
The compressed package contains 2 ComfyUI workflows for running:
1.Wan 2.1 T2V: wan2-t2v-upscale-v1.json
2.Wan 2.1 I2V: wan2-i2v-upscale-v1.json
Reference output:
On my RTX4060 8GB vRAM + 32G RAM i2v: Prompt executed in 2807.42 seconds
On my RTX5080 laptop 16G vRAM + 32G RAM i2v: Prompt executed in 1401.00 seconds
Requirements:
Models:
- wan2.1-t2v-14b-Q3_K_M.gguf (T2V) Put in: ComfyUI\models\unet
https://huggingface.co/city96/Wan2.1-T2V-14B-gguf/resolve/main/wan2.1-t2v-14b-Q3_K_M.gguf
- wan2.1-i2v-14b-480p-Q3_K_M.gguf (I2V) Put in: ComfyUI\models\unet
https://huggingface.co/city96/Wan2.1-I2V-14B-480P-gguf/resolve/main/wan2.1-i2v-14b-480p-Q3_K_M.gguf
- wan2.1_t2v_1.3B_fp16.safetensors (t2v model, used in workflow "v2v") Put in: ComfyUI\models\diffusion_models
- umt5-xxl-encoder-Q4_K_M.gguf (CLIP) Put in: ComfyUI\models\text_encoders
https://huggingface.co/city96/umt5-xxl-encoder-gguf/resolve/main/umt5-xxl-encoder-Q4_K_M.gguf
- umt5_xxl_fp8_e4m3fn_scaled.safetensors (CLIP, can use above if you modify workflow "v2v") Put in: ComfyUI\models\text_encoders
- wan_2.1_vae.safetensors (VAE) Put in: ComfyUI\models\vae
- clip_vision_h.safetensors (CLIP VISION) Put in: ComfyUI\models\clip_vision
- RealESRGAN_x2plus.pth (Upscale Model) Put in: ComfyUI\models\upscale_models
https://github.com/xinntao/Real-ESRGAN/releases/download/v0.2.1/RealESRGAN_x2plus.pth
ComfyUI Nodes:
- rgthree-comfy
- ComfyUI-KJNodes
- ComfyUI-VideoHelperSuite
- ComfyUI-Frame-Interpolation
- Comfyui-Memory_Cleanup (Not required if you modify the workflow)
If you have higher performance hardware, you can choose higher quantization models.
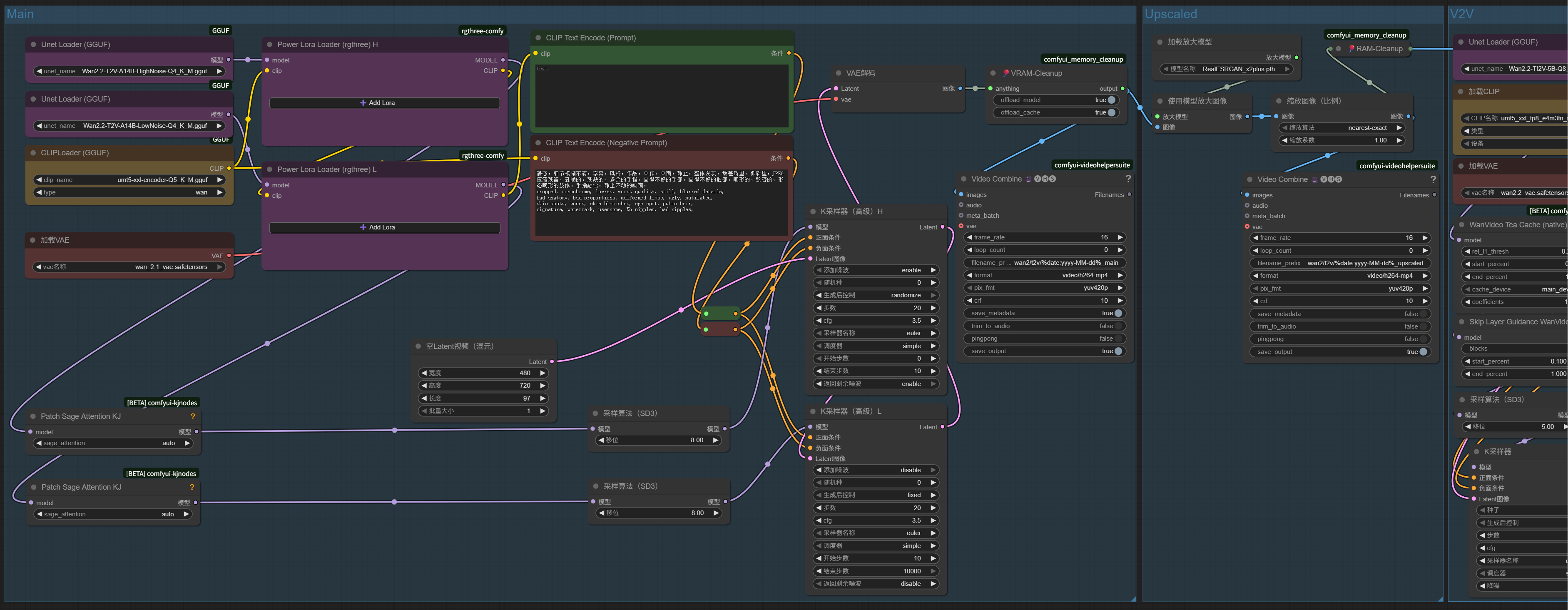
Description
The wan2-video-v2.zip compressed file contains 2 ComfyUI workflows for running:
1.Wan 2.2 T2V: wan2-t2v-upscale-v2.json
2.Wan 2.2 I2V: wan2-i2v-upscale-v2.json
