You don't need to download anything, this is a guide with online tools. Click "Show more" below.
You can find an updated version of this guide in my new website, a comfy place where experienced AI artists and model creators can share their work.
🏭 Preamble
Even if you don't know where to start or don't have a powerful computer, I can guide you to making your first Lora and more!
In this guide we'll be using resources from my GitHub page. If you're new to Stable Diffusion I also have a full guide to generate your own images and learn useful tools.
I'm making this guide for the joy it brings me to share my hobbies and the work I put into them. I believe all information should be free for everyone, including image generation software. However I do not support you if you want to use AI to trick people, scam people, or break the law. I just do it for fun.
📃What you need
An internet connection. You can even do this from your phone if you want to (as long as you can prevent the tab from closing).
Knowledge about what Loras are and how to use them.
Patience. I'll try to explain these new concepts in an easy way. Just try to read carefully, use critical thinking, and don't give up if you encounter errors.
🎴Making a Lora
It has a reputation for being difficult. So many options and nobody explains what any of them do. Well, I've streamlined the process such that anyone can make their own Lora starting from nothing in under an hour. All while keeping some advanced settings you can use later on.
You could of course train a Lora in your own computer, granted that you have an Nvidia graphics card with 6 GB of VRAM or more. We won't be doing that in this guide though, we'll be using Google Colab, which lets you borrow Google's powerful computers and graphics cards for free for a few hours a day (some say it's 20 hours a week). You can also pay $10 to get up to 50 extra hours, but you don't have to. We'll also be using a little bit of Google Drive storage.
This guide focuses on anime, but it also works for photorealism. However I won't help you if you want to copy real people's faces without their consent.
🎡 Types of Lora
As you may know, a Lora can be trained and used for:
A character or person
An artstyle
A pose
A piece of clothing
etc
However there are also different types of Lora now:
LoRA: The classic, works well for most cases.
LoCon: Has more layers which learn more aspects of the training data. Very good for artstyles.
LoHa, LoKR, (IA)^3: These use novel mathematical algorithms to process the training data. I won't cover them as I don't think they're very useful.
📊 First Half: Making a Dataset
This is the longest and most important part of making a Lora. A dataset is (for us) a collection of images and their descriptions, where each pair has the same filename (eg. "1.png" and "1.txt"), and they all have something in common which you want the AI to learn. The quality of your dataset is essential: You want your images to have at least 2 examples of: poses, angles, backgrounds, clothes, etc. If all your images are face close-ups for example, your Lora will have a hard time generating full body shots (but it's still possible!), unless you add a couple examples of those. As you add more variety, the concept will be better understood, allowing the AI to create new things that weren't in the training data. For example a character may then be generated in new poses and in different clothes. You can train a mediocre Lora with a bare minimum of 5 images, but I recommend 20 or more, and up to 1000.
As for the descriptions, for general images you want short and detailed sentences such as "full body photograph of a woman with blonde hair sitting on a chair". For anime you'll need to use booru tags (1girl, blonde hair, full body, on chair, etc.). Let me describe how tags work in your dataset: You need to be detailed, as the Lora will reference what's going on by using the base model you use for training. If there is something in all your images that you don't include in your tags, it will become part of your Lora. This is because the Lora absorbs details that can't be described easily with words, such as faces and accessories. Thanks to this you can let those details be absorbed into an activation tag, which is a unique word or phrase that goes at the start of every text file, and which makes your Lora easy to prompt.
You may gather your images online, and describe them manually. But fortunately, you can do most of this process automatically using my new 📊 dataset maker colab.
Here are the steps:
1️⃣ Setup: This will connect to your Google Drive. Choose a simple name for your project, and a folder structure you like, then run the cell by clicking the floating play button to the left side. It will ask for permission, accept to continue the guide.
If you already have images to train with, upload them to your Google Drive's "lora_training/datasets/project_name" (old) or "Loras/project_name/dataset" (new) folder, and you may choose to skip step 2.
2️⃣ Scrape images from Gelbooru: In the case of anime, we will use the vast collection of available art to train our Lora. Gelbooru sorts images through thousands of booru tags describing everything about an image, which is also how we'll tag our images later. Follow the instructions on the colab for this step; basically, you want to request images that contain specific tags that represent your concept, character or style. When you run this cell it will show you the results and ask if you want to continue. Once you're satisfied, type yes and wait a minute for your images to download.
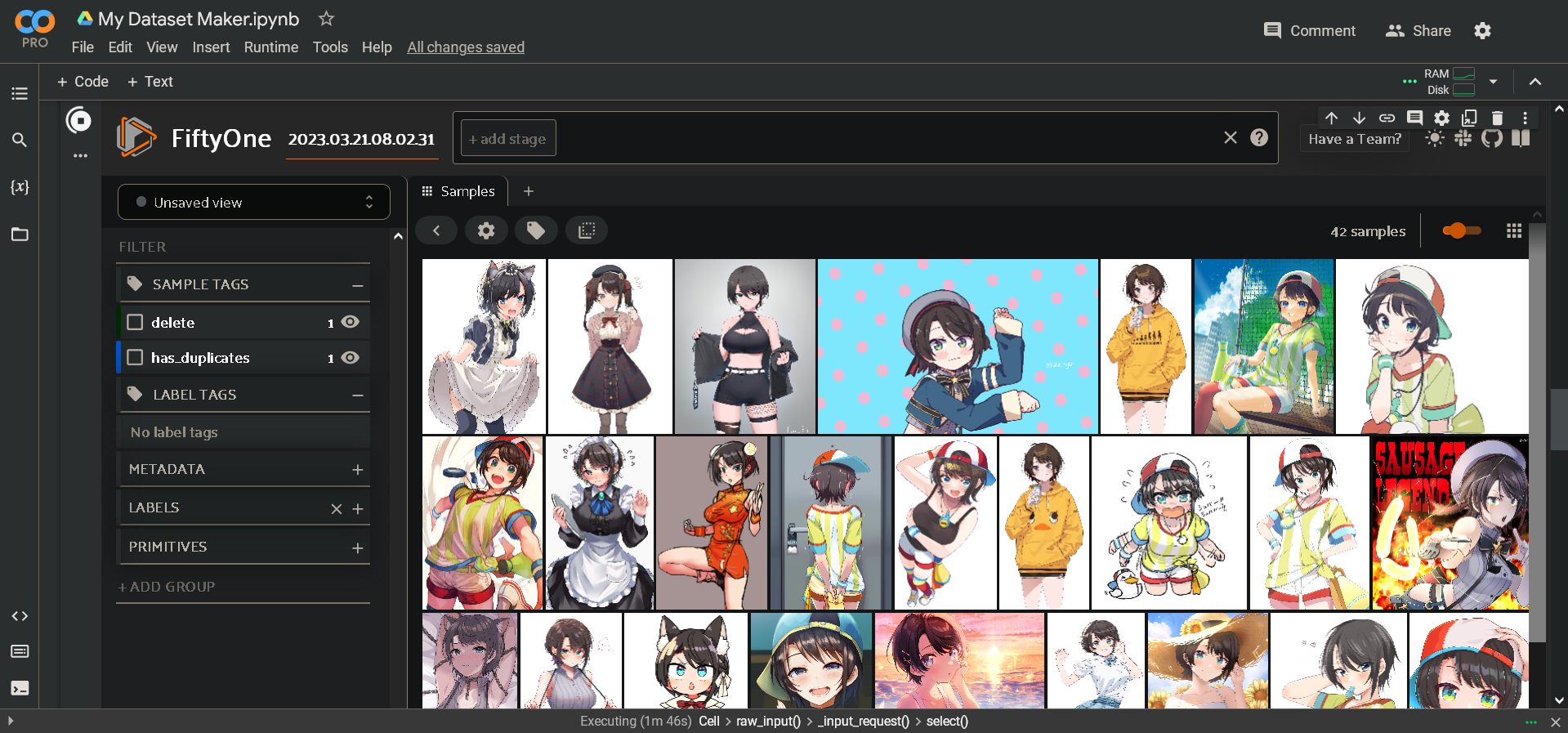
3️⃣ Curate your images: There are a lot of duplicate images on Gelbooru, so we'll be using the FiftyOne AI to detect them and mark them for deletion. This will take a couple minutes once you run this cell. They won't be deleted yet though: eventually an interactive area will appear below the cell, displaying all your images in a grid. Here you can select the ones you don't like and mark them for deletion too. Follow the instructions in the colab. It is beneficial to delete low quality or unrelated images that slipped their way in. When you're finished, send Enter in the text box above the interactive area to apply your changes.
4️⃣ Tag your images: We'll be using the WD 1.4 tagger AI to assign anime tags that describe your images, or the BLIP AI to create captions for photorealistic/other images. This takes a few minutes. I've found good results with a tagging threshold of 0.35 to 0.5. After running this cell it'll show you the most common tags in your dataset which will be useful for the next step.
5️⃣ Curate your tags: This step for anime tags is optional, but very useful. Here you can assign the activation tag (also called trigger word) for your Lora. If you're training a style, you probably don't want any activation tag so that the Lora is always in effect. If you're training a character, I myself tend to delete (prune) common tags that are intrinsic to the character, such as body features and hair/eye color. This causes them to get absorbed by the activation tag. Pruning makes prompting with your Lora easier, but also less flexible. Some people like to prune all clothing to have a single tag that defines a character outfit; I do not recommend this, as too much pruning will affect some details. A more flexible approach is to merge tags, for example if we have some redundant tags like "striped shirt, vertical stripes, vertical-striped shirt" we can replace all of them with just "striped shirt". You can run this step as many times as you want.
6️⃣ Ready: Your dataset is stored in your Google Drive. You can do anything you want with it, but we'll be going straight to the second half of this tutorial to start training your Lora!
⭐ Second Half: Settings and Training
This is the tricky part. To train your Lora we'll use my ⭐ Lora trainer colab or the 🌟 XL Lora trainer colab depending if you want to train for a SD1.5 model or an SDXL model. They are very similar, and they consist of a single cell with all the settings you need. Many of these settings don't need to be changed. However, this guide and the colab will explain what each of them do, such that you can play with them in the future.
Here are the settings:
▶️ Setup: Enter the same project name you used in the first half of the guide and it'll work automatically. Here you can also change the base model for training. There are 2 recommended default ones, but alternatively you can copy a direct download link to a custom model of your choice. Make sure to pick the same folder structure you used in the dataset maker.
▶️ Processing: Here are the settings that change how your dataset will be processed.
The resolution should stay at 512 this time, which is normal for Stable Diffusion. Increasing it makes training much slower, but it does help with finer details. (SDXL has a default of 1024)
flip_aug is a trick to learn more evenly, as if you had more images, but makes the AI confuse left and right, so it's your choice.
shuffle_tags should always stay active if you use anime tags, as it makes prompting more flexible and reduces bias.
activation_tags is important, set it to 1 if you added one during the dataset part of the guide. This is also called keep_tokens.
▶️ Steps: We need to pay attention here. There are 4 variables at play: your number of images, the number of repeats, the number of epochs, and the batch size. These result in your total steps.
You can choose to set the total epochs or the total steps, we will look at some examples in a moment. Too few steps will undercook the Lora and make it useless, and too many will overcook it and distort your images. This is why we choose to save the Lora every few epochs, so we can compare and decide later. For this reason, I recommend few repeats and many epochs.
