IMPORTANT UPDATE:
After the Comfy update my custom node always gives error like "There is no CUDA kernel available" no matter what I try to do for fix.
I can only recommend all of you guyz and gals to search for "qwen 3.5 vl" in Comfy registry of the nodes.
I am very sorry, but I have no exact idea what causes it (googling and githubbing didn't make me know the root cause).
As for "heretic support" it is easy to add heretic model into the available QWEN 3.5 VL node from registry. It is needed to edit the file with the list of models by adding the "someuser/model-name" element into the array of model name in one or two .py files and add a SYSTEM_PROMPT options. I did it on my side but have no resources to make another release of the modified node that will easily adoptable for everyone's setup.
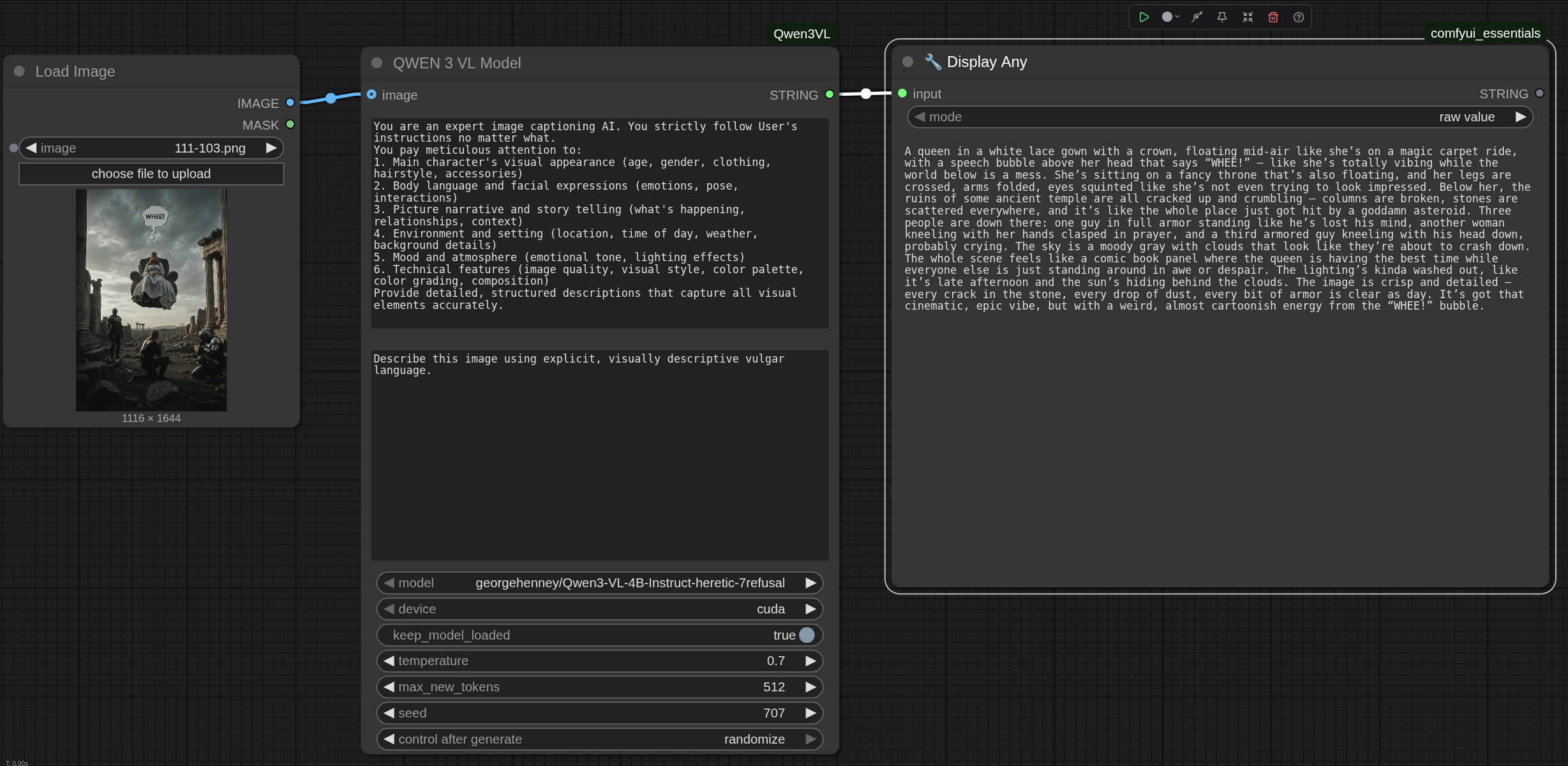
Minimalistic custom node that implements QWEN 3 VL image captioning (uncensored).