Requirements:
Models:
Main Process:
- Wan 2.2 (GGUF), Put in: ComfyUI\models\unet; vRAM 16G can use Q4_K_M, vRAM 8G can use Q3_K_M.
- Wan2.2-T2V, download same or mixed sets for use.
OR
- Wan2.2-I2V, download same or mixed sets for use.
OR
- umt5-xxl-encoder-Q5_K_M.gguf (CLIP) Put in: ComfyUI\models\text_encoders
https://huggingface.co/city96/umt5-xxl-encoder-gguf/resolve/main/umt5-xxl-encoder-Q5_K_M.gguf
- wan_2.1_vae.safetensors (VAE) Put in: ComfyUI\models\vae
- Optional Loras, speed-up; Put in: ComfyUI\models\loras\LightX2V
Page Link: https://civitai.com/models/1838893?modelVersionId=2090458
https://civitai.com/api/download/models/2090458?type=Model&format=SafeTensor
https://civitai.com/api/download/models/2090481?type=Model&format=SafeTensor
The Main process's output is fine now, If you have a more powerful graphics card, you can simply change the output resolution.
If you don't need to increase the resolution, you can disable Upscaled and V2V processing.
Upscaled Process:
- RealESRGAN_x2plus.pth (Upscale Model) Put in: ComfyUI\models\upscale_models
https://github.com/xinntao/Real-ESRGAN/releases/download/v0.2.1/RealESRGAN_x2plus.pth
V2V Process:
- Wan2.2-TI2V-5B with wan2.2_vae OR wan2.1_t2v_1.3B with wan_2.1_vae all OK.
https://huggingface.co/QuantStack/Wan2.2-TI2V-5B-GGUF/resolve/main/Wan2.2-TI2V-5B-Q8_0.gguf
Put in: ComfyUI\models\unet
Put in: ComfyUI\models\vae
OR
Put in: ComfyUI\models\diffusion_models
wan_2.1_vae is same in Main.
- umt5_xxl_fp8_e4m3fn_scaled.safetensors (CLIP, or same in "Main") Put in: ComfyUI\models\text_encoders
ComfyUI Nodes:
- rgthree-comfy
- ComfyUI-KJNodes
- ComfyUI-VideoHelperSuite
- ComfyUI-Frame-Interpolation
- Comfyui-Memory_Cleanup (Not required if you modify the workflow)
If you have higher performance hardware, you can choose higher quantization models.