There are many ways to train a Lora. The method I follow nowadays involves balancing these values to produce 250-1000 steps depending on the amount of images. Note that styles may need to train for more epochs with a smaller learning rate. If you're training in XL you need around half as many repeats. Here are some examples for XL:
10 images × 10 repeats × 10 epochs ÷ 2 batch size = 500 steps
20 images × 5 repeats × 10 epochs ÷ 4 batch size = 250 steps
100 images × 1 repeats × 10 epochs ÷ 4 batch size = 250 steps
1000 images × 1 repeat × 6 epochs ÷ 8 batch size = 750 steps
▶️ Learning: The most important settings. However, you don't need to change any of these your first time. In any case:
The unet learning rate dictates how fast your Lora will absorb information. Like with steps, if it's too small the Lora won't do anything, and if it's too large the Lora will deepfry every image you generate. There's a flexible range of working values, specially since you can change the intensity of the lora in prompts. Assuming you set dim between 8 and 32 (see below), I recommend 5e-4 unet for almost all situations. If you want a slow simmer, 1e-4 or 2e-4 will be better. Note that these are in scientific notation: 1e-4 = 0.0001
The text encoder learning rate is less important, specially for styles. It helps learn tags better, but it'll still learn them without it. It is generally accepted that it should be either half or a fifth of the unet, good values include 1e-4 or 5e-5. Use google as a calculator if you find these small values confusing.
The scheduler guides the learning rate over time. This is not critical, but still helps. I always use cosine with 3 restarts, which I personally feel like it keeps the Lora "fresh". Feel free to experiment with cosine, constant, and constant with warmup. Can't go wrong with those. There's also the warmup ratio which should help the training start efficiently, and the default of 5% works well.
▶️ Structure: Here is where you choose the type of Lora from the 2 I mentioned in the beginning. Also, the dim/alpha mean the size of your Lora. Larger does not usually mean better. I personally use 16/8 which works great for characters and is only 18 MB.
▶️ Ready: Now you're ready to run this big cell which will train your Lora. It will take 5 minutes to boot up, after which it starts performing the training steps. In total it should be less than an hour, and it will put the results in your Google Drive.
🏁 Third Half: Testing
You read that right. I lied! 😈 There are 3 parts to this guide.
When you finish your Lora you still have to test it to know if it's good. Go to your Google Drive inside the /lora_training/outputs/ folder, and download everything inside your project name's folder. Each of these is a different Lora saved at different epochs of your training. Each of them has a number like 01, 02, 03, etc.
Here's a simple workflow to find the optimal way to use your Lora:
Put your final Lora in your prompt with a weight of 0.7 or 1, and include some of the most common tags you saw during the tagging part of the guide. You should see a clear effect, hopefully similar to what you tried to train. Adjust your prompt until you're either satisfied or can't seem to get it any better.
Use the X/Y/Z plot to compare different epochs. This is a builtin feature in webui. Go to the bottom of the generation parameters and select the script. Put the Lora of the first epoch in your prompt (like "<lora:projectname-01:0.7>"), and on the script's X value write something like "-01, -02, -03", etc. Make sure the X value is in "Prompt S/R" mode. These will perform replacements in your prompt, causing it to go through the different numbers of your lora so you can compare their quality. You can first compare every 2nd or every 5th epoch if you want to save time. You should ideally do batches of images to compare more fairly.
Once you've found your favorite epoch, try to find the best weight. Do an X/Y/Z plot again, this time with an X value like ":0.5, :0.6, :0.7, :0.8, :0.9, :1". It will replace a small part of your prompt to go over different lora weights. Again it's better to compare in batches. You're looking for a weight that results in the best detail but without distorting the image. If you want you can do steps 2 and 3 together as X/Y, it'll take longer but be more thorough.
If you found results you liked, congratulations! Keep testing different situations, angles, clothes, etc, to see if your Lora can be creative and do things that weren't in the training data.
Finally, here are some things that might have gone wrong:
If your Lora doesn't do anything or very little, we call it "undercooked" and you probably had a unet learning rate too low or needed to train longer. Make sure you didn't just make a mistake when prompting.
If your Lora does work but it doesn't resemble what you wanted, again it might just be undercooked, or your dataset was low quality (images and/or tags). Some concepts are much harder to train, so you should seek assistance from the community if you feel lost.
If your Lora produces distorted images or artifacts, and earlier epochs don't help, or you even get a "nan" error, we call it "overcooked" and your learning rate or repeats were too high.
If your Lora is too strict in what it can do, we'll call it "overfit". Your dataset was probably too small or tagged poorly, or it's slightly overcooked.
If you got something usable, that's it, now upload it to Civitai for the world to see. Don't be shy. Cheers!
Check out my new website, a comfy place where experienced AI artists and model creators can share their work: https://arcenciel.io
Description
You can download a copy of the colabs from my GitHub page. This download is just a link to that page now.
FAQ
Comments (1221)
Showing latest 296 of 1221.
How does the information here change if making XL Loras? I can't seem to get any model to learn the character I'm trying to replicate.
The techniques are the same. You need to include more tags than in 1.5 for it to learn things properly (for example, sometimes the hair/eye color won't work without those tags). You can also increase the learning rate and/or train for longer.
@holostrawberry I see, so removing tags so they blend into the LoRa is a no go for XL?
@smurfme Usually that's correct.
@holostrawberry Okay, thank you for the info!
Would this guide work for training on objects instead of a face or a style. Also could I train multiple objects using your colab notebook, like for say the different models of a car brand
It should work for objects, remember to give it an activation tag. Training multiple folders at the same time is also possible.
@holostrawberry Whats an activation tag? Also I saw the multiple folder option. So do I just run the cell and and during training the model will know that the images in the different folders are images of different car models? One more thing, how do I manually enter in captions for images?
@holostrawberry you are simply the best, I trained it on a single car model, and the results are faaaar better than any other training resources I've used(paid training resources incl).
If i want to train a lora (character lora) to use with Pony checkpoint. In Lora_Trainer_XL Collab, what checkpoint should i choose for training? And that trained lora will work with SDXL?
You should train on the pony model so it works with pony-based models
@holostrawberry Thank you very much :3
I couldn't do what I do, without the work you do. So thanks for everything :)
Thank you :)
Is it possible to use regularization images with colab?
Yes, you need to scroll down to the multiple folders section
@holostrawberry oh yes I see, thank you
Can somebody help me how to train Pony style lora? What i should prepare ? Collab settings etc...?
The default settings of the xl trainer work fine for a pony lora. Just give it enough repeats
It would be nice if i could use e621 site to scrape images. Will this feature be added someday?
It's a possibility but it's not a priority
@holostrawberry So, will this possibility be added someday?
Hi.
Can someone confirm that this method still works??
I enjoyed using this colab last year. Then suddenly the Loras generated started creating pink smoke.
So I stopped using this.
Moved on to Kohya Dreambooth Colab. Which now stopped working as well.
Are you making XL LoRas? If so, XL LoRas require very specific settings to come out properly.
@smurfme Nope. I'm satisfied with 1.5's results.
Have you used this recently? 1.5 or XL Can you confirm it works?
@shrujanreventon653 I've used the XL variant recently and it does work. 1.5 is very easy to train on, so if your LoRa's are coming out borked, your dataset is probably bad or the concept your trying to train is too difficult.
@smurfme What do you mean by the XL variant?
@ponyboi There's a trainer for XL LoRas and a trainer for 1.5 LoRas.
Hey! I'm trying to make a character lora for PonyXl, but when I run the code I get the error
Traceback (most recent call last): File "/content/kohya-trainer/train_network_wrapper.py", line 9, in <module> train(args) File "/content/kohya-trainer/train_network.py", line 168, in train text_encoder, vae, unet, = trainutil.load_target_model(args, weight_dtype, accelerator) File "/content/kohya-trainer/library/train_util.py", line 3150, in load_target_model text_encoder, vae, unet, load_stable_diffusion_format = loadtarget_model( File "/content/kohya-trainer/library/train_util.py", line 3116, in loadtarget_model text_encoder, vae, unet = model_util.load_models_from_stable_diffusion_checkpoint(args.v2, name_or_path, device) File "/content/kohya-trainer/library/model_util.py", line 863, in load_models_from_stable_diffusion_checkpoint info = unet.load_state_dict(converted_unet_checkpoint) File "/usr/local/lib/python3.10/dist-packages/torch/nn/modules/module.py", line 2152, in load_state_dict raise RuntimeError('Error(s) in loading state_dict for {}:\n\t{}'.format(And then a bunch more red error code. How can I fix this?
They deleted the "ponyv6" file that was used as the base model, I tried to use a base model as an alternative, but the error persisted, the only solution is to be patient :(
A new source for the pony model is now built into the trainer, try again
@holostrawberry new error: /usr/local/lib/python3.10/dist-packages/torch/utils/checkpoint.py:460: UserWarning: torch.utils.checkpoint: please pass in use_reentrant=True or use_reentrant=False explicitly. The default value of use_reentrant will be updated to be False in the future. To maintain current behavior, pass use_reentrant=True. It is recommended that you use use_reentrant=False. Refer to docs for more details on the differences between the two variants. warnings.warn(
@holostrawberry Thanks for responding! Now, after 5 minutes, it just ends on:
[Dataset 0] loading image sizes. 100% 81/81 [00:00<00:00, 272.40it/s] make buckets number of images (including repeats) / 各bucketの画像枚数(繰り返し回数を含む) bucket 0: resolution (704, 1408), count: 6 bucket 1: resolution (768, 1280), count: 30 bucket 2: resolution (768, 1344), count: 39 bucket 3: resolution (832, 1216), count: 48 bucket 4: resolution (896, 1152), count: 30 bucket 5: resolution (960, 1088), count: 6 bucket 6: resolution (1024, 1024), count: 12 bucket 7: resolution (1152, 896), count: 3 bucket 8: resolution (1216, 832), count: 3 bucket 9: resolution (1280, 768), count: 9 bucket 10: resolution (1344, 768), count: 57 mean ar error (without repeats): 0.02424573131766932 Warning: SDXL has been trained with noise_offset=0.0357, but noise_offset is disabled due to multires_noise_iterations / SDXLはnoise_offset=0.0357で学習されていますが、multires_noise_iterationsが有効になっているためnoise_offsetは無効になります preparing accelerator loading model for process 0/1 load StableDiffusion checkpoint: /content/downloaded_model.safetensors building U-Net loading U-Net from checkpoint U-Net: <All keys matched successfully> building text encoders
Nothing after that. Any idea?
@BesolloAI it might be running out of memory
@SasakiNsfw that's just a warning
@holostrawberry quedó usando más ram que antes, antes se podría entrenar con la t4, ahora mínimo necesita la l4 😞😞osea que si o si, toca comprar la versión pro de colab
@holostrawberry I'm getting the same issue when using the direct download link for Pony Diffusion. After the error mentioned above there is a bunch of red errors:
RuntimeError: Error(s) in loading state_dict for UNet2DConditionModel: Missing key(s) in state_dict: "down_blocks.0.attentions.0.norm.weight", "down_blocks.0.attentions.0.norm.bias" ...........
and many size mismatch for down and up blocks. Am I doing anything wrong? I appreciate for any help.
@Cookie4Free I'm still not sure what causes that. If worked fine for me yesterday.
