I now use WAN to generate videos instead of hunyuan. This article is about the usage of the i2v function that was not officially released by hunyuan. It is now outdated. If you like the videos I posted, you can follow me or go to my model homepage
##############################
My graphics card has been changed to 5090, and I have successfully generated hunyuan video through Sage Attention. If you are not sure how to run Sage Attention on a 50 series graphics card, I have a document for reference:
https://civarchive.com/articles/12602/how-to-run-sage-attention-on-50-series-graphics-cards
2025.3.6
Hunyuan officially released the Image to video model. This workflow is based on the model just released by kijai.
Kijai model download :
https://huggingface.co/Kijai/HunyuanVideo_comfy/blob/main/hunyuan_video_I2V_fp8_e4m3fn.safetensors
Because this is just released, I haven't tested it carefully. The bouncing breast and side anal sex lora before the test can be used normally.
I sold my 4090, so the new workflow test is based on 4060ti 16GB.
Simple test;
512x512 89 frames . It took about 4 minutes
Please review the instructions below carefully
============================================================
This workflow mainly optimizes images to NFSW Video,Added lora block node, optimized parameter settings, and reduced video artifacts, blur and other issues when using certain hunyuan lora.
I use it myself, if you have any questions you can leave me a message
Check out the original author of the plugin here:
https://github.com/kijai/ComfyUI-HunyuanVideoWrapper
purgevram needs to be installed manually
https://github.com/T8mars/comfyui-purgevram
Use the new img2vid lora to replace the original version
https://huggingface.co/leapfusion-image2vid-test/image2vid-960x544/blob/main/img2vid544p.safetensors
You can check out the pinned image to see how my video looks like.
All settings are tested by me on my 4090 graphics card.
I want to tell you what I think is a good setting if your graphics card has 24GB video memory (I haven't tried other video memory sizes):
First, you should consider generating longer videos(I don't think you want to watch a 1-second or 2-second video), because the generated video can be enlarged in high definition later, so you need to crop your pictures to be smaller
Some of the resolutions and num_frames I tested, which do not use shared memory(Using shared memory is very slow):
496x496 181
408x496 217
720x576 101
624x624 101
496x896 101
816x560 101
I do not recommend using IP2V, teacache, hyvid_cfg, etc., as they will consume additional video memory. You should use the video memory based on the resolution and total frame rate of the generated video.
The following are only for NFSW
I don’t recommend using AI to write prompts, try to write them yourself,How to write a prompt word, for example:
anal sex,bouncing breasts,An Asian girl with gigantic breasts is lying on a bed. The man is holding her thighs. The man is moving his hips up and down in fast rhythmic movements, inserting his penis completely into the girl's anus, and then pulling it out in fast pumping movements. The girl's gigantic breasts are bouncing wildly as the man's hips ram into her from behind. The man's penis is very thick and is completely inserted into the girl's asshole. The girl is wearing an unbuttoned shirt and white knee-high socks. The girl rolls her eyes and loses consciousness. The background is a bedroom. High quality.
anal sex,bouncing breasts are Lora's prompts.
The prompt words should include the action and clothing, etc. It is not recommended to write too long, which will distract the weight of the main prompt words,Don’t write any prompts that are irrelevant to your video. Focus on the action description.
In addition, I found that using some loras will affect the quality of the video. It may be that the resolution is low when the loras is trained. I am not sure about the specific reason.
The video resolution should not be lower than 512x512, which will seriously affect the association between the video and the prompt word.
My parameter settings
The parameters I am currently using:
embedded_guidance_scale:12 (If the action is too intense, lower this value)
flow_shirt:12
denoise:1
num_frames:101
steps:30 or 9(Fast version)
LORAs
In addition, you need bouncing breasts lora (mainly to increase the breast shaking effect) and anal sex lora (you can use other ones, I use this one mainly for the effect, but this lora will affect the image quality)
1.
strength:0.85
2.
https://civarchive.com/models/1193034/side-anal-sex?modelVersionId=1343233
Strength: 1.1,(The default setting in the workflow is 1.1. If the action is too intense, reduce the weight slightly), the higher the weight, the smoother the action. Note that setting this value requires enabling Lora Block Weight, otherwise there will be serious image quality issues, please check the Lora Block Weight description in the next section.
Lora Block Weight
This node has been added to the new Workflow. Please set it as follows to prevent blurring when using Side Anal Sex Lora. Please see the sample images.
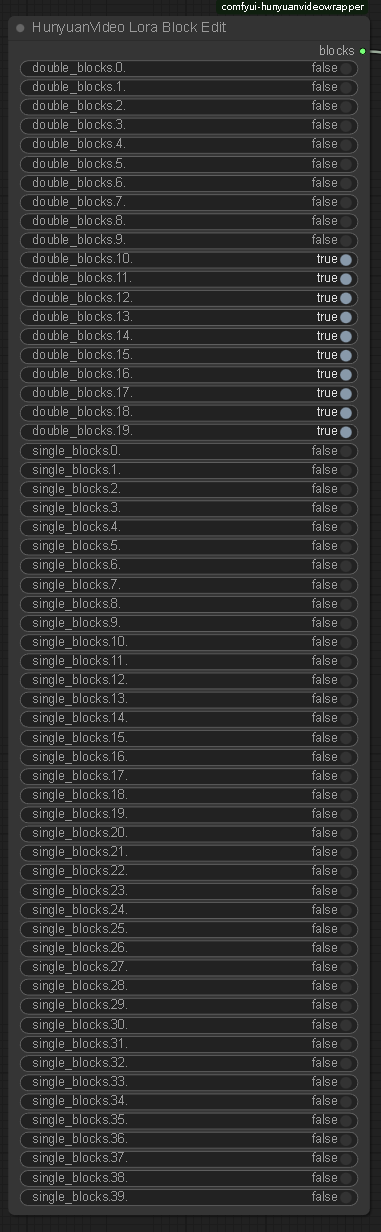
Image selection
The problem of multiple fingers and other defects in the picture is not a big deal.
