, speech bubble, logo, watermark, signature, patreon, web address:1.2), twitter username, patreon username, english text, speech bubble, bad hands, bad feet, bad proportions, bad perspective, bad leg, bad arm, bad neck, extra, fewer digits, extra digits, missing finger, scan artifacts, adversarial noise, artistic error, wardrobe error
Steps: 28, Sampler: Euler a, CFG scale: 7
I just want to know how to use different models' clip and unet. Or is this just a conceptual statement? I don't quite understand what the underlying technology is like.
@2022211688660 That depends on which UI you're using. It should be somewhat similar to using another VAE, but since the default clip is rarely changed, the option might be a bit more hidden.
can somebody help me to use this I've tried so many times and all results are garbage, and if somebody can explain me how to use the artist/art style option it will be amazing
Look at the image gallery posted below and copy the metadata to start with.
@LazyTrainer I have the same problem too.But it didn't work.Though I copy the data for those images that did not use any lora, it still couldn't draw the same.
@LazyTrainer i did it and the results are trash, it generates something that looks like it came from crayon lite
@lorenzofee04557 post an image that you've had a problem with including it's metadata then link it here. it's hard for us to guess what might be going wrong for you if we can't see what you're doing, or even see the problem
@nubby thanks for replying, i think that the problem was on Automatic 1111, i moved it to comfy ui and worked perfectly using the same generation data
@lorenzofee04557 I also encountered the same problem, do I have to switch from webui to comfyui or forge
@dou_ou i recommend you to do so, it was instant improvement without changing the parameters or the metadata between the UIs
great checkpoint.This is the best!
After using it for a bit here are my pros and cons coming from an Artiwaifu user.
NoobAI
Pros
- Multiple characters gen is A+
- Character accuracy is very good on well-known characters
Cons
- Very limited artist trained compared to Artiwaifu or mid-level artist data just isn't trained well enough?
- eyes are sometimes disfigured
- The default art style has a very messy dark lineart look that doesn't look polished imo
ye, i'm waiting for super duper merge of noobai vrep trained on illustrious 2.0 and artiwaifu 3.0. this will be the best model
@Kellenok yeah a merge of both would be best of both worlds because the stylization customization of artiwaifu is so good.
whatever others say, I still believe in your model, because there's no way others would know what you are aiming for better than you.
This is still an unfinished version, so please be a bit more patient, friends. It will be masterpiece I believe
It is a really well-crafted and excellent base model. The feedback suggesting that version 0.75 has undergone some stylistic degradation compared to version 0.5 seems to stem from the way version 0.75 draws certain styles, particularly characters with a mature appearance. When using the same artist tags and age-related tags like 'adult,' version 0.75 seems to depict the character's facial features slightly younger compared to version 0.5. Additionally, some of the oil painting-like feel also seems to have been toned down.
What is clear, however, is that version 0.75 shows better prompt comprehension—although version 0.5 was certainly good in this aspect as well—and the accuracy of hands and details seems to have improved when using the same artist tags. Furthermore, the model appears to offer better overall stability in its illustrations.
Of course, I haven't used version 0.75 extensively yet, so I'll need to experiment with it more to know for sure.
反馈,随着版本更新,agm阿戈魔的画风没了,或者说很淡了
最高のモデルをありがとうございます。
can i use pony lora
yes but they will not work
Major improvement over Illustrious-XL in concept understanding thanks to the e621 dataset. Now it can do the diapers and farting correctly.
If you don't mind, I'd like to see the latest v-pred version.
Amazing model wish it gets to the Civitai generator, I think its better than illustrious
I've noticed that there seems to be a decline in image aesthetic, especially color, as this model continues to be trained. It appeared to have leveled off with 0.5, but the issue continues to be pronounced in 0.75. I implore the team to take a step back and make sure everything is working as intended.
is it possible to have a vpred conversion of the .50 model as well?
Made some artists study list for myself. Just a few. Maybe someone will find it useful
Thank you for your work! This is aways appreciated, I'm glad you used something closer to a character, it helps to notice the difference better. I also noticed that Hatsune Miku is a great subject for this kind of examples. Either way, thanks you for sharing!
this is perfect. UR A LEGEND
I've spend so much time on Pony checkpoints that I forgot that normal SDXL ones could remember artists without LORA remining.
这些对比非常棒,让我注意到更多好的画师和画风
Somehow there was a downgrade from 0.5 to 0.75
In what regard? Some artists that didn't work before work now and some concepts seem to be better understood as well.
Things that weren't known are known now, and concepts that were built in are stronger. Adjust weights accordingly, your same stacks won't work as model progresses, that's why this isn't a "complete" model yet. once v1.0 is out you can start making tons of stacks you can consistently use.