Heyo im back again, I seem to be having a problem when creating a LoCon that is 800 epochs and up, and when I try testing the lora out I end up getting a glitched out generation, or fully static, generation this has happened before when I tried making my own raven lora and the generations will come out as blacked out generations, Could this be a similar glitch? if so could you fix it? I basically trained over 3000s steps in one day for no results and pretty disapointed :/
You trained for too long and burned it. Think 10 epochs not 800. If you don't have a lot of images set the repeats to 5.
@holostrawberry ohhhhhhh I get it now that makes sense for it to be like that, I did do a 10 epoch that went up to 800 this one time but II will try for 5 or maybe put less lora bc im wasting google collab time, thank you so much for always answering questions right away and just knowing lora problems!!!! <3
hey, so since PonyDiffusion Lora training don't work for me with CoLabs I checked out your guide on how to train on my own computer.
WD1.4 Tagger is discontinued and doesnt work with the latest StableDiffusion version. It doesn't show me a tab for it. Do you have any alternativefor it?
Also I can't use Kohya_ss, it always gives me the error "Could not load torch: No module named 'torch.amp'" and I coudn't find a solution for it. Torch is installed.
I recommend using this to train locally
https://github.com/derrian-distro/LoRA_Easy_Training_Scripts
@holostrawberry thx I already checked that one out from your guide. About the Tagger, is it also integrated in the Easy Trainer? I couldn't find it - if not, is there a good alternative for WD1.4 Tagger?
@Cookie4Free I use BooruDatasetTagManager from starrik in github as dataset editor, it comes with autotagger which includes we taggers.
There's also this new one https://github.com/derrian-distro/SD-Tag-Editor
Thank you so much!
When i try to start the Trainer, it either says:
Error: Invalid file ind dataset: "xxx". Aborting.
Or it says the Dataset is empty, if i try to figure out which file is "invalid" and remove some of it.
I recommend using png or jpeg images as well as txt files. Anything else may show that error
Apparently, if I want to train something niche, I still have to open every single txt files and hand-write the tags. T_T
Yep I had to do this once
hi!! how i can enable the flip_aug in the sdxl lora trainer? also what is the best bach size?
I have removed that option because I don't think it's very useful, however, you can still set flip_aug = True when setting the folder manually in the "multiple folders" section
@holostrawberry thanks bud, your lora trainer is amazing
Thx
Finally made and published my first lora because of you: https://civitai.com/models/494184/bibble-barbie-fairytopia-trilogy
Congrats!
Hola puedes hacer un nuevo tutorial con el XL Lora Trainer by Hollowstrawberry en google colab porfis
He estado pensando en ello
Suddenly there is an error with importing fiftyone.
It worked fine before, so I assumed that the recent version might be the problem. Fixing
!pip install fiftyonel ftfy
into
!pip install fiftyone==0.23.8
!pip install ftfy
fixed the problem for me.
Quick question: should I be tagging things like "shoulders", "torso", "arms" or "hands" on a character LoRA?
in my experience I don't ever explicitly tag body parts unless its like... part of an outfit.
like If you want to ensure that a crop top stays as a crop top you could include "midriff" or "belly button" or "stomach" or something like that. Probably still unnecessary but I do it for reassurance.
most of the time I just let deepdanbooru do its thing and then don't change the tags, and it works fine.
that's just how I do it though.
@EricHuanggle1001 Thank you. That actually helps a lot
According to your experience, what is a good range for the number of steps calculated by images × repeats × epochs ÷ batch size?
1000 to 4000 steps, it depends
@holostrawberry depend on what?
how exactly do batch sizes work? Just got the error "Token indices sequence length is longer than the specified maximum sequence length for this model (80 > 77). Running this sequence through the model will result in indexing errors", but checking my dataset the most tags any image has is 52
so just wondering if training a batch like... adds tags from two different images or something.
idk.
eitherway I guess I should stick to a maximum of 38 tags I guess
ok i fixed all my tags to below 38 tags and it still breaks
googling "running this sequence through the model will result in indexing errors" doesn't net anything
what is an indexing error
Love this method of training Loras as using your method is easier compared to the main method of training the Loras. I really hope there's a way to run the SDXL trainer using local runtime as Google Colab token is just way too expensive.
training_config file shows that "clip_skip" arrgument is 2, and I've read that it should be 1 for realistic loras. Can I change it? I didn't find it.
I'm late to reply but you'll have to double click the main cell of the colab and find the clip skip in the code, also for XL the clip skip doesn't matter
ok I dont see anyone else complaining about this so im confused as to what im doing wrong
"epoch 1/12 steps: 0% 10/5484 [00:12<1:55:26, 1.27s/it, loss=0.0932] Traceback (most recent call last): File "/content/kohya-trainer/train_network_wrapper.py", line 9, in <module> train(args) File "/content/kohya-trainer/train_network.py", line 627, in train latents = vae.encode(batch["images"].to(dtype=weight_dtype)).latent_dist.sample() AttributeError: 'NoneType' object has no attribute 'to'"
its not the trainer itself because I tried a different dataset and it worked fine. The only thing im doing different is i'm removing tags.
Is there a minimum number of tags required or something?
steps: 0% 9/5484 [00:10<1:49:48, 1.20s/it, loss=0.0908] Traceback (most recent call last): File "/content/kohya-trainer/train_network_wrapper.py", line 9, in <module> train(args) File "/content/kohya-trainer/train_network.py", line 617, in train for step, batch in enumerate(train_dataloader): File "/usr/local/lib/python3.10/dist-packages/accelerate/data_loader.py", line 383, in iter next_batch = next(dataloader_iter) File "/usr/local/lib/python3.10/dist-packages/torch/utils/data/dataloader.py", line 630, in next data = self._next_data() File "/usr/local/lib/python3.10/dist-packages/torch/utils/data/dataloader.py", line 1345, in nextdata return self._process_data(data) File "/usr/local/lib/python3.10/dist-packages/torch/utils/data/dataloader.py", line 1371, in processdata data.reraise() File "/usr/local/lib/python3.10/dist-packages/torch/_utils.py", line 694, in reraise raise exception TypeError: Caught TypeError in DataLoader worker process 0. Original Traceback (most recent call last): File "/usr/local/lib/python3.10/dist-packages/torch/utils/data/_utils/worker.py", line 308, in workerloop data = fetcher.fetch(index) File "/usr/local/lib/python3.10/dist-packages/torch/utils/data/_utils/fetch.py", line 51, in fetch data = [self.dataset[idx] for idx in possibly_batched_index] File "/usr/local/lib/python3.10/dist-packages/torch/utils/data/_utils/fetch.py", line 51, in <listcomp> data = [self.dataset[idx] for idx in possibly_batched_index] File "/usr/local/lib/python3.10/dist-packages/torch/utils/data/dataset.py", line 302, in getitem return self.datasets[dataset_idx][sample_idx] File "/content/kohya-trainer/library/train_util.py", line 1003, in getitem example["latents"] = torch.stack(latents_list) if latents_list[0] is not None else None TypeError: expected Tensor as element 1 in argument 0, but got NoneType
:(
I can't discern the cause, but just to be sure, the tag files can't be empty
@holostrawberry I threw together a small python script to check the minimum and maximum number of tags in my dataset. Of my dataset, the minimum tags is 9, and the max is 41. -> and it breaks.
Of my other dataset that works, the minimum tags is......... also 9......... uhhh. ok there goes my theory. (I was hoping that the minimum would be 10 or 11)
I'll do some further testing tomorrow. And by further testing I mean adding one image at a time until something throws an error
ok I just don't even know anymore.
Since I've got subsets, I just added and subtracted those instead of individual images (to narrow it down). I've identified the subset that causes things to break, So I run it with 12/13 subsets it works, but 13/13 it doesn't.
So okay cool, Just for redundancy I tried the one problem child subset on its own, and it worked fine.
So I guess it's not the images themselves, but somehow its..... the combination of the datasets? I have no clue. Clearly this is so niche there's no point in worrying about it, but now I'm curious so I'll continue on my own time.
ok this shall be my last message on the topic because ive given up lol.
I've attached a copy of my dataset (incase you care). I have narrowed down the perpatrators to 9 images (conveniently in the "TDoesntWork" folder). Slapping any one of those images into the "TheRest" folder causes it to throw an error. For some reason.
I have also included the Multiple Folders In Dataset string in "Custom.txt"
and the rest are pretty much useless. Though I added a copy of the Lora_Trainer collab just for futureproofing I guess. Copy made today so it is up to date.
https://drive.google.com/file/d/1S_gcYXMg-wZXCjSH1r4ETkC5slhG6fe0/view?usp=sharing
uhh.. im gonna go back to training now that I can.
^ I lied, and I lied
1: im back
2: it didnt work
I give up im just straight up deleting all of it idc.
@holostrawberry ok.... I think I have FINALLY figured it out. In the custom dataset section down below (aka "Multiple folders in dataset"), I had set "flip_aug = true" manually on some of my datasets, but the checkbox up top ("Turn it off if you care about asymmetrical elements in your Lora.") was not set. ie, I wanted asymmetrical except for the two subsets which I deemed symmetrical.
Now, because flip_aug was set to false the "Caching Latents..." bit of code never cached the flipped latents. Because it didn't think it needed to.
But the actual training portion saw "flip_aug = True" for the subset, and looked for the latents of the flipped image, which it couldn't find because it was never written. causing it to die.
(I only figured this out because I set cache_to_disk = True, and the error I got instead of "expected a tensor" was "hey this file doesn't exist". Finally some useful information istg.)
The temporary solution is set flip_aug to true with cache_to_disk set to True, write all the files, set flip_aug back to false, and carry on as normal. Since it gets written to my drive, the files persist when flip_aug is false, and can still be used by the datasets with "flip_aug = true"
(cache_to_disk can be forcefully set to True in "/contnet/kohya-trainer/library/train_util.py") line 735)
@EricHuanggle1001 I'm glad you found the cause. I'll have to see if I can do something to avoid this issue in the future
Hey there, I'm following this guide but using the XL trainer of the colab that you created. I have a question about batch sizes... In the guide, you list a general formula that you use to calculate steps (images x repeats x epochs / batch size). On the top of your XL colab, you recommend using the highest batch size available (with colab premium).
Is batch size still relevant to calculating step count? I've tried reading around and have gotten some mixed answers about whether or not it's needed or if it's automatically calculated now.
For reference, I'm trying to train a style lora with 74 images in it.
im not entirely sure what you're asking, but I will say batch count does make a difference.
74 images with a batch count of 2 = 37 steps
74 images with a batch count of 74 = 1 step
atleast in the non-XL version it automatically calculates the steps for you when you run the trainer
"Found 50 images with 10 repeats, equaling 500 steps.
📉 Divide 500 steps by 2 batch size to get 250.0 steps per epoch.
🔮 There will be 12 epochs, for around 3000 total training steps."
idk if that answers your question but hopefully its better than nothing
@EricHuanggle1001 Thanks for the reply! So if I wanted to use a batch count of 16, then I should theoretically be multiplying the epoch count by a significant amount in order to still hit a target of, say, 3000 steps?
@znk123 you've got 74 images, with a batch size of 16 is 4.625, which I THINK gets rounded up to 5 (do not quote me on that). Assuming your repeats are set to "1" (which it does make a difference), you'd need 3000/5 = 600 epochs.
considering you're probably not using repeats of "1", you're probably using like... 10 or something. that'd be 740/16 = 46.25, (once again i'm unsure how rounding works, lets just assume it rounds up again to 47), you'd need 3000/47 = 63 epochs
@znk123 batch size takes several steps and does them at the same time, if you increase the batch size you don't need to compensate by increasing the steps, just leave it as is. For batch size 4 in XL, 500 to 1000 steps is enough, the "sweet spot" will vary depending on how many images you have
Hello. Thank you for your guide.