Highlights:
15-17 seconds per image
No local LM Studio or remote VLM service required
Smart memory management by ComfyUI
System Prompt can be specified
Supports 'cuda', 'cuda:0', 'cuda:1', 'cpu' devices (not yet fully tested yet)
By default uses the Qwen 3 VL model that was abliterated (de-censored) using "Heretic" technology.
Instructions:
If you downloaded full 6.58Gb archive then you need to split it.
Folder "Qwen3-VL-4B-Instruct-heretic-7refusal" must be placed into path: "ComfyUI/models/prompt_generator/".
Archive "ComfyUI-Qwen3VL.zip" must be unzipped into "ComfyUI/custom_nodes".
Restart ComfyUI backend and frontend (browser) after the manipulations above.
Good luck!
Comments are welcome.
Description
FAQ
Comments (39)
Brilliant! This thing works even without input image, very useful to make T2I prompts.
Yep... Qwen family is a very functional LLMs and VLMs
Followed the steps/instructions but ran into this error "OSError: Can't load image processor... preprocessor_config.json"
EDIT: OH NVM, my comfyui was installed with StabilityMatrix and stabilitymatrix uses a shortcut folder for all its models, I put the folder into this wrong folder
D:\StabilityMatrix-win-x64\Data\Models\prompt_generator
The correct one is the the direct and correct path where it could read it-
D:\StabilityMatrix-win-x64\Data\Packages\ComfyUI\models\prompt_generator
Looks like the issue with paths for the models. Can't test on Windows because using it on Linux.
"prompt_generator" is the name of the model folder used in original Qwen2.5 VL script, but I changed it to other.
I remember that I had the same error message when I didn't download all the config files.
On the huggingface the repo with Heretic model don't have exactly that file "preprocessor_config.json". So, I took this file from original QWEN3 VL repo.
Maybe somehow this required file was removed,
PS: In the end of your message there is a "The correct one..." - this means you resolved the issue? If not, then check the things mentioned in this message.
@homoludens yes Ty works now, wrong folder path I used
BTW does it usually normally take like around 100 seconds to load up the model? cause it seems kinda long
First time only. On my side with RTX 4060 Ti it takes 15-30 seconds rep image starting from second run.
It slows down on big image. I usually reduce the image size to 0.6 ... 1Mpx.
It also can slowdown if "Keep loaded" is switched ON (some errors in memory management might lead to duplication of this model in VRAM).
I usually keep this switch OFF. My models are on fast SSD. So, no big profit in keeping them loaded between runs. Didn't investigate deeply, but switching this off makes everything goes smoother on my machine.
Also, it can be slow if one workflow contains this node and usual rendering nodes (SDXL, FLUX, ...). ComfyUI smart memory management tries hard but cannot keeep them working fast together.
Also 2, you are working in Windows. Starting from some version of NVidia driver there is a feature called "Unified memory". This thing merges RAM and VRAM in virtual space. ComfyUI maybe don't know which space on which side. So, smart memory management doesn't work. Depending on PCI-E width and version your slowness might be caused by transferring lots of data between RAM and VRAM.
What to check? Try the separate minimal workflow where only this node uses big amount of VRAM. Also, make sure the models are on fastest SSD, if possible.
@homoludens Yes, thanks for the tip. It really struggles with any images with a dimension above 3000x3000. Literally takes forever, I tried a 3000x5000 image and after 5 minutes I just gave up and cancelled the progress but it refused and just froze, had to restart my comfyui.
I finally got the touted 15-17 second speeds you advertised by using a 512x512 image upload. Seems I was using too big of images. Qwen3 VL really struggles with anything beyond 1024x1024.
I guess for most images I will just stick to google gemini, but for the ones gemini refuses I will use this.
@fox23vang226 For images above 1536x1536 I suggest you to use Ultimate SD Upscale node. It renders in tiles which results in better VRAM usage.
I have re-checked i have the folder on the correct path: "ComfyUI\models\prompt_generator\Qwen3-VL-4B-Instruct-heretic-7refusal" and config.json is there, but i'm still getting this message:
Can't load image processor for '(...)l\ComfyUI\models\prompt_generator\Qwen3-VL-4B-Instruct-heretic-7refusal'. If you were trying to load it from 'https://huggingface.co/models', make sure you don't have a local directory with the same name. Otherwise, make sure '(...)\ComfyUI\models\prompt_generator\Qwen3-VL-4B-Instruct-heretic-7refusal' is the correct path to a directory containing a preprocessor_config.json file
Facing the same issue
Was able to solve this by manually downloading the preprocessor_config.json from
https://huggingface.co/svjack/Qwen3-VL-4B-Instruct-heretic-7refusal/blob/main/preprocessor_config.json
Workflow, unable to find the workflow in your case.
