



















bigASP 🐍 v2.0
A photorealistic SDXL finetuned from base SDXL on over 6 MILLION high quality photos for 40 million training samples. Every photo was captioned using JoyCaption and tagged using JoyTag. This imbues bigASP 🐍 with the ability to understand a wide range of prompts and concepts, from short and simple to long and detailed, while generating high quality photographic results.
This is now the second version of bigASP 🐍. I'm excited to see how the community uses this model and to learn its strengths and weaknesses. Please share your gens and feedback!
Features
Both Natural Language and Tag based prompting: Version 2 now understands not only booru-style tags, but also natural language prompts, or any combination of the two!
SFW and NSFW: This version of bigASP 🐍 includes 2M SFW images and 4M NSFW images. Dress to impress? Or undress to impress? You decide.
Diversity: bigASP 🐍 is trained on an intentionally diverse dataset, so that it can handle generating all the colors of our beautiful species, in all shapes and sizes. Goodbye same-face!
Aspect ratio bucketing: Widescreen, square, portrait, bigASP 🐍 is ready to take it all.
High quality training data: Most of the training data consists of high quality, professional grade photos with resolutions well beyond SDXL's native resolution, all downloaded in their original quality with no additional compression. bigASP 🐍 won't miss a single pixel.
Large prompt support: Trained with support for up to 225 tokens in the prompt. It is BIG asp, after all.
(Optional) Aesthetic/quality score: Like version 1, this model understands quality scores to help improve generations, e.g. add
score_7_up, to the start of your prompt to guide the quality of generations. More details below.
What's New (Version 2)
Added natural language prompting, greatly expanding the ability to control the model, resolve a lot of complaints about v1, and lots, lots more concepts can now be understood by the model.
Over 3X more images. 6.7M images in version 2 versus 1.5M in version 1.
SFW support. I added 2M SFW images to the dataset, both so bigASP can be more useful as well as expanding its range of understanding. In my testing so far, bigASP is excellent at nature photography.
Longer training. Version 1 felt a bit undertrained. Version 2 was trained for 40M samples versus 30M in version 1. This seems to have tighten up the model quite a bit.
Score tags are now optional! They were randomly dropped during training, so the model will work just fine even when they aren't specified.
Updated quality model. I updated the model used to score the images, both to improve it slightly and to handle the new range of data. In my experience the range of "good" images is now much broader, starting from score_5. So you can be much more relaxed in what scores you prompt for and hopefully get even more variety in outputs than before.
More male focused data. It may come as a surprise to many, but nearly 50% of the world population is male! Kinda weird to have them so underrepresented in our models! Version 2 has added a good chunk more images focused on the male form. There's more work to be done here, but it's better than v1.
Recommended Settings
Sampler: DPM++ 2M SDE or DPM++ 3M SDE
Schedule: Kerras or Exponential. ⚠️ WARNING ⚠️ Normal schedule will cause garbage outputs.
Steps: 40
CFG: 2.0 or 3.0
Perturbed Attention Guidance (available in at least ComfyUI), can help sometimes so I recommend giving it a try. It is especially helpful for faces and more complex scenes. However it can easily overcook an image, so turn down CFG when using PAG.
⚠️ WARNING ⚠️ If you're coming from Version 1, this version has much lower recommended CFG settings.
Supported resolutions (with image count for reference):
832x1216: 2229287
1216x832: 2179902
832x1152: 762149
1152x896: 430643
896x1152: 198820
1344x768: 185089
768x1344: 145989
1024x1024: 102374
1152x832: 70110
1280x768: 58728
768x1280: 42345
896x1088: 40613
1344x704: 31708
704x1344: 31163
704x1472: 27365
960x1088: 26303
1088x896: 24592
1472x704: 17991
960x1024: 17886
1088x960: 17229
1536x640: 16485
1024x960: 15745
704x1408: 14188
1408x704: 12204
1600x640: 4835
1728x576: 4718
1664x576: 2999
640x1536: 1827
640x1600: 635
576x1664: 456
576x1728: 335Prompting
bigASP 🐍, as of version 2, was trained to support both detailed natural language prompts and booru-tag prompting. That means all of these kinds of prompting styles work:
A photograph of a cute puppy running through a field of flowers with the sun shining brightly in the background. Captured with depth of field to enhance the focus on the subject.Photo of a cute puppy, running through a field of flowers, bright sun in background, depth of fieldphoto (medium), cute puppy, running, field of flowers, bright sun, sun in background, depth_of_fieldIf you've used bigASP v1 in the past, all of those tags should still work! But now you can add natural language to help describe what you want in more words than just tags.
If you need some ideas for how to write prompts that bigASP understands well, try running some of your favorite images through JoyCaption: https://huggingface.co/spaces/fancyfeast/joy-caption-alpha-two bigASP v2 was trained using JoyCaption (Alpha Two) to generate short, medium, long, etc descriptive captions, so any of those JoyCaption settings will work well to help you out.
I also recommend checking out the metadata for any of the images in the gallery to get some ideas. I always upload my images with the ComfyUI workflow when possible.
Finally, scoring. bigASP 🐍 v2, like v1 and inspired by the incredible work of PonyDiffusion, was trained with "score tags". This means it understands things like score_8_up, which specify the quality of the image you want generated. All images in bigASP's dataset were scored from 0 to 9, with 0 completely excluded from training, and 9 being the best of the best. So when you write something like score_7_up at the beginning of your prompt, you're telling bigASP "I want an image that's at least a quality of 7."
Unlike v1, this version of bigASP does not require specifying a score tag in your prompt. If you don't, bigASP is free to generate across its wide range of qualities, so expect both good and bad! But I highly recommend putting a score tag of some kind at the beginning of your prompt, to help guide the model. I usually just use score_7_up, which guides towards generally good quality, while still giving bigASP some freedom. If you want only the best, score_9. If you want more variety, score_5_up. Hopefully that makes sense! You can specify multiple score tags if you want, but one is usually enough. And you can put lower scores in the negative to see if that helps. Something like score_1, score_2, score_3.
NOTE: If you use a score tag, it must be at the beginning of the prompt.
NOTE: If you want booru style tags in your prompt, don't forget that some tags use parenthesis, for example photo (medium). And many UI's use parenthesis for prompt weighting! So don't forget to escape the parenthesis if you're using something like ComfyUI or Auto1111, i.e. photo \(medium\).
Example prompts
SFW, chill sunset over a calm lake with a distant mountain range, soft clouds, and a lone sailboat.score_7_up, Photo of a woman with blonde hair, red lipstick, and a black necklace, sitting on a bed, masturbating, watermarkscore_8, A vibrant photo of a tropical beach scene, taken on a bright sunny day. The foreground features a wooden railing and lush green grass, with a large, twisted palm tree in the center-right. The background showcases a sandy beach with turquoise waters and a clear blue sky. The palm tree has long, spiky leaves that contrast with the smooth, curved trunk. The overall scene is peaceful and inviting, with a sense of warmth and relaxation.score_8_up, A captivating and surreal photograph of a cafe with neon lights shining down on a handsome man standing behind the counter. The man is wearing an apron and smiling warmly at the camera. The lighting is warm and glowing, with soft shadows adding depth and detail to the man. Highly detailed skin textures, muscular, cup of coffee, medium wide shot, taken with a Canon EOS.score_7_up, photo \(medium\), 1girl, spread legs, small breasts, puffy nipples, cumshot, shockedscore_7_up, photo (medium), long hair, standing, thighhighs, reddit, 1girl, r/asstastic, kitchen, dark skinscore_8_up, photo \(medium\), black shirt, pussy, long hair, spread legs, thighhighs, miniskirt, outsidePhoto of a blue 1960s Mercedes-Benz car, close-up, headlight, chrome accents, Arabic text on license plate, low qualityPrompting (Advanced)
Like version 1, this version of bigASP understands all of the tags that JoyTag uses. Some might find it useful to reference this list of tags seen during v2's training, including the number of times that tag occurs: https://gist.github.com/fpgaminer/0243de0d232a90dcae5e2f47d844f9bb
Of course, version 2 now understands more natural prompting, thanks to JoyCaption. That means there's a gold mine of new concepts that this version of bigASP 🐍 understands. Many people found the tag list from v1 to be helpful in exploring the model's capabilities. For natural language, a similar approach is to do "n-gram" analysis on the corpus of captions the model saw during training. Basically, this finds common combinations of "words". Here's that list, including the number of times each fragment of text occurs: https://gist.github.com/fpgaminer/26f4da885cc61bede13b3779b81ba300
The first column of the n-gram list is the number of "words" considered, from 1 up to 7. The second column is the text. The third column is the number of times that particular combination of words was seen (which might be higher than the number of images, since they can occur multiple times in a single caption). Note that "noun chunks" are counted as a single word in this analysis. Examples: "her right side", "his body", "water droplets". All of those are considered a single "word", since they represent a consolidated concept. So don't be surprised if the list above has "tattoo on her right side" listed as being 3 words. Also note that some punctuation might be missing from the extracted text fragments, due to the way the text was processed for this analysis.
Various sources can be mentioned, such as reddit, flickr, unsplash, instagram, etc. As well as specific subreddits (similar to v1).
Tags such as NSFW, SFW, and Suggestive, can help guide the content of the generations.
For the most part, bigASP 🐍 will not generate watermarks unless one is specifically mentioned. The trigger word is, coincidentally, watermark. Adding watermark to negatives might help avoid them even more, though in my testing they're quite rare for most prompts.
bigASP 🐍 can generate text that you specify using language like The person is holding a sign with the text "Happy Halloween" on it. You can prompt for text in various ways, but definitely put the text you want to appear on the image in quotes. That said, this is SDXL, so except to have to hammer a lot of gens to get good text. And the more complex the image, the less well SDXL will do with text. But it's a neat parlor trick for this old girl!
Some camera makes and models, as well as focal length, aperture, etc are understood by the model. Their effects are unknown. You can use a tag like DSLR to more generally guide the model towards "professional" photos, but beware that it will also tend to put a camera in the photo...