They just made an announcement on the discord admitting that this version is degraded because of the TE training. Stick to 0.5 and hope that the issues get fixed for the 1.0 release.
@scythesaint99 Please provide the source.
@zeseren there is no such announcement, they are trolling. devs have not mentioned text encoder at all on discord.
@fizalpher ??? https://files.catbox.moe/hsgg5f.png
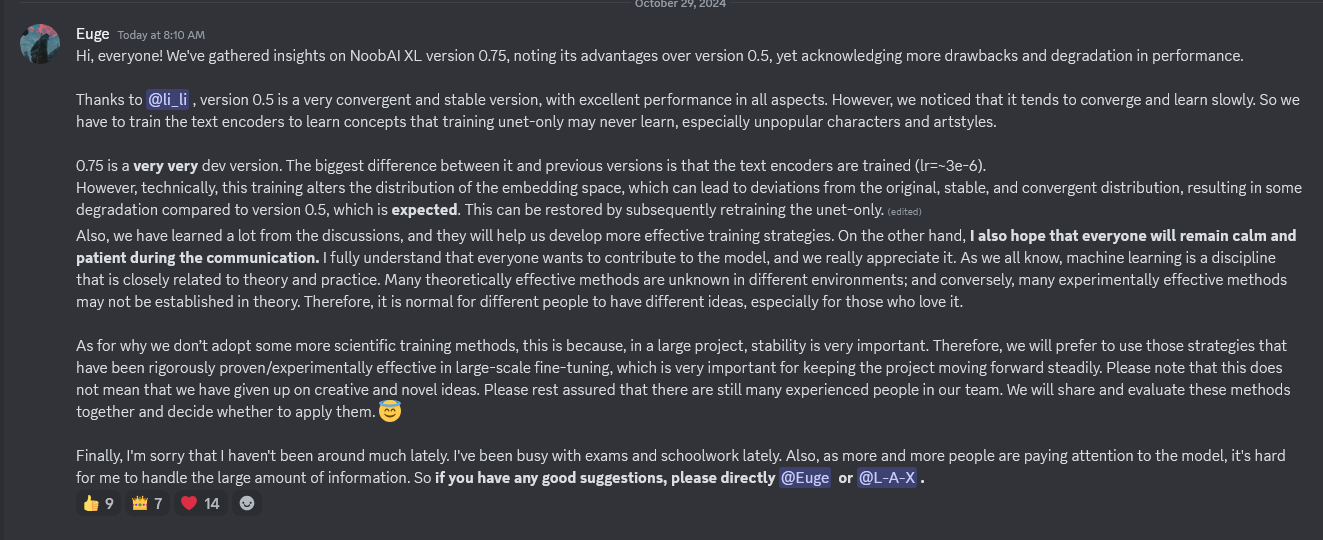{kind=link}
@scythesaint99 this is not the official discord, therefore could be referring to anything. Unless you have a discord link for this as well?
@fizalpher Euge is one of the creators and the announcement comes from his discord. you shouldn't claim something is trolling just because you don't know it..
@hasoo then that discord should be linked. the official nai-xl server is Laxhar, if the info isn't there there'd be no reason to believe the claims being made about the Laxhar product on another server unless verifiable.
@fizalpher You're talking BS with a very serious face. It's beautiful.
For some reason i get worse results with 0.75 than with 0.5 version: Worse colors, less accurate styles (for majority of artists that i like), worse anatomy, worse coherency. I've juggled the prompt a lot but it's still a downgrade for me.
Can you try this format? it's working for me.
(masterpiece, best quality, good quality:1.1), absurdres, YOUR PROMPT HERE
Negative:
worst quality,bad quality,bad hands,very displeasing,extra digit,fewer digits,jpeg artifacts,signature,username,reference,mutated,lineup,manga,comic,disembodied,futanari,yaoi,dickgirl,turnaround,2koma,4koma,monster,cropped,amputee,text,bad foreshortening,what,guro,logo,bad anatomy,bad perspective,bad proportions,artistic error,anatomical nonsense,amateur,out of frame
@bionagato 我打算明天试试你这种方法
After using 0.75, it grasps a lot of tags better then 0.5, especially e621 tags but it suffers when it comes to anatomy, characters are often in awkward poses or have their heads cropped. Overall I prefer 0.75 to 0.5 but I understand why people hate it. Here's hoping the full version turns out better and satisfies everyone.
Since people keep making posts about "0.75 bad": This is due to it being an intermediary model, the trainers did extra Text Encoder training between 0.5 and 0.75, but the Unet hasn't had time to catch up - This is the cause of the distortions. To my knowledge they've paused the TE again, and the next version should have the Unet caught up and resolve the issues.