Look into archive (Download files)
@homoludens same, download both, can't find worklow
@Xriston OMG... This is my bad. I thought I've included the json or posted the image with workflow. So stupid mistake. Sorry I misled you.
There is actually no need in any prior workflow.
Just unzip the custom node into "ComfyUI/custom_nodes" folder, restart comfy and reload the page in browser or press R to update the nodes in browser. After that you can double click the background and press search. Input "qwen 3" into search box. The node goes with reasonably good system prompt by default. You need to edit the user prompt only. Or, if it is needed, you can adjust the system prompt as well.
Again, sorry for my mistake. Too busy with training... [shrugs]
@homoludens thanks!
@homoludens thanks! I have already done it myself, there are no more problems.
can anyone please post a json of the full workflow? Can't figure it out. Thank you.
@AI_Wanderer Unfortunately it will not work with high chance. After the Comfy update my custom node always gives error like "There is no CUDA kernel available" no matter what I try to do for fix.
I can only recommend all of you guyz and gals to search for "qwen 3.5 vl" in Comfy registry of the nodes.
I am very sorry, but I have no exact idea what causes it (googling and githubbing didn't make me know the root cause).
Is it possible to use Huihui-Qwen3-VL-8B-Instruct-abliterated instead? It appears to be quite popular.
The "Qwen3-VL" in the name suggests that it should have the same architecture as the model used by me.
Open `ComfyUI/cusutom_nodes/ComfyUI-Qwen3VL/nodes.py` in any text editor, add a `,` after the last model in array and add your model (follow the format like "user_name/model_name"). Save and restart ComfyUI backend (console) and frontend (browser). Then press right mouse button on my Qwen3VL nodeFix (recreate)` command.
These manipulations must update the list of the models, so you can download and test your option.
so how to add custom models? i dont wanna use a fp16 model. i tried to change the nodes.py but i could only get it to not finding the model.safetensor
this issue is mostly with gguf, it looks for those 00001 of 00003 models.
@kurd GGUF support needs to be coded separately. Right now it is tested with safetensors only. sry.
@kurd Probably it can be done by looking into GGUF nodes for unet models, but I have no resources right now to go this way.
I know cuda but,
what 'cuda', 'cuda:0', 'cuda:1' stand for?
It seems actually not working... but...
cuda - default GPU
cuda:0 - GPU with index 0 for this running instance of comfyUI (might not be in sync with GPU ID from /> nvidia-smi utility)
cuda:1 - secondary GPU
cuda and cuda:0 supposed to be the same
If you set an environment variable called like CUDA_VISIBLE_DEVICES=0,1
it is supposed the ComfyUI will be able to see both. But I didn't manage to see it in real runtime.
@homoludens I see, Thx U.
How can this be setup to run through batches of images? and save the txt in the same folder?
I am using the Int primitive with an Action after generation set to increment. You can basically name the images in sequencial numbers like 1.png, 2.png, etc. In comfy you can convert the seq num into a string and use a string replacement to replace some token in full path with the num string. After the caption is ready, you can use a node "Save batch image and caption" (name similar like that; can't tell right now more precise). You need some node that save image and txt with the same base name but different extensions.
And finally you run comfy in Instant prompt mode. It will add new job when queue gets empty. But then you need to watch the number - it will overflow eventually and will try to caption black images without any error.
On RTX 4060 Ti and RTX 3060 it takes 15-19 seconds per image (info for reference)
keep running into the issue of when updating comfy it replaces your node with the default qwen 3vl as they are named the same i think
possibly... quick fix is to edit the py file on your side or by uninstalling the other qwen 3 vl node. There was no QWEN 3 VL node in Comfy.Core ATM of this node development. On my side updated Comfy don't have such conflict either. There is two possible sources of the error:
1. You have installed the other package with the same name
2. In your workflow you didn't Re-Create the node after edits. Try Right Mouse Button -> Fix (recreate)
I just renamed the folder "Qwen 3 vl" in the download to "qwen 3 vl (insert something here like 1 or A or something). then reloaded front and back end (shut down and restarted.)
it's fxxkkkking good!!!!! I used it to write muuuuch better prompt!!!!
Yeah... even QWEN 3 VL vanila is good. Heretic abliterated is better
Where can I find your workflow JSON file?
so I try to install all the necessary nodes, but I am unable to locate the node named 'display any'.
good job mate