As mentioned in the list of features, bigASP 🐍 was trained with long prompt support. It was trained using the technique that NovelAI invented and documented graciously, and is the same technique that most generation UIs use when your prompt exceeds CLIP's maximum of 75 tokens. There's a good mix of caption lengths in the dataset, so any length from a few tokens up to 225 tokens should work well. With the usual caveats of this technique.
Limitations
No offset noise: Sorry, maybe next version.
No anime: This is a photo model through and through. Perhaps in a future version anime will be included to expand the model's concepts.
Faces/hands/feet: You know the deal.
VAE issues: SDXL's VAE sucks. We all know it. But nowhere is it more apparent than in photos. And because bigASP generates such high levels of detail, it really exposes the weaknesses of the VAE. Not much I can do about that.
No miracles: This is SDXL, so expect the usual. 1:24 ratio of good to meh gens, a good amount of body horror, etc. Some prompts will work well for no reason. Some will produce nightmares no matter how you tweak the prompt. Multiple characters is better in this version of bigASP compared to v1, but is still rough. Such is the way of these older architectures. I think bigASP is more or less at the limit of what can be done here now.
Training Details (Version 2)
All the nitty gritty of getting version 2 trained are documented here: https://civarchive.com/articles/8423
Training Details (Version 1)
Details on how the big SDXL finetunes were trained is scarce to say the least. So, I'm sharing all my details here to help the community.
bigASP was trained on about 1,440,000 photos, all with resolutions larger than their respective aspect ratio bucket. Each image is about 1MB on disk, making the database about 1TB per million images.
Every image goes through: the quality model to rate it from 0 to 9; JoyTag to tag it; OWLv2 with the prompt "a watermark" to detect watermarks in the images. I found OWLv2 to perform better than even a finetuned vision model, and it has the added benefit of providing bounding boxes for the watermarks. Accuracy is about 92%. While it wasn't done for this version, it's possible in the future that the bounding boxes could be used to do "loss masking" during training, which basically hides the watermarks from SD. For now, if a watermark is detect, a "watermark" tag is included in the training prompt.
Images with a score of 0 are dropped entirely. I did a lot of work specifically training the scoring model to put certain images down in this score bracket. You'd be surprised at how much junk comes through in datasets, and even a hint of them and really throw off training. Thumbnails, video preview images, ads, etc.
bigASP uses the same aspect ratios buckets that SDXL's paper defines. All images are bucketed into the bucket they best fit in while not being smaller than any dimension of that bucket when scaled down. So after scaling, images get randomly cropped. The original resolution and crop data is recorded alongside the VAE encoded image on disk for conditioning SDXL, and finally the latent is gzipped. I found gzip to provide a nice 30% space savings. This reduces the training dataset down to about 100GB per million images.
Training was done using a custom training script based off the diffusers library. I used a custom training script so that I could fully understand all the inner mechanics and implement any tweaks I wanted. Plus I had my training scripts from SD1.5 training, so it wasn't a huge leap. The downside is that a lot of time had to be spent debugging subtle issues that cropped up after several bugged runs. Those are all expensive mistakes. But, for me, mistakes are the cost of learning.
I think the training prompts are really important to the performance of the final model in actual usage. The custom Dataset class is responsible for doing a lot of heavy lifting when it comes to generating the training prompts. People prompt with everything from short prompts to long prompts, to prompts with all kinds of commas, underscores, typos, etc.
I pulled a large sample of AI images that included prompts to analyze the statistics of typical user prompts. The distribution of prompts followed a mostly normal distribution, with a mean of 32 tags and a std of 19.8. So my Dataset class reflects this. For every training sample, it picks a random integer in this distribution to determine how many tags it should use for this training sample. It shuffles the tags on the image and then truncates them to that number.
This means that during training the model sees everything from just "1girl" to a huge 224 token prompt! And thus, hopefully, learns to fill in the details for the user.
Certain tags, like watermark, are given priority and always included if present, so the model learns those tags strongly.
The tag alias list from danbooru is used to randomly mutate tags to synonyms so that bigASP understands all the different ways people might refer to a concept. Hopefully.
And, of course, the score tags. Just like Pony XL, bigASP encodes the score of a training sample as a range of tags of the form "score_X" and "score_X_up". However, to avoid the issues Pony XL ran into, only a random number of score tags are included in the training prompt. That way the model doesn't require "score_8, score_7, score_6," etc in the prompt to work correctly. It's already used to just a single, or a couple score tags being present.
10% of the time the prompt is dropped completely, being set to an empty string. UCG, you know the deal. N.B.!!! I noticed in Stability's training scripts, and even HuggingFace's scripts, that instead of setting the prompt to an empty string, they set it to "zero" in the embedded space. This is different from how SD1.5 was trained. And it's different from how most of the SD front-ends do inference on SD. My theory is that it can actually be a big problem if SDXL is trained with "zero" dropping instead of empty prompt dropping. That means that during inference, if you use an empty prompt, you're telling the model to move away not from the "average image", but away from only images that happened to have no caption during training. That doesn't sound right. So for bigASP I opt to train with empty prompt dropping.
Additionally, Stability's training scripts include dropping of SDXL's other conditionings: original_size, crop, and target_size. I didn't see this behavior present in kohyaa's scripts, so I didn't use it. I'm not entirely sure what benefit it would provide.
I made sure that during training, the model gets a variety of batched prompt lengths. What I mean is, the prompts themselves for each training sample are certainly different lengths, but they all have to be padded to the longest example in a batch. So it's important to ensure that the model still sees a variety of lengths even after batching, otherwise it might overfit and only work on a specific range of prompt lengths. A quick Python Notebook to scan the training batches helped to verify a good distribution: 25% of batches were 225 tokens, 66% were 150, and 9% were 75 tokens. Though in future runs I might try to balance this more.
The rest of the training process is fairly standard. I found min-snr loss to work best in my experiments. Pure fp16 training did not work for me, so I had to resort to mixed precision with the model in fp32. Since the latents are already encoded, the VAE doesn't need to be loaded, saving precious memory. For generating sample images during training, I use a separate machine which grabs the saved checkpoints and generates the sample images. Again, that saves memory and compute on the training machine.
The final run uses an effective batch size of 2048, no EMA, no offset noise, PyTorch's AMP with just float16 (not bfloat16), 1e-4 learning rate, AdamW, min-snr loss, 0.1 weight decay, cosine annealing with linear warmup for 100,000 training samples, 10% UCG rate, text encoder 1 training is enabled, text encoded 2 is kept frozen, min_snr_gamma=5, PyTorch GradScaler with an initial scaling of 65k, 0.9 beta1, 0.999 beta2, 1e-8 eps. Everything is initialized from SDXL 1.0.
A validation dataset of 2048 images is used. Validation is performed every 50,000 samples to ensure that the model is not overfitting and to help guide hyperparameter selection. To help compare runs with different loss functions, validation is always performed with the basic loss function, even if training is using e.g. min-snr. And a checkpoint is saved every 500,000 samples. I find that it's really only helpful to look at sample images every million steps, so that process is run on every other checkpoint.
A stable training loss is also logged (I use Wandb to monitor my runs). Stable training loss is calculated at the same time as validation loss (one after the other). It's basically like a validation pass, except instead of using the validation dataset, it uses the first 2048 images from the training dataset, and uses a fixed seed. This provides a, well, stable training loss. SD's training loss is incredibly noisy, so this metric provides a much better gauge of how training loss is progressing.
The batch size I use is quite large compared to the few values I've seen online for finetuning runs. But it's informed by my experience with training other models. Large batch size wins in the long run, but is worse in the short run, so its efficacy can be challenging to measure on small scale benchmarks. Hopefully it was a win here. Full runs on SDXL are far too expensive for much experimentation here. But one immediate benefit of a large batch size is that iteration speed is faster, since optimization and gradient sync happens less frequently.
Training was done on an 8xH100 sxm5 machine rented in the cloud. On this machine, iteration speed is about 70 images/s. That means the whole run took about 5 solid days of computing. A staggering number for a hobbyist like me. Please send hugs. I hurt.
Training being done in the cloud was a big motivator for the use of precomputed latents. Takes me about an hour to get the data over to the machine to begin training. Theoretically the code could be set up to start training immediately, as the training data is streamed in for the first pass. It takes even the 8xH100 four hours to work through a million images, so data can be streamed faster than it's training. That way the machine isn't sitting idle burning money.
One disadvantage of precomputed latents is, of course, the lack of regularization from varying the latents between epochs. The model still sees a very large variety of prompts between epochs, but it won't see different crops of images or variations in VAE sampling. In future runs what I might do is have my local GPUs re-encoding the latents constantly and streaming those updated latents to the cloud machine. That way the latents change every few epochs. I didn't detect any overfitting on this run, so it might not be a big deal either way.
Finally, the loss curve. I noticed a rather large variance in the validation loss between different datasets, so it'll be hard for others to compare, but for what it's worth:
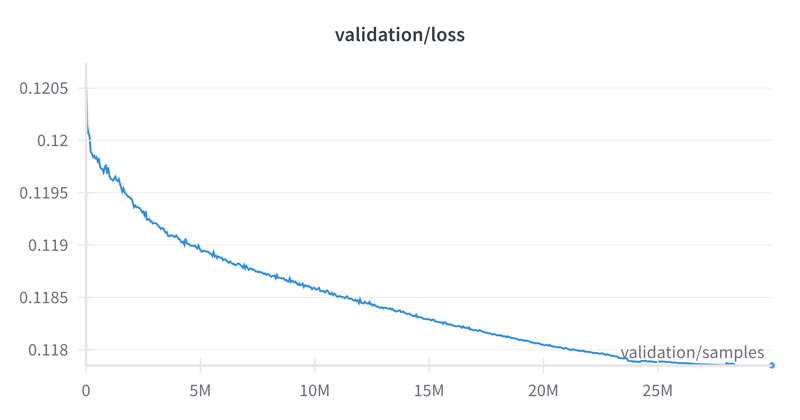
Description
Version 2
FAQ
Comments (327)
Showing latest 312 of 327.
I am following your recommended settings, but all I get is garbage out of every single render. Perturbed guidance doesn't help. I don't understand how you are getting the quality from your examples. Are you using hires fix (doesn't seem to help for me)?
