

















- Follow for more updates at http://discord.com/invite/TTTGccjbEa
- Try Model: Huggingface Playground
- Access to more training versions
- 中文模型说明
- QQ group: 1039442542
Introduction
Neta Lumina is a high‑quality anime‑style image‑generation model developed by Neta.art Lab.
Building on the open‑source Lumina‑Image‑2.0 released by the Alpha‑VLLM team at Shanghai AI Laboratory, we fine‑tuned the model with a vast corpus of high‑quality anime images and multilingual tag data. The preliminary result is a compelling model with powerful comprehension and interpretation abilities (thanks to Gemma text encoder), ideal for illustration, posters, storyboards, character design, and more.
Key Features
Optimized for diverse creative scenarios such as Furry, Guofeng (traditional‑Chinese aesthetics), pets, etc.
Wide coverage of characters and styles, from popular to niche concepts. (Still support danbooru tags!)
Accurate natural‑language understanding with excellent adherence to complex prompts.
Native multilingual support, with Chinese, English, and Japanese recommended first.
Model Versions
For models in alpha tests, requst access at https://huggingface.co/neta-art/NetaLumina_Alpha if you are interested.
Neta-lumina-v1.0
Request access at https://huggingface.co/neta-art/Neta-Lumina if you are interested.
Official Release: overall best performance
Neta-lumina-beta-0624
Primary Goal: General knowledge and anime‑style optimization
Data Set: >13 million anime‑style images
>46,000 A100 Hours
How to Use
Neta Lumina is built on the Lumina2 Diffusion Transformer (DiT) framework, please follow these steps precisely.
ComfyUI
Environment Requirements
Currently Neta Lumina runs only on ComfyUI:
Latest ComfyUI installation
≥ 8 GB VRAM
Downloads & Installation
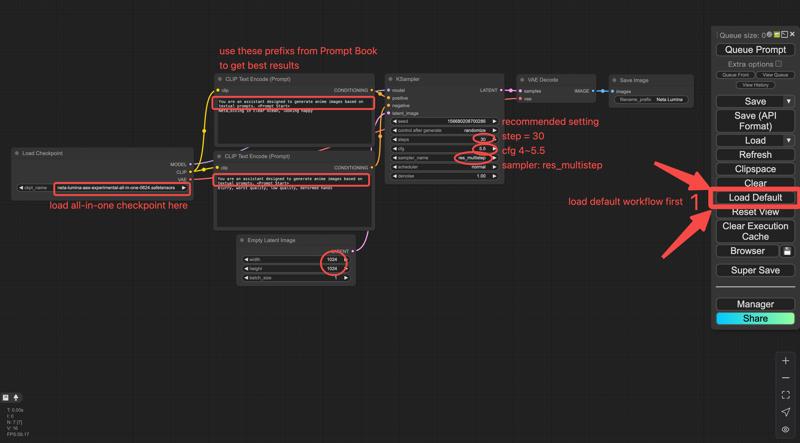
The model provided by Civitai is a three-in-one (te, dit, vae) packaged version, which can be run using the comfyui basic workflow without the need to download Text Encoder and VAE separately.
Original (component) release
Neta Lumina-V1.0
Hugging Face: https://huggingface.co/neta-art/Neta-Lumina/blob/main/Unet/neta-lumina-v1.0.safetensors
Save path:
ComfyUI/models/unet/
Text Encoder (Gemma-2B)
Download link: https://huggingface.co/neta-art/Neta-Lumina/blob/main/Text%20Encoder/gemma_2_2b_fp16.safetensors
Save path:
ComfyUI/models/text_encoders/
VAE Model (16-Channel FLUX VAE)
Download link: https://huggingface.co/neta-art/Neta-Lumina/blob/main/VAE/ae.safetensors
Save path:
ComfyUI/models/vae/
 Workflow: load lumina_workflow.json in ComfyUI.
Workflow: load lumina_workflow.json in ComfyUI.
UNETLoader – loads the .pth
VAELoader – loads ae.safetensors
CLIPLoader – loads gemma_2_2b_fp16.safetensors
Text Encoder – connects positive /negative prompts to the sampler
Simple merged release
Download neta-lumina-v1.0-all-in-one.safetensors,
md5sum = dca54fef3c64e942c1a62a741c4f9d8a,
you may use ComfyUI’s simple checkpoint loader workflow.
Recommended Settings
Sampler: res_multistep
Scheduler: linear_quadratic
Steps: 30
CFG (guidance): 4 – 5.5
EmptySD3LatentImage resolution: 1024 × 1024, 768 × 1532, 968 × 1322, or >= 1024
Prompt Book
Detailed prompt guidelines: https://civarchive.com/articles/16274/neta-lumina-drawing-model-prompt-guide
Community
Discord: https://discord.com/invite/TTTGccjbEa
QQ group: 1039442542
Roadmap
Model
Continous base‑model training to raise reasoning capability.
Aesthetic‑dataset iteration to improve anatomy, background richness, and overall appealness.
Smarter, more versatile tagging tools to lower the creative barrier.
Ecosystem
LoRA training tutorials and components
Development of advanced control / style‑consistency features (e.g., Omini Control). Call for Collaboration!
