Update:
I have had very good results with the new Lightx2v LoRA (https://huggingface.co/Kijai/WanVideo_comfy/blob/main/Wan21_T2V_14B_lightx2v_cfg_step_distill_lora_rank32.safetensors) when used with this workflow. You can read more about this LoRA and its origins here (https://civarchive.com/models/1585622/self-forcing-causvid-accvid-lora-massive-speed-up-for-wan21-made-by-kijai). That writeup suggests a complex workflow is needed to use this new tool, but in my experience it works very well without the added nodes. To use it, you only need to do three things:
Add the LoRA to the provided LoRA loader node in the Settings area.
Change CFG to 1.0.
Change steps to a value anywhere from 4 to 20. I've been using 10 steps and my results have been very good.
Using this LoRA did not change my VRAM use at all and the video was produced MUCH faster than normal. It's so fast, it's easy to extend the transition time from 3 seconds up to 5 seconds to get a full 5 seconds of new material in the video and the result was still much faster than before.
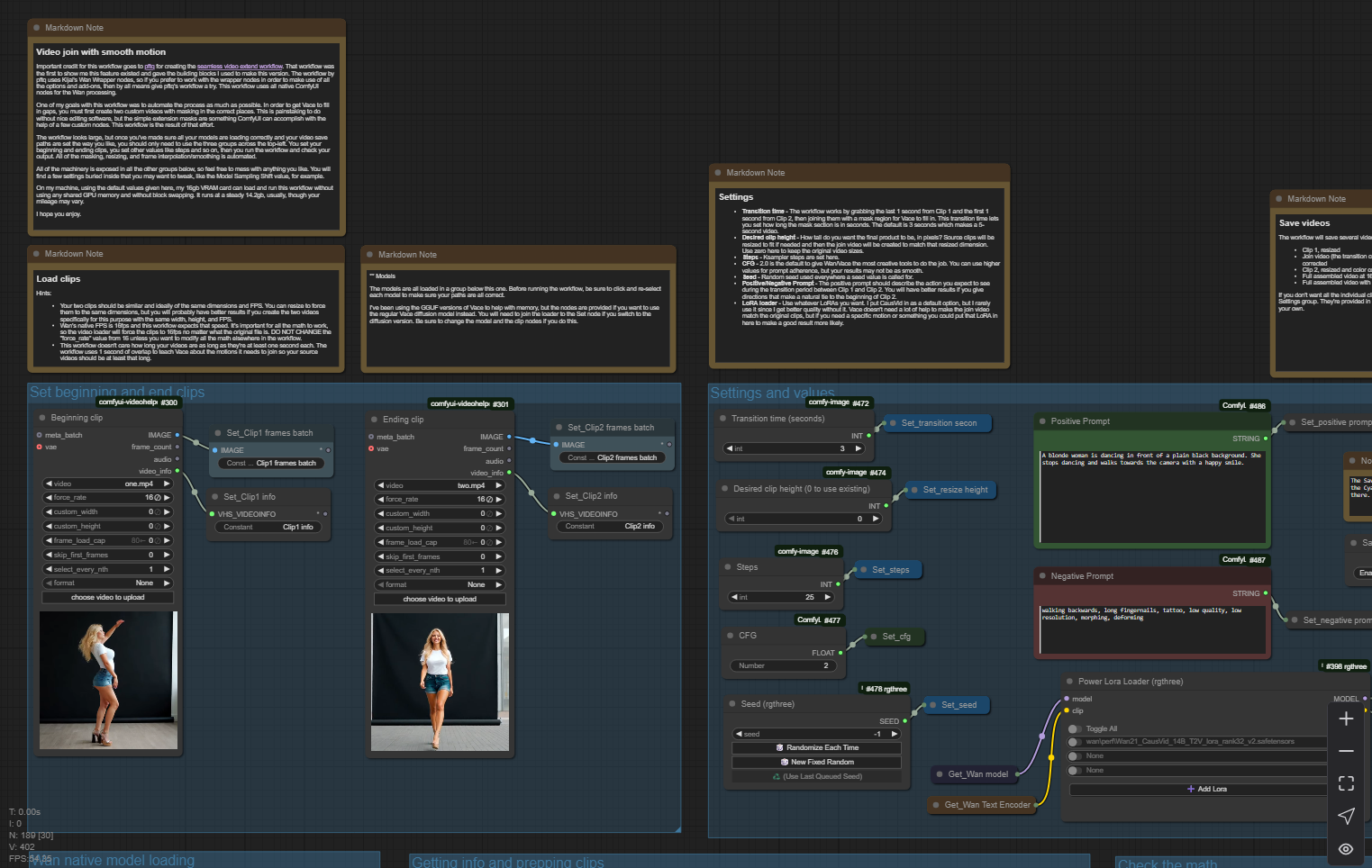
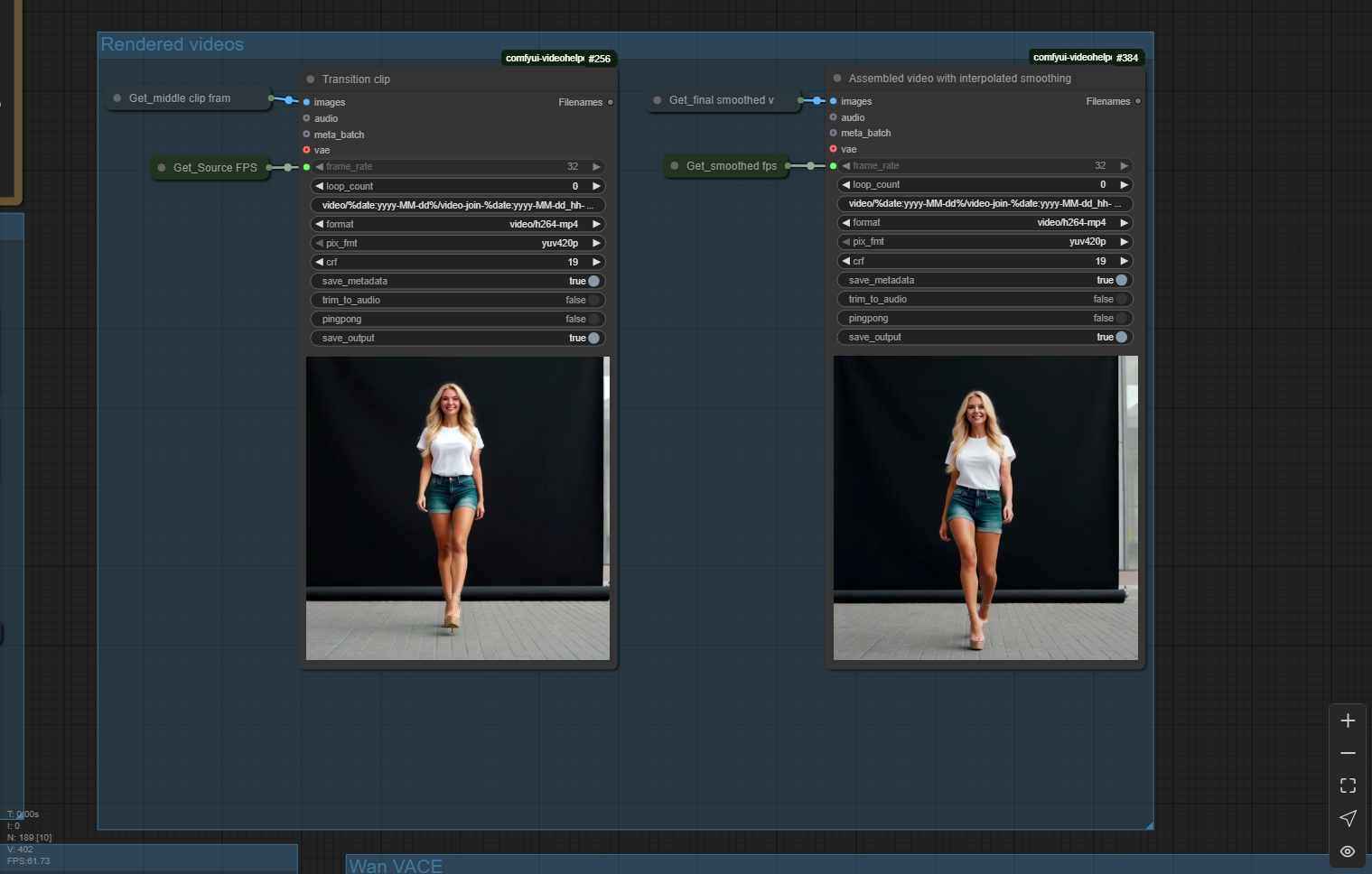
This workflow uses Wan with Vace to seamlessly join two video clips with a transition video that smoothly incorporates the motion on either side of the transition. The result is a 3-part video that runs without the jarring motion changes that you get by doing a simple "extend this video from the last frame".