If you're using ComfyUI, you should be able to download any of the sample images and drop them in, to get the exact settings and workflow. If you're using Auto1111 or similar, I've added an image generated using Auto1111 (https://civitai.com/images/36552237). You can drop that into the PNG info tab and then send all the exact settings to txt2img. That should recreate the exact image. If you're not able to get that image, or at least something similar, there could be oddness in your UI's deeper settings, or dependencies.
I used these settings in Forge/Automatic1111
Prompt:
score_7_up
Negative prompt:
score_1, score_2, score_3
Steps: 35,
Sampler: DPM++ 2M SDE
Schedule type: Exponential (Automatic)
CFG scale: 5.5
Size: 1024x1024
Model: bigasp_v20
VAE: sdxl.vae.safetensors
@CyclopsGER I'm using the Lighning lora with 8 steps, cfg 1.5, Euler SGM Uniform. Works fine.
has anybody a solution to this problem that works with Draw Things? I I'm intrigued with this model's prompt adhesion but there's so much work/time required to get the best out of it, more than seems to be the other commenter's experiences here. I think maybe DT needs to support this other renderer. I wish I could get this one to work…
Firstly, NB, thank you. For the time, the effort, the expense. You are greatly appreciated.
I'm probably your biggest most obsessive fan. I don't do anything stable diffusion that doesn't include or incorporate your work. It's the best. By a long mile.
I hope you and your other fans take this as a conversation to help march things forward, not as just raw criticism, and I'm certainly open to learning that the errors are mine due to poor prompting or parameters.
At this point, I think I'm as close as anyone to being a BigAsp-ologist. I have hundreds of hours in finetune and lora training on V1, and am excited to continue that journey with V2.
There's nothing here that can't be fixed via further training and loras, and you've provided a much more powerful and flexible playground with V2 that will provide a platform for lots of fun experiments.
In my initial runs, the primary issue I'm seeing is a degradation in quality and consistency with hands and genitalia when compared with V1 output. Faces, which suffered from a clear and difficult to address bias in V1, are much more varied and flexible, a huge win, but female genitalia is generally less accurate and reliable, even when employing inpaint techniques (adetailer ect).
Close-up images are amazingly photorealistic, but once the camera zooms out to full or partial-full body poses, the consistency in quality is lower than V1 for nude and partial nude photography.
You've certainly beaten the stone backgrounds out of the model, and background quality is superior to V1, and is overall dramatically more flexible.
V1 had a ridiculous level of nipple quality and symmetry, but V2 consistently produces only one realistic nipple and one distorted. If V1 did this 2 out of 5 images, V2 does it nearly 4 out of 5.
Again, these are issues that are correctable, one way or another, I just wanted to share my initial experience to provide some feedback as you continue to perfect your process.
I've found that using the tags tends to give you better outputs than natural language prompting. And v2 results with tags are better than v1 results with the same tags.
I appreciate the detailed feedback, thank you. I'm definitely looking into these issues to see what can be done about them.
I saw the issues with hands, genitalia & closeup vs zoomed out too. Prompting is definitely easier. Strangely, 1 in 10 or 20 images has superior quality when only varying.the seed. Would be nice to have a higher hit rate.
Ok, so after digging deeper, I've found that, like V1, V2 benefits greatly from being stabilized via merging with other checkpoints. This allows the high quality and variety from bigasp while reducing body horror and producing better consistency. With the correct merging and ratios, you can retain all of bigasp's prompting ability. This also provides a bit more flexibility and lora compatibility. By merging bigaspv2 with my gurilamash i've been able to leverage all of my loras as well as a wide variety loras from other authors. I'm excited to start training on this as it'll likely be a few months before we all head over to SD3.5.
@gurilagardnr What helps a lot without merging is using PAG or Lightning or both. This reduces a lot of problems. Retains the creativity but likely does not add lora compatibility.
Been a huge fan of yours since your subreddit models, honestly the best NSFW model maker on CivitAI. None of my merges go without your models, its an absolute requirement.
The god is back :) thanks for V2 and this model
Gr34t1
I am getting garbled outputs using your example config, even with PAG. Tried 50+ times. Example here: https://imgur.com/a/fkNwXgE
That looks like what happens when using the "normal" schedule. Double check that your schedule is set to either Kerras or Exponential. Also 720x1080 is kind of an odd resolution.
Same. Tried all kinds of samplers and schedulers. I only get bad or mediocre results.
Dude the model is great but the info that you provided about how you did it it's awesome. I really want to know more about how you did it and your experience.
Thanks! My break down of training version 2 is now up: https://civitai.com/articles/8423
I want to second that I really appreciate your write-up! And of course one of my absolute favs as far as models go!
I'll retrain the Anime Screencap Style Lora and the Unrealistic Concepts one, when I get a chance, for V2. Great work!
I've been using no score prompts and then using a refiner to clean up the results; the creativity is through the roof doing it this way and it looks fantastic. Fabled Illusion is a good fit as a refiner with CFG set to 5, Detailer isn't needed either.
Thanks for creating a truly unique model.
unique is the right word! There is so much creative potential inside, I appreciate this model for what it does when leaving out the score tags.
FYI, regular DPM++ SDE GPU (so like not 2M, not 3M) is also a great option with this. And for that one you DO want to use the Normal scheduler, and a CFG of around 5.0. It's slow to generate compared to other configs, however, but gives fantastic quality.
Huge info shared here. I am only interested in SWF, haven't tested yet, but if not spitting out NSFW randomly this can be new base sdlx model
It was trained on the keywords "sfw", "nsfw", and "suggestive", so those should be helpful is limiting the output to SFW. However I'll note that it's not going to be as accurate as I would like, since JoyCaption Alpha Two's accuracy here is not optimal. This will improve in the future.
@nutbutter thanks looking forward to it
Clearly, this model isn't yours, aside from using your face and charging for configuration files and paywalling free data, Maybe here you'll find for free the missing knowledge that you should have if your weren't a fraud. 😍😂
How much time and money did you spend on this?
It seems that the size of this training dataset has already surpassed Pony's, right? With such a massive amount of data, it could almost be considered a separate series—maybe a realistic version of Pony? Anyway, I'll download it and give it a try first.
The training run itself was $3,600 and just under 6 days.
@nutbutter Do you make that back or is this just a passion project for you?
@chollman82141 The model is free so ... no. So far I just consider it the cost of learning. Certainly better value than most university ML courses, I figure.
be ready for sd35 , because it will be your better 2.5x ~ 3x next bigasp model
lightning 4 steps version please, or hyper version that works with dpm ++ sde karras
The lower the config, the more washed out it looks.
I almost wrote it off until I tried higher configs, now it's my GOAT.
What do you mean higher configs?
Very strange, I also get very deformed body horror outputs like 70% of the times, blurry and nasty. Using forge and reforge, with or without low bits settings - result is bad.
Did you ever sort it out? I also found that Forge turned out nothing but blurry, early SD 1.5 style images for me.
i like how this model can easily do natural looking vintage analog film kind of stuff which pony-based models are seemingly completely incapable of. you're doing great, keep at it.
Took some dialing in of the settings, but once I got it down 2.0 is a MASSIVE improvement over 1.0. The variety is so great, many different faces and body types from simple prompts. Best skin detail I've ever seen in a model as well, captures tiny details like fine body hairs and goosebumps that really elevate the realism of the image. Keep up the fantastic work!
First of all, you have gained an unfathomable amount of respect from me and the rest of the community for taking your time and spending $3500+ on training this incredible model. I cannot even comprehend the scale at which this was trained, and the skillset required to gather and prepare the data for this. As SECourses has stated in the other comment, this can truly be seen as a new SDXL base model.
Stop promoting this SECourses fraud publicly. Just give him your love & money quietly.
In case you didn't see, this model is from nutbutter, and it's valuable knowledge shared for free here. Please promote him and spread his name instead of making marketing for SECourses. 😩
@roberto_baggio Aw man, I was just referring to his comment on here. I am a firm believer of giving back freely to the open source community, and I kinda understand the hate for the dinosaur riding man as I've been in the community for quite a while.
@nottheninja, Fair answer, I apologize for my harsh tone. You don't deserve that.😅
I must be missing a trick somewhere. I've tried this model in both Comfy and Forge and I get nothing but blurry, mushy outputs that are very low quality. I'm using the settings as described in the instruction...
I can't get any useful output from this model, but would love to know how. I appreciate the creator sharing the processes and working hard on this. For all those who love this model, what's your trick?
I'm using Forge and have tried the recommended settings, as well ones mentioned in comments. I've tried booru and sentence style prompting. The examples images posted here are missing prompts, use extremely short prompts, or the images don't match the prompts. I've only been able to output very distorted faces and body horror, and even those don't match the prompt. Scenery prompts I tried worked worse than human prompts - mostly incoherent.
I assume you're running it in forge? Try running in comfy. the forge doesn't work properly.
@terrariyum Try dropping this image (https://civitai.com/images/36552237) into Forge or Auto1111 and sending the settings into txt2img. If your installation of Forge or Auto1111 is not able to replicate that image, it could be an issue with some deeper settings in your UI, or plugins. I did a fresh install of Forge on my machine to verify that this image reproduces correctly. I've seen people mention Forge/Auto1111 having quantization settings that caused them issues.
@nutbutter thanks so much for your reply. I can confirm that I was able to reproduce that image exactly using the most recent Forge. At least as of today, Forge has no problem using bigASP and works great in general.
After playing more prompts, I'm still rarely getting coherent images. But I could say the same of vanilla PonyXL. Yet Pony with certain loras becomes very predictable and excellent. Maybe that's also true for bigASP
@terrariyum Yeah, bigASP v2 is a bit unstable, with its consistency in gens being very dependent on prompt. I'm working to make it more stable, so hopefully it gets better in later versions.
@nutbutter Oh? More bigAsps?!
If anyone is struggling with washed out photos at CFG 2-3, remove all LORA's, simplify your prompts and try again.
It seems to be extremely sensitive to LORA-use (at least LORA's based on other checkpoints)
You can run it just fine at more normal configs. The default of 7 works fine. It's still coherent well above 7 in many cases.
Civitai must label this as base model. So it will be some chance, that good lora makers make new versions of celebs specifically for this.
If you dont know, there is a new SDXL basemodel, called Illustrious, which behave same as Pony. It has its own section, so Bigasp desperatly needs its own section too.
I agree but this model isn't as easy to use as Pony is.