I am having an issue, though. I'm at the training stage and trying to use https://civitai.com/models/288584?modelVersionId=324619 for my training model but it is not able to download it and gives the following error:
```
06/27 21:13:14 [ERROR] CUID#7 - Download aborted. URI=https://civitai.com/api/download/models/324619 Exception: [AbstractCommand.cc:351] errorCode=24 URI=https://civitai.com/api/download/models/324619 -> [HttpSkipResponseCommand.cc:215] errorCode=24 Authorization failed. Download Results: gid |stat|avg speed |path/URI ======+====+===========+======================================================= 3e4f87|ERR | 0B/s|//content/downloaded_model.safetensors Status Legend: (ERR):error occurred. aria2 will resume download if the transfer is restarted. If there are any errors, then see the log file. See '-l' option in help/man page for details. mv: cannot stat '/content/downloaded_model.safetensors': No such file or directory Renamed model to /content/downloaded_model.ckpt 💥 Error: The model you selected is invalid or corrupted, or couldn't be downloaded. You can use a civitai or huggingface link, or any direct download link.```
I also experienced as similar, I thought the lora file was broken
This is most likely due to me not knowing what Im doing.
I can work around that error by giving it a different link to a custom model. The only thing that worked for me was giving a direct link to the model(has to end with .safetensors), not just the page or download button.
"Worked" in this case means that I get a different wall of errors and I get it slightly later.
```
loading model for process 0/1 load StableDiffusion checkpoint: /content/autismmixSDXL_autismmixPony.safetensors
Traceback (most recent call last): File "/content/kohya-trainer/train_network_wrapper.py", line 9, in <module> train(args) File "/content/kohya-trainer/train_network.py", line 168, in train text_encoder, vae, unet, = trainutil.load_target_model(args, weight_dtype, accelerator) File "/content/kohya-trainer/library/train_util.py", line 3150, in load_target_model text_encoder, vae, unet, load_stable_diffusion_format = loadtarget_model( File "/content/kohya-trainer/library/train_util.py", line 3116, in loadtarget_model text_encoder, vae, unet = model_util.load_models_from_stable_diffusion_checkpoint(args.v2, name_or_path, device) File "/content/kohya-trainer/library/model_util.py", line 863, in load_models_from_stable_diffusion_checkpoint info = unet.load_state_dict(converted_unet_checkpoint) File "/usr/local/lib/python3.10/dist-packages/torch/nn/modules/module.py", line 2152, in load_state_dict raise RuntimeError('Error(s) in loading state_dict for {}:\n\t{}'.format( RuntimeError: Error(s) in loading state_dict for UNet2DConditionModel: Missing key(s) in state_dict: "down_blocks.0.attentions.0.norm.weight", "down_blocks.0.attentions.0.norm.bias", "down_blocks.0.attentions.0.proj_in.weight", "down_blocks.0.attentions.0.proj_in.bias", "down_blocks.0.attentions.0.transformer_blocks.0.attn1.to_q.weight",
...
```
@tglink yes that's the way to let the download work. I'm not sure about the next error though. You may be trying to use the 1.5 trainer instead of the XL trainer?
@holostrawberry yes, that was the issue. I didn't see an XL version until a few days later. Managed to train and release a couple loras since then, although I used the included options(namely Pony Diffusion V6 XL) rather than using a custom model. I'll try again sometime this week and post results here.
Also, I had a case of a model outright breaking - using any epoch after the 6th produced pink noise - but I explain it by solar flares or plain bad luck.
Can you fix XL Trainer?
There, I had trained my lora and downloaded it, but, the lora doesn't works, in other words cannot be used at all.
Sorry for late reply, but you trained too many steps, XL lora is more sensitive, you can see when the training broke when it starts saying "loss=nan" near the progress bar
For anyone having problem with your custom model not downloading, follow this :
https://education.civitai.com/civitais-guide-to-downloading-via-api/
Great tutorial, what are the blacklist_tags mentioned in the colon notebook
when you use the auto-tagger, "blacklist_tags" simply automatically removes said tags.
like no one cares about "official_alternate_outfit" because it says nothing about the image itself
"style_parody" doesn't do anything either
basically it gets rid of human classification tags that are completely irrelevant to learning
@EricHuanggle1001 Thanks for the clarification, just to be sure, I am training a Lora for multicolor hairstyles (tight braids). I will not need to say anything about hairstyle and color in the captions. Is this correct?
@dinusha94 if nearly all your images have the same tag, you can remove it to make it part of the lora, that way you won't need to use it in the prompt when generating. Otherwise just include all details including hair colors
@holostrawberry Thanks, I don't have a common tag for all the images, I have different captions/tags for each image. So I need to add all the tags and information about hairstyles and colors to the "blacklist_tags" then it will be a part of the lora right?
@dinusha94 if they're different for each image you shouldn't blacklist them
@holostrawberry Thanks for the reply. will the different hair colors be a part of Lora then? I am very new to this subject. I am using the loras with automatic1111.
RuntimeError: Error(s) in loading state_dict for UNet2DConditionModel:
I always get same error on custom models
KeyError: 'time_embed.0.weight'
You might be trying to use the 1.5 trainer for XL or viceversa, otherwise you might need to upload the model to huggingface to let it work
what does it mean when loss is nan? it seems to make bad loras and i don't know what's causing it. i'm using the XL lora trainer
The guide author said in another comment that: "Sorry for late reply, but you trained too many steps, XL lora is more sensitive, you can see when the training broke when it starts saying "loss=nan" near the progress bar"
Tried using the XL Trainer for one LORA, and it worked out fine with no issues, but I'm trying to train another LORA and the colab cell is stopping abruptly with no obvious error message. After loading the buckets, it gives me this:
load Diffusers pretrained models: hollowstrawberry/67AB2F, variant=fp16 /usr/local/lib/python3.10/dist-packages/diffusers/pipelines/pipeline_utils.py:1223: FutureWarning: You are trying to load the model files of the `variant=fp16`, but no such modeling files are available.The default model files: {'unet/diffusion_pytorch_model.safetensors', 'text_encoder/model.safetensors', 'text_encoder_2/model.safetensors', 'vae/diffusion_pytorch_model.safetensors'} will be loaded instead. Make sure to not load from `variant=fp16`if such variant modeling files are not available. Doing so will lead to an error in v0.22.0 as defaulting to non-variantmodeling files is deprecated. deprecate("no variant default", "0.22.0", deprecation_message, standard_warn=False) U-Net converted to original U-Net load VAE: stabilityai/sdxl-vae additional VAE loaded Enable SDPA for U-Net import network module: networks.lora
It ends after the last line. I can't figure out what the issue is this time and why it's messed up now compared to the previous training I did.
I tried redoing the previous LORA through the XL trainer just to see if it was the new dataset, but that one also ends at the same place now when it worked before. I also made another dataset and it also ends itself. I guess the XL trainer is messed up? It started messing up the day after I made the first LORA. I'm not sure if it is running out of RAM because it jumps up to the red at the same spot.
@TheOneAndOnlyFella Yes it's running out of memory, might be because of your settings
@holostrawberry Okay, I had a feeling that was the case. What settings would help it not run out of memory? The first time I used the trainer, I used pretty much default settings and I used mostly default the next time. Is having a small dataset going to cause that issue? The first had a few hundred images while the next only had about 40-50, that's the only major difference between the two times.
I may have figured out what the issue was. When starting up the colab for the first time, it'll do the installation process, and near the end prompts me to restart the session to apply something. If I restart as it asks, it forces me to restart using a runtime with no GPU RAM, which leads to it running out of memory. If I don't, it seems to work totally fine and uses the GPU runtime instead, which doesn't run out of memory. I don't think it lets me select the GPU runtime without Colab premium, so restarting it is actually just a trap.
Anyway, thanks for at least telling me it was a memory issue so I knew what to look out for.
I'm getting a ModuleNotFoundError: No module named 'xformers' error, and I'm not sure how to fix it. I've tried reinstalling xformers by command lines but nothing seems to work.
If using the XL trainer, your can use sdp instead of xformers
Started receiving the error:
ERROR: No matching distribution found for torch==2.3.0+cu121
Delete the collab and import it again seems to fix the problem.
If one of my folders has a lot of tags, in my case it's for the character's face, should I keep the training steps as low as possible?
If you have lots of images you can have less repeats so that the number of total steps is the same. The tags in the text files don't affect this.
@holostrawberry Good to know. I appreciate the help you've been giving me. This LoRA I've been making has been so close to being good several times, but there's always something I mess up or that I'm not happy with. Thanks again.
can you make video tutorial for SDXL Lora Trainer?
I get the following error, does anyone know how to fix it? , "ValueError: File format not supported: filepath=/content. Keras 3 only supports V3 .keras files and legacy H5 format files (`.h5` extension). Note that the legacy SavedModel format is not supported by load_model() in Keras 3. In order to reload a TensorFlow SavedModel as an inference-only layer in Keras 3, use keras.layers.TFSMLayer(/content, call_endpoint='serving_default') (note that your call_endpoint might have a different name)."
Fixed
the xl version doesnt give me a output
Hi holostrawberry, Thank you very much for your hard work in making this colabs. I have used it several times in the past, only this month there is a slight change in the LORA making process. if you are free can you help me?
when I made LORA, for the current version of colabs the lora results were taken for each percentage step as in the following example:
(Current collabs)
epoch 1/10
steps: 10% 153/1530 [01:39<14:53, 1.54it/s, loss=0.101]
saving checkpoint: /content/drive/MyDrive/Loras/DNDH/output/DNDH-01.safetensors
epoch 2/10
steps: 20% 306/1530 [03:16<13:06, 1.56it/s, loss=0.0995]
saving checkpoint: /content/drive/MyDrive/Loras/DNDH/output/DNDH-02.safetensors
epoch 3/10
steps: 30% 459/1530 [04:53<11:24, 1.56it/s, loss=0.0906]
saving checkpoint: /content/drive/MyDrive/Loras/DNDH/output/DNDH-03.safetensors
epoch 4/10
steps: 40% 612/1530 [06:30<09:45, 1.57it/s, loss=0.0817]
saving checkpoint: /content/drive/MyDrive/Loras/DNDH/output/DNDH-04.safetensors
epoch 5/10
steps: 50% 765/1530 [08:08<08:08, 1.57it/s, loss=0.0822]
saving checkpoint: /content/drive/MyDrive/Loras/DNDH/output/DNDH-05.safetensors
while the last collabs I used, each step was in 100% position like this:
(Old collabs)
epoch 1/10
steps: 1530/1530 [01:39<14:53, 1.54it/s, loss=0.101]
epoch 2/10
steps: 1530/1530 [03:16<13:06, 1.56it/s, loss=0.0995]
epoch 3/10
steps: 1530/1530 [04:53<11:24, 1.56it/s, loss=0.0906]
epoch 4/10
steps: 1530/1530 [06:30<09:45, 1.57it/s, loss=0.0817]
epoch 5/10 steps: 1530/1530 [08:08<08:08, 1.57it/s, loss=0.0822]
Is there a way to get the same settings as the old one? I usually get good results in epoch 3 or 4. For me now, low epoch values produce inappropriate LORA and high LORA values produce appropriate characters but with poor body parts.