Important credit for this workflow goes to pftq for creating the seamless video extend workflow. That workflow was the first to show me this feature existed and gave the building blocks I used to make this version. The workflow by pftq uses Kijai's Wan Wrapper nodes, so if you prefer to work with the wrapper nodes in order to make use of all the options and add-ons, then by all means give pftq's workflow a try. This workflow uses all native ComfyUI nodes for the Wan processing.
One of my goals with this workflow was to automate the process as much as possible. In order to get Vace to fill in gaps, you must first create two custom videos with masking in the correct places. This is painstaking to do without nice editing software, but the simple extension masks are something ComfyUI can accomplish with the help of a few custom nodes. This workflow is the result of that effort.
The workflow looks large, but once you've made sure all your models are loading correctly and your video save paths are set the way you like, you should only need to use the three groups across the top-left. You set your beginning and ending clips, you set other values like steps and so on, then you run the workflow and check your output. All of the masking, resizing, and frame interpolation/smoothing is automated.
All of the machinery is exposed and I hope it's tidy enough to follow without too many crazy node connectors, so feel free to mess with anything you like. You will find a few settings buried inside that you may want to tweak, like the Model Sampling Shift value, for example.
On my machine, using the default values given here, my 16gb VRAM card can load and run this workflow without using any shared GPU memory and without block swapping. It runs at a steady 14.2gb, usually, though your mileage may vary.
I hope you enjoy.
Description
FAQ
Comments (28)
Nice idea, I will try this. Normally I get the last frame of a clip as first frame for the new one, but character consistency suffer and color shift heavily. And having the constrain of the frame do not help. I hope this can allow for a better transition between the two
This works about half the time, but on some attempts I get an error in KSampler. The problem is coming from some attribute of the first vid, since I never get that error if I swap the first vid for one that I know works.
KSampler
The size of tensor a (25350) must match the size of tensor b (27000) at non-singleton dimension 1
Also, thank you for this, when it does work it is great :)
Width or Height resize
Width or Height resize
I've seen that error and it seems to be that vace is very picky about video dimensions and won't accept just anything. Sometimes you have to change both height and width and tell the resize nodes to crop in order to get a size that vace will work with. There are 4 resize nodes in total. Sorry that's inconvenient, I'll have to fix it in a future version
@darkroast175696 Thanks for responding :)
on default settings it join 2 clips but in between extended transition clip time is more than i thought and it also create unnecessary movements and result - how to reduce that time, which setting should i reduce to get perfect match ? i need only 1 or 2 sec extended transition duration between 2 clips.
Thanks for workflow it helped a lot, waiting for reply.
There is a node in the settings section near top left labeled transition length in seconds. It's set to 3 which renders a 5 second clip including the motion at either end. You can change that value to 1 or 2 for a quicker transition join between clips.
This is great! Exactly what I was looking for. However, I had difficulties installing the final nodes for the smoothing part. So I replaced them with the interpolation nodes used in this workflow - https://civitai.com/models/1604221?modelVersionId=1897238
There are quite a few choices for frame interpolation in comfy. The one in this workflow has given me the best results for me but that's subjective. I don't know why the installation gave you trouble. In any case I tried to make the workflow pretty spread out and straightforward so people would have an easy time messing around under the hood. I hope that was the case for you.
So I was also having issues with installing the original final nodes for the smoothing part. I've noticed (Not sure if its ComfyUI-related), but sometimes it fails to install "Missing nodes" if you simply go off the prompt "Install missing nodes". In order to fix the issue, a user needs to open Comfy Manager < View Custom Nodes in Workflow < Filter for "Missing" < Install.
This is what fixed it for me! :D
im still not sure whats the reason for it , but the result looks like as if my start and end clips arent being used.