Don’t choose images with a clear gap between the man and the woman, otherwise the man will not be able to touch the woman’s body when he swings, resulting in insufficient shaking. You should choose images where the man and the woman are close together.
====================================
Description
FAQ
Comments (74)
Got it boss. Thanks for sharing!
This is the correct node for Purge VRAM? https://github.com/T8star1984/comfyui-purgevram If I run it on L40 with 48GB do I need to purge?
@aiboom1 This node is correct, but I don't think it's useful. I didn't use it.
@fayer1688 Thanks again, this is a very simplified approach to what I was looking at earlier. I will try it tomorrow in the cloud and see how it works. :)
@aiboom1 I think there are still some problems with Lora and node that need to be solved, and errors will occur when using it
@fayer1688 Good heads up, I can't expect perfection. We're early to the party. Gives us something to look forward to when it does improve.
@fayer1688 I am using it now and it does really well! I will let it run for a couple hours and pick the best one to share. 624x624, 20/97, 30 steps takes 13 minutes to complete with L40.
@aiboom1 You can generate a smaller resolution video and then enlarge it using the enlargement restoration workflow
@fayer1688 In such cases which resolution are you making first and what are you upscaling it to? 312x312 -> 624x624? Do I need to resize the starting image to 312x312 if doing that or it can stay 624x624?
@aiboom1 I use 624x624, or other higher resolutions. I don't use the upscaling workflow. I'm still testing the upscaling workflow.
There are some problems now. I use t2v to generate low-resolution videos and then upscale them. There is no problem, and the video becomes clear, but using i2v has no effect. I'm still studying whether it's a workflow problem.
There is a problem with using low-resolution videos. The video and your prompt words will not be well associated. Now img2vid's lora is not perfect yet. I checked the original page and they used 512x320 resolution for training.
@fayer1688 512x320 would probably give an even better result with the LeapVision LoRA then? Thanks for sharing your testing results.
@fayer1688 I will try Topaz Video AI, is that what you use when you said you upscale the low resolution videos?
@aiboom1 I just used upscale workflow
I tried to generate but when it gets to the Load HunyuanVideo Tokenizer Node I get an error. I asked chatgpt about it and it told me to update transformers and timm but that didn't help. I also ran the update bat to make sure my comfy and dependencies are up to date. Here's the error:
"DownloadAndLoadHyVideoTextEncoder
Failed to import transformers.models.timm_wrapper.configuration_timm_wrapper because of the following error (look up to see its traceback): cannot import name 'ImageNetInfo' from 'timm.data' (...ComfyUI\ComfyUI_windows_portable\python_embeded\Lib\site-packages\timm\data\__init__.py)"
install timm model 1.0.13
pip install timm==1.0.13
@fayer1688 Thanks but I got the error again. Could I possibly have some dependency conflicts? I'm not sure how to check that tho
@fayer1688 it's odd bc I use to have a workflow that used that node and I'm getting the same error there as well now
@bhopping Have you confirmed that your timm module is installed in the python in ComfyUI_windows_portable?
It may be installed in another python of yours
Check if the path setting in your system's environment variables is correct
@fayer1688 Yes I can see them when I search in the that folder, it shows timm, tim_wrapper and tim_backbone is under ComfyUI_windows_portable\python_embeded\Lib\site-packages\...
I installed it by typing cmd in my python_embeded folder address and when I type pip show timm it says Version: 1.0.13. Is that the proper way of installing it? Also which transformers version are you running?
@bhopping Uninstall the timm module, and then check if there is still a timm folder in the folder. If there is no folder, it means that you have installed it correctly.
I suggest you check the python path in the environment variable. If you have not installed other pythons, you cannot use pip install to install the timm module to the python in the ComfyUI portable version.
I have not used the ComfyUI portable version, but I think the python in the ComfyUI portable version will not automatically add the path to the environment variable. Maybe you have installed other versions of python, and then this installation step adds the python path to the environment variable.
@fayer1688 I ran the command to uninstalled timm but the folders were still present. Also I appear to have 2 different pythons in my PATH environment variable except the python for comfy appears to be missing. So would that mean I just add, "(USER)\ComfyUI\ComfyUI_windows_portable\python_embeded\ into my environment variable PATH? Thanks for the help so far btw
@bhopping Comfyui portable will not automatically add PATH to the environment variable, so when you install timm, timm is not installed in the python in comfyui portable. Check if your environment variable PATH path is in the python path in comfyui portable. If not, modify the python path to the python in comfyui portable. Remember that there are different versions in the path. Then reinstall timm again.
@bhopping You also need to delete other python paths
@fayer1688 Thanks that helps with that node! BUT now I have another issue with the HunyuanVideo Sampler Node lol. I have history with this node not working before and couldn't get it to work but I'll look into into again. If you do know anything about it, the error I get it: TypeError: HyVideoSampler.process() got an unexpected keyword argument 'feta_args'
Thank you for this! I have tried some other LeapFusion workflows, but the model took too long to load, and the results weren't good. In your workflow, you skip the IP2V node, which helped a lot with model loading time.
I was able to get it to generate at the expected (same) speed as txt2vid on my 4700 12GB VRAM by adding a blockswap node and teacache node.
