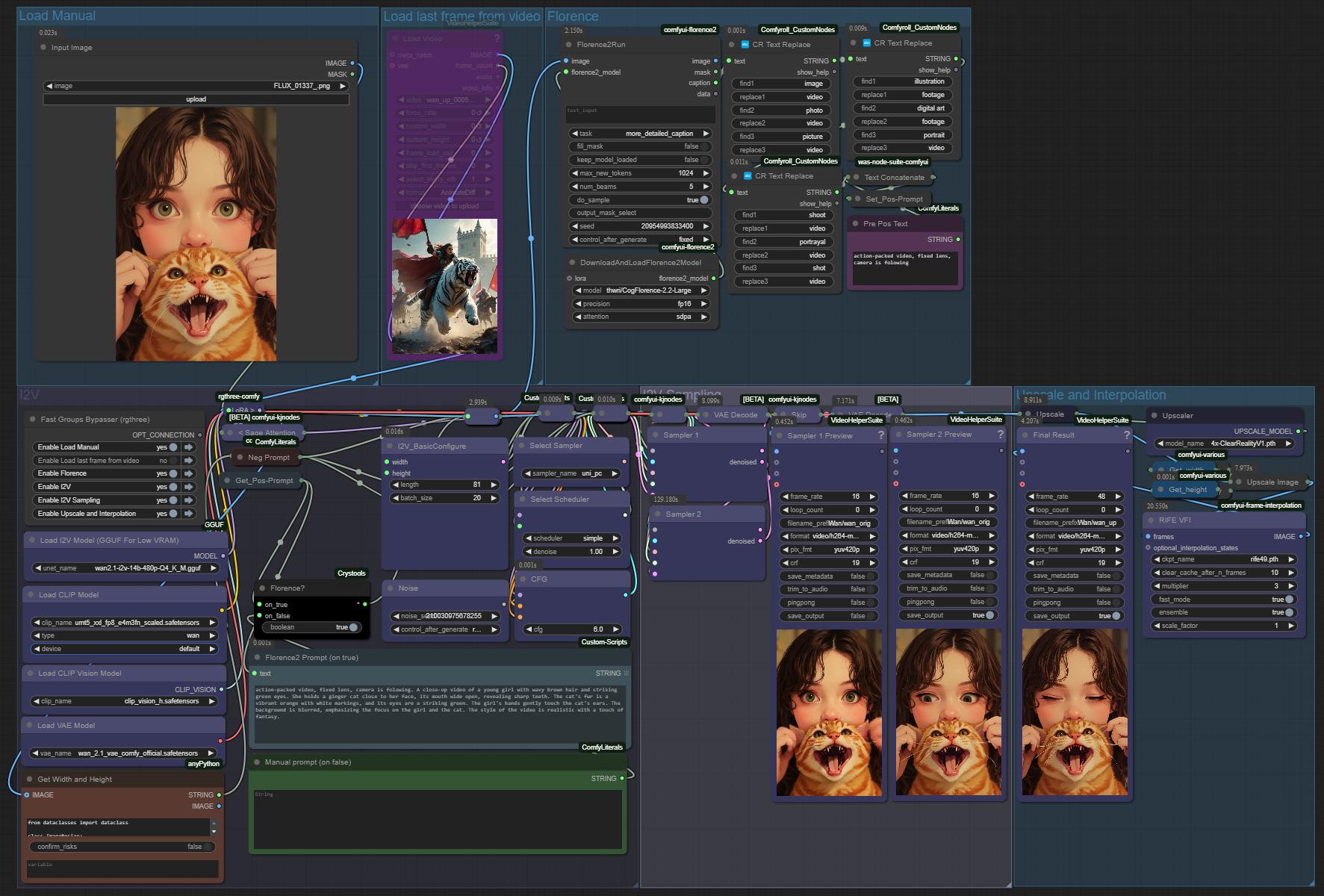
For v1.0
For v2.0
1) I2V Quant Model -> models/diffusion_models
2) CLIP VISION -> models/clip_vision
3) VAE -> models/vae
Prompt can write Florence2 LLM (workflow has toggle between Florence2 and manual user prompt).
Tested on 4080 16GB
v2.0 dev in development. If you have problems with AnyPython node, you should switch the channel recent or/and lower security_level (normal- OR weak) in the ComfyUI/Custom_nodes/ComfyUI-Manager/config.json
Description
v2.0 dev in development. If you have problems with AnyPython node, you should switch the channel recent or/and lower security_level (normal- OR weak) in the ComfyUI/Custom_nodes/ComfyUI-Manager/config.json
FAQ
Comments (9)
Great, as always :) In this one I can't seem to find a couple of things:
1) a way to set the size
2) a way to load the whole non gguf model. can you help?
Thanks again!
Hi!
1) Both versions set the size based on the size of the original image
2) ComfyUI/models/diffusion_models (gguf / non gguf)
I get missing node type "WanImageToVideo". How can I fix that?
Hi, try to update comfyui and nodes.
In v2.0 used official Comfy implementation for Wan video (ComfyUI v0.3.18),
In v1.0 used kijai repo
@rmmnty I updated everything, then a lot of things broke. Then I removed everything and started from scratch and now everything seems to work again!
AnyPython node problem persists even after switching channel recent and lowering security level to weak. Plz help!
The AnyPython node makes things overly complicated, in addition to layering nodes over each other. You extract the size of the image as strings and convert them back to integers. Why not use a getImageSize node in the first place?
I am working on it but hope to give feedback about the overall functionality of the Workflow.