



- Follow for more updates at http://discord.com/invite/TTTGccjbEa
- Try Model: Huggingface Playground
- Access to more training versions
- 中文模型说明
- QQ group: 1039442542
Introduction
Neta Lumina is a high‑quality anime‑style image‑generation model developed by Neta.art Lab.
Building on the open‑source Lumina‑Image‑2.0 released by the Alpha‑VLLM team at Shanghai AI Laboratory, we fine‑tuned the model with a vast corpus of high‑quality anime images and multilingual tag data. The preliminary result is a compelling model with powerful comprehension and interpretation abilities (thanks to Gemma text encoder), ideal for illustration, posters, storyboards, character design, and more.
Key Features
Optimized for diverse creative scenarios such as Furry, Guofeng (traditional‑Chinese aesthetics), pets, etc.
Wide coverage of characters and styles, from popular to niche concepts. (Still support danbooru tags!)
Accurate natural‑language understanding with excellent adherence to complex prompts.
Native multilingual support, with Chinese, English, and Japanese recommended first.
Model Versions
For models in alpha tests, requst access at https://huggingface.co/neta-art/NetaLumina_Alpha if you are interested.
Neta-lumina-v1.0
Request access at https://huggingface.co/neta-art/Neta-Lumina if you are interested.
Official Release: overall best performance
Neta-lumina-beta-0624
Primary Goal: General knowledge and anime‑style optimization
Data Set: >13 million anime‑style images
>46,000 A100 Hours
How to Use
Neta Lumina is built on the Lumina2 Diffusion Transformer (DiT) framework, please follow these steps precisely.
ComfyUI
Environment Requirements
Currently Neta Lumina runs only on ComfyUI:
Latest ComfyUI installation
≥ 8 GB VRAM
Downloads & Installation
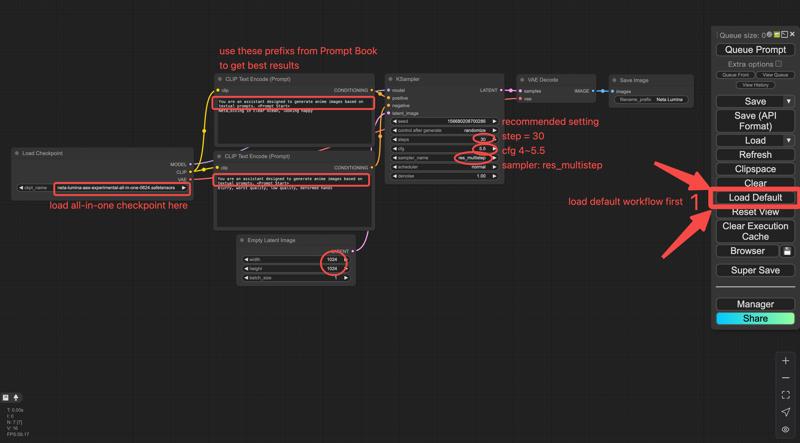
The model provided by Civitai is a three-in-one (te, dit, vae) packaged version, which can be run using the comfyui basic workflow without the need to download Text Encoder and VAE separately.
Original (component) release
Neta Lumina-V1.0
Hugging Face: https://huggingface.co/neta-art/Neta-Lumina/blob/main/Unet/neta-lumina-v1.0.safetensors
Save path:
ComfyUI/models/unet/
Text Encoder (Gemma-2B)
Download link: https://huggingface.co/neta-art/Neta-Lumina/blob/main/Text%20Encoder/gemma_2_2b_fp16.safetensors
Save path:
ComfyUI/models/text_encoders/
VAE Model (16-Channel FLUX VAE)
Download link: https://huggingface.co/neta-art/Neta-Lumina/blob/main/VAE/ae.safetensors
Save path:
ComfyUI/models/vae/
 Workflow: load lumina_workflow.json in ComfyUI.
Workflow: load lumina_workflow.json in ComfyUI.
UNETLoader – loads the .pth
VAELoader – loads ae.safetensors
CLIPLoader – loads gemma_2_2b_fp16.safetensors
Text Encoder – connects positive /negative prompts to the sampler
Simple merged release
Download neta-lumina-v1.0-all-in-one.safetensors,
md5sum = dca54fef3c64e942c1a62a741c4f9d8a,
you may use ComfyUI’s simple checkpoint loader workflow.