I also added a colorswap node to better match colors in the final result to the source image. I'm not sure why mine wasn't match as closely as the examples posted, but they weren't.
Workflow posted here (I can take this down if you make a new version here): https://civitai.com/models/1199965?modelVersionId=1351186
I'll try it, thanks
After using your workflow, with the same settings, my graphics card is out of memory. I am checking the cause.
@fayer1688 Your 4090 is OOM on it? That's unexpected! Maybe block swap is bad in that situation somehow?
@samsismas I can confirm that this workflow is very slow and causes OOM errors.
@samsismas IP2V will take up a lot of vram, it's not suitable for me to use
@fayer1688 I agree for me too
Where can I get the img2vid lora? thx for info
@fayer1688 for link vae?
@fayer1688 I'm experiencing an error like this, why is it in the vae section, what should I do HyVideoVAELoader
Error(s) in loading state_dict for AutoencoderKLCausal3D: Missing key(s) in state_dict: "encoder.down_blocks.0.resnets.0.norm1.weight", "encoder.down_blocks.0.resnets.0.norm1.bias", "encoder.down_blocks.0.resnets.0.conv1.conv.weight", "encoder.down_blocks.0.resnets.0.conv1.conv.bias", "encoder.down_blocks.0.resnets.0.norm2.weight", "encoder.down_blocks.0.resnets.0.norm2.bias", "encoder.down_blocks.0.resnets.0.conv2.conv.weight", "encoder.down_blocks.0.resnets.0.conv2.conv.bias", "encoder.down_blocks.0.resnets.1.norm1.weight", "encoder.down_blocks.0.resnets.1.norm1.bias", "encoder.down_blocks.0.resnets.1.conv1.conv.weight", "encoder.down_blocks.0.resnets.1.conv1.conv.bias", "encoder.down_blocks.0.resnets.1.norm2.weight", "encoder.down_blocks.0.resnets.1.norm2.bias", "encoder.down_blocks.0.resnets.1.conv2.conv.weight", "encoder.down_blocks.0.resnets.1.conv2.conv.bias", "encoder.down_blocks.0.downsamplers.0.conv.conv.weight",
@fayer1688 thank you very much, this works great
@fayer1688 thx a lot
I do not see the Purgevram node in comfyUI
https://github.com/T8star1984/comfyui-purgevram
Error no file named pytorch_model.bin, model.safetensors, tf_model.h5, model.ckpt.index or flax_model.msgpack found in directory Z:\ComfyUI_windows_portable\ComfyUI\models\clip\clip-vit-large-patch14.
This is an automatically downloaded model. Your network is down and you need to re-download it.
Invalid image type. Expected either PIL.Image.Image, numpy.ndarray, torch.Tensor, tf.Tensor or jax.ndarray, but got <class 'str'>.
What is the cause of this error? Please tell me.Sorry, I can't solve this problem. You can consult the original author of the node:
Error(s) in loading state_dict for AutoencoderKLCausal3D: Missing key(s) in state_dict: "encoder.down_blocks.0.resnets.0.norm1.weight", "encoder.down_blocks.0.resnets.0.norm1.bias", "encoder.down_blocks.0.resnets.0.conv1.conv.weight", "encoder.down_blocks.0.resnets.0.conv1.conv.bias", "encoder.down_blocks.0.resnets.0.norm2.weight", "encoder.down_blocks.0.resnets.0.norm2.bias", "encoder.down_blocks.0.resnets.0.conv2.conv.weight", "encoder.down_blocks.0.resnets.0.conv2.conv.bias", "encoder.down_blocks.0.resnets.1.norm1.weight", "encoder.down_blocks.0.resnets.1.norm1.bias", "encoder.down_blocks.0.resnets.1.conv1.conv.weight", "encoder.down_blocks.0.resnets.1.conv1.conv.bias", "encoder.down_blocks.0.resnets.1.norm2.weight", "encoder.down_blocks.0.resnets.1.norm2.bias", "encoder.down_blocks.0.resnets.1.conv2.conv.weight", "encoder.down_blocks.0.resnets.1.conv2.conv.bias", "encoder.down_blocks.0.downsamplers.0.conv.conv.weight", "encoder.down_blocks.0.downsamplers.0.conv.conv.bias", "encoder.down_blocks.1.resnets.0.norm1.weight", "encoder.down_blocks.1.resnets.0.norm1.bias", "encoder.down_blocks.1.resnets.0.conv1.conv.weight", "encoder.down_blocks.1.resnets.0.conv1.conv.bias", "encoder.down_blocks.1.resnets.0.norm2.weight", "encoder.down_blocks.1.resnets.0.norm2.bias", "encoder.down_blocks.1.resnets.0.conv2.conv.weight", "encoder.down_blocks.1.resnets.0.conv2.conv.bias", "encoder.down_blocks.1.resnets.0.conv_shortcut.conv.weight", "encoder.down_blocks.1.resnets.0.conv_shortcut.conv.bias", "encoder.down_blocks.1.resnets.1.norm1.weight", "encoder.down_blocks.1.resnets.1.norm1.bias", "encoder.down_blocks