















If you like what I do please consider supporting me on Patreon and contributing your ideas to my future projects!
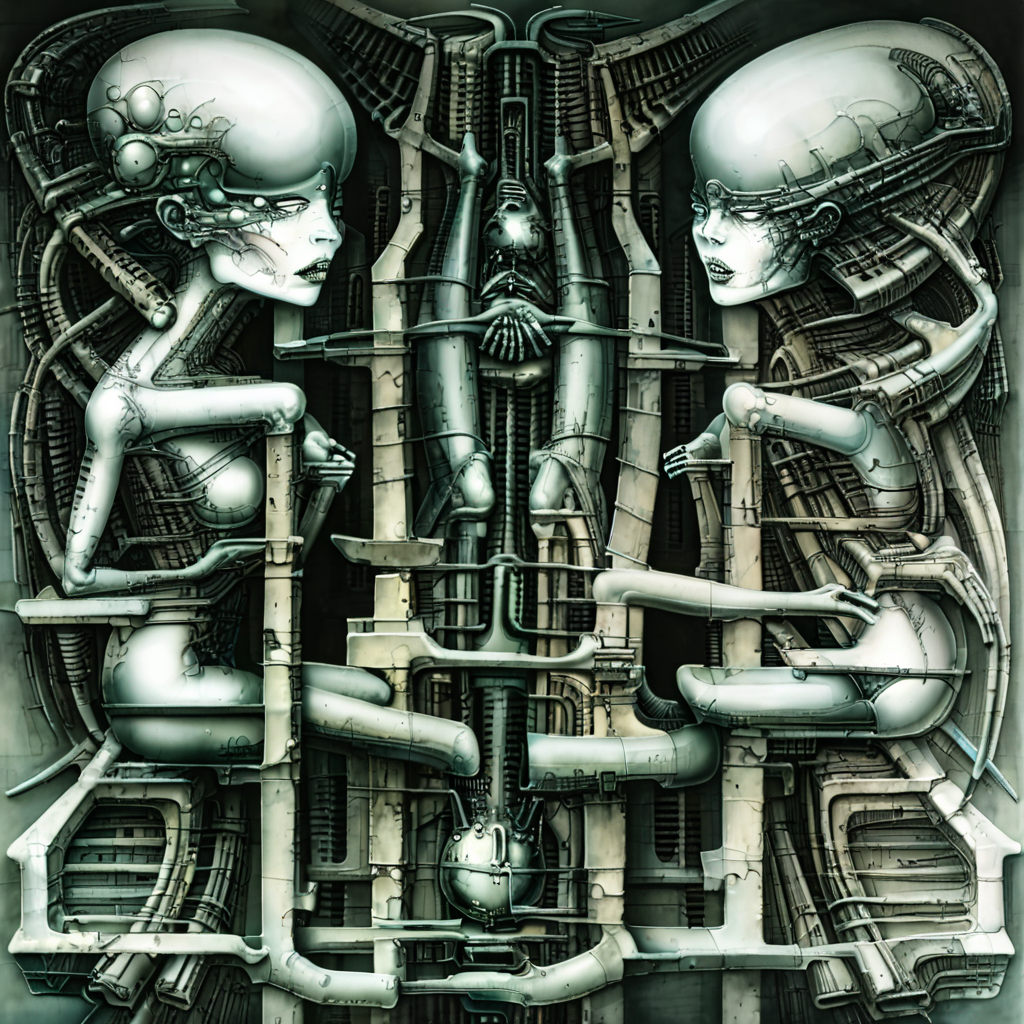
H. R. Giger art style lora for SDXL 1.0. H. R. Giger is a dark surrealist artist and now you can generate art similar to his style within your own Stable Diffusion workflow. This model was trained on 1024 x 1024 resolution and is able to produce higher details than if you were to simply put his name into your prompt.
I use this at a weight of around 1 but sometimes I'll have to go down to 0.75 or 0.5 depending on the prompt. I used clip skip 1 for all of the images you see uploaded to this page. CFG 7 looks okay but CFG 15 adds more definition. Experiment to find which setting works best for you.
In addition to the main trigger g1g3r which you can use on its own you can also use these additional custom tags to provide more variation. When using these you will have to adjust LoRa weight periodically.
t4bl3
m4ch1ne
h4ng
4li3n
th3y
f4c3s
p1p3
t0b3
l0ng
l1ck
t0ur1st
b0n3
0fg1
sc4p3
3t3rn1ty
Have fun playing around with this remarkable tech and if you like it be sure to review and upload all of your amazing works of art!
Invite to my public discord: https://discord.gg/UFkPTfTDWs
Description
The custom captions are "obfuscated" because dreambooth is not implemented into Kohya and this is the only way I can get them to work for now.
FAQ
Comments (16)
I do wish you hadn't obfuscated the keywords. using giger_ as a prefix if you don't want the words triggering normally would be quite strongly preferable.
You have to with SDXL otherwise the AI will misinterpret it. I know its easier that way but it doesn't work and its not going to work until dreambooth gets implemented. This is the best I can do for now.
I'll give you an example. I trained on an image of alien sex. So I used the word "s3x" which I thought was good enough. Nope. The AI interprets it as "Sex" when prompted. It's extremely hard to get custom captions to work right now.
Another one I tried to do was "tub3" it interpreted that as "tub" and had to retrain everything all over again.
Oof, good to know. For those of us with insufficient coffee, could you perhaps also provide a translation guide/intention for each sub-prompt? Thanks for the response -- this is not a failure mode I had expected.
@Flibertygibbet They're meant to just add some variation to the default trigger. The best way to use them would be to put them in a wildcard and add one or two to your prompt or to try each one and see which one you like.
One question, this is not happening in the rest of your SDXL LORAs? Good content.
@LDWorksDavid Different styles, different training methods
I think it's a good step in the right direction, but needs either better data, more training, or both.
Noted, I used only the best pictures I could find
For what its worth, I adjusted the dataset by culling any images that werent the best of the best, retrained, generated 200 images with various prompts, and I don't think the results are any better.
I'm leaving the lora the way it is. It's way better than what SDXL can do on its own so I'm happy with it.
Awesome, thank you! Could you do also one LoRA about Scorn art? I would do it myself if I had enough vram for it xD
Can't thank you enough for sharing this! From someone who loves phallus inspired dark art...this is the lora I have been looking for! Can't wait to give it a shot.
I see this lora and I see a "barbie core" lora and I think a collision may be imminent
Thanks for uploading this airbrushed, biomechanical style of LoRa!
Details
Available On (1 platform)
Same model published on other platforms. May have additional downloads or version variants.