Recommended Settings
Sampler: res_multistep
Scheduler: linear_quadratic
Steps: 30
CFG (guidance): 4 – 5.5
EmptySD3LatentImage resolution: 1024 × 1024, 768 × 1532, 968 × 1322, or >= 1024
Prompt Book
Detailed prompt guidelines: https://civarchive.com/articles/16274/neta-lumina-drawing-model-prompt-guide
Community
Discord: https://discord.com/invite/TTTGccjbEa
QQ group: 1039442542
Roadmap
Model
Continous base‑model training to raise reasoning capability.
Aesthetic‑dataset iteration to improve anatomy, background richness, and overall appealness.
Smarter, more versatile tagging tools to lower the creative barrier.
Ecosystem
LoRA training tutorials and components
Development of advanced control / style‑consistency features (e.g., Omini Control). Call for Collaboration!
License & Disclaimer
Neta Lumina is released under Apache License 2.0
Participants & Contributors
Special thanks to the Alpha‑VLLM team for open‑sourcing Lumina‑Image‑2.0
Partners
nebulae: Civitai ・ Hugging Face
narugo1992 & deepghs: open datasets, processing tools, and models
Community Contributors
Evaluators & developers: 二小姐, spawner, Rnglg2
Other contributors: 沉迷摸鱼, poi, AshenWitch, 十分无奈, GHOSTLX, wenaka, iiiiii, 年糕特工队, 恩匹希, 奶冻, mumu, yizyin, smile, Yang, 古神, 灵之药, LyloGummy, 雪时
Appendix & Resources
TeaCache: https://github.com/spawner1145/CUI-Lumina2-TeaCache
Advanced samplers & TeaCache guide (by spawner): https://docs.qq.com/doc/DZEFKb1ZrZVZiUmxw?nlc=1
Neta Lumina ComfyUI Manual (in Chinese): https://docs.qq.com/doc/DZEVQZFdtaERPdXVh
license: other
license_name: fair-ai-public-license-1.0-sd
license_link: https://freedevproject.org/faipl-1.0-sd/
Description
FAQ
Comments (16)
im very excited about future of this model
This is insanely good! Thank you for sharing it with us, really excited to see the next iterations
I hope this model gets some attention its real good
别放弃这个模型,求求了。
10GB的大小,感觉很不错,能否支持sdxllora,以及NSFW呢,我想让他变成2.5画风
不,这是一个全新的架构,他不可能兼容任何社区的lora(无论是SDXL,SD1.5或者FLUX),他的一切生态都得重建。关于NSFW内容,在当前版本应该就有;至于特定的画风,我建议等待base模型完成训练后再使用lora或者其他方式实现。
@nian__gao233 嗯...目前是只有平面,forge可否使用
Very promising model!
加油,二次元需要次世代模型
像咱這樣的二次猿最需要啥,目前咱們急需擺脫SDXL基礎架構,過去這段時間看到了太多優秀的模型訓練者與充滿了心血的同樣優秀的訓練集,為啥成果馬馬虎虎,整鍋粥爛了不是因為混進了老鼠屎,而是廚房不行,糟蹋了食材。SDXL基礎過時、不堪使用,這是漂亮話,這是場面話。目前隔壁棚有個正在烤的Chroma,基於Flux.S,極有可能成為次世代的Pony。走著瞧,看咱們能不能有自己的次世代模型罷
说得对,最新的Novelai 4.5很明显已经摆脱了SDXL架构,可惜闭源导致生态不行。不过新架构和更大更高分辨率的训练集会导致训练成本越来越高,也是需要训练上下很多功夫
Yooo, this fine-tune is sick! Feels like unstable child of PonyV6 and Illustrious. It's surprisingly good with artist styles and characters, but it's a bit of a trial and error to figure out which artists it actually learned.
It still messes with anatomy (hands, of course) and the quality is super seed-dependent, but overall, the results are really promising!
Got a few Qs for the creator:
1. How'd you guys put the dataset together? Like, was there a cutoff for artists, say, they had to have >1000 images or something?
2. Any tips for prompting to get the best out of it?
3. And are you planning to tweak the prefill for different things later on?
Seriously, can't wait to see the next versions! Keep it up!
Please keep iterate this model.
Working in progress!