Thank you for your time, may you always be healthy.
The colab has options for number of epochs and saving every epoch. Additionally if you want each epoch to have 1530 steps you'll have to increase the number of repeats in the colab.
@holostrawberry Thank you very much for the suggestion.
Can you update this guide to make it clear that this tutorial is only to make SD 1.5 loras. I was trying to use it to make pony loras and kept getting confused when they didn't work.
It works for pony loras but you have to use the XL trainer which has a link from the regular trainer
I just edited it to mention this
The one time I got this to work it reached a max of 12.8 when training a Lora in T4.... The max free Ram without it is 12.7, if it goes past that it just stops.
Mother fuckers.
Got a problem here:
---------------------------------------------------------------------------
4 frames
/usr/local/lib/python3.10/dist-packages/mongoengine/connection.py in <module> 2 3 from pymongo import MongoClient, ReadPreference, uri_parser ----> 4 from pymongo.database import _check_name 5 6 from mongoengine.pymongo_support import PYMONGO_VERSION ImportError: cannot import name '_check_name' from 'pymongo.database' (/usr/local/lib/python3.10/dist-packages/pymongo/database.py) --------------------------------------------------------------------------- NOTE: If your import is failing due to a missing package, you can manually install dependencies using either !pip or !apt. To view examples of installing some common dependencies, click the "Open Examples" button below.Sorry to tell you this, but the trainer is having another problem again
unfortuneately, I'm here to inform about the trainer problem too. I stuck at the Captions step, it said 2024-09-24 19:49:32.864827: W tensorflow/compiler/tf2tensorrt/utils/py_utils.cc:38] TF-TRT Warning: Could not find TensorRT
stuck at this issue too
It appears your data maker is also having a problem
Tensorflow needs to be reconfigured on this colab...sigh
Yep, google keeps breaking it
@holostrawberry Excellent tool BTW. Hope you can get it back up soon. Thanks for your great work!
get to the tag your images section and the whole thing sorta buggers out with:
Launching program...
env: PYTHONPATH=/content/kohya-trainer
2024-09-25 19:26:07.688415: E external/local_xla/xla/stream_executor/cuda/cuda_dnn.cc:9261] Unable to register cuDNN factory: Attempting to register factory for plugin cuDNN when one has already been registered
2024-09-25 19:26:07.688502: E external/local_xla/xla/stream_executor/cuda/cuda_fft.cc:607] Unable to register cuFFT factory: Attempting to register factory for plugin cuFFT when one has already been registered
2024-09-25 19:26:07.690650: E external/local_xla/xla/stream_executor/cuda/cuda_blas.cc:1515] Unable to register cuBLAS factory: Attempting to register factory for plugin cuBLAS when one has already been registered
I love your work, But like the others I got the same error now :(
Sorry about that, google update broke it
datasets not working atm I read the other comments and i see similar problems I hope you can get it up and running soon🥺
the same with lora maker, It is not working
hello! The blip function does not work, as does Lora training. Returns this error. Thank you for your hard work, I hope you will be able to solve this problem soon
CalledProcessError: Command '['/usr/bin/python3', 'train_network_wrapper.py', '--dataset_config=/content/drive/MyDrive/Loras/Loratest/dataset_config.toml', '--config_file=/content/drive/MyDrive/Loras/Loratest/training_config.toml']' died with <Signals.SIGSEGV: 11>.
I saw your response in the comments that this is due to the latest Google updates. Thank you for the information
There's a temporary workaround for the Trainer here :
https://colab.research.google.com/github/uYouUs/Hollowstrawberry-kohya-colab/blob/Experiments/Lora_Trainer.ipynb
what about XL??
@Voltvoided XL still works? If not im using his version to speed up XL
https://colab.research.google.com/github/uYouUs/Hollowstrawberry-kohya-colab/blob/Threading/Lora_Trainer_XL_threaded.ipynb
It unzips datasets on the go and stores them in colab's drive instead of your google drive. its a bit faster but You dont keep the unzipped dataset in your google drive if you want that.
@ShunaRimuru ohhhhh okay
unfortunately, this link worked for one day and now it has stopped again((
@nikaantekhina842 what error are you getting? I know it wasnt working for GPUs other than the default T4, However that was fixed with a triton install. I'm currently running it with no issues.
Edit: it seems like it was just updated to include the triton fix.
@ShunaRimuru /usr/local/lib/python3.10/dist-packages/transformers/utils/generic.py:441: FutureWarning: torch.utils._pytree._register_pytree_node is deprecated. Please use torch.utils._pytree.register_pytree_node instead. torchpytree._register_pytree_node( /usr/local/lib/python3.10/dist-packages/transformers/utils/generic.py:309: FutureWarning: torch.utils._pytree._register_pytree_node is deprecated. Please use torch.utils._pytree.register_pytree_node instead. torchpytree._register_pytree_node(
@tsum Those are warnings. You can safely ignore them. Its for developers to know the code has changed from something to another, and in the future they should change it to the new way. Its like the developer way of saying, windows 10 will no longer get support, update to windows 11.
Trainer should be fixed now
I've installed different versions of torch and torchvision getting the same error under the Lora Trainer.
I haven't heard this issue from anyone else, try opening the trainer from the link in the post
ERROR: Could not find a version that satisfies the requirement torch==2.4.1+cu121 (from versions: 1.11.0, 1.12.0, 1.12.1, 1.13.0, 1.13.1, 2.0.0, 2.0.1, 2.1.0, 2.1.1, 2.1.2, 2.2.0, 2.2.1, 2.2.2, 2.3.0, 2.3.1, 2.4.0, 2.4.1, 2.5.0) ERROR: No matching distribution found for torch==2.4.1+cu121
Same error
RuntimeError: operator torchvision::nms does not existyeah, i get the same error ! :s
📢 I get the same error start from yesterday.
Should be fixed now@mat63000 @commandokittykitty320 @asbtownai
anyone having issues with the XL lora trainer?
I make a handful of xl loras wednesday night and now there is this error :
ModuleNotFoundError: No module named 'voluptuous'
it usually happens a few seconds after starting the code
Should be fixed now
@holostrawberry . the sites XL training and hardware training(self) cant seem to get the same results compared to the colab. ??? - so once again thank you, its really appreciated
@holostrawberry Thank You!
I just ran into the same error
@ixalon make sure you're using the latest version, my post has the link
Hitting an error with the XL LORA trainer "ModuleNotFoundError: No module named 'diffusers'"
Not sure what the issue is
Oh I retried using the provided PonXL model and it worked this time.
When I run the setup in the LoRa training part I get "ValueError: torch.cuda.is_available() should be True but is False. xformers' memory efficient attention is only available for GPU"
This error happened because you ran out of free time for the GPU and thus you're running the colab without a GPU. By the time of this comment you probably already have more free time available
You know, I just wanna comment that I finally get why it's important to delete common/recurring character tags for a proper trigger word.
Like if a character has brown hair or red eyes you don't need to keep the brown hair or red eyes tags. I get it now.
have a problem with xl lora. the procces finish, but dont save anything in output folder.
final log:
unet/diffusion_pytorch_model.safetensors: 100% 5.14G/5.14G [02:06<00:00, 40.6MB/s] Fetching 14 files: 100% 14/14 [02:06<00:00, 9.06s/it] U-Net converted to original U-Net load VAE: stabilityai/sdxl-vae config.json: 100% 607/607 [00:00<00:00, 1.32MB/s] diffusion_pytorch_model.safetensors: 100% 335M/335M [00:10<00:00, 32.9MB/s] additional VAE loaded Enable SDPA for U-Net import network module: networks.lora
Hmmm, not sure what the problem could be.
Can you update the tagger for the dataset to a newer one like Eva02 - Large?
The old tagger version misses many of the tags, even the general ones. It becomes harder to tag them manually when there are too many images. Or can you add multiple taggers and give the option to choose between them?
Try lowering the threshold value
Getting an error when trying to train using illustrious or custom url model. doesnt happen with pony.
RuntimeError: Error(s) in loading state_dict for CLIPTextModel: Missing key(s) in state_dict: "text_model.embeddings.position_ids".
That's strange, I'll let you know if I find a cause.
i have the same problem
It works fine for illustrious when I run the colab. Make sure you're using the latest version, the link is at the top of the colab itself or in my post.
Same with NoobAI and T-illunai3
i have the same issue
same issue for IL works for SDXL though
This may be fixed now after today's changes!
For the regular lora trainer colab, some custom models return an authorization error when trying to download the model. For example, https://civitai.com/models/107677?modelVersionId=115828 will work but https://civitai.com/models/83930/pornmaster-anime will not. Do you know how to fix this? Thanks
12/09 19:22:57 [ERROR] CUID#7 - Download aborted. URI=https://civitai.com/api/download/models/928154?type=Model&format=SafeTensor&size=pruned&fp=fp16
Exception: [AbstractCommand.cc:351] errorCode=24 URI=https://civitai.com/api/download/models/928154?type=Model&format=SafeTensor&size=pruned&fp=fp16
-> [HttpSkipResponseCommand.cc:215] errorCode=24 Authorization failed.
Download Results:
gid |stat|avg speed |path/URI
======+====+===========+=======================================================
43869e|ERR | 0B/s|//content/downloaded_model.safetensors
Hey, you would need to put your civitai token in the link, but I forgot exactly how to do it. I should add it as an option. In the meantime, I suggest you download the model, upload it to your google drive, and use a path to it in the model url (for example "/content/drive/MyDrive/model.safetensors"). Or if the model can be found on huggingface, or you can upload it there, that will work too.
Thank you for this great resource. If I use an A100 and increase the batch size to 16, should I raise the epochs or repeats so it is still in the 1000 - 2000 after the batch adjustment or should it be 2000 steps before the batch adjustment? For example, should it be 20 images × 10 repeats × 10 epochs ÷ 16 batch size = 125 steps?
You would have 1000-2000 before the batch size, so 125 is about right.
@holostrawberry thanks.
Thanks for this, works like a charm if I use the default pony Diffusion.