.1.resnets.1.conv1.conv.weight", "encoder.down_blocks.1.resnets.1.conv1.conv.bias", "encoder.down_blocks.1.resnets.1.norm2.weight", "encoder.down_blocks.1.resnets.1.norm2.bias", "encoder.down_blocks.1.resnets.1.conv2.conv.weight", "encoder.down_blocks.1.resnets.1.conv2.conv.bias", "encoder.down_blocks.1.downsamplers.0.conv.conv.weight", "encoder.down_blocks.1.downsamplers.0.conv.conv.bias", "encoder.down_blocks.2.resnets.0.norm1.weight", "encoder.down_blocks.2.resnets.0.norm1.bias", "encoder.down_blocks.2.resnets.0.conv1.conv.weight", "encoder.down_blocks.2.resnets.0.conv1.conv.bias", "encoder.down_blocks.2.resnets.0.norm2.weight", "encoder.down_blocks.2.resnets.0.norm2.bias", "encoder.down_blocks.2.resnets.0.conv2.conv.weight", "encoder.down_blocks.2.resnets.0.conv2.conv.bias", "encoder.down_blocks.2.resnets.0.conv_shortcut.conv.weight", "encoder.down_blocks.2.resnets.0.conv_shortcut.conv.bias", "encoder.down_blocks.2.resnets.1.norm1.weight", "encoder.down_blocks.2.resnets.1.norm1.bias", "encoder.down_blocks.2.resnets.1.conv1.conv.weight", "encoder.down_blocks.2.resnets.1.conv1.conv.bias", "encoder.down_blocks.2.resnets.1.norm2.weight", "encoder.down_blocks.2.resnets.1.norm2.bias", "encoder.down_blocks.2.resnets.1.conv2.conv.weight", "encoder.down_blocks.2.resnets.1.conv2.conv.bias", "encoder.down_blocks.2.downsamplers.0.conv.conv.weight", "encoder.down_blocks.2.downsamplers.0.conv.conv.bias", "encoder.down_blocks.3.resnets.0.norm1.weight", "encoder.down_blocks.3.resnets.0.norm1.bias", "encoder.down_blocks.3.resnets.0.conv1.conv.weight", "encoder.down_blocks.3.resnets.0.conv1.conv.bias", "encoder.down_blocks.3.resnets.0.norm2.weight", "encoder.down_blocks.3.resnets.0.norm2.bias", "encoder.down_blocks.3.resnets.0.conv2.conv.weight", "encoder.down_blocks.3.resnets.0.conv2.conv.bias", "encoder.down_blocks.3.resnets.1.norm1.weight", "encoder.down_blocks.3.resnets.1.norm1.bias", "encoder.down_blocks.3.resnets.1.conv1.conv.weight", "encoder.down_blocks.3.resnets.1.conv1.conv.bias", "encoder.down_blocks.3.resnets.1.norm2.weight", "encoder.down_blocks.3.resnets.1.norm2.bias", "encoder.down_blocks.3.resnets.1.conv2.conv.weight", "encoder.down_blocks.3.resnets.1.conv2.conv.bias", "encoder.mid_block.attentions.0.group_norm.weight", "encoder.mid_block.attentions.0.group_norm.bias", "encoder.mid_block.attentions.0.to_q.weight", "encoder.mid_block.attentions.0.to_q.bias", "encoder.mid_block.attentions.0.to_k.weight", "encoder.mid_block.attentions.0.to_k.bias", "encoder.mid_block.attentions.0.to_v.weight", "encoder.mid_block.attentions.0.to_v.bias", "encoder.mid_block.attentions.0.to_out.0.weight", "encoder.mid_block.attentions.0.to_out.0.bias", "encoder.mid_block.resnets.0.norm1.weight", "encoder.mid_block.resnets.0.norm1.bias", "encoder.mid_block.resnets.0.conv1.conv.weight", "encoder.mid_block.resnets.0.conv1.conv.bias", "encoder.mid_block.resnets.0.norm2.weight", "encoder.mid_block.resnets.0.norm2.bias", "encoder.mid_block.resnets.0.conv2.conv.weight", "encoder.mid_block.resnets.0.conv2.conv.bias", "encoder.mid_block.resnets.1.norm1.weight", "encoder.mid_block.resnets.1.norm1.bias", "encoder.mid_block.resnets.1.conv1.conv.weight", "encoder.mid_block.resnets.1.conv1.conv.bias", "encoder.mid_block.resnets.1.norm2.weight", "encoder.mid_block.resnets.1.norm2.bias", "encoder.mid_block.resnets.1.conv2.conv.weight", "encoder.mid_block.resnets.1.conv2.conv.bias", "encoder.conv_norm_out.weight", "encoder.conv_norm_out.bias", "decoder.up_blocks.0.resnets.0.norm1.weight", "decoder.up_blocks.0.resnets.0.norm1.bias", "decoder.up_blocks.0.resnets.0.conv1.conv.weight", "decoder.up_blocks.0.resnets.0.conv1.conv.bias", "decoder.up_blocks.0.resnets.0.norm2.weight", "decoder.up_blocks.0.resnets.0.norm2.bias", "decoder.up_blocks.0.resnets.0.conv2.conv.weight", "decoder.up_blocks.0.resnets.0.conv2.conv.bias", "decoder.up_blocks.0.resnets.1.norm1.weight", "decoder.up_blocks.0.resnets.1.norm1.bias", "decoder.up_blocks.0.resnets.1.conv1.conv.weight", "decoder.up_blocks.0.resnets.1.conv1.conv.bias", "decoder.up_blocks.0.resnets.1.norm2.weight", "decoder.up_blocks.0.resnets.1.norm2.bias", "decoder.up_blocks.0.resnets.1.conv2.conv.weight", "decoder.up_blocks.