@MachineMinded Yes, you are right. Thatswhy we need finetunes, merges. Too much potential wasted, if nobody will use it.
I didnt use it either, i am on a realistic Pony checkpoint. But this has so much potential, which goes to trash, if nobody supports it.
@MachineMinded this understands natural language descriptions of things like 10x better than Pony though, which I find helps. Overall the level of detail this thing puts out is way way way ahead of anything anyone could ever do with a tweaked Pony as far as realism.
An epic Model, sadly does not work well with characters lora
it's a heavy finetune, it's the sort of thing you'd have to train new Loras directly on, like Pony or Illustrious
@diffusionfanatic1173 ohh, the same problem happened with the Natvis model
I see that putting the snake emoji into the model spits out a snake image. Besides words, are there any other ways or tips to prompt? Any way to prompt specific people if they were trained in, etc? Ideas? Esoteric hints? Anything other than words? Hashes? What kind? Anything? Curious to see what variations I can get on your trained concepts.
This model is not able to run on Comfyui...
Yeah it is
it works in comfyui as in forge. but you can't run it in FP8 because this chekpoint has been made wrong. maybe autor will fix it
I confirm. 😔 It doesn't work on ComfyUI or works with monstrous distortions.😑
This model is incredible but quite finnicky to use.
What tends to work for me is to generate in slightly larger format like 1024x1280, use DPM ++2M SDE with Karras, CFG between 2 and 3, Perturbed attention guidance betwen 1 and 2 and upscale the good ones.
Steps : 40 to 50.
This is all in Swarm UI.
Even then it is quite hit and miss but unmatched when it works well.
multiple_views is almost always required as a negative, I find.
Thank you for the incredible work !
Thank you for the feedback! Yeah the multiple views are annoying. I'll try to make those a "required keyword" for those training images in the future. This will make it so it only generates multiple views when asked. As for it being finnicky, I'm doing lots of experiments in the background to figure out the root cause and get that fixed going forward.
I agree, am using forge though, mostly using 1344X768 format. Prompting takes me longer than with other models. But when it is done and the model finally behaves the output is gorgeous. I also agree on the multiple view problem. It seems certain keywords trigger it a lot while with other prompts I never have the problem occur even once. Sadly I did not take notes which were the bad words.
In any case thank you very much for this incredible model. I am having a lot of fun with it so far. If you ever release another/improved version I will download for sure.=^_^=
PS: I never had a good image with Perturbed attention guidance EVER no matter the model. It is either zoomed in or scrambled limbs etc...If anyone has a tip what numbers to use in FORGE would be much appreciated.
Try a more normal CFG of 7 maybe? Colors and faces will be vastly better.
@jelinaradich493 The default value of 3 for PAG gives bad results, I've found. For text2img, I like a very low value (I use 0.8) and with lower CFG (BigAsp v2 already recommends low CFG values of 2-3).
If you're doing img2img or upscaling, you can safely crank PAG to 3.
@Gremble Thank you very much. I will try that out!
a lot of helpful tips in this comment (not least was just a coincidence since I only just over the weekend decided to up my resolution at the expense of time to the very ratio you say, and it's crazy how much it improves every generation…), thanks, I wish there was more discussion like this cos it's just so frustrating to like generate a 100 pics and almost give up but then it throws out ONE (1) result that's so damn good you just can't give up lol. but that's I guess the whole essence of AI Art.
Please train SD 3.5 your model are AMAZING !!!
3.5 Medium would probably be the most cost-effective way to still be able to improve bigASP a lot, with a dataset that isn't smaller than the current one, IMO. (Technically speaking though, so would Kolors, as obscure as it is, since Kolors is pretty much literally SDXL with better noise scheduling and ChatGLM as the sole text encoder instead of CLIP, to allow for much better prompt adherence).
Didn't understand this CP at first sight/prompt... In the end, It happens to be the most versatile/sexy/creative/surprising model out there... BigUp ! & Thank you ;-)
What did you find is best practice for prompting etc?
The quality of this model is incredible, but I can't get it to generate what is in my prompt. Do you have any tips to get it to adhere to the prompt?
@nutbutter Ok, so I find this model does recognize some website names and reproduces their style quite well, as well as the watermark. How do I get it to prompt a specific model?
I'm itching to try it out, but I'm getting no joy on calling up the appearance of any given model from sites. Is there a method, or was joycaption just reading the watermark (odd because it did very well with one in very stylized cursive).
Please, oh master, share your secrets! Tell us how to get more out of your masterwork? Were any site or model names incorporated into training data or were some kind folder naming or something? I need to call forth the hidden potential!
Also, is there any way to prompt specifically innies? I've seen other checkpoints where you can, but this one spits out random ones and I didn't see a prompt for it.
Yeah, the ability to prompt for specific websites is accidental; just JoyCaption reading the watermarks. I didn't intentionally include that kind of source information outside of the more public sources like flickr, reddit, and unsplash.
I included a link to an n-gram analysis of v2's training data in the model description. You should be able to go through that list to find things the model will recognize and respond to, including these website names it picked up on through watermarks and anything else JoyCaption recognized or picked up on.
By "innies" do you mean innie vaginas? If so, the trigger words should be things like "cleft of venus", "cleft_of_venus", "outer labia", putting "inner labia" in the negatives, etc. JoyCaption Alpha Two is a bit weak here, so that's the best v2 will understand for now. "Innie pussy" and variations thereof are in JoyCaption's training data, but not very strongly yet. Hopefully that improves in the future.
@nutbutter Yeah, the sites are not in your n-gram excel file....
This is the best and most flexible model I have ever used. It's exceptional for a broad range of needs and wants. I find the model doesn't do well for my prompting at 2-3 cfg, as it seems to forget certain concepts entirely. Cfg 7 is best for me, but I can see why you advise cfg 2-3.
Anyway, you're awesome, thanks for the checkpoint.
Be sure to check the n-gram file, not the tag list: https://gist.github.com/fpgaminer/26f4da885cc61bede13b3779b81ba300
Plenty of website names in there.
@nutbutter Looks like it was "trimmed."
V2 is an immense jump from V1, congratulations.
If you elect to continue model training (and especially if you're considering upgrading to SD 3.5 at some point), I think you're on path to having one of the best finetunes in the community. That said, I'd like to offer my observations/criticisms.
I'm aware that cohesive, robust, accurate captioning is a hard issue, but I hope you'll be able to improve JoyCaption in the future. As an avid Pony addict, I can immediately notice the massive decrease in prompt adherence.
One specific pitfall of prompt adherence is—for a model that has porn in mind as a primary feature—it's actually quite unreliable at conjuring specified positions. There's also gaps in sex knowledge that I'd never run into in Pony.
As I've seen others note, the unprompted "multiple views" is extremely prevalent. Equally so, you can end up with dick-girls even with no mention of "penis" or its synonyms. Which is quite novel to me, I've basically never seen this quirk in all my time with diffusion (manginas, however, I've seen hundreds). Of course I've realized you can negative prompt these issues, though it's not the greatest that one should have to. Cropped off heads are more prevalent than I've ever seen as well.
But again, despite these issues, your efforts and expenditure have definitely borne fruit, it's still a very special and capable finetune.
I wish you prosperity in your future.
Thank you for the detailed feedback! Very helpful :)
Something I noticed is that adding DMD2 really, really increases the prompt adherence and output quality of this model. It's simply incredible. I invite others to try it out.
To do so:
1. Download the DMD2 model: https://huggingface.co/tianweiy/DMD2/resolve/main/dmd2_sdxl_4step_lora_fp16.safetensors?download=true
2. Load the LoRA as you would any other.
3. Set your steps to 7.
4. Set CFG to 1.
5. Set sampler/scheduler to LCM/karras
6. 🚀🚀🚀
@MachineMinded Thanks for pointing this out! I've been playing around with this today, and I'm really impressed.
One thing I've noticed: DMD2 isn't compatible with PAG. No big deal, because DMD2 does a great job at cleaning up hands and faces, so PAG isn't needed.
I do think it sucks to lose the negative prompt -- BUT -- I've found that DMD2 works great as a refiner after an initial generation.
Just do an initial generation without DMD2, then pass the latent into another KSampler with DMD2, and do 7 more steps with .25 denoise. You get a sharper image that isn't changed drastically.
DMD2 also works great with upscaling with tiled controlnet.
@MachineMinded I tried this and only getting weird output :( using forge webui. any tips by chance?
@carperold277 If you have Discord, hit me up there under machineminded. It could be a number of things depending on your settings.
@MachineMinded I could reproduce this in A111. Getting kind of interesting results. Not sure if I like it. But its fast!
Edit: Prompt is not fully respected but I can use it as fast prototyping :-)
Here is a pastebin with a very basic comfyui workflow
https://pastebin.com/q9rD9h3p
this works for bigaspv2lustify too
@MachineMinded This lora works very well for me, thank you. Exponential works pretty well too.
@prodajie It seems like it improves just about any model. It works great with Pony models as well!
Using DMD2 gives me the same/similar face with a lot of models, with others it's fine, I would be curious about the technical aspect why that is.
Yeah I've been using DMD2 before and it really does improve outputs, especially if you want realism. Add tags like "1980s", "1990s", "ISO 100" and stuff like that and you get images with good color and skin texture and a little noise that really boosts the realism, no more plasticy or "too perfect" look that makes it look fake. It helps to hide potential artifacts while still keeping a lot of detail in the image. I think the reason why DMD2 works better for adherence is because it doesn't need as many steps, so it's not overthinking things and so it doesn't blend too many different neural paths of the same concept.
@Gremble I'm using PAG in my workflow. It have it set to 0.20. It does help. I also use ddim uniform with lcm.
I want to thank you for all the work you put into this, and especially, the work put into the description of the checkpoint, how it works, and guidelines for best practice. This aspect of releasing a model to CivitAI is so important and so often overlooked. Thank you, thank you, and thank you.
just want to echo a couple other comments that suggest things aren't working in ComfyUI.
Fresh install + directly copied the workflows on some of your provided images... creates some really poor results, body horror, washed out, etc. nothing coherent. raising CFG just toasts it more.
Was using torch 2.4 with cuda 12.1, then I reinstalled everything and used torch 2.5 with cuda 12.6, same results. Disabled all custom nodes.
any ideas on what might be going on?