If you post one of these videos (or share it in some file sharing service) with the workflow embedded, I can take a look at it and see if I can find the problem. I've used the workflow a bunch of times and also modified it to do just a video extend and it always works well for me, so it's probably something simple. If it turns out to be a failure of instructions on my part, I can take that chance to improve the notes in the workflow.
Seems a nice workflow. But iam not able to get the "round node" working.
Oh, right. I've had trouble with that node in a few of my workflows. I should release an update to this workflow with a replacement node. Sorry about that.
@darkroast175696 Thanks for your reply. Iam looking forward to your update. :)
@MrSmith2025 I just posted an update to this workflow with new custom nodes to replace the broken ones. You can download and give it a try.
@darkroast175696 Thanks for your message! Will try it out now!
I first tried out the safetensor version but iam getting error:
UNETLoaderb - ERROR: Could not detect model type of: E:\AI_Forge\Models\Diffusion\Wan2_1-VACE_module_14B_fp8_e4m3fn.safetensors
but the GGUF checkpoint is working. But iam getting very strange results. People are running backwards and forwards again. No smooth transition is generated.
But maybe this is the wrong workflow for me. I generate the first clip with img2vid and then iam doing a second clip with the last frame. The problem is not that these clips do not match. It fits perfectly, but the cam movement of the 1st and 2nd clip is different. So iam looking for a vace workflow that is able to generate a smooth transition between clip 1 and clip 2.
@MrSmith2025 I have not encountered the running backwards problem, so I don't have much advice for that. If you switch between gguf and a .safetensors model then you will need to switch which model loader node you use. One node only works for gguf models and the other node only works for diffusion models. They are right next to each other and one is disabled (purple in color) while the other one is connected. You'll have to manually switch that connection and switch which node is bypassed or alive if you want to use the other kind of model. Sorry I don't have a cleaner more automatic interface for that part.
@darkroast175696 Yes, i know how to reconnect nodes... ;-)
But its not working with safetensor files. Only GGUF. But its ok. But the result is not very satisfying. Ive also saw that you added the keywords "running backwards" into the negative prompt. So i thought you experienced the same problems.
@MrSmith2025 the backwards walking is a pretty common issue in wan 2.1. it even appears in 2.2 sometimes. I haven't seen it much when I'm using vace, but that was my standard negative prompt for wan 2.1 clips.
Was trying to recreate the one from a comfy live youtube clip and then this popped up. im using the fp8 version of VACE and get heavy colour change and ghosting in frames created. Any tweeks to deal with this?
I don't know the answer to this one, I'm afraid. I haven't had that problem myself. It sounds like maybe you're using a model somewhere that isn't completely compatible with the rest of your models? Not sure. I've always used the Wan Vace gguf (Q4) because vace is pretty memory hungry and that works best on my system. You could try switching to a gguf model and see if it runs better for you, I suppose.
Is there a reason why you chose to go with WAN2.1 vs 2.2?
I'm still trying to figure out the best way to extend the 5 second videos and this sounds promising, but i'd been using qwen image edit to build and modify my initial image, then wan 2.2 to create the 5 second videos. So i would figure the wan 2.2 and wan vace 2.2 would probably be the way to go, as it's even mentioned in the original workflow from pftq, but you've only got things set up with 2.1 here.
If 2.1 here makes the most sense, i guess i'd like to understand a little more if you could share some of your knowledge?
I haven't been able to find a wan 2.2 vace. There's the 2.2 FUN model, but it doesn't seem to do the seamless joins as well as 2.1 vace. Maybe I just need to play with it more. Also, I like doing transformation videos and haven't found any other model that does those as smoothly or as well as 2.1 Vace.
With all that said, if you're comfortable editing comfyui workflows, you could probably adjust this one to use 2.2 by adding a second ksampler and switching which models get loaded. All the existing stuff in the workflow that cuts and re-combines the finished videos should keep working as is. It might not be the perfect 2.2 workflow, but it would be enough for a proof of concept anyway.
Edit to add: I forgot to answer your original question, "why did I go with wan 2.1?" Answer: because I made this workflow before wan 2.2 was released. :)
@darkroast175696 Appreciate the response thank you so much!