STATEMENT OF INTENT
My workflow itself and example videos that are clearly SFW have been unfairly blocked by Civitai moderators. If this situation continues, I will leave Civitai and migrate to Hugging Face.
Important Notice
Optimized to work with the latest version of ComfyUI (v0.18.1 + Frontend 1.42.8).
The latent upscaler ltx-2.3-spatial-upscaler-x2-1.1 has been released.
Version 1.0 had an issue where a strange overlay appeared at the end when generating long videos (241F+), but this has been fixed in 1.1.
Updating is strongly recommended.
Overview
A simple LTX-2.3 Video-to-Video workflow.
You can choose the reference from the original video using Depth, Canny, or OpenPose (default).
An inpaint Edit Mode has been added. You can "add," "delete," and "replace" elements using prompts (it's not universally applicable).
How to Use
• Motion Track Mode
Set Enable Motion Track Mode to yes and disable bypass.
Set Edit Mode to false.
Load the start image you want to animate.
Load the source video for tracing.
Specify a simple prompt (examples: comic style, dancing).
• Inpaint Edit Mode
Set Enable Motion Track Mode to no and enable bypass (not strictly required, but otherwise unnecessary processing will occur).
Set Edit Mode to true.
Load the video you want to edit.
Specify the edit in the prompt.
[Add]
Add a/an [subject/object] with [clear visual attributes], [precise location in the scene].
[Remove]
Remove the [subject/object] [location or identifying description].
[Replace]
Replace the [original subject/object] [location] with a/an [new subject/object] with [clear visual attributes].
[Convert / Style]
Convert the video into a [style name] style.
Description
v1.1 : Fixed an issue where style could not be changed.
v1.1.1 : Resolution issue fixed.
v1.1.2 : Fine-grained optimization.
FAQ
Comments (14)
RuntimeError: The size of tensor a (2304) must match the size of tensor b (303616) at non-singleton dimension 2
Number in brackets above keeps changing as I try different resolutions.
What are the settings for the grouped nodes for ltx2.3v2v? The width and height is set to 1 on load, however you can't set it back to 1 if you try to change them.
I fixed the issue. The IC-LoRA node ultimately requires that the latent size (n / 32) be divisible by 2. For example, (768 / 2) / 32 works, but (480 / 2) / 32 is not divisible, which causes an error. Therefore, I modified it to round down when it is not divisible by 2. Naturally, when rounding down occurs, the output video size becomes smaller than specified. This is unavoidable.
However, what do you mean by "The width and height is set to 1 on load"?
@javawock7618 on initial load of the workflow, the ltx2.3v2v group node width and height is set to 1.
I tried setting every possible size combinations that are divisible by 2 like 768, 512 square, rectangle combinations, same error. I set the sizes for the initial reference image, video, and the group nodes LTX-2.3 v2v.
SamplerCustomAdvanced
The size of tensor a (10368) must match the size of tensor b (1335808) at non-singleton dimension 2
@chud1 What versions of ComfyUI and ComfyUI Frontend are you using? Are they the latest versions?
@javawock7618 ComfyUI: v0.17.2. I remember recently downgrading the frontend to a version that didn't mess group nodes, so not the latest. It shouldn't matter because I'm setting up the dimension values?
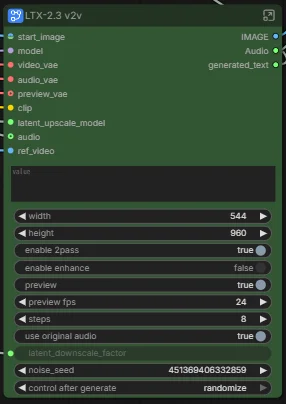
@chud1 I’ve uploaded a screenshot, so please take a look. First, as a prerequisite, check whether the default values for LTX-2.3 v2v are displayed like this. If they are not, this workflow will not work in your ComfyUI. Alternatively, update the frontend to version 1.42.8.
@javawock7618 the screenshot seem to have failed to be uploaded here or your profile. When I updated all in ComfyUI to the latest version, I encountered the same error, try different references with different sizes to make sure it wasn't the references. However, all defaults settings are properly loaded now like the dimensions 1280x768.
@javawock7618 I recently followed the settings you showed (544x960) and it shows a different error now: Add Video IC-LoRA Guide ValueError: Latent spatial size 8x15 must be divisible by latent_downscale_factor 2.0
@chud1 I was able to generate a dancing cat in my ComfyUI without any issues. I don’t know what kind of environment you’re using, which reference images or videos you’re trying to generate with, or whether your custom nodes are up to date. Therefore, I can’t troubleshoot this any further.
I appreciate your interest in my workflow, but it would be better for you to look for another v2v workflow that works with your ComfyUI setup.
@javawock7618 Thank you very much for the help and workflow. It narrowed the solution. Tried res with width and height divisible by 32 to fix ic lora error, and for tensor mismatch: the fix here from Carloschi1994: https://github.com/Comfy-Org/ComfyUI/issues/11653
credit Google AI mode:
If you have the ComfyUI_smZNodes custom node pack installed, it hijacks how ComfyUI prepares noise. It is currently incompatible with LTX-Video's nested tensor structure.
The Fix: Go to your custom_nodes folder and delete or move the ComfyUI_smZNodes folder. Restart ComfyUI and try again.
got oom with my 12gb vram and 64gb ram, what node or settings should i improve to make it work? :)
i can generate 25 sec ltx i2v and t2v and never got oom with other workflow.
This workflow needs to load a reference video, so it requires more memory than normal generation. If possible, use a smaller GGUF such as Q5. Also, I think your only options are to lower the generation resolution, for example 960*544 instead of HD, or shorten the generation length, such as 5 seconds.
Any instructions on how to use this would be very appreciated. Currently it just makes an openpose wireframe video, I cant do anything else without some guidance.
I've added usage instructions to the overview, so please check it.