Clip "set last layer" to -1 seems to help me
every thing was working fine , just happened to me for no reason .. really 0 reason. just comfyui updated! that enough reason to make this sh*t happens !? it generate only noise and crap weird lines , it was working very fine , why that ?!!
This model is incredible. Amazing work. I like your instinct with not overtraining. This model performs like an unlocked foundational model imo.
Very true, gets a lot of variety between seeds, while a bunch of other models pretty much give the same stuff like lighting and faces. You can actually test a model by generating without a prompt. When you see the differences between certain models output without a prompt, you can tell how well they were trained and if they were over trained.
One of the best XL models!
New version of the Unrealistic Concepts Lora trained for Asp V2 is available now:
https://civitai.com/models/578869?modelVersionId=1068779
Bunch of the samples were flagged for review so aren't visible at the moment lol, but I do expect them to get cleared.
We need a dictionary, wiki, like there is for Pony. Until this is unusable.
why lol?
@slightlyoutofphase Because 99% of output is garbage. Im generating pics with AI to create my dreamgirls.
This would be a very good model to create them very realistic. But who cares about ugly, or just normal looking girls. If i would want that, i would just download some porn pics.
@denzilaudiel235 what?? it makes absolutely any type you want. You need to prompt better.
I am very interested in the checkpoint, also because of the taging. Unfortunately, it doesn't work for me. My test:
Focus, SwarmUI, Automatic1111
1024x1024, DPM++ 2M SDE, Karras, CFG 3, Steps 30-40
pos promt: score_7_up neg. promt: score_1, score_2, score_3
Only ugly faces are generated, incomplete bodies. Where is the error?
Use PAG, Lightning, both or merge with another checkpoint.
Thank you. PAG (Perturbed-Attention Guidance Scale? i choose 3 ) does not make it any better and should it work without it, after all the checkpoint author does not describe it?
Lightning: I'm testing with 'SDXL Lightning LoRAs', but it's not nice either.
@Sandi22 Every 20-30th image looks very nice with PAG and/or Lighning for me. I know, the hit rate could be higher. But also depends on the prompt. Some work better. You could also try a bigASP based model like Lustify or Big Lust. They are great. Or check out my own bigASP/Pony merge called Big Love at https://civitai.com/models/897413
You have to think of bigASP as a foundation model like the SDXL base model, which alone does not produce great results all the time. Subsequent training & merging steer it more into an appealing direction. But the bigASP based models will never have the full creativity of bigASP itself.
@SubtleShader ok, they work better for me
The author of this checkpoint SEVERLY overrateds Karras quite frankly, it looks better 90% of the time with Euler Ancestral at CFG 7.0 or DPM++ SDE GPU at CFG 5.0.
@SubtleShader Its same as Pony. But Pony works out of stock good, the base v6 is good enough.
If it would be a foundation model, i would say, OK. But this is an SDXL finetune, which doesnt work, as intended. What finetune is, which needs more finetune? Less would have been better in this case.
@denzilaudiel235 It is no fine-tune. Was trained on millions of images just like Pony. Does not have much to do with the SDXL base. I suggest you try Lustify or Big Lust, which are easier to use & are based on it.
@SubtleShader I understand you. But other models with millions captioned datas work good out of stock. Im on a Pony realistic model, Pony is a fuckin goldmine just on the surface, and a fuckin diamond mine, if we dig down more. Yeah, this could be good, if there would be not just merges, but new datas. Yes new datas.
High quality beauties(i mean gorgeous) need to be add. Merges are not good enough.
Your CFG recommendations are strangely low IMO. I get far better results just using Euler Ancestral at CFG 7 with no PAG, or DPM++ SDE GPU at CFG 5.
I'd mostly agree as someone who has even trained several loras for this model, I don't really understand how you'd wind up recommending what the description does.
Why doesnt somebody capture just the best girls?
There are ton of onlyfan, egirl, instabeuties. No need millions of datas, just 10 thousands of the best.
Anime lovers have everything, we are hungry too.
It generates only ugly faces
everyone's idea of "best girls" is different. So better to have a wide dataset and then prompt what you want.
Your "only the best" would probably be "meh" to a lot of ppl.
what tags do i used get a full nelson sex positikn like they have with pony model
@Kitten123 See the post about pony/illustrious/noob concept integration. Posted same day as this reply. Should work for you. This model is based entirely on photographic content, and that position is not common in real content, only anime content. You probably CAN use it, but it will take using bigasp as a refiner to an anime-realism model. Full instructions in the other post.
@null yeah I have never seen real people doing Pony-style full nelson I think ever lol
Keeps spitting out split images and comic style 4 in 1 images and multiple subjects is really difficult
@shubasaur877 It's an acknowledged issue. OP is looking into why. Put "multiple angles" in the negative prompt (without quotation marks). If it starts putting text in, then put "text" in the negative prompt.
Multiple different people is something non-anime SDXL models have always struggled with. Regional prompting is probably the go-to there.
I often add these ... it seems to be reducing the effect:
multiple views, image grid, split image, collage, split view
What are optimal full fine-tune settings for this model? I tried adafactor, lr 1e-05, bs7, 1500 steps for about 500 pictures but the outcome is quite blurry (photography style). Are there recommendations for this model? I use runpod so VRAM is not an issue for me .
1 bad data is enough to poison your entire dataset, so double check you don't have any blurry images in your dataset, even 1 image is enough to poison! I'll be very careful with all my inputs before expecting a good output!
@Ababiya Agreed - a small high quality data set will trump anything. I've had great luck fine tuning this model and training Loras.
How do I make the model generate images with the same face?
You don't. If you want the same face with no variation, you can use a pony-based model (for ponyface), or you can use an ipadapter or similar.
Train a Lora or two against bigasp and blend them.
Put a random name in, it will work "kinda"
Thanks for your hard work and also for making something for SDXL, us SDXL users are feeling left out in the cold
Its the best time, to be on XL, Lustify and BigLove brought present for XL users.
I have 8GB VRAM if I use basic prompt 512x512 40 stepc CFG 3 i get artifacts images, how fix this?
The model was not trained on 512x512. The supported resolutions are listed in the model description.
@nutbutter Thanks! I am idiot...
@rodriquez_88315 artifacts problem just happening here for no reason ! , same work flow now just out put artifacts shit , what reason ?!
Big time for XL users, Lustify and new BigLove.
I wont move back from Pony though still there is a porn chekpoint with total celeb and character likeness.
I read the instructions carefully but nothing works in my case, I'm only getting terrible generations
Try DPM++ SDE GPU (not 2M, not 3M) with the Normal scheduler, at around CFG 5.0.
Edit: It's also possible that you're using a UI where "Clip Skip" actually does something on SDXL (which normally it shouldn't, e.g. in Comfy there's no reason to ever use the "Clip Set Last Layer" node at all in an XL workflow). If that is the case though you'd want to set it to "2".
Specifically using 'photo \(medium\)' is basically necessary for good images, I've found, like it's way more important than any score tag. I think this is because literally every image in the dataset is tagged with it, meaning using it basically brings in the entire collective aesthetic of the dataset at a higher priority than anything that existed in base SDXL.
Very good, but make sure your resolution is in the 1024x1024 range (by area, things like 800x1500 work too) or you'll get noise.
Watching the user pics, if these are the best, whats this capable for, im sorry for the creator. He spent a lot money on this for nothing. Its a glorious failure, how to not create a model with gazillion low quality data.
It's actually the best realistic model out there, you just need to prompt it more like SD 1.5, and tweak the CFG/steps as needed. It can handle short prompts, but really it needs long prompts with the proper keywords and order of keywords. This isn't like FLUX, so natural language isn't really great. A good start for NSFW stuff is to keyword all the words for body parts, then keyword actions, scene descriptions, etc. Sometimes using the same keywords later in the prompt can help it better focus on what you're trying to generate. It also performs exceptionally well with DMD2 4 step accelerator LORA. As with all models, you have to learn how to prompt them.
@plk The problem is not the special prompt need, i use Pony and had to learn the whole booru dictionary.
But what can we squeeze out from this 6m dataset. The best, we can get a good looking girl, thats it. You are lucky, if you get a good looking girl 1/10.
Simple, this checkpoint has no use on its own. Lustify and Biglove has some bigasp in it, but they managed to get constant good looking girls, effortless realism(Lustify needs a pose prompt, a background prompt with no negative and you get photorealism)
Other thing, which bothers me with Bigasp, unability to prompt unique girls. He should drop a list of captioned whores, so we could prompt them. But no.
And all XL hardcore checkpoint has only one thing left to do: celeb likeness, and lora character likeness. Everybody wants that, not just 1girls. If i want 1girl, i download a real pic.
I just cant get my head around, why nobody understand this.
This checkpoint would be good only, if there would be a whole infrastructure around it, but nobody makes loras, true finetunes from it.
@suveermarkon910 Bruh, this is, bar none, the best checkpoint out there and it isn't even close. You're just prompt-inept or using the wrong settings. Joker is probably trying to prompt for a pony model or something. I'm extremely grateful to @nutbutter for this amazing model. I hope we will one day be blessed by another world class ASP model
@tymirrainier865 I mean I've released three celebrity Loras for this, and also a concept Lora. Gonna have an updated version of the anime style one out soon also. It's really not that hard to prompt either, the score tags literally work the same as Pony. It's like Pony but with not-dogshit natural language adherence, basically, or "Pony if hadn't literally forgotten what shit like a semi truck is" lol.
@tymirrainier865 your rant is somehow grimmer than the Illustrious section
@tymirrainier865 when someone says this about AI models when clearly and demonstrably - with both download counts and actual imagery proving the opposite - all the person is saying is "i haven't learned something, i'm frustrated and impatient, and want to pretend my experience is everyone's experience for whatever inexplicable reason"
like, just stop using it and don't bother people about it. you'lll get no long goodbyes or 'nice try!'s.. just leave it be, literally no one else cares.
@Narz One can love the style, the always different output, but nobody can say its a good checkpoint:))), or you didnt use any other model in your life.
