
I now use WAN to generate videos instead of hunyuan. This article is about the usage of the i2v function that was not officially released by hunyuan. It is now outdated. If you like the videos I posted, you can follow me or go to my model homepage
##############################
My graphics card has been changed to 5090, and I have successfully generated hunyuan video through Sage Attention. If you are not sure how to run Sage Attention on a 50 series graphics card, I have a document for reference:
https://civarchive.com/articles/12602/how-to-run-sage-attention-on-50-series-graphics-cards
2025.3.6
Hunyuan officially released the Image to video model. This workflow is based on the model just released by kijai.
Kijai model download :
https://huggingface.co/Kijai/HunyuanVideo_comfy/blob/main/hunyuan_video_I2V_fp8_e4m3fn.safetensors
Because this is just released, I haven't tested it carefully. The bouncing breast and side anal sex lora before the test can be used normally.
I sold my 4090, so the new workflow test is based on 4060ti 16GB.
Simple test;
512x512 89 frames . It took about 4 minutes
Please review the instructions below carefully
============================================================
This workflow mainly optimizes images to NFSW Video,Added lora block node, optimized parameter settings, and reduced video artifacts, blur and other issues when using certain hunyuan lora.
I use it myself, if you have any questions you can leave me a message
Check out the original author of the plugin here:
https://github.com/kijai/ComfyUI-HunyuanVideoWrapper
purgevram needs to be installed manually
https://github.com/T8mars/comfyui-purgevram
Use the new img2vid lora to replace the original version
https://huggingface.co/leapfusion-image2vid-test/image2vid-960x544/blob/main/img2vid544p.safetensors
You can check out the pinned image to see how my video looks like.
All settings are tested by me on my 4090 graphics card.
I want to tell you what I think is a good setting if your graphics card has 24GB video memory (I haven't tried other video memory sizes):
First, you should consider generating longer videos(I don't think you want to watch a 1-second or 2-second video), because the generated video can be enlarged in high definition later, so you need to crop your pictures to be smaller
Some of the resolutions and num_frames I tested, which do not use shared memory(Using shared memory is very slow):
496x496 181
408x496 217
720x576 101
624x624 101
496x896 101
816x560 101
I do not recommend using IP2V, teacache, hyvid_cfg, etc., as they will consume additional video memory. You should use the video memory based on the resolution and total frame rate of the generated video.
The following are only for NFSW
I don’t recommend using AI to write prompts, try to write them yourself,How to write a prompt word, for example:
anal sex,bouncing breasts,An Asian girl with gigantic breasts is lying on a bed. The man is holding her thighs. The man is moving his hips up and down in fast rhythmic movements, inserting his penis completely into the girl's anus, and then pulling it out in fast pumping movements. The girl's gigantic breasts are bouncing wildly as the man's hips ram into her from behind. The man's penis is very thick and is completely inserted into the girl's asshole. The girl is wearing an unbuttoned shirt and white knee-high socks. The girl rolls her eyes and loses consciousness. The background is a bedroom. High quality.
anal sex,bouncing breasts are Lora's prompts.
The prompt words should include the action and clothing, etc. It is not recommended to write too long, which will distract the weight of the main prompt words,Don’t write any prompts that are irrelevant to your video. Focus on the action description.
In addition, I found that using some loras will affect the quality of the video. It may be that the resolution is low when the loras is trained. I am not sure about the specific reason.
The video resolution should not be lower than 512x512, which will seriously affect the association between the video and the prompt word.
My parameter settings
The parameters I am currently using:
embedded_guidance_scale:12 (If the action is too intense, lower this value)
flow_shirt:12
denoise:1
num_frames:101
steps:30 or 9(Fast version)
LORAs
In addition, you need bouncing breasts lora (mainly to increase the breast shaking effect) and anal sex lora (you can use other ones, I use this one mainly for the effect, but this lora will affect the image quality)
1.
strength:0.85
2.
https://civarchive.com/models/1193034/side-anal-sex?modelVersionId=1343233
Strength: 1.1,(The default setting in the workflow is 1.1. If the action is too intense, reduce the weight slightly), the higher the weight, the smoother the action. Note that setting this value requires enabling Lora Block Weight, otherwise there will be serious image quality issues, please check the Lora Block Weight description in the next section.
Lora Block Weight
This node has been added to the new Workflow. Please set it as follows to prevent blurring when using Side Anal Sex Lora. Please see the sample images.
