Now faster and easier to install
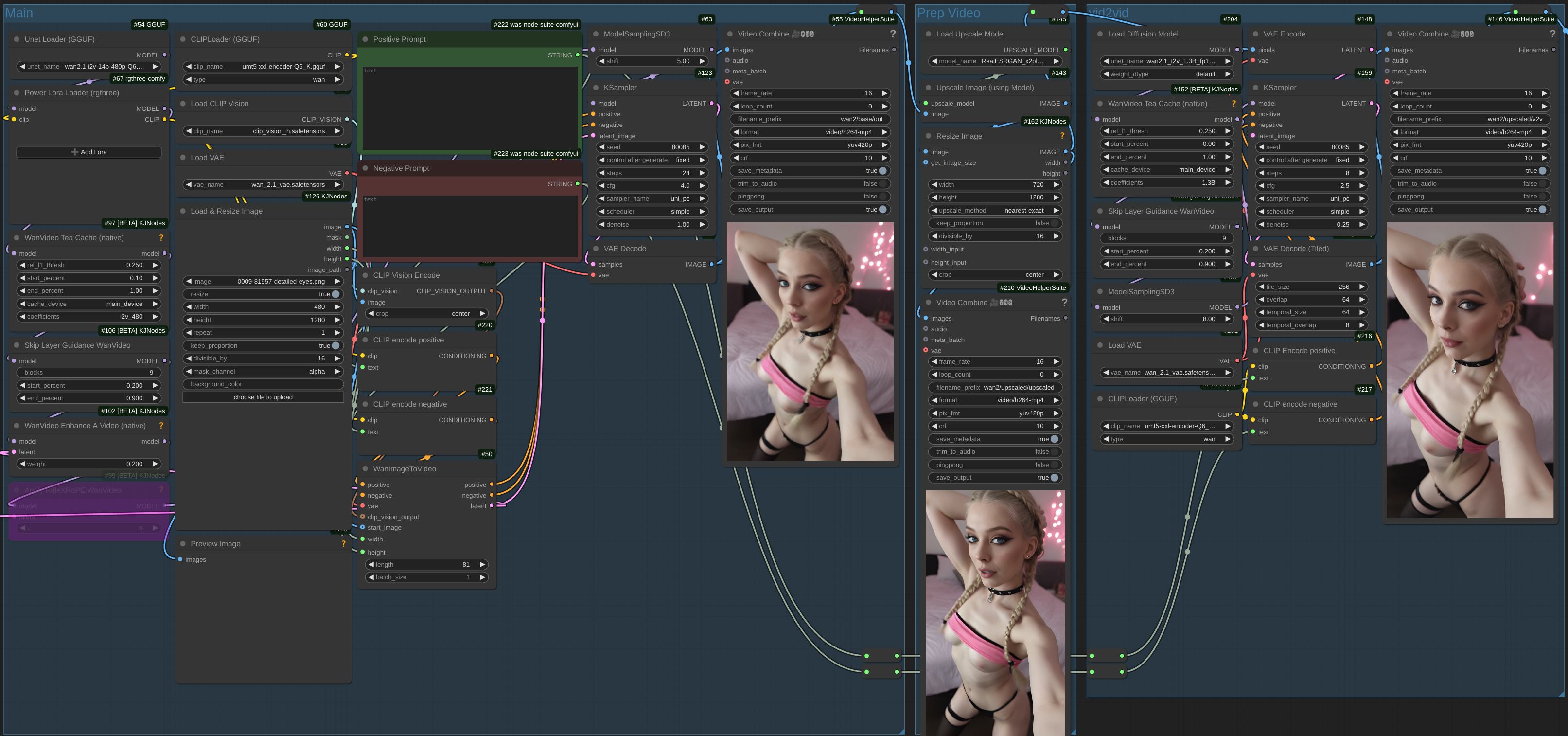
This workflow uses a small baseline generation using the 14B image to video model, followed by upscaling, and then smoothing out the result using the 5B model.
This lets you test prompts and iterate quicker on the base generation before upscaling to a final resolution.
Links for all the required models and where to put them are now included in the workflow.
FAQ
Do I need both Wan 2.1 and 2.2 VAEs?
Yes. The 2.2 VAE only works with the 5b model (confusing, I know). Make sure the main section loads the 2.1 VAE, and the upscale section loads the 2.2 VAE.
Its frozen on VAE decode
The second vae decode can take a long time. Just be patient.
Description
This version simply removes the torch compile nodes for users without Triton. If you have an AMD GPU or an older Nvidia GPU, you probably want this version.
FAQ
Comments (31)
Oh damn first time I see a Wan workflow utilising 1.3b t2v for upscale after i2v pass. Looks promising, gonna try it out!
Basicaly it's kind of "hiresfix" for video gen
@fronyax Definitely. That was exactly what I was trying to replicate with this. Generating at higher resolutions takes far too long, so this seemed like the next best way to get reasonably good quality at higher resolutions in a reasonable amount of time.
@HazardAI seems to be great for realistic, but losing losts of details from illustrations. 720p is a bummer for the time indeed, but i guess still most reliable for max detail
@Catz Try reducing the denoise down to 0.1 or lower for 2d/illustration style. If I'm doing a specific character, I typically go for 0.1, and it preserves the original likeness much better while still doing reasonably well at smoothing.