The creator simple didnt know, what is high quality dataset. He just put everything into it, then it become a crap. Even Pony creators captioned only the best looking pics, then they manually threw out half of it.
exactly I join you people pretend to believe that this model is good if it's good then or are the quality photos with their data that proves otherwise
@plk or are your photos with their data ....??? haven't fools;)
My images all seem super over saturated, as if they're borderline burned. All characters develop loads of freckles in the final steps. I've gone through all the comments and still don't know what I'm doing wrong!
post a catbox of such of an image
if it's burned, you're either using too high of CFG or too many steps.
@bodikai dpm3 sde automatic, 30 steps, cfg 3 (up to 7-10 still works). I've never had that issue.
did you try changing the scheduler to karras or exponential?
Easily the best model out there, if it can be a bit finnicky at times. Much better in that regard than BA1. It's amazing how little credit this author gets. All the best mixes have his work in them.
That's how mix-leeches do their thing. Take other people's works, mix'em into a soup. And call it a day with no credits.
@nutbutter Have you given any consideration to training a BigAsp HunyuanVideo? I know it is probably far more demanding to train, so I was just wondering.
Would be cool, but I don't have a dataset for it. Roadmap right now is working on finish JoyCaption and then training a v3 of bigasp on a more modern diffusion model like Flux or something.
@nutbutter How do you make Flux hardcore capable? What i know, t5 is censored, thatswhy nobody could make a porn model.
@nutbutter Sounds neat. I'm hoping flux doesn't end up a dead end. It seems to have some issues taking to nsfw training. But if anyone can do it, it will be you.
@null It seems, there is a breakthrough in Flux.
Impressive work and very influential in the new generation of SDXL checkpoints like Biglove and others. This work totally made an impact in the community.
Do you have plans for a BigASP3 next year or it's the creator's vision already fulfilled? Just asking out of curiosity.
Thanks for your invaluable work!
Thank you. Yeah I'm looking at basing the next version on a next gen model like Flux or something.
@nutbutter Oh thank goodness! I am glad to hear! Hoping you can find a way to include certain conceptual knowledge from anime sources without letting the anime contaminate the model's photorealism... Hopefully you can find a way to overcome the issues flux trainers seem to be having. Seems like the more they train them the worse they get, and they still can't seem to make decent looking clams. If anyone can do it, it's nutbutter.
this is only good for txt2img not img2img right? I havent had any good results so far with img2img
It works for both, but it excels far more in txt2img
@faketitslovr thanks for confirming it !
Pony/Illustrious/NoobAI concept use tip:
I have a tip for anyone looking for the amazing quality and knowledge of BigAspV2, but that wants to add conceptual knowledge of an anime-based model.
Pick a realistic anime merge that you know does "ok" with what you want (it can be done with fully anime models, but it's hit or miss). My go to is pornmaster pro noob v2 (no longer on civit , but can still be found on huggingface). You'll set that as your primary checkpoint. Use "realistic photo" in your positive prompt (negative prompts probably not needed).
You'll use bigaspv2 as a refiner. Total steps:40. Switch to refiner one third of the way through. dpm 3+sde.
Some concepts will be known differently by different models. Spamming a bunch of similar-meaning words until you find a combo that clicks for both models can work wonders. Or you can use [ first model prompt : refiner model prompt : step at which prompt will switch ex 23 ] Brackets and colons are imperative to get right.
It turns out you can have much of the wild concept knowledge of an anime model with the photorealism of BigAspV2, it just takes a few more steps.
Try it out!
Update: Pornmaster pro noob V1 (uploaded Dec 26, 2024) is the new recommendation. It seems to serve as a conceptual key to turn bigasp v2 into an even better model.
@nutbutter I've found that the pornmaster pro noob v1 model seems to unlock amazing latent information in your model. It will cause bigasp V2 to produce far better quality outputs if I use bigasp as a refiner. It does even small details very well and seems to boost realism and range of ideas quite amazingly, and in a way that no other model comes close to (I've tried MANY). I know that with bigasp v1, there were amazing abilities latent if you didn't use the photo_\(medium\) and score tags, but so far I haven't been able to figure it out with bigasp v2. Can you give some tips maybe? Something I'm missing in the n-gram list or anything? Anyway, thanks for the invaluable models.
I'm not sure what I'm doing wrong, but my results are far from the ones shown here. They're actually horrible, like between early SD1.4 body horrors at worst to SD1.5 garbage outputs at best. Not to mention 3 out of 4 times the prompt (usual Booru prompts) is largely ignored.
What I think is particularly weird is that even when I try to recreate any of the photos shown here by using the same parameters, I'm getting different (again garbage) results.
I'm using a simple SDXL workflow (without refiner, just model+vae+pos/neg conditioning to ksampler to image) to try and figure out what the issue is, but haven't figured it out yet. I've tried entering the various words in the prompt mentioned here (photo (medium) and the score tags), but no luck :/ I've also tested with the recommended samplers, both Karras and Exponential give substantially worse results than Normal.
I'm not having any issues with other models in general.
I'm convinced there must be something at my end, but I have no clue what it might be.
post a workflow JSON or catbox PNG link if you have one, hard to diagnose otherwise
@jtabox If you're using v1 bigasp, then you will get rough output without correct syntax for the preamble. Certain UI's require this format: photo_\(medium\), score_7_up, whatever else. And then the usual score_1, score_2, score_3 in the negative prompt.
Bigasp V2 should not be giving you that kind of trouble and isn't as particular. It's possible there might be an issue with your UI or the model you downloaded was corrupted? If your UI hashes the model, check that against this site's hash for the model to see if that is the issue.
@null or maybe its possible, Bigasp is a pile of crap, with ton of shit quality datas.
@traceydario392 BigAsp V2 is the best model out there right now. It's user error or UI issues if you're not getting good outputs.
@traceydario392 I mean I've asked several people in these comments to just like, provide an actual example image with workflow (which would make it immediately clear what their problem was) so far nobody has done it lol. You can't really troubleshoot this kind of thing properly without examples.
Same things man
@traceydario392 No, it's very good but does require learning how to prompt for it, every model has it's nuances and character to it, to get the best out of it you need to learn its quirks before passing judgement, you can't just copy paste a prompt/workflow from another model into a model like this and expect similar results.
Sorry, I've been away from my home PC, will try to find some of the creations to post when I'm back in a couple days.
this model is a disaster I would say very bad the worst SDXL I'm sorry
Its really good for amateur slut generations. If you want generate dreamgirls, like me, its not your model:)))))
Give me the proof in image with their real data, I'm not stupid ;)
@radela Yeah, thats what i want too. There is no data. No real girls, no party.
@emricmaysin118I see you share no image of the shot I banish you
stop lying to you find me a great quality photo with its actual prompt data. no pictures post here to prove the opposite to be unstopmable but this checkpoint is bad ;)
@manangraeson363 an error :) :)
@radela Actually post one image with this model and I can guarantee I'll be able to tell you WHY it's bad lol. Beyond that, looking at your profile quickly you're the sort of person who unironically writes rambling broken english gibberish prompts like the following, which would certainly explain some things lol:
"Full view The most beautiful girl in the world (age 20 years old) cute,irresistible,a pretty (flaccid big penis Big gland ), (testicles), toned abs, wearing loose model PonyXL and xpenis-v2.13"
@emricmaysin118 You share zero image and you're a liar shows us saying your work...??
And who said cubism was an antiquated art form?
Is is possible to use this with the Lightning lora?
Works even better with dmd2 lora, use lcm sampler and simple scheduler, 6 steps, cfg 1.0
nice upload thanks
Like an ameteur porn reddit sub.
Nobody share their prompts, not that the women would be slightly good looking.
Absolutely, this gatekeeping is nasty business. Sharing is caring afterall
both of you have empty accounts. cry more. cope seeth. pathetic groomers
If you think that's all that's in it you clearly haven't tried very much lol.
@axicec ??? I may be a horndog but I always post my workflow and prompts with the images, loras, embedding, nodes, everything. I am not crying, just agreeing with the OP. It seems that your profile is saying the same regurgitated stuff you posted here. Why are you so salty and passive agressive ? Who hurt you? And what is a groomer anyway?
I want to train this model to always generate a specific girl (I have tons of pictures of her). I'm new to this, can someone explain how to and how many pics I need? I heard I need over 1,000
uh, you just train a Lora on it lol. You absolutely don't need 1000 images lmao, for like 35 - 50 well-captioned ones is enough.
Am I missing something here? Is this only for ComfyUI? I tested it with A1111 and wasn't able to get anything good and I've read other comments about people following the instructions and not getting anything good, plus seems to me like all the good images uploaded here were made in ComfyUI or don't have info at all.
If it is, that's fine, I'm actually getting into ComfyUI now, just want to know so I don't waste my time with it when using A1111 👀
I would definitely recommend ComfyUI since it allows the use of Perturbed Attention Guidance, which can improve the reliability of bigASP. But the model does work in Auto: https://civitai.com/images/36552237
I'm in an older A1111 install and have had no issues.
@nutbutter I thimk it might be a case of "Clip Skip" actually mattering for this model for whatever reason, which is more of an issue in Automatic1111 where that option is always there (whereas in Comfy there's just not actually any reason to use the "Clip Set Last Layer" node for any SDXL model at all, since that setting SHOULDN'T do anything for any XL model, like you're supposed to train with it set to "nothing" as opposed to 1 or 2 I guess for XL)
@ZootAllures9111 yeah, from what I've read that's why I'm waiting until I get some time to mess around with it in ComfyUI. Sure, it seems it can work in A1111 but I'm guessing since ComfyUI having less "clutter" out of the box it might work best. I'd guess most people complaining here about bad quality are using A1111 or Forge (haven't used it but I've been told it's very similar to A1111)
@DynamiteJoe I tried using this model and have only been getting burnt out images, don't know what I am doing wrong
@dereaperr Honestly, haven't had a chance to test it a bit more but are you using the recommended settings? For example, this one uses a much lower CFG (2-3) than most models (7) and burnt out images is one of the effects of having CFG too high.
@DynamiteJoe If the issue is indeed the Pertubed AG then you can just use Forge, which has it built in.
@DynamiteJoe Forge is indeed very similar because it is a fork and it supports Pertubed AG as nutbutter mentioned could be the cause
You gotta raise the resolution to at least 1024x1024, otherwise youre gonna generate bullshit
updated torch then nothing work literally , same png with work flow give noise!. this question for OP.
aslo is it capable for dmd2 , lcm sampler ? again , everything was working fine dmd and lcm then after update nothing output except noise..