License & Disclaimer
Neta Lumina is released under Apache License 2.0
Participants & Contributors
Special thanks to the Alpha‑VLLM team for open‑sourcing Lumina‑Image‑2.0
Partners
nebulae: Civitai ・ Hugging Face
narugo1992 & deepghs: open datasets, processing tools, and models
Community Contributors
Evaluators & developers: 二小姐, spawner, Rnglg2
Other contributors: 沉迷摸鱼, poi, AshenWitch, 十分无奈, GHOSTLX, wenaka, iiiiii, 年糕特工队, 恩匹希, 奶冻, mumu, yizyin, smile, Yang, 古神, 灵之药, LyloGummy, 雪时
Appendix & Resources
TeaCache: https://github.com/spawner1145/CUI-Lumina2-TeaCache
Advanced samplers & TeaCache guide (by spawner): https://docs.qq.com/doc/DZEFKb1ZrZVZiUmxw?nlc=1
Neta Lumina ComfyUI Manual (in Chinese): https://docs.qq.com/doc/DZEVQZFdtaERPdXVh
license: other
license_name: fair-ai-public-license-1.0-sd
license_link: https://freedevproject.org/faipl-1.0-sd/
Description
Neta Lumina release version.
FAQ
Comments (49)
这是预发布文件夹里面的模型?如果是,那我将不下载尝试,因为已经试验过,如果有方法训练lora就好了
It is labeled as release version
v1.0是此次的发布版本,lora的训练脚本可以关注kohya_tech的sd scripts
neta_art 感谢,这个模型我感觉就缺个lora,毕竟有些特殊画风还是难以唤出,极大部分都是没有立体五官的二次元,二次元一直缺少一个主力为自然语言的大模型
-Serious problems with anatomy
-Very low detail, especially backgrounds
-Otherwise it looks great, the pictures are very lively and feel like a step away from generic AI pictures
Hi, thanks for feedback, I think negative + good prompting format will relieve many problems and we are going to release a prompt guide soon!
Also, I think this is a good guide for now: https://www.nextdiffusion.ai/tutorials/neta-lumina-anime-style-image-generation-comfyui
Damn so far it's pretty good, clean outputs, although struggles with some characters from some games like zenless,and seems like is very hard to apply anime screencap style to characters out of animes or a screencap scene in gral, gotta play with the prompting style to make it follow your direction, so far as pretty much every model, struggles with hands , feet eyes, will be testing more. By the way, Until what date are the characters data inside the model?
Will future Flux VAE implementations leverage an EQ-VAE based approach? I believe there might be some unclean parts that lead to undesirable results in the final output quality.
sd可以用么
我该怎么炼制它的lora?像是炼制sdxl的lora那样吗
kohya正在更新sd-scripts,我们也会提供lora训练教程
I love the models creativity and range but it looks pretty undercooked, so many ai artefacts
It's hard to prompt for, follow the cookbook and it works fine.
It doesn't have a default style really, you'll get better results by a lot using one or more artist tags
我不知道说什么,太牛逼了!
🔥🔥🔥🔥🔥🔥🔥🔥🔥🔥🔥🔥🔥🔥🔥🔥🔥
要是forge可以使用就好了,因为comofyui真的很慢,还很麻烦
comfyui is faster/same speed
comfyui能比forge慢?
wangpeijia02830 nope
2P2 毋容置疑
wangpeijia02830毋容置疑
wangpeijia02830毋容置疑Q_7 毋容置疑
请问一下,Text Encoder (Gemma-2B)里的文本编辑模型,可以用FP8的吗?
Maybe a secessor of Illustrious has come....?
Still need community help!
High potential but i will never be able to use/train this with my current GPU sadly.
I tested the 10GB all-in-one file on a desktop PC with 16GB System RAM and a 6GB VRAM Turing GTX 1660 Ti. Worked fine, bit slower than SDXL or SD 3.5 Medium though.
ZootAllures9111 5 minutes for 20 steps? I hope someone distills Lumina2
2P2 I dunno what you're referring to specifically, I just mean overall it doesn't get much smaller than this lol. A simple GGUF Q8_0 quant would probably be a better starting point than a distillation, though.
Wow! This is a new level of prompt understanding!
Of course the model still needs fine tuning (or how is it called?😅) to understand more concepts, but looks very promising.
Love to the authors of this magnificent work (´▽`ʃ♡ƪ)
Btw using it in SwarmUI without problems.
This model is definitely being slept on. It's pretty good now but a bit more tuning this could be next level
Hi, thank you for sharing this wonderful model. Your model performs very well. However, I'm not sure why it isn't as well-known as Illustrious XL. Why currently, there is not many model tunning on this checkpoint :<
It's just released a week ago...
hope it can use on webui(or webui forge)
Why?
You could try this
https://github.com/DenOfEquity/Lumina2-for-webUI
Seems to be an All-In-one Checkpoint. The one person who ask about gemma being fp8, from what I can tell it is fp16. Still awesome! Been using at 2 Megapixels resolution. Have gotten great results. BTW ModelSamplingAuraflow node is still needed. Set to 6.00
What workflow are you using?
KeMiliUs Okay... Wow! First goto Neta-Art huggingface page and get the basic workflow. Then... Create a 3part prompt system, top - you are telling Gemma what it is, middle - add Danbooru tags for the image you want. bottom - write out your prompt like you would for flux. I use a empty latent node with mega scale to input size and ratio. My workflow is terribly complicated, but the before mentioned will help you. Hope that helps.
The text encoder and Vae are in fp16, the Unet is in bf16.
Is there some way to get ControlNets working for this? Does it have to be specially trained?
Start model of another legend
This model has real potential and has a great understanding of language.
Pls make an anime finetune of Lumina-DiMOO
THIS MODEL NEEDS MORE ATTENTION!!!!!!!!! <3