@HazardAI Ah you're right, totally oversight that setting, thanks. I would have thought it would need some denoise for the movement, but I guess the lora carry that part
i used q5_k gguf in other workflows with 16gb vram, i could generate 5secs videos but in yours, i cant with OOM. even though i downgrade gguf model to q4, no difference. after i change length to 3secs, it worked. there should be problems in workflow.
try lowering the resolution a touch (unless it break things)
Thanks! Best I2V results I've gotten so far. Question: I'm seeing an intermittent tensor error when the first sampler reaches about 20 percent. It seems to happen randomly:
"Failed running call_function <built-in function linear>(*(FakeTensor(..., device='cuda:0', size=(769, 4863), dtype=torch.float16), FakeTensor(..., device='cuda:0', size=(5120, 5120), dtype=torch.float16), FakeTensor(..., device='cuda:0', size=(5120,), dtype=torch.float16)), **{}): a and b must have same reduction dim, but got [769, 4863] X [5120, 5120]."
Any thoughts?
I've also run into that recently, and typically if i just re-run the generation, it works. I suspect its coming from a recent update to Kijai's nodes, but I haven't dived into it deeply.
I am quite impressed with the quality. I am no expert on video making, but this is quite good.
I keep running into this error though: ConnectionResetError: [WinError 10054] An existing connection was forcibly closed by the remote host
I feel like it's just on my end, probably screwed up somewhere. Would appreciate any help.
Hey! I love your videos! You seem like quite the expert to me.
I'm afraid I've never seen that error before. I wish I could help more.
I have this error on some other workflows. Couldnt find anything helpfull about it so i just left it be, it doesnt seem to have any negative effect anyway atleast for me.
@HazardAI Thanks, but my workflows compared to this are laughably simple. Great work here!
@HazardAI Another thing, some of the videos including the ones I posted, are experiencing some discoloration near the end. It seems to be coming from the vid2vid and I don't know how to solve that.
@victerprime i fixed it by replacing vae decode (tiled) with normal vae decode, but that can cause oom depending on your vram and resolution used
@kuaksu I'll try that, but I'm already pushing my 3070 to it's limits. :(
I also get the socket warning with this and other workflows. Might be too many nodes for windows socket api? idk I couldnt find a fix either
Any help with running this one without Tritot/Sage? Or that's a no-go?
I'm really wary of installing Triton @ Windows...
Yep! Use the "No Torch Compile" version. Its exactly the same, except without the torch compile node, so works without Triton.
@HazardAI ... Now, had I know Torch Compile requires Triton... Well, that's what you get for going in blind without tech knolwedge into AI vid gen I guess. Thank you a thousandfold!
@HazardAI Hi, one more question if it's not a problem...
I managed to install Triton and SageAttention, but now with some generations I run into Not enough SMs to use max_autotune_gemm mode.
I assume it's because of dynamo cache size limit in TorchCompileModelWan node (dynamic and transformer blocks only ON), but I'm not sure what should I set it to? I'm with a 4070 Ti Super 16 gb vram.
I don't understnd anything in this workflow, but the only thing I can say is every single (or almost) video i've seen featuring this workflow was pretty nice quality, so well done (currently trying myself, so far it run, which is rare enoughwhen I use other workflows...)
But, wouldn't it be better (even if maybe a touch slower) instead of loading T5X something text encoder as a GGUFF, to load the bf16 version but with the cpu loaded option (ths way I believe it load in ram and not in VRam no ?)
I'm testing now with the umt5_xxl_fp8_e4m3fn_scaled version using the clip loader node and setting the device to CPU. So far I'm seeing a slight increase to total vram. I'd love to explore this further as an option for getting the vram requirements lower.
@HazardAI Yeah I'm not sure how Vram and Ram is managed I was just wondering.
@HazardAI I always got OOM error with Q4 GGUF, but generate normaly with umt5_xxl_fp8_e4m3fn_scaled version.
Strange..
good work buddy.. gonna try
Great workflow, but when you introduce Loras to the workflow it starts to fall apart (particularly for subject matter base WAN 1.3B is not familiar with). To explain the issue, in this workflow the Lora need to be both 14B i2v ... and also needs to have a corresponding 1.3B t2v version. I have some great results with it working with some of my own trained Loras using both models but sadly that is only a subset of the Loras I use.
Does anyone have suggestions for get a 14B i2v (or 14B t2v for that matter) with a 1.3B t2v model? My experience says it is not possible but thought to ask.
You could potentially use the i2v model for the smoothing process, and then use the same loras for low res and high res, but that'd somewhat defeat the purpose of this workflow, since that's probably not much quicker than just generating at 720p to start, and definitely wouldn't save any vram. It still might be quicker, so is probably worth testing.
Some Loras seem to work well between the 14b i2v model and the 14b t2v model. In my tests, the 14b t2v model produces slightly cleaner final results too. If you have enough vram and patience, that'd be a good option.
You can also try and reduce the denoise so that the vid2vid process doesn't eliminate details.
Is there any way to batch videos? Like load multiple with prompts? And does the positive prompt accept wild cards?
Generating multiple at the same time would take one hell of a GPU. You can always use ComfyUI's built in queing to generate sequentially though.
It should be pretty easy to implement wildcards, depending on which node you're using for that.