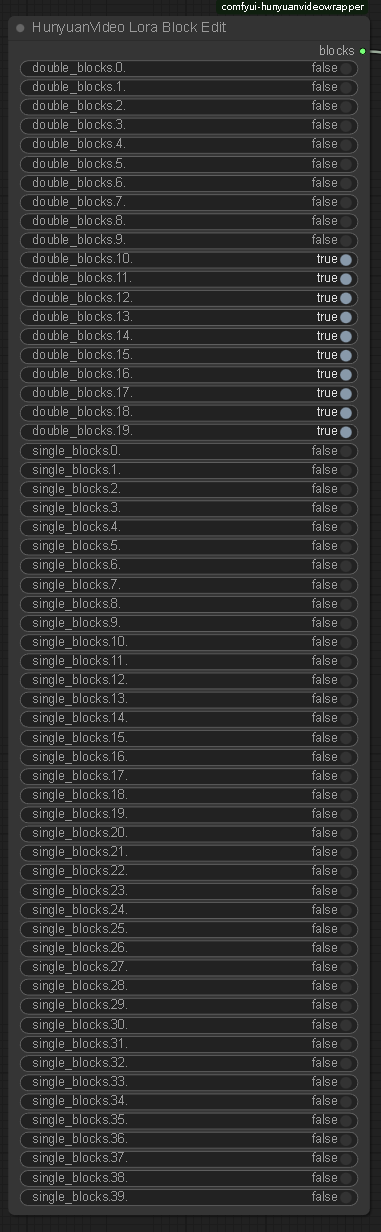
Image selection
The problem of multiple fingers and other defects in the picture is not a big deal.
Don’t choose images with a clear gap between the man and the woman, otherwise the man will not be able to touch the woman’s body when he swings, resulting in insufficient shaking. You should choose images where the man and the woman are close together.
====================================
Description
Add color match image and lora block nodes and adjust the settings
增加color match image和lora block节点,调整设置
FAQ
Comments (79)
I need to know how to fix Sageattention still,i HAVE it but comfyui says No :(
Use sdpa instead, they are almost the same
Works c:
@fayer1688 nope. sageattention allow for longer video and higher resolution
If on windows use this guide to get sage attention working
How to run HunyuanVideo on a single 24gb VRAM card. : StableDiffusion
@o0Maikeru0o Put the wheel on the ComfyUI_windows_portable\update folder,
The Problem is that Desktop ComfyUI doesn't have a folder like that lol
@Santaonholidays I believe it does. It is inside your %appdata% folder.
@gorodork Nothing to see in \AppData\Roaming\ComfyUI
@Santaonholidays Aw crap. I'm sorry lad. Maybe the only thing left for you to do is to use the portable version...
HyVideoSampler
Failed to find C compiler. Please specify via CC environment variable.
大佬我这是缺了啥哇
我用 guidance 12 ,shift 20 出来的效果经常是 直接图片慢慢变灰的 这种视频,而不是动起来,不知道应该怎么调整
guidance设置成6 提示词写全点
@fayer1688 试过很多次了还是不行,但锁seed后我每次重新加载模型后 似乎第一次能正常生成
查看你的VAE是不是对的,有两个同名的VAE,要用这里面的https://huggingface.co/Kijai/HunyuanVideo_comfy/tree/main
@fayer1688 这个之前就下了,现在的现象是每次一次生成都是正常的,但是换张图换个参数或者第二次生成都不行,都得点一次 重载一下模型才能正常产生,不然生成的就是很怪的灰图,不知道是我本地的问题还是通用问题
@twoldogs 先跑一次然后用comfyui把缓存清了 再试下,如果没问题那可能这个node有问题,或者用Purgevram节点自动清缓存
Nice workflor, but is it possible to make one that uses GGUF models to lower the VRAM usage?
I'm able to get it to run, but this is causing a lot of problems with VRAM usage, even if I put it at lower resolutions. I have a 4070ti Super, 16GB VRAM, and 496x560, 49 frames, at 7 steps is taking nearly 15 minutes to generate.
The original author said he had no intention of supporting gguf.check here:https://github.com/kijai/ComfyUI-HunyuanVideoWrapper/issues/310,Try lowering the resolution and total frame rate to find the parameters that suit you
Why the generation after the first time gets weird? The first time it runs reproduces a nice result, after that its just random stuff.
Try upgrading comfyui and HunyuanVideoWrapper to see if the problem can be solved
@fayer1688 Tried it but sadly the issue continues. If I change the hunyuan model, the next prompt is generated without problems but after that its screwed again. If i keep changing from fasthunyuan to normalhunyuan betwen each prompt I dont have any issues though.
What are your pytorch and cuda versions? Please upload the video you have the problem with so that I can see it.
@gorodork Have you found a solution? I'm having the same issue in another workflow.
大佬请问,降低哪些参数可以降低显存用量。我是4080 16g。。谢谢
num_frames和分辨率
Purgevram link not working. There’s any workaround?
@fayer1688 Thanks!
請問Can't import SageAttention: No module named 'sageattention' 這個錯誤詳細要怎麼處理 我安裝了還是報錯
@fayer1688 我照著步驟在執行..\python_embeded\python.exe -s -m pip install triton-3.1.0-cp312-cp312-win_amd64.whl 的時候 cmd回報找不到路徑或ERROR: triton-3.1.0-cp312-cp312-win_amd64.whl is not a supported wheel on this platform. 該怎麼處理呢 謝謝
@rdfssqa 你看你的python版本对得上吗
@fayer1688 我的python確實低於 但是我該如何特別用想要的去跑 我電腦裡有三個版本的python 但我comfy是3.10的 可以切換嗎 謝謝
@rdfssqa 不能多个python。把你comfyui里的python加到环境变量里,然后安装你这个版本的triton,我建议你在新的comfyui里安装
Thanks for the input, has anyone tried it on a 12gb 3060? I wouldn't mind waiting 30 minutes per generation.