Any way you might be able to upload full precision 12gb models of these asp models?
Either people are just taking actual photos or hiding their prompts it seems.
The Version here seems broken. Download it from Huggingface: https://huggingface.co/fancyfeast/big-asp-v2/blob/8a9ee68352b0cccce5280921ee867a333b4a23b4/cuwm1gxo-complete-20241024a.safetensors and it works for some strange reason (Tested today with ComfyUI directML)
@illiminator31 This definitely isn't the case TBH
@TheArchitext I mean they're visibly not lol. Anyways try this as a general prompt format:
positive prompt:
score_9, score_8_up, score_7_up, INSERT NATURAL LANGUAGE OR TAG PROMPT FOR WHATEVER HERE, photo \(medium\)
negative prompt:
score_1, score_2, score_3, score_4, score_5
This is essentially the format I've used for every image I've posted to the gallery, I think. Beyond that I generally use "DPM++ SDE GPU" as the sampler and "Normal" as the scheduler, in ComfyUI, at around CFG 5.
@ZootAllures9111 Yes you are correct. After further testing I seen, that for some reason I had a different SHA256 everytime. However I still could Import the Model in ComfyUI it would just produce strange results.
I suspect a Data Transfer Issue with my ISP to be the reason for it
@kainenradek541 I think it's basically because those anime-models are objectively more promptable, flexible, and handle greater diversity and flexibility (while unfortunately being less capable in realism). You can very clearly lay out with exceptional accuracy exactly what you want and have it produced. They are trained with the booru tags that humans input for the source data, while Asp is trained with AI generated captions.
I think there is a huge amount to be gained if a BigAsp V3 would be trained in some way on anime/cartoon/booru content without poisining the model's exception photorealism. I wonder if it's even possible to do. It'd be pretty wild to have an pony/illustrious/noob capability with the realism of Asp.
@TheArchitext In most cases, you just need to drag and drop the image into comfyUI and the whole workflow will populate, but yeah sometimes ppl remove metadata.
@null And who would tag the pics one by one? Booru datasets are already tagged.
@benjamynwasim444 No need to tag one by one. Just use booru pics. If a way can be found to have the model learn the concepts without poisining the photorealism, it's a win for everyone. I think we all want a pony/illustrious/noob smart model, but with full 100% realism in appearance like asp offers.
@null Yes, we want. What i heard Pony7 can do realism out of box. With finetuning, we will have an ultimate model.
Bigger sysreq though. But qquf can run, like flux.
please, anyone have an example workflow i'm lost
Drag and drop one of the better pics from below into comfy.
@null I tried to do it with the pics that people share here but it doesn't work, there is no data
orka95 i would suggest use automatic1111, i tested it yesterday and it is a bit easy to set setting and genrate
@nutbutter Very interested to hear if you have any future plans for models! You make the best quality models, by far. Any consideration to HunYuan or Wan video?
Is there still a plan for a V3? Now you've got plenty of different models to try it on. The new Cogview4 seems like an almost equal model to flux although with an open license. And then there's the video models if you ever get into video gen
He should unironically just throw the unchanged V2 dataset at the Kolors UNET if you ask me before he does anything else, I've been experimenting with it recently and it learns exactly like SDXL but with the benefit of significantly better natural language support from ChatGLM (which you do not need to train at all, JoyCaption captions just against the UNET part seems to work great in my experiments).
@ZootAllures9111 It doesnt matter, how to train the model, if the dataset doesnt contain a single beautiful girl.
I seen on his hugingface (fancyfeast) that he is gather a breast cup size data selection, presumably for training! Maybe a feature for next Asp?
>seen on his hugingface (fancyfeast) that he is gather a breast cup size data selection, presumably for training! Maybe a feature for next Asp?
I noticed people wanting to use body measurements and cup sizes for more finegrained control. There didn't seem to be a good source of "ground truth" for that stuff, so I built a dataset for it. That will get trained into JoyCaption, which should hopefully make future iterations of bigasp understand that kind of stuff. How well it works remains to be seen :P
@nutbutter So you're going to make a V3 eventually? Still SDXL or?
@banditlevel200 Yeah, on one of the more recent base models. Don't know exact base model, I'll do some test runs and pick one.
@nutbutter There's a model trainer named @AbstractPhila that has created a model that's properly capable of both anime and realism using combined training data. Maybe consider check out their "NOOBSIM" model's page or ask them about their training? They're using some kind of multi-level wizardy using V-pred and timesteps or something. (try the model, don't go by thumbnails on this one). Would be crazy good to include a noob/illustrious level of knowledge with a future Asp.
Anyway, the noobsim models are proof positive that anime concepts can be mixed with full photoreal without damaging anything, when done properly. Just figured I'd toss out the suggestion if you're interested. I almost missed the author's work entirely in the sea of thumbnails and bad pony merges.
I read your article about making ASP, such a big work.
But hands are fkd as hell, it looks like regression to SD1.5. And this "feature" of all home trained models.
I run model through the list of concepts and it is completely out of understanding anything except porn tags. Well known porn logos popping up all the time. It absolutely useless as normal checkpoint. Same time it can do naked females pretty well.
In general It is awful and same time kinda cool to observe, what next it will draw.
PS I had an idea, what if it short tags not working but long AI generated tags will work? (as author used JOY tagger) - And indeed, if use long AI generated prompts, checkpoint start to behave more like normal, it outputs what is expected.
bigASP can be quite temperamental. V2 is an improvement over V1 in that regard, and I hope to continue to hammer it down for V3. Captioning will continue to improve as I work on JoyCaption, and I have tweaks to the training process planned for the future. And more diverse data to help flexibility.
As a side note, I trained https://huggingface.co/spaces/fancyfeast/llama-bigasp-prompt-enhancer to help with "what if it short tags not working but long AI generated tags will work". It can be used to take a prompt and re-write it like the captions bigASP was trained on. It can generate random prompts, for fun. Or you can tell it what kind of image you want and it will write a prompt.
I don't know how much it helps wrangle bigASP, but it's an experiment worth trying. And I suspect the prompts it writes can be used with other models.
I dont know. Maybe less and cleaner dataset would be better, than just throw in everything.
@nutbutter with my Loras of specific people I've released for V2 so far, I found that captioning every image simply with JoyCaption natural language output first and then booru tags from wd-eva-02-large-tagger-v3 second, just like concatenated in the same file one after next, works quite well. I'm not sure that this is exactly how the model itself was captioned though? Like did you use ONLY tags for some, and ONLY natural language for others? If so that might be where some of the weirdness comes from, it's almost certainly going to be better to just have the full two prompting styles on every image, as far as I can tell.
@davidphillips the only note I have is that I personally don't agree that the author's recommended generation settings make any sense. I have no idea how he's getting good results with that crazy low CFG and the particular samplers he mentions. I find mostly that DPM++ SDE GPU (NOT 2M and NOT 3M) with a CFG of about 5.0 is a significantly better starting point. Beyond that I don't think there's anything wrong with the model itself.
@nutbutter Absolute legend Nut!!! This is absolute gold for Big ASP / Big Love etc.... works a treat, thanks for all you do for the community, amazing work!!!
This model makes grids almost by default sometimes, like the author trained it in a CLIP-like way. Has anyone found how to prompt this functionality?
What do you mean exactly?
TRES BON !!
I was considering this project a flop. Until I read in description its captioned with joy. So I've used some florence and results are insane good!
Does this model support ControlNet? I tried to use the diffusers_xl_depth_full depth model in A1111 but it would greatly mess up the color. The picture would just turn grey and blurry.
Try with a low CN strength (0.4-0.6), also try using mask and masking part of the image (even most of it if you want, I find this helps). Also try other CN models. For Depth I usually use "controlnet-depth-sdxl-1.0-small" so maybe look for that.
good
Has any recommended workflows for 12GB? for the most realism*
Drag and drop a few of the best user-posted examples from below into comfy. Also, user RaymondLuxuryYacht has a good workflow available that does pretty well with Asp2.
@nutbutter Are you working on a V2.5? I saw your HF was updated with a new version of Asp2? Very xciting
Can U share the link?
@P_Universe Actually, I checked. It was seemingly a reupload of the same files, sadly. The hashes that I randomly crosschecked against the original Asp2 were the same. HF username fancyfeast
@misterpoobiepantzer585 oh well that's a shame , I guess we will wait a lot till a new version yet, thanks tho
@P_Universe Think he may be prepping to do another one soon. Had mentioned plans a few months back. Looks like he is doing work on captioning and language models etc etc that might lead to another asp. Am hopeful. Have you discovered any esoteric formats or prompts for asp2?
@null not really, I just usually put score_7_up and then going straight to natural language
Sorry, that was just me fixing the repo so HF libraries can import it properly. Just tinkering with things for the next bigasp right now. I've got my head around the newer generation of models and did some flow-matching training. Also collecting more data. Likely target will be SD3.5. Maybe Flux, but it's less straightforward to train. HiDream looks to be very nice, but the model is huge which would make it extremely difficult for me to do a real finetune on it.
@nutbutter There is a model called "beatrix" (SDXL) from abstractphila that was recently released. The photorealism is not quite 100%, but can be prompted pretty darn close (better than many realism models) with the right prompt wrangling (while retaining full anime abilities). They managed to weave like half a dozen of the major models together into a super-model that retains a huge percent of the knowledge of its constituent parts. I know the sample images look bad (not sure why the author did this), but if you play around, you'll see it's better than 99%+ of models on this site. It is truly amazing for asp-adjacent things (ahem)... Maybe your excellent skills could tune it to full photorealism? It might take a lot less work than a full asp. (just a dream of mine, sorry for the beg)
Also, can I ask you is there a way to use CLIP in your Asp2 model (new to the idea of it and might have the concept wrong)? I often get grids of images, and was wondering how to make the subject of the grids full size instead of a lineup or collage. I also notice the model responds different to "nude," "naked," and sometimes extremely different to "she's not wearing any clothes." Do you have any other tips on similar words or phrases that might produce tasty outputs?
@nutbutter "HiDream looks to be very nice, but the model is huge which would make it extremely difficult for me to do a real finetune on it."
