


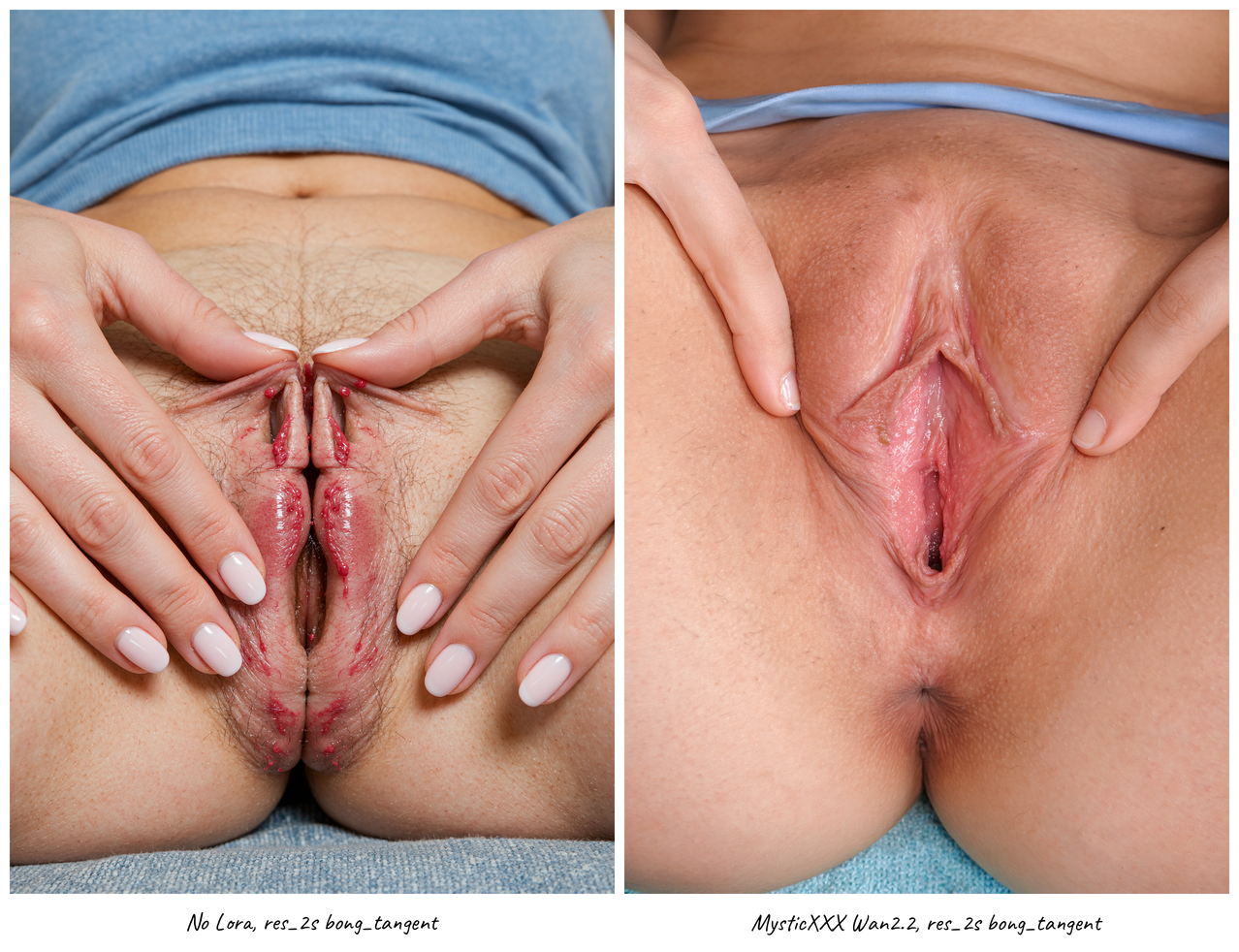
















Unlock xxx images using flux, Qwen or Wan 2.2.
ATTENTION
Second version for WAN 2.2 T2V works with the usual models BUT for T2V I recommend some different models and LoRas:
https://huggingface.co/lightx2v/Wan2.2-Lightning/blob/main/Wan2.2-T2V-A14B-4steps-250928-dyno/Wan2.2-T2V-A14B-4steps-250928-dyno-high-lightx2v.safetensors instead of wan 2.2 high
https://huggingface.co/eddy1111111/WAN22.XX_Palingenesis/blob/main/WAN22.XX_Palingenesis_low_t2v.safetensorsinstead of wan 2.2 lowRemoved this recommendationNO speed/low step loras on high noise phase
https://huggingface.co/alibaba-pai/Wan2.2-Fun-Reward-LoRAs/blob/main/Wan2.2-Fun-A14B-InP-low-noise-HPS2.1.safetensors with STR:1.0 on low noise phase
https://huggingface.co/lightx2v/Wan2.2-Lightning/blob/main/Wan2.2-T2V-A14B-4steps-lora-250928/low_noise_model.safetensors with STR:1.0 on low noise phase
???
Profit!
All my videos have workflow embedded, the workflow is just a suggestion. But it works, and works very well.
First version for KREA.
Start using: 20 steps, res_2s, bong_tangent, STR 0.8
After that you can experiment with other arguments. It is not very good and deform hands and feet very badly.
ALL PICTURES ARE PNG WITH WORKFLOW INCLUDED
It is not perfect, sometimes it creates monsters, detached members and strange things, just try another seed or adjust your prompt. Eventually it get it right.
Examples:



Recommended Usage:
Checkpoint: flux1-dev
Strength: 1 (adjust depending on the image)
Sampling Method: DPMPP_2M
Scheduler Type: BETA
CFG Scale: 4
Steps: 35
Feel free to share your creations and feedback so I can improve this model and continue contributing to the creative community!
Description
First version see the workflow on the images
FAQ
Comments (36)
is there a high version for wan 2.2?
@Lora_Addict even for text to image you are missing out on a LOT by skipping the high model. it has better prompt adherence than the low for one. They are meant to be used together. you start with high and finish with low. just like video.
@cutetodeath78409597 not wrong, i just tried to say, it also works with only the low or use the Lora on low and high
I use my own WF and use the same lora for high and low. For high i use cfg 3.5, for low 1. Works fine.
@Lora_Addict well, youd want one trained specifically on high though, i dont think it would have much of an effect if you plugged the low lora into the high model though i have never tried.
No, I will train one but it will take some time, this lora needs long times to cook.
I just posted some 6 steps videos using it. They have workflow embedded.
I don't understand. This is for video wan2.2, so why are there photos? And what is i2v or t2v for. Low or High.
A video with one frame is a picture, this lora is trained only on the low noise, and create pictures better than flux. It produce videos too, i just didn't posted it yet. The most important part is that wan don't draw good anatomy and this lora solves this problem.
I just posted some 6 steps videos made with it, they have workflow embedded.
@alcaitiff the videos are great! do you use it in low or high step? both?
@sunburnt_toasty Both, just drag a video on comfyui and see how it was done.
@alcaitiff Is there a reason its only on the low noise? The high model seems super fast to train.
@tazmannner379 no, I will train it. Just not done yet, I have only one pc and much to do...
@alcaitiff no problem great work so far, thanks!
@tazmannner379 High noise uploaded
wan 2.2 is great for still image generation too. its mainly what ive been using lately. not everyone wants video. and the best text to image workflows ive used make use of both the high and low models--they are designed to work together. just make sure you have a lot of RAM available, I use a HIGH and LOW workflow comfortably with 24gb vram and 64gb ram--though first-run is kind of painful. After that speeds are regular-slow, but the model is so good that i dont have to run as many seeds to get something I like.
Wait you're definitely cooking with the wan2.2 variant of this, I see the vision. If only this could be used as a complete finetune of the model.
Version 7 was a great advertisement for version 6. The side by sides actually made version 6 look better. Thanks.
Please use the version you like most. I'm glad there is one you liked.
@alcaitiff I was updating from version 1. I've always liked your lora, but Version 6, imho, looks better than version 7 by the side by sides on version 7.
How do you make videos with this when there's no High model, only Low?
Use it on both
It works
@alcaitiff That's a 2.1 style then. And also, maybe... You wouldn't name it HIGH if it was to be used with LOW?
@brnlittokhoes3110 no, its a 2.2, only low trained yet and named low. I don't understand where you saw high on it.
@brnlittokhoes3110 and @brnlittokhoes3110 High noise model uploaded
@alcaitiff just gave it a try. it works for some things, but doesn't seem to understand what a penis is. is there any specific way i should be prompting to get a normal penis instead of just a flesh blob?
@ObsidianDreams what? I don't got problems with this, can you share your prompt via dm? I'll give it a try and reply after.
@alcaitiff seems like it only works on text to video?
@ObsidianDreams It is a t2v model, yes
@alcaitiff normally all T2V models work for I2V with Wan. But I guess not this one. it's a solid model but T2V doesn't work for my use-case. keep up the good work
we are waiting for the corrected version
we are waiting for the corrected version Krea v2
I don't think krea will get any better, the censorship on this model and the strong style make it very hard to train without breaking it. On my last tries it started to destroy everything else, like hands and feet, teeth and eyes. The model refuses me in. And wan 2.2 is so much better, it almost do it by itself.
Details
Files
Wan2.2-Low-MysticXXX.safetensors
Mirrors
Wan2.2-Low-MysticXXX.safetensors
Wan2.2-Low-MysticXXX.safetensors
Wan2.2-Low-MysticXXX.safetensors
Wan2.2-Low-MysticXXX.safetensors
Wan2.2-Low-MysticXXX.safetensors
Wan2.2-Low-MysticXXX.safetensors
Wan2.2-Low-MysticXXX.safetensors
Wan2.2-Low-MysticXXX.safetensors
Wan2.2-Low-MysticXXX.safetensors
t2v_Wan2.2-Low-MysticXXX.safetensors
Wan2.2-Low-MysticXXX.safetensors
Wan2.2-Low-MysticXXX.safetensors
Wan2.2-Low-MysticXXX.safetensors
Wan2.2-Low-MysticXXX.safetensors
Wan2.2-Low-MysticXXX.safetensors
Wan2.2-Low-MysticXXX.safetensors
Wan2.2-Low-MysticXXX.safetensors