I tried but got a torch.OutOfMemoryError
for me it is working on 4070 12GB. 6min for 2sek.
Failed to import transformers.models.timm_wrapper.configuration_timm_wrapper because of the following error (look up to see its traceback): cannot import name 'ImageNetInfo' from 'timm.data'
佬,这个错误是什么原因啊,这些库都都下载更新过的
https://github.com/kijai/ComfyUI-HunyuanVideoWrapper/issues/272 You would go to the ComfyUI_windows_portable\python_embeded -folder and run:
python.exe -m pip install -U timm
@NoArtifact Thank you for your help. I have resolved all the issues, but the generated video is pure black(lol). I am using an RTX4080 graphics card, 16GB, and I am not sure if it is a memory problem
@voidyear no idea, but probably not memory if not it would've crashed with a OOM error message I suppose, did you put some loras in the mix ? it doesn't seems to accept lora very well
升级timm和transformers试试
@NoArtifact @fayer1688 Thank you for your reply. I have noticed that the issue was caused by selecting 'sdpa' in my attention model in the sampler. I switched to 'comfy' and was able to generate colored videos. However, when I use 'ageattn_varlen', an error message appears: 'No module named' triton '. I am not sure if different selections will affect the video results.'
It works, but I'm getting faded lines in a grid across my videos. Is this something others have run into or solved?
lora weight is too high, try to reduce the weight
appreciate for you service. It's very awesome...
HyVideoTextEncode
list index out of range 这个是什么原因啊
same problem here
@BigBugAnimation This is a comfyui problem. Have you upgraded comfyui?
@fayer1688 thanks for the reply, the comfyui was upgraded to date, still have the problem
I'm getting this error, does anyone have any ideas on what could be causing it? Using Comfy UI Portable...
HyVideoSampler
[WinError 2] The system cannot find the file specified
it's because you just generated without making sure you have all the models. Ensure you have the correct hunyuan model, vae, llm text and clip encoders etc. Also when you use a workflow, it loads with the names of the models used by the creator, so you may not have those models and haven't selected the ones you have from the dropdow. Whatever is missing, the node it belongs to will be highlighted in red
Calculated padded input size per channel: (0 x 16 x 16). Kernel size: (1 x 1 x 1). Kernel size can't be greater than actual input size,我在最后解码节点的时候遇见这个问题,我的尺寸是408×496,请问这是什么原因造成的错误啊?该如何解决?
i have a issue about : HyVideoSampler
shape mismatch: value tensor of shape [16, 1, 81, 72] cannot be broadcast to indexing result of shape [1, 16, 1, 82, 72]
any suggestion ?
The resolution is wrong. You can refer to what I wrote for details.
I set this up in about 10 minutes with all the dependencies on a MimicPC setup (Large-pro+Instant$1.49/h) and got some pretty decent gens out of it on 9 steps in under 2 minutes.
The movement is generally a bit strange and jerky but I can see how playing with the parameters and increasing step count could fix this (as well as using more appropriate LoRas to the images I am starting with).
REALLY impressed and will keep playing with it. Thank you!
無論如何修改都會出現'img_in.proj.weight'
錯誤...不知如何解決
I'm a new guy, may I ask how to download these model-hunyuanlanal_sex-000150_converted.safetensors, hunyuanlbouncing breasts hunyuan.safetensors, hunyuanimg2vid544p.safetensors, hunyuanhunyuan video vae bf16.safetensors?
我是新手,请问如何下载这些模型-hunyuanlanal_sex-000150_converted.safetensors、hunyuanlbouncing breasts hunyuan.safetensors、hunyuanimg2vid544p.safetensors、hunyuanhunyuan video vae bf16.safetensors?
@fayer1688 thank u!!!
@fayer1688 By the way, what is the "dawd1234.png", can I replace it to another photo or I need to keep it as usual? But I cant find it.
@yikingpeter845 That's just where you upload YOUR image for IMG2VID!
May I ask where can I find "dawd1234.png"? Or Can I replace it with the photo I like?
This is the picture I used for testing, you can replace it with the picture you like
May I ask how to solve this problem?
我想问一下如何解决下面问题:
HyVideoModelLoader
Can't import SageAttention: No module named 'sageattention'
Follow this process to install, but it is difficult. If you don’t know how to install, you can use sdpa, but it will affect the generation speed
@fayer1688 好,我发现文件少了权重模型,我从github上下载了补回去了,但是遇到了新的问题,还请帮忙解答:module 'comfy.latent_formats' has no attribute 'HunyuanVideo'
@yikingpeter845 要升级comfyui版本到最新
大佬,我遇到了新的问题,还请帮忙解答:module 'comfy.latent_formats' has no attribute 'HunyuanVideo'
要升级comfyui版本到最新
index 0 is out of bounds for dimension 0 with size 0
Resolution 408 * 496, where wrong?
Try to lower the transformers version, pip install transformers==4.41.2
解决不了,你去github问下kijai