0.resnets.1.conv2.conv.bias", "decoder.up_blocks.0.resnets.2.norm1.weight", "decoder.up_blocks.0.resnets.2.norm1.bias", "decoder.up_blocks.0.resnets.2.conv1.conv.weight", "decoder.up_blocks.0.resnets.2.conv1.conv.bias", "decoder.up_blocks.0.resnets.2.norm2.weight", "decoder.up_blocks.0.resnets.2.norm2.bias", "decoder.up_blocks.0.resnets.2.conv2.conv.weight", "decoder.up_blocks.0.resnets.2.conv2.conv.bias", "decoder.up_blocks.0.upsamplers.0.conv.conv.weight", "decoder.up_blocks.0.upsamplers.0.conv.conv.bias", "decoder.up_blocks.1.resnets.0.norm1.weight", "decoder.up_blocks.1.resnets.0.norm1.bias", "decoder.up_blocks.1.resnets.0.conv1.conv.weight", "decoder.up_blocks.1.resnets.0.conv1.conv.bias", "decoder.up_blocks.1.resnets.0.norm2.weight", "decoder.up_blocks.1.resnets.0.norm2.bias", "decoder.up_blocks.1.resnets.0.conv2.conv.weight", "decoder.up_blocks.1.resnets.0.conv2.conv.bias", "decoder.up_blocks.1.resnets.1.norm1.weight", "decoder.up_blocks.1.resnets.1.norm1.bias", "decoder.up_blocks.1.resnets.1.conv1.conv.weight", "decoder.up_blocks.1.resnets.1.conv1.conv.bias", "decoder.up_blocks.1.resnets.1.norm2.weight", "decoder.up_blocks.1.resnets.1.norm2.bias", "decoder.up_blocks.1.resnets.1.conv2.conv.weight", "decoder.up_blocks.1.resnets.1.conv2.conv.bias", "decoder.up_blocks.1.resnets.2.norm1.weight", "decoder.up_blocks.1.resnets.2.norm1.bias", "decoder.up_blocks.1.resnets.2.conv1.conv.weight", "decoder.up_blocks.1.resnets.2.conv1.conv.bias", "decoder.up_blocks.1.resnets.2.norm2.weight", "decoder.up_blocks.1.resnets.2.norm2.bias", "decoder.up_blocks.1.resnets.2.conv2.conv.weight", "decoder.up_blocks.1.resnets.2.conv2.conv.bias", "decoder.up_blocks.1.upsamplers.0.conv.conv.weight", "decoder.up_blocks.1.upsamplers.0.conv.conv.bias", "decoder.up_blocks.2.resnets.0.norm1.weight", "decoder.up_blocks.2.resnets.0.norm1.bias", "decoder.up_blocks.2.resnets.0.conv1.conv.weight", "decoder.up_blocks.2.resnets.0.conv1.conv.bias", "decoder.up_blocks.2.resnets.0.norm2.weight", "decoder.up_blocks.2.resnets.0.norm2.bias", "decoder.up_blocks.2.resnets.0.conv2.conv.weight", "decoder.up_blocks.2.resnets.0.conv2.conv.bias", "decoder.up_blocks.2.resnets.0.conv_shortcut.conv.weight", "decoder.up_blocks.2.resnets.0.conv_shortcut.conv.bias", "decoder.up_blocks.2.resnets.1.norm1.weight", "decoder.up_blocks.2.resnets.1.norm1.bias", "decoder.up_blocks.2.resnets.1.conv1.conv.weight", "decoder.up_blocks.2.resnets.1.conv1.conv.bias", "decoder.up_blocks.2.resnets.1.norm2.weight", "decoder.up_blocks.2.resnets.1.norm2.bias", "decoder.up_blocks.2.resnets.1.conv2.conv.weight", "decoder.up_blocks.2.resnets.1.conv2.conv.bias", "decoder.up_blocks.2.resnets.2.norm1.weight", "decoder.up_blocks.2.resnets.2.norm1.bias", "decoder.up_blocks.2.resnets.2.conv1.conv.weight", "decoder.up_blocks.2.resnets.2.conv1.conv.bias", "decoder.up_blocks.2.resnets.2.norm2.weight", "decoder.up_blocks.2.resnets.2.norm2.bias", "decoder.up_blocks.2.resnets.2.conv2.conv.weight", "decoder.up_blocks.2.resnets.2.conv2.conv.bias", "decoder.up_blocks.2.upsamplers.0.conv.conv.weight", "decoder.up_blocks.2.upsamplers.0.conv.conv.bias", "decoder.up_blocks.3.resnets.0.norm1.weight", "decoder.up_blocks.3.resnets.0.norm1.bias", "decoder.up_blocks.3.resnets.0.conv1.conv.weight", "decoder.up_blocks.3.resnets.0.conv1.conv.bias", "decoder.up_blocks.3.resnets.0.norm2.weight", "decoder.up_blocks.3.resnets.0.norm2.bias", "decoder.up_blocks.3.resnets.0.conv2.conv.weight", "decoder.up_blocks.3.resnets.0.conv2.conv.bias", "decoder.up_blocks.3.resnets.0.conv_shortcut.conv.weight", "decoder.up_blocks.3.resnets.0.conv_shortcut.conv.bias", "decoder.up_blocks.3.resnets.1.norm1.weight", "decoder.up_blocks.3.resnets.1.norm1.bias", "decoder.up_blocks.3.resnets.1.conv1.conv.weight", "decoder.up_blocks.3.resnets.1.conv1.conv.bias", "decoder.up_blocks.3.resnets.1.norm2.weight", "decoder.up_blocks.3.resnets.1.norm2.bias", "decoder.up_blocks.3.resnets.1.conv2.conv.weight", "decoder.up_blocks.3.resnets.1.conv2.conv.bias", "decoder.up_blocks.3.resnets.2.norm1.weight", "decoder.up_blocks.3.resnets.2.norm1.bias", "decoder.up_blocks.3.resnets.2.conv1.conv.weight", "decoder.up_blocks.3.resnets.2.conv1.conv.bias", "decoder.up_blocks.3.resnets.2.norm2.weight", "decoder.up_blocks.3.resnets.2.norm2.bias", "decoder.up_blocks.3.resnets.2.conv2.conv.weight", "decoder.up_blocks.3.resnets.2.conv2.conv.bias", "decoder.mid_block.attentions.0.group_norm.weight", "decoder.mid_block.attentions.0.group_norm.bias", "decoder.mid_block.attentions.0.to_q.weight", "decoder.mid_block.attentions.0.to_q.bias", "decoder.mid_block.attentions.0.to_k.weight", "decoder.mid_block.attentions.0.to_k.bias", "decoder.mid_block.attentions.0.to_v.weight", "decoder.mid_block.attentions.0.to_v.bias", "decoder.mid_block.attentions.0.to_out.0.weight", "decoder.mid_block.attentions.0.to_out.0.bias", "decoder.mid_block.resnets.0.norm1.weight", "decoder.mid_block.resnets.0.norm1.bias", "decoder.mid_block.resnets.0.conv1.conv.weight", "decoder.mid_block.resnets.0.conv1.conv.bias", "decoder.mid_block.resnets.0.norm2.weight", "decoder.mid_block.resnets.0.norm2.bias", "decoder.mid_block.resnets.0.conv2.conv.weight", "decoder.mid_block.resnets.0.conv2.conv.bias", "decoder.mid_block.resnets.1.norm1.weight", "decoder.mid_block.resnets.1.norm1.bias", "decoder.mid_block.resnets.1.conv1.conv.weight", "decoder.mid_block.resnets.1.conv1.conv.bias", "decoder.mid_block.resnets.1.norm2.weight", "decoder.mid_block.resnets.1.norm2.bias", "decoder.mid_block.resnets.1.conv2.conv.weight", "decoder.mid_block.resnets.1.conv2.conv.bias", "decoder.conv_norm_out.weight", "decoder.conv_norm_out.bias". Unexpected key(s) in state_dict: "encoder.down.0.block.0.conv1.conv.bias", "encoder.down.0.block.0.conv1.conv.weight", "encoder.down.0.block.0.conv2.conv.bias", "encoder.down.0.block.0.conv2.conv.weight", "encoder.down.0.block.0.norm1.bias", "encoder.down.0.block.0.norm1.weight", "encoder.down.0.block.0.norm2.bias", "encoder.down.0.block.0.norm2.weight", "encoder.down.0.block.1.conv1.conv.bias", "encoder.down.0.block.1.conv1.conv.weight", "encoder.down.0.block.1.conv2.conv.bias", "encoder.down.0.block.1.conv2.conv.weight", "encoder.down.0.block.1.norm1.bias", "encoder.down.0.block.1.norm1.weight", "encoder.down.0.block.1.norm2.bias", "encoder.down.0.block.1.norm2.weight", "encoder.down.0.downsample.conv.conv.bias", "encoder.down.0.downsample.conv.conv.weight", "encoder.down.1.block.0.conv1.conv.bias", "encoder.down.1.block.0.conv1.conv.weight", "encoder.down.1.block.0.conv2.conv.bias", "encoder.down.1.block.0.conv2.conv.weight", "encoder.down.1.block.0.nin_shortcut.conv.bias", "encoder.down.1.block.0.nin_shortcut.conv.weight", "encoder.down.1.block.0.norm1.bias", "encoder.down.1.block.0.norm1.weight", "encoder.down.1.block.0.norm2.bias", "encoder.down.1.block.0.norm2.weight", "encoder.down.1.block.1.conv1.conv.bias", "encoder.down.1.block.1.conv1.conv.weight", "encoder.down.1.block.1.conv2.conv.bias", "encoder.down.1.block.1.conv2.conv.weight", "encoder.down.1.block.1.norm1.bias", "encoder.down.1.block.1.norm1.weight", "encoder.down.1.block.1.norm2.bias", "encoder.down.1.block.1.norm2.weight", "encoder.down.1.downsample.conv.conv.bias", "encoder.down.1.downsample.conv.conv.weight", "encoder.down.2.block.0.conv1.conv.bias", "encoder.down.2.block.0.conv1.conv.weight", "encoder.down.2.block.0.conv2.conv.bias", "encoder.down.2.block.0.conv2.conv.weight", "encoder.down.2.block.0.nin_shortcut.conv.bias", "encoder.down.2.block.0.nin_shortcut.conv.weight", "encoder.down.2.block.0.norm1.bias", "encoder.down.2.block.0.norm1.weight", "encoder.down.2.block.0.norm2.bias", "encoder.down.2.block.0.norm2.weight", "encoder.down.2.block.1.conv1.conv.bias", "encoder.down.2.block.1.conv1.conv.weight", "encoder.down.2.block.1.conv2.conv.bias", "encoder.down.2.block.1.conv2.conv.weight", "encoder.down.2.block.1.norm1.bias", "encoder.down.2.block.1.norm1.weight", "encoder.down.2.block.1.norm2.bias", "encoder.down.2.block.1.norm2.weight", "encoder.down.2.downsample.conv.conv.bias", "encoder.down.2.downsample.conv.conv.weight", "encoder.down.3.block.0.conv1.conv.bias", "encoder.down.3.block.0.conv1.conv.weight", "encoder.down.3.block.0.conv2.conv.bias", "encoder.down.3.block.0.conv2.conv.weight", "encoder.down.3.block.0.norm1.bias", "encoder.down.3.block.0.norm1.weight", "encoder.down.3.block.0.norm2.bias", "encoder.down.3.block.0.norm2.weight