Is it because it would be more expensive?
I cannot get this thing to render a damn thing correctly... Wondering if it's my forge or the chkpt?
Use one of the merges or use it with dmd2 sdxl 4 step lora. Or else you'll really easily get mangled outputs
@jospp score_7_up in the positive prompt works wonders.
pos: score_7_up,
neg: score_1, score_2, score_3
for HQ photos: "a photo \(medium\) of"
for cinematics: "a cinematic film still of"
@nutbutter How to prompt clip grids in asp2?
@nutbutter Thanks for the model. If there are any other versions, finetunes, or originals of asp 2, is there any chance you might be able to upload them to hf now that you are moving on (probably) to asp 3? I would really like to collect them... The more jpeg artifacts and multiple images the better, uwu. (not joking, I've gotten improvements using source jpeg artifacts in my positive prompt depending on what I'm trying to make asp2 produce, any ideas to help out would be great)
I have recently ran into a problem that when inpainting with bigasp 2.0 the faces become the standard plastic AI looking skin ones. I have tried fiddling with all the settings, but no luck. I wonder what could have caused this and if anyone is experiencing similar issues?
Booru prompting without the understanding of booru poses.
You should have caption poses with danbooru tags.
what do you mean?
@ZootAllures9111 Prompting poses with booru is superior to any normal language. You get perfect poses easily with 2-3 tags.
https://danbooru.donmai.us/wiki_pages/tag_group%3Asex_acts
Pony, Illustrious works with these tags, thatswhy its too easy to get perfect pose.
@jamesluke609 This model is only trained on actual photographs keep in mind. Anything that isn't as heavily done or photographed in real life isn't going to work as well in this model.
Hello dear friends. I am new to lora training (SDXL, Flux I am good at) and trained a character lora on this model as the base. It's not so good compared to my flux lora, it hasn't learned the character well. How many epochs would you reccomend ? Or is it just not a good model to train a character lora on ? Any advice ? Is this a peculiarity of this model that it needs more epochs to drill my character into ti ? Thank you kindly.
I find it gives very good real person loras personally if you use hybrid natural language / booru tag captioning. As for settings, a good starting place for single-subject BigAsp loras is like, the default "Pony" settings in the CivitAI trainer but batch size 2 instead of 5, and like not necessarily the same number of repeats / epochs. (I personally NEVER use repeats, it is not the same thing as having a single repeat and more epochs, and like the way people use repeats isn't even what it was meant for at all, duplicating dataset images the way it does gives very different results than just having more epochs).
@ZootAllures9111 Thank you, will do. 1: more epochs less repeats 2. booru tag + natural. There were no booru on my tries, only trigger and background elements and anything I want to change on the character. I will do a run and remove the background completely only leaving the subject and a white bacgkround + only using one tag, the trigger word (apparently this worked for someone when training on lustify). Let's see what happens !
quite hard to use, i'm using dmd2 lora (when fewer steps works, its painful to work the old way). had to lower cfg to 0.7 using LCM+Karras, produces good result, but there aren't many model that produces bad result nowadays. Left some of my best generation with workflow embedded. For now i'm not keeping this model, i'm searching for ones with good scenery or landmark for my "fake holiday trip".
here is the thing, bigasp needs alot of experimentation BUT what it rewards you with is extreme versatility and variety. So yes, there easier models (Lustify comes to mind, it's highly stable) but bigasp is amazing and unique for it's qualities
@kunde2 dmd2 is what makes it hard in my statement. given normal situation its great and works wonder when used with sdxl power prompt node (rgthree, which separates clip L for minor detail and clip g for strong concepts, but if used together with dmd2 4 steps lora (distilation model), 4-8 steps definitely not enough to let that prompt expand latent noises into detailed image. typically with my current workflow that carries ipadapter and dmd2 lora, which sometimes pushes the boundary of sub cfg 1 . Even using dmd2 lora at 0.2 strength still shorten the steps to 16 max. With that in mind, more obedient models that interbred (mix or train) with bigasp base is usually easier to use (for its prompting benefit). i think i shouldv'e left my generation here. i did get a good result, but the painstaking effort to make it happens sometimes just make most take the easier way around.
Edit: Yup, i saw my generation using this model, and its definitely great (if i may say so, at least i'm proud and extremely thankful for nutbutter to let me try and review his/her work).
Note: My generation (.png ones) is embedded with the workflow to recreate it, there are comments too useful or not, it should be my v2 workflow
@menyan1381 I think you maxed out regarding good looking protagonist. But anything else is shit. Background looks like bad photoshop, not even good realism(which is at least surprising), we see nothing, what you can achive with poses.
Better to stick to Biglust, BigLove and Lustify.
Anyway, if this base would have gotten so much love, like Pony, Illustrious we could select from much more good models. Lack of loras is a big handicap also.
@graytonjaco779 lol, that's why i said its hard. if you mean my workflow, then everything within (double undrscore)<name>(double underscore) is a wildcard, and if you don't have the respective file, you can change it into anything imaginable. It's just part of the sharing (it works well with other models though) feel free to remove/change/modify anything you like, if you leave the base parameters intact, you should still achieve similar result
Is there gonna be a BigAsp3 for sdxl? just asking out of curiosity.
I hope so personally, I still think there's room for improvement like dataset / captioning wise, he definitely hasn't "maxxed out" SDXL yet.
@ZootAllures9111 SDXL is far from being "maxxed out" in my opinion.
@electricdreams BigAsp 2.5 is out now on "fancyfeast" huggingface page.
does not seem to want to work in forge. has anyone else tried this?
kunde2 it doesn't. It's on the description: it only works on Comfy.
Still one of the best models out there, in terms of flexibility. A lot of model merges, even with BigASP, may more readily produce good results, but often lose flexibility. Hope we get a V3 eventually, with an even larger dataset and better captioning.
Hi there @nutbutter. I'm currently unable to try out your latest (probably freaking amazing) model, asp 2.5, due to my hardware being inoperative at the moment (I sadly lost all of my models and gens, too). I was wondering if you could be so kind as to keep all of the iterations of finished product available, even after further refinement and training? I would some day like to try the July 16th version in addition to whatever further training you might do on it (when/if my situation permits in the future).
Also, I hope that IF the incoming (effective date the last day of July) Stability AI "terms of use" (or whatever they are called) cause such amazing models to be removed from civit and HF, that they will still be found somewhere else for the benefit of the many. Your work is foundational to this hobby, and greatly appreciated. Thank you.
Yup, I'll try to keep the versions available. Best of luck with your hardware <3
nutbutter Thanks m8!
👏
Hi nutbutter, do you think this checkpoint is finetunable? My target domain is buildings, facades, houses, skyscrapers etc etc.
Thanks!
I'm a big admirer of your work on the ASP v2.0 checkpoint; I'm aiming to use it as a base for my own style training via Dreambooth, but I have a question about captioning my dataset specifically for your base model.
My goal is to teach the model a distinct male-centric style, using a dataset of around 2,000 photos that include fashion and general-interest themes (mildly NSFW). Importantly, I'm not looking to reproduce specific individuals, but rather to teach the model a new generalized look and feel regarding faces, bodies, and backgrounds for style.
I've read in your paper that you posed on Reddit, but could not find an answer for my question.
My current captions are more like this: 'male focus, a young man, construction site, shorts, tank-top.'
Considering you trained ASP v2.0 on millions of images with detailed captions, for my goal of pure style training, would you recommend:
Continuing with simple, descriptive generalized tags? If yes, are there specific tags that you would recommend adding regarding male-centric themes?
Or another method entirely? Maybe more detailed captions?
Any advice would be very helpful. Thanks!
Your best bet is to try both approaches. Do a run with tag strings, and a run with detailed captions, and see which one performs best for you. Lora training is generally fast and cheap, so it's well worth experimenting and trying different approaches.
JoyCaption, the captioning model I use for bigASP's dataset, is built to generate a variety of captioning styles, so that should also make it easy to experiment.
But honestly, I don't have a lot of experience training loras, so I'm not the best person to ask. SubtleShader has far more experience than I do on that side of model training.
Someone has a setting for dmd, which works without oversaturation, overburning?
It shouldn't be doing that too much assuming your cfg is at 1 but indeed in general I do find compared to other models it is closer to the edge of oversaturation, depends on the prompt of course.
I'd try the LCM_Turbo lowers with DPM as an alternative, its typically used at 10 steps but works ok at 4 steps too I find.
I have a question: how do I train a LoRA to understand both natural language and tags within the same LoRA? If I want my LoRA to adapt to both styles, how should I create my .txt files?
I did this in the past, I'm not sure:
first line: natural tags for sdxl
second line: ponyxl tags
I'll take longer to train but I think it works for both
whats the update for bigasp 2.6
Any typo or unclosed quote in prompts produces anime, prompts are hard to zero in. Otherwise a versitle and very usefull model.
This is incredible. Bless you.
It seems to completely fail with the DMD2 Lora at strength 1, where 45 other tested models work fine. Any ideas why?
This is trash, a generator of blurry multiframes with grotesque mutants...
PEBKAC
@CuteCaption This. there is no question this model is more finnicky and can go wild compared to 'common' models, this is just user error and not understanding how to best prompt this model.
Never able to get good results with bigASP checkpoint models. Every single one of them. Idk what i'm doing wrong but this ain't it.
Any Klein or modern version coming? I would pay for this!!
Details
Files
bigasp_v20.safetensors
Mirrors
bigasp_v20.safetensors
bigasp_v20.safetensors
bigasp_v20.safetensors
bigasp_v20.safetensors
bigasp_v20.safetensors
bigasp_v20.safetensors
bigasp_v20.safetensors
bigASP.safetensors
bigasp_v20.safetensors
bigasp_v20.safetensors
bigasp_v20.safetensors
bigasp_v20.safetensors
bigasp_v20.safetensors
bigasp_v20.safetensors
bigaspv2.safetensors
bigasp_v20.safetensors
bigasp_v20.safetensors
bigasp_v20.safetensors
bigasp_v20.safetensors
bigasp_v20.safetensors
bigasp_v20.safetensors
bigasp_v20.safetensors
bigASP_v2.0.safetensors
Available On (1 platform)
Same model published on other platforms. May have additional downloads or version variants.