Sadly, when I try to use another model (PonyRealism or CyberrealisticPony), I get a memory error (working with free colab plan) at the caching latents step, no matter what I try to reduce the memory usage (batch size, number of image, epochs, ...).
caching latents. checking cache validity... 100% 129/129 [00:00<00:00, 6013.97it/s] caching latents... 0% 0/129 [00:00<?, ?it/s] Traceback (most recent call last): File "/content/kohya-trainer/train_network_xl_wrapper.py", line 10, in <module> trainer.train(args) File "/content/kohya-trainer/train_network.py", line 251, in train train_dataset_group.cache_latents(vae, args.vae_batch_size, args.cache_latents_to_disk, accelerator.is_main_process) File "/content/kohya-trainer/library/train_util.py", line 1823, in cache_latents dataset.cache_latents(vae, vae_batch_size, cache_to_disk, is_main_process) File "/content/kohya-trainer/library/train_util.py", line 872, in cache_latents cache_batch_latents(vae, cache_to_disk, batch, subset.flip_aug, subset.random_crop) File "/content/kohya-trainer/library/train_util.py", line 2147, in cache_batch_latents latents = vae.encode(img_tensors).latent_dist.sample().to("cpu") File "/usr/local/lib/python3.10/dist-packages/diffusers/utils/accelerate_utils.py", line 46, in wrapper return method(self, *args, **kwargs) File "/usr/local/lib/python3.10/dist-packages/diffusers/models/autoencoder_kl.py", line 236, in encode h = self.encoder(x) File "/usr/local/lib/python3.10/dist-packages/torch/nn/modules/module.py", line 1736, in _wrapped_call_impl return self._call_impl(*args, **kwargs) File "/usr/local/lib/python3.10/dist-packages/torch/nn/modules/module.py", line 1747, in _call_impl return forward_call(*args, **kwargs) File "/usr/local/lib/python3.10/dist-packages/diffusers/models/vae.py", line 139, in forward sample = down_block(sample) File "/usr/local/lib/python3.10/dist-packages/torch/nn/modules/module.py", line 1736, in _wrapped_call_impl return self._call_impl(*args, **kwargs) File "/usr/local/lib/python3.10/dist-packages/torch/nn/modules/module.py", line 1747, in _call_impl return forward_call(*args, **kwargs) File "/usr/local/lib/python3.10/dist-packages/diffusers/models/unet_2d_blocks.py", line 1150, in forward hidden_states = resnet(hidden_states, temb=None) File "/usr/local/lib/python3.10/dist-packages/torch/nn/modules/module.py", line 1736, in _wrapped_call_impl return self._call_impl(*args, **kwargs) File "/usr/local/lib/python3.10/dist-packages/torch/nn/modules/module.py", line 1747, in _call_impl return forward_call(*args, **kwargs) File "/usr/local/lib/python3.10/dist-packages/diffusers/models/resnet.py", line 598, in forward hidden_states = self.nonlinearity(hidden_states) File "/usr/local/lib/python3.10/dist-packages/torch/nn/modules/module.py", line 1736, in _wrapped_call_impl return self._call_impl(*args, **kwargs) File "/usr/local/lib/python3.10/dist-packages/torch/nn/modules/module.py", line 1747, in _call_impl return forward_call(*args, **kwargs) File "/usr/local/lib/python3.10/dist-packages/torch/nn/modules/activation.py", line 432, in forward return F.silu(input, inplace=self.inplace) File "/usr/local/lib/python3.10/dist-packages/torch/nn/functional.py", line 2380, in silu return torch._C._nn.silu(input) torch.OutOfMemoryError: CUDA out of memory. Tried to allocate 480.00 MiB. GPU 0 has a total capacity of 14.75 GiB of which 315.06 MiB is free. Process 92408 has 14.44 GiB memory in use. Of the allocated memory 14.01 GiB is allocated by PyTorch, and 314.76 MiB is reserved by PyTorch but unallocated. If reserved but unallocated memory is large try setting PYTORCH_CUDA_ALLOC_CONF=expandable_segments:True to avoid fragmentation. See documentation for Memory Management (https://pytorch.org/docs/stable/notes/cuda.html#environment-variables)Obviously I also tried to set at the begibnning of the code PYTORCH_CUDA_ALLOC_CONF=expandable_segments:True as suggested in the error, without any success.
If you have any idea how to fix this I would appreciate. Otherwise, I will continue to make loras with dthe default model. using them with realistic models later give decent results.
Thanks again!
Maybe you'd need to convert it to diffusers to save memory. Unfortunately I don't have an easy way to do it
is there a command i could add somewhere to handle the save state function? id like at least the last epoch so maybe i could continue
save state doesn't work right now as it was using up the entire google drive recycle bin
Deduplicator doesn't work:
--------------------------------------------------------------------------- RuntimeError Traceback (most recent call last) <ipython-input-2-070d2a48d88b> in <cell line: 36>() 93 dataset.app_config.sidebar_groups = sidebar_groups 94 dataset.save() ---> 95 session = fo.launch_app(dataset) 96 97 print("❗ Wait a minute for the session to load. If it doesn't, read above.")6 frames
/usr/local/lib/python3.10/dist-packages/fiftyone/core/session/client.py in _post_event(self, event) 202 203 if response.status_code != 200: --> 204 raise RuntimeError( 205 f"Failed to post event `{event.get_event_name()}` to {self.origin}/event" 206 ) RuntimeError: Failed to post event `deactivate_notebook_cell` to http://0.0.0.0:5151/eventIs it normal to have so much waiting time? It is for Lora XL
steps: 5% 95/2050 [07:29<2:34:00,
1 to 3 hours is expected
hey, thank you! i'd only ever trained embeddings for characters before starting to use XL, so all of this was new to me. the results are ten thousand times better! it was very worth it to upload the custom model as well
How to made them so it can be used in civitai generator?
Would XL training work on free tier T4? I have a feeling it would disconnect from inactivity in half an hour or less.
It works, you may need to keep checking to make sure they don't register inactivity, but the sessions should be around 3 hours long otherwise.
I am facing a problem when using XL Lora Trainer
this is what appears when starting to train the dataset:
WARNING: All log before absl::InitializeLog() is called are written to STDERR E0000 00:00:1738176057.5774 messages72 1649 cuda_dnn.cc:8310] Unable to register cuDNN factory: Attempting to register factory for plugin cuDNN when one has already been registered E0000 00:00:1738176057.583698 1649 cuda_blas.cc:1418] Unable to register cuBLAS factory: Attempting to register factory for plugin cuBLAS when one has already been registered Traceback (most recent call last): File "/content/kohya-trainer/train_network_xl_wrapper. py", line 2, in <module> from sdxl_train_network import setup_parser, SdxlNetworkTrainer File "/content/kohya-trainer/sdxl_train_network.py", line 4, in <module> import train_network File "/content/kohya-trainer/train_network.py", line 23, in <module> import library.config_util as config_util File "/content/kohya-trainer/library/config_util.py", line 21, in <module> import voluptuous ModuleNotFoundError: No module named 'voluptuous'
can you help me fix it.
I also got this error
Should be fixed now
@holostrawberry thanks
Hey there!
I'm using Lora Trainer XL Legacy, and I'm trying to create a LoRa style. Here's the configuration I'm using:
▶️ Learning
unet_lr: 1e-4
text_encoder_lr: 0
lr_scheduler: constant_with_warmup
lr_scheduler_number: 0
▶️ Structure
network_dim: 32
network_alpha: 16
▶️ Advanced
optimizer: AdaFactor
optimizer_args: ["scale_parameter=False", "relative_step=False", "warmup_init=False"]
However, I ran into the following error:
'''
Traceback (most recent call last):
File "/content/kohya-trainer/train_network_xl_wrapper.py", line 10, in <module>
trainer.train(args)
File "/content/kohya-trainer/train_network.py", line 324, in train
optimizer_name, optimizer_args, optimizer = train_util.get_optimizer(args, trainable_params)
^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^
File "/content/kohya-trainer/library/train_util.py", line 3174, in get_optimizer
value = ast.literal_eval(value)
^^^^^^^^^^^^^^^^^^^^^^^
File "/usr/lib/python3.11/ast.py", line 64, in literal_eval
node_or_string = parse(node_or_string.lstrip(" \t"), mode='eval')
^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^
File "/usr/lib/python3.11/ast.py", line 50, in parse
return compile(source, filename, mode, flags,
^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^
File "<unknown>", line 1
False",
^
SyntaxError: unterminated string literal (detected at line 1)
'''
Any idea what might be causing this? Also, big thanks for the Colab notebook—it’s been super helpful! 😊
I think it's because the optimizer args can't contain quotes or commas:
scale_parameter=False relative_step=False warmup_init=False
@holostrawberry yeahh, it's work, thankss mate
ERROR: pip's dependency resolver does not currently take into account all the packages that are installed. This behaviour is the source of the following dependency conflicts
Getting this issue
You can ignore this
If I want to train a Lora for five different characters, lets say with 20 images each and therefore 100 in total, how do I calculate the number of steps? Seperately for each character, so there are 250-1000 steps for each character?
Thanks for your help.
The most important part when training multiple characters in the same lora is the tagging. You have to make sure the tags for each of the characters don't collide, or they will "bleed" into one another. That being said, you can put each character in a different folder, give a different activation tag for each, and set the number of repeats of each folder so that the total number of images×repeats is between 50 and 100 for each folder. Then I just do 10 epochs of that and pick the best.
Hello, I want to train a XL Lora and I got this issue "load VAE: /content/sdxl_vae.safetensors exception occurs in loading vae: We couldn't connect to 'https://huggingface.co' to load this model..."
I need help 😭
Try again later, huggingface was offline for a bit
Hello! I trained a SDXL Lora but the results became satisfactory with 350 steps (!!!). Where did i fail? What can be done to reduce it to, like, 30 steps? It has about 40 hq images (1024x1024), 4 repeats, 40 epochs and 5 batch size.
350 steps is normal, you will never be able to train a successful lora with 30 steps
@holostrawberry thanks, but i think i wasn't clear enough. I trained a Lora and, WHEN USING it (applying to SDXL and generating the image), the results starts to become satisfactory with 350 steps.
But I've worked on it changing the unet_lr parameter
Getting this error when I put the google drive path into the optional_custom_training_model
OSError: We couldn't connect to 'https://huggingface.co' to load this model, couldn't find it in the cached files and it looks like /content/sdxl_vae.safetensors is not the path to a directory containing a config.json file. Checkout your internet connection or see how to run the library in offline mode at 'https://huggingface.co/docs/diffusers/installation#offline-mode'.
Hello, sir, Great guide.
But I have a small question. What values of Network Dim and Network alpha should I use for styles/characters and concepts for pony/Ilustrious loras? Tell me, please.
8/4 dim/alpha works fine for characters and concepts. You probably want 16/8 or 24/12 for styles.
@holostrawberry but why? Why wouldn't I want 16/12 or 24/18 for style loras?
@smart_enjoyer Is not an exact science, I can recommend values but other people might not agree
If anyone else is having issues with the trainer like me, the experiments link is working
https://colab.research.google.com/github/uYouUs/kohya-colab/blob/main/Lora_Trainer.ipynb
SOS,how do I correctly indicate a custom model? I specify the link, but the error still does not find it?
try the experiments link
https://colab.research.google.com/github/uYouUs/kohya-colab/blob/main/Lora_Trainer_XL.ipynb
it's not unzipping my zip file of the dataset all it does is create a empty folder
It should be working, did you make sure the path to the zip file is correct, and that you have enough space in your google drive?
@holostrawberry yes and yes but for some reason it's not working
I think the Lora trainer XL is broken because I keep getting ModuleNotFoundError: No module named 'accelerate' error message
This problem started today and I know what happened. Stay tuned for a fix soon.
@holostrawberry Okay, Thank you
Would be cool if you wrote a guide for using civitais trainer
you said 16/8 which works great for characters and is only 18 MB. but when i train with 16/8 it go above 100mb. why?
That was old information for sd1.5, now you usually want 8/4 for 50 MB
The Dataset maker is broken because it keep saying it found 0 images when I have 300 images in my dataset
It's a problem with google drive. Delete the folder, let step 1 create the folder for you, and put your images there after that.
I had the same problem. I tried deleted directories, renamed project, and had the dataset maker create them again, and running into same issue. Am I missing some type of permissions to read images?
[ImportError: No bitsandbytes / bitsandbytesがインストールされていないようです]
I get this error and can't train. Please let me know how to fix it.
https://colab.research.google.com/github/uYouUs/kohya-colab/blob/main/Lora_Trainer_XL.ipynb
This version is working fine.
