Improved Hunyuan Video. FP8 CUSTOM MERGE!
Example workflow for merging available as the 2nd download file.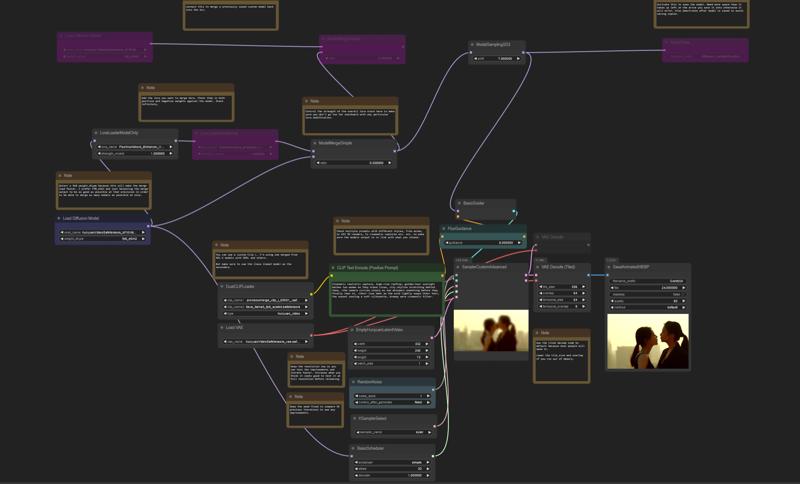 I merged the model with ~65 lora.
I merged the model with ~65 lora.
Before
 After
After
Before
 After
After

Before
 After
After

Description
FAQ
Comments (25)
Any chance of getting a GGUF/Quantized version to be more VRAM friendly?
At the moment I've had issues getting the GGUF conversion code to work. Will revisit again shortly and see if I can do it.
@Triple_Headed_Monkey I converted this model to GGUF using a modified script from city96 repo. It currently lacks HyV support but it's not hard to add. Your model is unusually quantized to fp8_e5m2 (which is 3000-series friendly as it can use torch compile), most models use fp8_e4m3. If you have the original FP16 weights I can quantize them for you if you publish them, no problem. The current e5m2 => Q8_0 that I did works but it's probably worse than what can be achieved with FP16 => Q8_0 conversion.
The main advantage of GGUF is that it can be dynamically offloaded to CPU using the updated MultiGPU nodes (DisTorch variants) and as such allow much higher resolution/length.
@rkfg Awesome stuff. Yeah I prefer that quantization in general. Because most of my work involves a heavy amount of merging between multiple models I don't usually work in any other precision levels. It would take too long to wait around for the models to load otherwise.
Do other loras work well with this model?
They should, yes.
Sorry but this is pretty bad and doesn't improve HV at all :/ Thanks for the effort though
try using Sampler: DPM++ 2M / Scheduler: beta / Sharpen radius 1 / Sigma 0.46
Blame the community for not making enough interesting lora to expand the model with. :D I'll be looking into making my own lora soon, but for now it's just an extension of the communities work in general.
Sadly the choices I have are: NSFW poses/motions or Celebrities/characters.
There is not really much that I would normally use, in regards to styles and additional concepts, like styles or physics (E.g Fire, water, electricity etc.,).
@helloworld45 i disagree. i tried out few others and came out that this model give the best results so far, even in SFW
Yep, I favour this checkpoint over the kijai, I find it much more promptable with more varied results. We just need loras trained on it, though I found it improves results for many.
Just glad this works for me at all with 12gb vram. Any chance make an img2vid workflow for this without Kijai nodes?
I'll look into that. :D
Could you list the Loras merged? Could help prevent some repetition
I can, yeah. But it doesn't necessarily change much. I didn't add or remove too much of any one lora, so there is still room to work with them all.
In terms of repetition/stacking the same stuff, if it looks good and performs better - who cares? Stack 100x of the same lora if it makes the output better :D
three_breasts.safetensors
AmorousLesbianK
twoheads4.safetensors
Move_Enhancer_V
Ass_Worship_Version
SECRET_SAUCE_B
BreastMassage.safetensors
bouncing_breasts
breast_drop_v2_17
Boob69_5P_100s
Graphical_Clothes
anime_anime_style
Full_Nelson_Po
doggystyleFancing
revealing_boobs_safetensors
POVExtremeCoug
ReverseCowgirl
Tentacle_v1.safetensors
pronebone100-con
pov_cowgirlposition
trip_v2.safetensors
pussyjob_v1.safetensors
venom_hunyan_v
pov_missionary_pov_v1
standard_clamps_e
binding_dildo_v1_h
helper_prototy
cunnilingus.safetensors
machine_safetensors
femboy_masturbation
missionary_pov_v1
doggystyle_facingC
handbra_s3-epoch
anime_char_sg10
boopas_5P00s5_ca
here are some of them I could find. Not sure off the top of my head how they were utilized though. Some in positive, some in negative. Also not sure about the direct links at this point in time.
out of all the LoRAs I don't see the hyvideo_FastVideo_LoRA-fp8 LoRA, I am assuming that maybe it isn't needed with this model? Did you base your model on the FastVideo model?
@BlarpWibble This is based on the non-fast Hunyuan video model. Adding the lora on top is pretty helpful to get even more clarity and consistency without having to increase the step counts though.
I will release an updated version merged with the fast lora in the near future.
@Triple_Headed_Monkey Do you have Move_Enhancer_V saved still? The author seems to have deleted it and his profile is also missing (banned?), it pops up in search but I get 404 opening the lora page or author's profile. I want to try making a custom merge myself using some of the loras you've listed and this one seems to be crucial for general motion improvement, yet it's deleted. Can you upload it somewhere if you still have it?
Interestingly enough, the SFW capabilities were also improved a lot. For example, I made a video of puppies playing in the snow and the vanilla HyV makes them twitch randomly as if they're freezing. And it's not really snow-related, I saw the same effect in other circumstances. But HunCusVid makes a good smooth video with all the same settings. It's slightly less saturated but I don't complain, it makes it a bit more realistic even.
the simply prove how much of an improved version they could put, Hunyuan V2 should give at least as much improvement than SDXL gave over Sd 1.5 I hope (and I have no Idea if they plan to mrelease a Hunyuan V2...)
Has anyone tried merging a character lora with the base model yet?
Not as far as I am aware. Last I checked I was the only person who had bothered to create a custom merge in the 2 months since Hunuyan Video support was added to Comfyui and merging became possible.
Official I2V model has been released, are you inclined to do a HuncusI2V?
Yeah, for sure. I just had to give it some time first to make sure it was fleshed out a bit. I should be working on this pretty soon though.
Details
Files
Available On (1 platform)
Same model published on other platforms. May have additional downloads or version variants.