", "encoder.down.3.block.1.conv1.conv.bias", "encoder.down.3.block.1.conv1.conv.weight", "encoder.down.3.block.1.conv2.conv.bias", "encoder.down.3.block.1.conv2.conv.weight", "encoder.down.3.block.1.norm1.bias", "encoder.down.3.block.1.norm1.weight", "encoder.down.3.block.1.norm2.bias", "encoder.down.3.block.1.norm2.weight", "encoder.mid.attn_1.k.bias", "encoder.mid.attn_1.k.weight", "encoder.mid.attn_1.norm.bias", "encoder.mid.attn_1.norm.weight", "encoder.mid.attn_1.proj_out.bias", "encoder.mid.attn_1.proj_out.weight", "encoder.mid.attn_1.q.bias", "encoder.mid.attn_1.q.weight", "encoder.mid.attn_1.v.bias", "encoder.mid.attn_1.v.weight", "encoder.mid.block_1.conv1.conv.bias", "encoder.mid.block_1.conv1.conv.weight", "encoder.mid.block_1.conv2.conv.bias", "encoder.mid.block_1.conv2.conv.weight", "encoder.mid.block_1.norm1.bias", "encoder.mid.block_1.norm1.weight", "encoder.mid.block_1.norm2.bias", "encoder.mid.block_1.norm2.weight", "encoder.mid.block_2.conv1.conv.bias", "encoder.mid.block_2.conv1.conv.weight", "encoder.mid.block_2.conv2.conv.bias", "encoder.mid.block_2.conv2.conv.weight", "encoder.mid.block_2.norm1.bias", "encoder.mid.block_2.norm1.weight", "encoder.mid.block_2.norm2.bias", "encoder.mid.block_2.norm2.weight", "encoder.norm_out.bias", "encoder.norm_out.weight", "decoder.mid.attn_1.k.bias", "decoder.mid.attn_1.k.weight", "decoder.mid.attn_1.norm.bias", "decoder.mid.attn_1.norm.weight", "decoder.mid.attn_1.proj_out.bias", "decoder.mid.attn_1.proj_out.weight", "decoder.mid.attn_1.q.bias", "decoder.mid.attn_1.q.weight", "decoder.mid.attn_1.v.bias", "decoder.mid.attn_1.v.weight", "decoder.mid.block_1.conv1.conv.bias", "decoder.mid.block_1.conv1.conv.weight", "decoder.mid.block_1.conv2.conv.bias", "decoder.mid.block_1.conv2.conv.weight", "decoder.mid.block_1.norm1.bias", "decoder.mid.block_1.norm1.weight", "decoder.mid.block_1.norm2.bias", "decoder.mid.block_1.norm2.weight", "decoder.mid.block_2.conv1.conv.bias", "decoder.mid.block_2.conv1.conv.weight", "decoder.mid.block_2.conv2.conv.bias", "decoder.mid.block_2.conv2.conv.weight", "decoder.mid.block_2.norm1.bias", "decoder.mid.block_2.norm1.weight", "decoder.mid.block_2.norm2.bias", "decoder.mid.block_2.norm2.weight", "decoder.norm_out.bias", "decoder.norm_out.weight", "decoder.up.0.block.0.conv1.conv.bias", "decoder.up.0.block.0.conv1.conv.weight", "decoder.up.0.block.0.conv2.conv.bias", "decoder.up.0.block.0.conv2.conv.weight", "decoder.up.0.block.0.nin_shortcut.conv.bias", "decoder.up.0.block.0.nin_shortcut.conv.weight", "decoder.up.0.block.0.norm1.bias", "decoder.up.0.block.0.norm1.weight", "decoder.up.0.block.0.norm2.bias", "decoder.up.0.block.0.norm2.weight", "decoder.up.0.block.1.conv1.conv.bias", "decoder.up.0.block.1.conv1.conv.weight", "decoder.up.0.block.1.conv2.conv.bias", "decoder.up.0.block.1.conv2.conv.weight", "decoder.up.0.block.1.norm1.bias", "decoder.up.0.block.1.norm1.weight", "decoder.up.0.block.1.norm2.bias", "decoder.up.0.block.1.norm2.weight", "decoder.up.0.block.2.conv1.conv.bias", "decoder.up.0.block.2.conv1.conv.weight", "decoder.up.0.block.2.conv2.conv.bias", "decoder.up.0.block.2.conv2.conv.weight", "decoder.up.0.block.2.norm1.bias", "decoder.up.0.block.2.norm1.weight", "decoder.up.0.block.2.norm2.bias", "decoder.up.0.block.2.norm2.weight", "decoder.up.1.block.0.conv1.conv.bias", "decoder.up.1.block.0.conv1.conv.weight", "decoder.up.1.block.0.conv2.conv.bias", "decoder.up.1.block.0.conv2.conv.weight", "decoder.up.1.block.0.nin_shortcut.conv.bias", "decoder.up.1.block.0.nin_shortcut.conv.weight", "decoder.up.1.block.0.norm1.bias", "decoder.up.1.block.0.norm1.weight", "decoder.up.1.block.0.norm2.bias", "decoder.up.1.block.0.norm2.weight", "decoder.up.1.block.1.conv1.conv.bias", "decoder.up.1.block.1.conv1.conv.weight", "decoder.up.1.block.1.conv2.conv.bias", "decoder.up.1.block.1.conv2.conv.weight", "decoder.up.1.block.1.norm1.bias", "decoder.up.1.block.1.norm1.weight", "decoder.up.1.block.1.norm2.bias", "decoder.up.1.block.1.norm2.weight", "decoder.up.1.block.2.conv1.conv.bias", "decoder.up.1.block.2.conv1.conv.weight", "decoder.up.1.block.2.conv2.conv.bias", "decoder.up.1.block.2.conv2.conv.weight", "decoder.up.1.block.2.norm1.bias", "decoder.up.1.block.2.norm1.weight", "decoder.up.1.block.2.norm2.bias", "decoder.up.1.block.2.norm2.weight", "decoder.up.1.upsample.conv.conv.bias", "decoder.up.1.upsample.conv.conv.weight", "decoder.up.2.block.0.conv1.conv.bias", "decoder.up.2.block.0.conv1.conv.weight", "decoder.up.2.block.0.conv2.conv.bias", "decoder.up.2.block.0.conv2.conv.weight", "decoder.up.2.block.0.norm1.bias", "decoder.up.2.block.0.norm1.weight", "decoder.up.2.block.0.norm2.bias", "decoder.up.2.block.0.norm2.weight", "decoder.up.2.block.1.conv1.conv.bias", "decoder.up.2.block.1.conv1.conv.weight", "decoder.up.2.block.1.conv2.conv.bias", "decoder.up.2.block.1.conv2.conv.weight", "decoder.up.2.block.1.norm1.bias", "decoder.up.2.block.1.norm1.weight", "decoder.up.2.block.1.norm2.bias", "decoder.up.2.block.1.norm2.weight", "decoder.up.2.block.2.conv1.conv.bias", "decoder.up.2.block.2.conv1.conv.weight", "decoder.up.2.block.2.conv2.conv.bias", "decoder.up.2.block.2.conv2.conv.weight", "decoder.up.2.block.2.norm1.bias", "decoder.up.2.block.2.norm1.weight", "decoder.up.2.block.2.norm2.bias", "decoder.up.2.block.2.norm2.weight", "decoder.up.2.upsample.conv.conv.bias", "decoder.up.2.upsample.conv.conv.weight", "decoder.up.3.block.0.conv1.conv.bias", "decoder.up.3.block.0.conv1.conv.weight", "decoder.up.3.block.0.conv2.conv.bias", "decoder.up.3.block.0.conv2.conv.weight", "decoder.up.3.block.0.norm1.bias", "decoder.up.3.block.0.norm1.weight", "decoder.up.3.block.0.norm2.bias", "decoder.up.3.block.0.norm2.weight", "decoder.up.3.block.1.conv1.conv.bias", "decoder.up.3.block.1.conv1.conv.weight", "decoder.up.3.block.1.conv2.conv.bias", "decoder.up.3.block.1.conv2.conv.weight", "decoder.up.3.block.1.norm1.bias", "decoder.up.3.block.1.norm1.weight", "decoder.up.3.block.1.norm2.bias", "decoder.up.3.block.1.norm2.weight", "decoder.up.3.block.2.conv1.conv.bias", "decoder.up.3.block.2.conv1.conv.weight", "decoder.up.3.block.2.conv2.conv.bias", "decoder.up.3.block.2.conv2.conv.weight", "decoder.up.3.block.2.norm1.bias", "decoder.up.3.block.2.norm1.weight", "decoder.up.3.block.2.norm2.bias", "decoder.up.3.block.2.norm2.weight", "decoder.up.3.upsample.conv.conv.bias", "decoder.up.3.upsample.conv.conv.weight".
https://github.com/kijai/ComfyUI-HunyuanVideoWrapper/issues/307
大佬你好,为什么我在14%的阶段总是会重新连接然后按任意键中止,是什么问题?
大佬好 想問一下時長是調哪個位置呀
num_frames
還有個問題想問一下,為什麼生成出來的影片和原生的圖片會不一樣,是有哪個位置的參數需要調整嗎
@kpkp84700592 提示词没写全,embedded-cfg-scale调大到12试试
@fayer1688 按照大佬原本的設定直接做也怪怪的,有時候人從第二幀開始就變了,有時候只有小範圍的動作,很玄
@kpkp84700592 我补充了点描述,你看我写的东西
大佬,嘗試過,seed我改成increment了,目前就是像抽獎一樣,同一張照片有時候成功有時候失敗
大佬我想問一下正常是每張圖片是正常生成的嗎,不知道為什麼我生成出來的10張有9張都是訓練集的人物,跟我原本輸入的圖片完全沒有任何關系,是圖片上傳對圖片的尺寸有要求嗎? 還是可能會有什麼原因導致的?
embedded_guidance_scale 太低,lora权重太高,或者把denoise降低点试试
Hi I need help over here
I get PurgeVRAM error missing Node how can I solve it
https://github.com/T8star1984/comfyui-purgevram
@fayer1688 where to put the file or how to install please?
i get a 404 error when trying to access the url, i have the node disabled for now
@getphat It can be accessed directly to check if there is any problem with your network
@fayer1688 hey thanks, I cant seem to install triton, and chatgpt was no help
new link : https://github.com/T8mars/comfyui-purgevram
I've also been stumped. Manually installed the git folder, but it's not showing up in the list of nodes. After several hard restarts, of course. Looks like this is just a modification of part of the LayerStyle node, but how it's supposed to work, or if it's supposed to be a mod for that node is unclear.
I got it. I was right, you don't need the purgevram.git, just install the layerstyles node package. It's such a simple thing, it is mentioned in passing on the git page but not explicitly stated that this was an attempt at a standalone node instead of part of a package. At least that's the only way I can interpret it. Regardless, once I installed the layerstyles nodes, the purge node showed up in comfyui. I can't understand why none of the comments that I have read mention this. Allocate that.
I found if you just delete the existing purgevram and add another it works. But does anyone know if the input image needs to be a specifc size? I'm getting a "mismatched size (284 vs. 288)"