












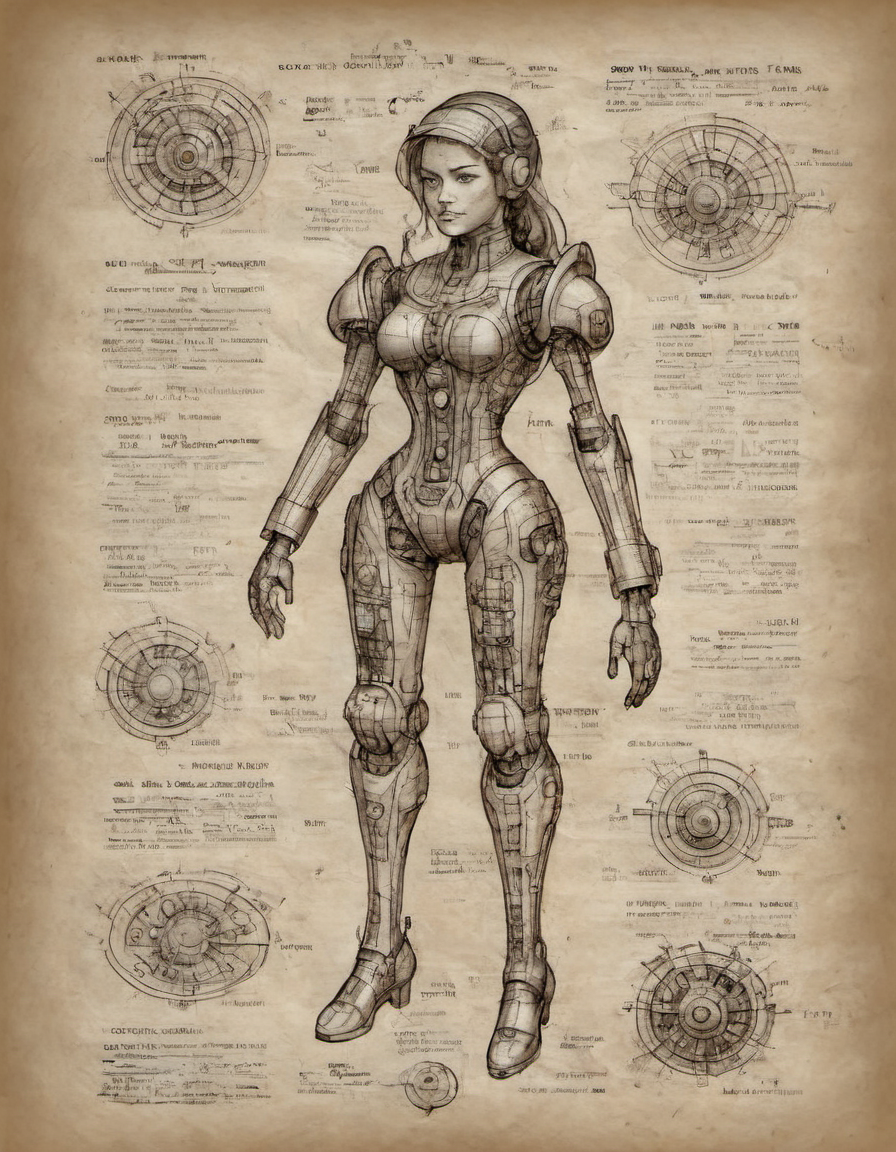






ParchartXL - art on parchment
The unifying theme of this LoRA is the substrate - parchment. Just add 'on parchment' to any prompt!
CODA: And that's a wrap! This version harmonizes basically all the previous versions of this LoRA and presents what is a near-perfect version of what I was chasing. The parchment texture (the whole raison d'être for the LoRA) is persistent and gorgeous, the illustration style consistent and reasonably flexible, and random words and annotations show up with regularity.
Compared to the last version of the LoRA this final iteration brings back those annotations a lot. It also shows a lot lower frequency of the compass rose shapes (they still pop up, but not so persistently) and some of the parchment surface quality is a little better, more akin to v1.2 than subsequent versions.
All in all, it's fully baked. Done and done!
🔗 new 1.5 version of ParchArt on a separate model page
Have some need to generate just a blank sheet of parchment? Check out the version 0.5 I uploaded here as well. Pretty niche kind of thing, but it's yours if you want it!
Description
FAQ
Comments (5)
Hello, may i ask you how many image did you use for training?
well - that's complicated! brace yourself.
The initial images trained on are all digital outputs from Midjourney, an older version (3 maybe?) which had a gorgeous parchment texture. It's really hard to find IRL decent parchment photo reference that's not just a document. So this thing was going to be from the beginning a totally digital-images-training thing.
But the output from those MJ were very abstract. Sorta map-like, but messy. The output from an initial training (of about 30 images) produces a lot of noise and junk.
So, I took that initial LoRA, and in combination with my oil-painting LoRA (trained on real-world artwork, so it has both great coherent image-making and real-world texture) prompted for parchment images and was able to get more coherent imagery that looked like my target style. Still a little wild, but less so. Generated a new set of 30 images and trained on those.
Did the same thing again.
Ran trainings with and without captions, and then did a ton of blending of different LoRA models until I found one that maximized the parchment texture with annotations and overall sketchy drawing style I want.
It still isn't as coherent to prompts as I want. So it may require some further re-training on its own output... or I may start doing some original digital image creation of my own with just blank parchment outputs.
All in all, hundreds of images were trained on, but each individual training run was roughly 30 images.
This one was a bit of a mad science project and still is!
@eldritchadam @eldritchadam I admire your perseverance
@eldritchadam Well that's pretty complicated. I think it would be pretty hard to find good lr for the next finetunings to prevent over-fitting... but the results from the lora are really nice, one of the most unique i have seen here, good job!
@stevenlehnmann144 thanks! I'm a big fan of sticking with the base model and augmenting it with LoRAs (or embeddings if they're sufficient for a task). Smaller hard drive footprint, the base model of SDXL is already really excellent and will get better with a 1.1 or 1.2 iteration, it's much more flexible to combine multiple LoRAs to achieve different outputs. I just don't see any of the fine tune models justifying themselves next to the base+LoRA paradigm.
Maybe the more hard NSFW stuff? Not my thing though, so I'm happy rolling like this.
Details
Available On (1 platform)
Same model published on other platforms. May have additional downloads or version variants.