Where was this ever confirmed? They never said it in Laxhar server... Someone posted a screenshot but not from any of the common anime AI discords I know about, so kinda doubt authenticity.
@fizalpher They're training the text encoder (I think it's still in progress). They want it to recognize characters with fewer than around 100 tags in Danbooru. If you look for a comment I made about 20 messages back, you'll find that he replied implying that the text encoder is training. They also discussed it with a Waifu Diffusion mod and others on Discord. I personally find that 0.75 works better than 0.5, but it's a bit more unstable for now.
Why I can not use controlnet with webui? There is some slightly difference but not too much, and doesn't fit the expectation at all.
The openpose doesn't work
@leegridmaster Depending on the checkpoint, you may need to change the ControlNet model for it to apply effectively.
@changpingjitian641 Thank you! The new controlNet Models are released, looks like the general model is deffective.
Please create version sd 3.5 as well. I believe it's possible with your capabilities. The medium model has been released, so please consider it.
Also made a few wildcards with artists.
The latest post ID is 7866491 / July 2024
P.S. Does anyone have newer artists list?
Hi, thank you <3 I think the link isn't working for me, idk why
And just when you thought SDXL had reached its natural limit... here comes this
:)
10/10
I don't know if this will reach the publisher but could you set this model to Illustrious? I can't use Illustrious models with it on the onsite generator since it's set to SDXL.
It looks like Shutumon (Zephyrmon) from Digimon isn't supported currently. There are about 100 images of her on Danbooru and about 40 on e621. Would it be possible to get her added to the training for a future version?
what vae do you use with it?
Will there be sd 3.5 large in the future?
以後會有SD 3.5 Large嗎?
Is work furry
Seems neat
good job
this model is wrongly tagged as SDXL 1.0. Should be tagged with Illustrious.
illustrious was not an option when this came out
@pumpkindolphin illustrious tag already came out as v 0.75 pred version came out. It's just wrongly tagged. OP can fix that easily.
I requested the same thing in the discord but I don't think they will do that
ill已死,noob当立
@Madafada1991 illustrious category is currently bugged, so i wouldnt change it for now.
What is the clip for this model?
clip last layer=-2 or keep it default?
clip skip doesn't work on XL architecture.
@Enigmata thank u!
The only thing I can't quite control is the drawing style.
you have a lot of drawing styles, i can tell you one that i like (artistningen_mame0.9),(artistsho_(sho_lwlw)0.9),(artistrhasta0.9),(artistwlop0.7),(artistke-ta0.6),(fkey0.5),(tianliang duohe fangdongye0.5),(hiten (hitenkei)0.6),
@carlosalextorres15238 Is there a page or section where all the styles are listed?
@Santiagosfx If you mean "drawing style" as in artist style, my way of doing this is going to danbooru.donmai.us , search for the artist i like (from twitter or pixiv), or click one of the picture listed, a new tab will open then i'd copy what's in the artist tag or the search box on the top left corner (ex: muku_(muku-coffee)) then paste it in the prompt box.
I do the same to any character, too.
Correct me if i'm wrong tho and if you learn any other methods later please share it too.
Details
Files
noobaiXLNAIXL_epsilonPred075.safetensors
Mirrors
noobaiXLNAIXL_epsilonPred075.safetensors
noobaiXLNAIXL_epsilonPred075.safetensors
noobaiXLNAIXL_epsilonPred075.safetensors
noobaiXLNAIXL_epsilonPred075.safetensors
noobaiXLNAIXL_epsilonPred075.safetensors
noobaiXLNAIXL_epsilonPred075.safetensors
noobaiXLNAIXL_epsilonPred075.safetensors
noobaiXLNAIXL_epsilonPred075.safetensors
noobaiXLNAIXL_epsilonPred075.safetensors
noobaiXLNAIXL_epsilonPred075.safetensors
waveXLNAI_EPS_0.75.safetensors
noobaiXLNAIXL_epsilonPred075.safetensors
NoobAI-XL-v0.75.safetensors
noobaiXLNAIXL_epsilonPred075.safetensors
noobaiXLNAIXL_epsilonPred075.safetensors
noobaiXLNAIXL_epsilonPred075.safetensors
noobaiXLNAIXL_epsilonPred075.safetensors
noobaiXLNAIXL_epsilonPred075.safetensors
noobaiXLNAIXL_epsilonPred075.safetensors
noobaiXLNAIXL_epsilonPred075.safetensors
Available On (3 platforms)
Same model published on other platforms. May have additional downloads or version variants.