Hey, what do I do if I've ran out of GPU usage in the middle of running it? I'm in the middle of epoch 9/10 when it ran out.
The Dataset Maker is broken because I'm trying to create my dataset and it said: /bin/bash: line 1: F/dataset: No such file or directory /content/kohya/venv/lib/python3.10/site-packages/diffusers/utils/outputs.py:63: FutureWarning: torch.utils._pytree._register_pytree_node is deprecated. Please use torch.utils._pytree.register_pytree_node instead. torch.utils._pytree._register_pytree_node( rich is not installed, using basic logging downloading wd14 tagger model from hf_hub. id: SmilingWolf/wd-v1-4-convnext-tagger-v2 /content/kohya/venv/lib/python3.10/site-packages/huggingface_hub/file_download.py:1143: FutureWarning: The force_filename parameter is deprecated as a new caching system, which keeps the filenames as they are on the Hub, is now in place. warnings.warn( /content/kohya/venv/lib/python3.10/site-packages/huggingface_hub/utils/_deprecation.py:131: FutureWarning: 'cached_download' (from 'huggingface_hub.file_download') is deprecated and will be removed from version '0.26'. Use hf_hub_download instead. warnings.warn(warning_message, FutureWarning) variables.data-00000-of-00001: 100% 388M/388M [00:01<00:00, 219MB/s] variables.index: 100% 22.6k/22.6k [00:00<00:00, 88.3MB/s] keras_metadata.pb: 100% 654k/654k [00:00<00:00, 284MB/s] saved_model.pb: 100% 5.71M/5.71M [00:00<00:00, 233MB/s] selected_tags.csv: 100% 254k/254k [00:00<00:00, 3.77MB/s] Traceback (most recent call last): File "/content/kohya/finetune/tag_images_by_wd14_tagger.py", line 515, in <module> main(args) File "/content/kohya/finetune/tag_images_by_wd14_tagger.py", line 164, in main from tensorflow.keras.models import load_model ModuleNotFoundError: No module named 'tensorflow' /bin/bash: line 1: F/dataset: No such file or directory /content/kohya/venv/lib/python3.10/site-packages/diffusers/utils/outputs.py:63: FutureWarning: torch.utils._pytree._register_pytree_node is deprecated. Please use torch.utils._pytree.register_pytree_node instead. torch.utils._pytree._register_pytree_node( rich is not installed, using basic logging using existing wd14 tagger model Traceback (most recent call last): File "/content/kohya/finetune/tag_images_by_wd14_tagger.py", line 515, in <module> main(args) File "/content/kohya/finetune/tag_images_by_wd14_tagger.py", line 164, in main from tensorflow.keras.models import load_model ModuleNotFoundError: No module named 'tensorflow'
The dataset maker is getting the File "/content/kohya/finetune/tag_images_by_wd14_tagger.py", line 6, in <module> import cv2 ModuleNotFoundError: No module named 'cv2' Traceback (most recent call last): File "/content/kohya/finetune/tag_images_by_wd14_tagger.py", line 6, in <module> import cv2 ModuleNotFoundError: No module named 'cv2'
idk if this is possible, but could you perhaps move the 'caching latents' to the dataset maker?
(idk how any of this works, the answer could just be 'no thats not possible thats not how that works')
anyway I ask because, as a free user, you gotta make every second count. being able to move one of the long-ish steps off of the training collab would save some time.
That wouldn't work, you can't cache latents in a different notebook.
Sadly it would have to be in the same training environment.
ktiseos_nyx aw
richperryon727296 It's the law of environments, the same thing wouldn't work for a JUpyter notebook,. it'd be akin to usiung tow different computers XD
Its definitely possible but not something you would want to actually do. what @ktiseos_nyx said is irrelevant since you are saving files to GDrive anyways. The bigger issue is that in order to encode the images into latents you would need to load the VAE. This means probably using a GPU instance, which might already be worse than saving on free resources by using a cpu instance. You would then need to in the background with a thread be downloading the same fork of Kohya, dependencies and VAE. So hopefully they are ready to use when you are ready to encode them. So long as they are cached to drive on your GDrive, the other notebook should find them in the check and skip caching them there. But again, you would probably have to be using a GPU instance when running the dataset maker.
If you are a free user, use the uYouuUs version which runs faster for me https://colab.research.google.com/github/uYouUs/kohya-colab/blob/Experiments/Lora_Trainer_XL_V.ipynb#scrollTo=OglZzI_ujZq-
Saves at least 10 minutes in the setup for me. Great for free users like us.
Theres a simple version there that I've tried and is faster but you need to zip up the dataset to use it.
@ShunaRimuru Well on google colab it may be "POSSIBLE" -- even on Jupyter it MIGHT be but the thing is sometimes it doesn't always work And yea -- if yo'ure loading a vae on google colab that takes more resources -- But hey there's a workaround for free users yay LOL -- i might see what research that takes me to impliment in the non-free jupyter version i've made -- which is based on Holo's colab :D
@ktiseos_nyx its not "maybe" possible, its definitely possible. The real question is if you should. The answer is usually not. No real benefits or gains from doing this.
@ShunaRimuru Well, i coudln't see the options in that notebook XD it's not TWO DIFFERENT notebooks -- which that's what the user was asking : Can you - - and ion theory 'YOU COULD" but there's problems: KohyaSS doesn't alwayse liek re-reading the same cache, it can and it can work - but GoogleCOlab's notebooks are ephemeral storage, not persistant.
@ktiseos_nyx Yes, hes asking about caching the latents in the dataset maker so the training step can just read them, in theory saving time. Kohya not recognizing cached latents are due to the kohya version/branch, some include alpha channels, others do not, some name them the same as the img name, others just name them a number and img size. If you were to attempt to do this, you would need to make sure you cache latents with the same version of kohya as the other colab notebook. Again though, this will barely save time at best and at worst cost you even more time than if you didn't do this.
@ShunaRimuru That won't work because you can't pass the mto the lora trainer, he wans to TRAIN A LORA and then -- Put it this way it may. cause errors down the line dependingo n how colab handles it, you're right "YOU CAN IN THEORY" and maybe a few people have- but pre cached latents can get corrupted, and i couldn't se IN THAT specific notebook where tyou can "CACHE LATENTS" when t's part of the lora training process
@ktiseos_nyx Im not sure if you were misguided or something, but its only theory because its not worth making it(which would make it real instead of theory). latent corruption isnt very common and more than likely you are running into is a version mismatch for the latent caching. You need to use the same code to train as what was used to turn them into latents.
And no, you wont see an option to do it... as I've said multiple times, its not worth it to make it. So why would it already be an option?
@ShunaRimuru I do keep missing your point LOL, because here to solve this : I agree in theory i'd be neat - i only disagree beuse of google colab's storage, that doesnt make me right it's just my experience -- You CAN still use precached on Jupyter becuse if you're doing it in the same instance.
@ktiseos_nyx Both, the trainer and dataset maker notebooks here save to google drive. If you read the guide you are commenting in, you would see there are 2 notebooks, dataset making and the other for training. If you cant see how the dataset can be used in different instances (One creates the dataset, the other trains on it), then you are truly lost. Basically the dataset maker, saves the dataset from the instance drive, over to your personal "cloud" google drive. The trainer notebook then loads that dataset from the previous notebook onto it. The only difference if caching latents were added to the dataset maker would be that it would also save the .npz latent along with the rest of the dataset.
Again, if were to actually implement this, it would probably not save you time, and instead waste resources.
@ShunaRimuru "IF I READ THE GUIDE" --- Shuna, my bud -- i've used his notebooks XD his notebooks are why i was inspired to vibe code through making my Jupyter edition -- I've USED colab. I'm not saying i'm 100% right, it's just epxerience and thought here on in - i'm aware there is things i've seen ahppen that are like "ROGUE CASES" - but the ephemeral storage isnt' the notebook, it's the INSTANCE you get when you load the notebook, you dont' get the same storage, and also you'd need to make sure you'd re-code Holo's notebook to handle pre-cached latents. Or at least teh other one, which MIGHT be doable, but it's finickey. The thing is i just stay clear of that idea onyl because 9 times out of tent the cache latents phase is the faster end of it, youre shaving what 2 minutes off max - unless you';re doing higher number datasets -- i don't quite get why needing to split it into a different phase is a big thing, like caching latents may even on the dataset ntoebook cause the google AUP to flip out
@ktiseos_nyx My dude, your code must be a safety hazard. I can't fathom someone attempting to code without knowing about detachable storage/cloud storage. Even kids these days know what google drive is.
And yes, As I mentioned like 5 times before, it's not worth it because you barely save time, or worse, lose time.
Explanation like you are 5: You put latents to USB Drive(Google Drive), and then on the second instance, you read from USB Drive. You only use the instance storage for kohya, dependencies and the model. The actual dataset is never in the instance storage.
@ShunaRimuru I'm not using Google Colab, i'm using VastAI/Runpod, which is docker containers, honsetly at this point i think you're just being agressive for no reason lol. I understand I MISREAD half of it, i understand you think i'm a complete numpty but maybe you should actually THINK before assuming someone's code is a mess. It's AI, nobody's code is perfect and in ML fro Stable Diffusion and shit i'm sure Pylint woudl run circles around most shit. I'm AWARE i dont program by myself, and that i use LLM's, but i'm aware of the instances where i use my content, and it's not "EPHEMERAL" storage like Colab, wihch isn't DETACHABLE - Kohya's system doesnt LIVE on your google drive, just your dataset, which is why it's buggy to do it the way this person was asking, and you're right it LIKELY is not going to save a lot of time, and in theory "YES IT COULD BE DONE" but even with a dataset notebook you're still loading a GPU instance of sorts because a TPU is not a CPU only machine, ti's still 10-12 gb of VRAM, and it's still used to run ONNX and everything. The part you'd run into problems with is: Who's colab notebook wold have the code in time, and who's would validate the cached files, is it secure enuogh to cache the files, would someone just randomly hack into the user's instance nd put random ones in - you can't just run a cell an go "CACHE MY LATENTS BRO" - in the Command line instance it's a part of the training process, it's nto that it's not DOABLE in theory it's that it's not logical.
@ktiseos_nyx Sorry, I just feel like you are ignoring everything i'm saying and making me say it again.
1. You are replying on a Google Colab specific place.
2. Yes, as I mentioned on my first reply. The need for a GPU instance is what makes it not worth it.
3. If you are training on these notebooks, they run on kohya's scripts. Kohya's scripts validate the cached latents if they are found in the dataset directory. If they are not there or they are invalid, it will make new latents. So once again like in my original reply, the key is to run the same version of Kohya on both notebooks.
4. Idk what you mean by hacking into an user's latents. How would this be any different if someone somehow hacks you and replaces your dataset anyways? Not sure how this would happen, but the latents themselves wouldnt change anything.
I think the issue fundamentally is a misunderstanding of latents. Latents are the "stable" in stable diffusion. The VAE encodes and images and can decode it as well. This makes the image smaller so its less numbers to work with. Think of it as changing formats similar to F to C and back. 32F = 0C, The issue with cache mismatches is due to what gets encoded. For example, older versions did not use images alpha channels. So it could go say AABBCC -> AC, and when decoding, AC-> AABBCC, but newer ones would be something like AABBCCDD ->ACD. When passing the old AC, into a newer one, it would expect ACD, not AC. So you need to make sure that the code that calls the VAE to encode, is the same that is going to decode.
@ShunaRimuru I have no clue what is going on anymore, but im pretty sure when I started the same collab in the same instance with the same cached-to-drive latents, it always just re-caches them anyway.
Even if my collab session never terminated, never reset, or whatever.
idk.
Maybe I'm hallucinating and I'm misremembering. I'll test next time I train something.
I guess my next question is "whats even the point of caching latents to drive if everything re-caches anyway?"
@ShunaRimuru If you feel like i was intentionally ignoring you then i have to apologize: I was not. I'm autistic AF, and sometimes i repeat the same subject with different words. It literally seems like we're on the same page LOL. And the reason i mentioned Jupyter is it's almost the same code apart from minor differeces, and Colab RUNS on Jupyter notebooks just Google flavored code. In some ways GPU rental is similar, but you could in theory do more finagling and wiggle room with a rented GPU -- but the only time a "RENTED GPU" that would be. free if they use my notebook setup that's roughly based on Holo's would run into. the same exact type of issue is: Amazon Sagemaker, it's basically out of all of the instances i've seen t he most like using Google Colab without using the EXACT same setup -- and i men tioned AUP several times because Google's AUP may be solid in writing, but it always felt like it was even on pro - slowing everyone down and kicking poeple off instances if you trained a lora. So you're right, i accidentally ignored you, i apologize, we were on mostly the same page. My code is probably a LITTLE JANKY sure - :P but i'm aware i'm not perfect, and I should've spent more time reading a litttttle more what you were saying. (Look even 10 times over of readintg the same thing i have a bad habit of repeating myself)
@richperryon727296 Yeah if you aren't used to it, it can be a bit confusing, but heres some hopefully helpful knowledge. In this case instance and colab sessions are the one and the same thing. Starting a colab session, creates an instance which is google's computer that actually runs.
Secondly, it can help to think of latents as Zip files. Turning image1.png into image1.zip, they are not technically the same, but it is a representation of it, just in another form. You might zip things up with a program like Winrar, similarly here we turn images into latents with the VAE. We do this because doing diffusion on large amounts of pixels needs an insane amount of resources, so we downscale, 52x52 in the case of SD1.5, 128x128 in the case of SDXL, its the "stable" in stable diffusion.
With this, we can see we need to use the latent version of an image and not normal types. So, when training, you can either keep the VAE loaded and turn .png -> .npz, which will take up more vram and time to do every time. Or you can turn every .png -> .npz in one go, and use those. Caching just means saving it as the .npz format. This means you can't do certain things like, the flip augmentation feature because its already in .npz format.
Now, with this knowledge, caching to drive means not only do you convert the image into .npz, you also save it to the drive. These notebooks save it to your google drive. The reason @ktiseos_nyx was mentioning was that it would save to the computer it is running on, which would be deleted between swapping notebooks/instances. However, this does not apply here as they save to your personal google drive.
Finally one by one, not caching latents, lets you enable certain features, but it will either use more resources to keep the VAE available. Caching latents, will turn them into latents in one go and save time and resources as they are ready to go. Caching latents to drive, will save the latents to drive as well.
So, caching latents without saving to drive, will generate them every time. This means, if you make a mistake and cancel, or it crashes and you need to re run, you will have to regenerate them. Caching latents to drive, will save the latent and all it will need to do is verify it is correct.
TLDR: Unless you need specific features, caching latents to drive is the best choice.
@ktiseos_nyx the problem is that the colab instances come with custom python packages built in. They aren't available outside of it as far as I'm aware. With it, it is as simple as importing drive from google.colab, and mounting it to the instance. That allows it to read and write from your personal google drive. Which you use to save both the dataset and the finished loras. It would be exactly the same to save latents there while you are at it. And in fact, if you do use these, you can check your own dataset folder and find the .npz files in the dataset folder so long as you enabled caching to drive.
So you would need to save the latents in the same way you save the finished lora file. And when training you would need to move the .npz files a long with the dataset.
@ShunaRimuru Yea so on Jupyter it's mostly "THEORETICAL" because my epxerience has been that in the first few times of using Bmaltais: his systems didn't like it - but i would be literally CURIOUS about seeing if it WOULD be DOABLE on jupyter as an add ed "edge case " factor, i'm aware i said it was "ILLOGICAL" becaues i'm used to colab, but pfft - our "tit for tat" on this gave way for me thinking outside the box finally and going "Hmmm maybe i should test this weird case" -- i mean IT COULD WORK ON COLAB too possible lik eyou just said with moving the NPZ files or just leaving in them your dataset fodler on drive - but my only question is: are the cached "code wise " only for the systme they're cached on or? -- Not bucking just askin :D
@ShunaRimuru ah so its mainly just memory reasons.
Cool, thanks :)
Dropping into the discussion quite late, hello. You CAN cache latents to disk without running the trainer, as long as you use the same algorithm the trainer uses and download the same vae. I just don't think there's any benefit to doing it separately, and it would be extra hassle to implement, as I've tried something similar before.
The dataset maker have this error in the ''Tag your images'' step, and can't continue to training the dataset.
Is there a reasons XL loras come out gray after training? Ive been using the current XL trainer since the legacy XL was busted for me (errors). But after training a lora for 2 hours and then testing them. some of them work but others partially can be used on certain models but just turn grey for general use.
I then have to rely on the cite trainer with more or less the same settings and the loras alteast work with no issue though less accurate ofourse.
I was thinking it has something to due with the size of the images. As the Unet settings didn't seem to make a difference of the issue. Or perhaps another setting.
Are you useing the SDXL vae?
@ktiseos_nyx well I didnt change any of my settings since using PXL and ILL loras for about a year now. it just seems random as I cant pinpoint whats causing it. Because when I re upload my dataset to google (or to another training account) it sometimes fix the issue.
My only other guess its that it may have something to do with tagging. Honestly its fine if there's no solution its just means I have to test some of the lower epochs before I commit to the full training now. So I don't waste credits finding out after it finished that it don't work.
@True_Might Tagging woudn't save the greyness, and tbh - i'm not trying to take you away from Holo's colab but if oyu're paying for google you'll get a better deal renting GPU's than paying for ephemeral storage and AUP wildcards - Not saying you suck or ANYTHING lol, Holo's notebook is the reason i got nerdy and made a non colab notebook set up for Vast/Local/Runpod etc
What model are you training on? I have a suspicion illustrious 2.0 might have issues with my trainer because of the resolution. Other than that, I sadly can't think of a reason why your images look grayish.
@holostrawberry nah just the base illustrious 0.1 or whatever. I Just started making them for a couple of weeks now. if there is a better model to train for ILL that be cool to know. But only the last few loras was having this issue. And again I just reupload the lora or redo the auto tagging and that usually fixes it.
changing repeats/epochs/precision/N.dim/N.Alpha seem to have not made any difference. the learning rate I just leave alone since its pretty decent so far. It could be something im doing wrong so I was just asking around so I could perhaps narrow down what it could be. Ill just continue on.
broken for me too, use https://colab.research.google.com/github/uYouUs/kohya-colab/blob/main/Lora_Trainer_XL.ipynb its working like before.
100 images × 1 repeats × 10 epochs ÷ 4 batch size = 250 steps
Any chance you can tell me the math if its more than a 100 but less than a 1000?
For some reason almost every LORA I've trained recently on the XL trainer does nothing and barely resembles the training data, I never had this problem before and I'm using the exact same settings as I always have. If anyone has some good settings for a LORA of a real person, please help!
Try this notebook instead: https://colab.research.google.com/github/uYouUs/kohya-colab/blob/Experiments/Lora_Trainer_XL_V.ipynb
I was trying to make an illustrious lora but keep getting this: torch.OutOfMemoryError: CUDA out of memory. Tried to allocate 510.00 MiB. GPU 0 has a total capacity of 14.74 GiB of which 250.12 MiB is free. Process 38593 has 14.49 GiB memory in use. Of the allocated memory 14.07 GiB is allocated by PyTorch, and 312.76 MiB is reserved by PyTorch but unallocated. If reserved but unallocated memory is large try setting PYTORCH_CUDA_ALLOC_CONF=expandable_segments:True to avoid fragmentation. See documentation for Memory Management
What went wrong here?
Had a similar error a while ago too. In my case it actually had to do with the virtual memory of my SSD. It filled up a bit faster than expected and I didn't realize at all. I had to troubleshoot it like this, hope it helps!
Right-click This PC → Properties → Advanced system settings.
Under Performance, click Settings → go to the Advanced tab → Virtual memory → Change.
Uncheck Automatically manage paging file size for all drives.
Select your fastest drive with enough capacity (SSD or NVMe).
Choose Custom size and set, for example: Initial size: 32768 MB, Maximum size: 65536 MB (32–64 GB).
Click Apply and restart your computer.
How do you train art style locons? Do you just choose it in lora_types? Because that's what I've been doing and the output has no effect on the generations (as opposed to character loras which do)
Styles need to train for longer, it also depends a lot on the consistency of the dataset
@holostrawberry I used 64 pages of one comic and trained for 50 epochs
@bonkabun2185 that's strange, how did you tag it?
@holostrawberry It was for art style so I didn't tag it. I also set text_encoder_lr to 0
@bonkabun2185 Well that right there is your problem... You need to tag it. Setting the lr for the text encoders to 0, just disables training on the text to token part of it. Without tags you dont get any tokens for the text output for the diffusion part to use in training.
@ShunaRimuru I just checked and turns out I did use tags. Gonna try again now
Hello. Hi there, training LoRA for SD1.5 is currently encountering an error. When I train, the resulting character is not matching the character in the data
ERROR: Could not find a version that satisfies the requirement torch==2.4.1+cu121 (from versions: 2.2.0, 2.2.1, 2.2.2, 2.3.0, 2.3.1, 2.4.0, 2.4.1, 2.5.0, 2.5.1, 2.6.0, 2.7.0, 2.7.1, 2.8.0, 2.9.0) ERROR: No matching distribution found for torch==2.4.1+cu121
ERROR: pip's dependency resolver does not currently take into account all the packages that are installed. This behaviour is the source of the following dependency conflicts. torchvision 0.23.0+cu126 requires torch==2.8.0, but you have torch 2.4.1 which is incompatible. torchaudio 2.8.0+cu126 requires torch==2.8.0, but you have torch 2.4.1 which is incompatible.
Try this version. https://colab.research.google.com/github/uYouUs/kohya-colab/blob/main/Lora_Trainer.ipynb I'm not sure what the problem is, but this repo seems to work when the main one doesn't
@ShunaRimuru thanks you
@ShunaRimuru Hey friend, the LoRa SD15 training is giving me an error again. Do you know any other solutions? Thanks
is the dataset maker not working? i've not been able to use it at all. it pops error 401 ,,,,,,
Hey friend, the LoRa SD15 training is giving me an error again. Do you know any other solutions? Thanks
Hey SD15 is not supported by strawberryhollow anymore. I use uyouus. You can open an issue directly there to let him know. However, what you can do in the mean time is on the top left of the colab, you can click Runtime, and then Change runtime, and pick the 2026.01, to rollback google's changes one version, this usually fixes it most of the time until he patches it.
@ShunaRimuru uyouus? Link?
@ShunaRimuru thanks you
Details
Available On (1 platform)
Same model published on other platforms. May have additional downloads or version variants.