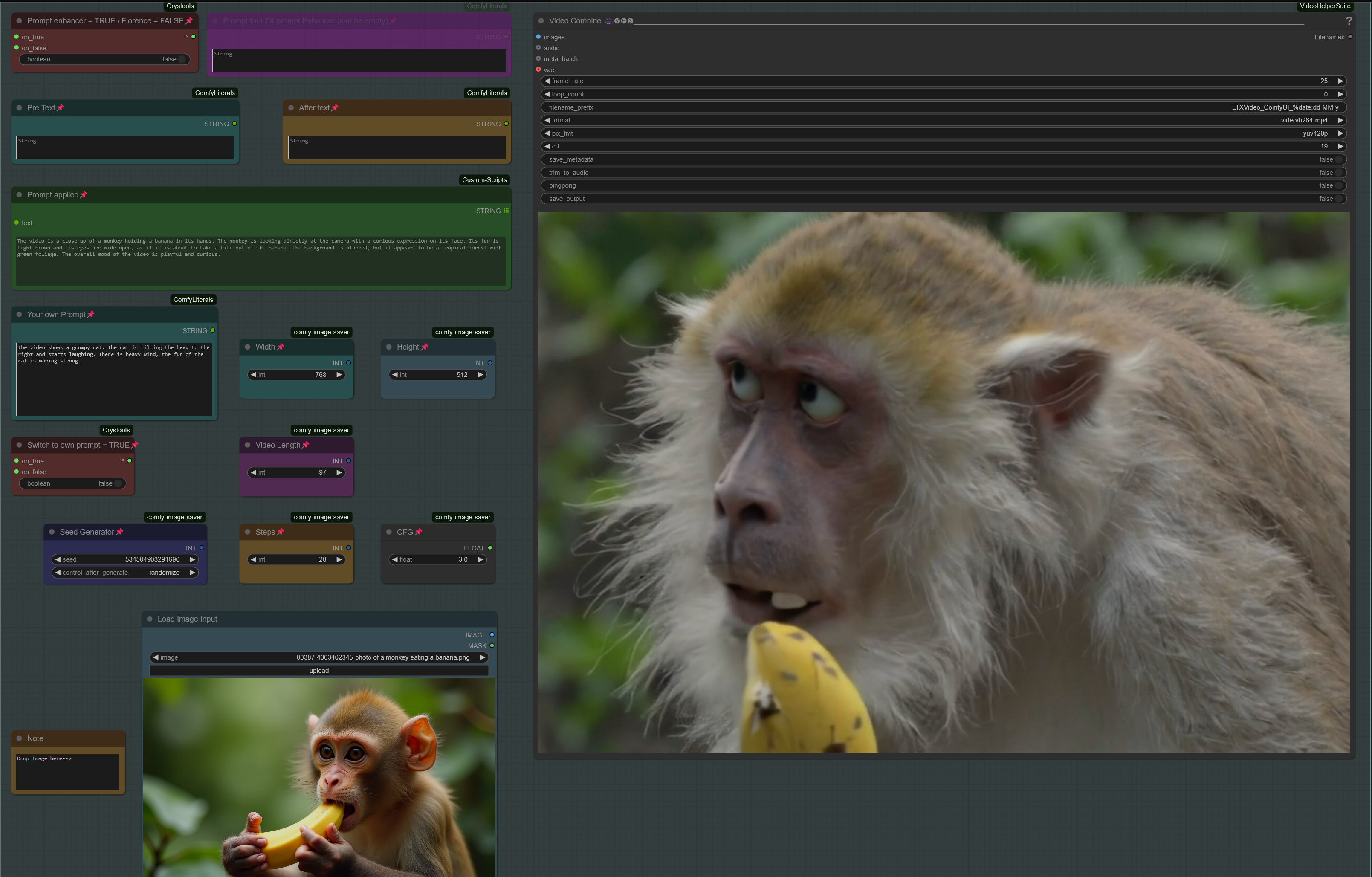
Workflow: Input Image (or prompt) -> captioning to a text prompt -> prompt is used for LTX TEXT to VIDEO (this is a Text to Video workflow, see my other workflow for Image to Video)
V5.0: Support for LTX 0.9.5 GGUF Models and Wavespeed/Teacache
LTX 0.9.5 GGUF Model and VAE: https://huggingface.co/calcuis/ltxv-gguf/tree/main
(vae_ltxv0.9.5_fp8_e4m3fn.safetensors)
(Clip Textencoder): https://huggingface.co/city96/t5-v1_1-xxl-encoder-gguf/tree/main
Worklfow supports Florence caption and LTX Prompt enhancer and works with all models (0.9 / 0.9.1 / 0.9.5)
(see notes in workflow for more details)
V4.0: Support for GGUF Models
GGUF Model, VAE and Textencoder can be downloaded here:
(Model&VAE): https://huggingface.co/calcuis/ltxv-gguf/tree/main
(Clip Textencoder): https://huggingface.co/city96/t5-v1_1-xxl-encoder-gguf/tree/main
(includes a GGUF Version and a GGUF+TiledVae Version for low Vram)
V3.1: Support for model 0.9.1
V3.0: GUI Clean up, reduced no. of custom nodes, feature to use your own prompt.
V2.0: Introducing STG (Spatiotemporal Skip Guidance for Enhanced Video Diffusion Sampling).
GUI includes two new nodes in blue:
STG settings, showing CFG, Scale and Rescale. Plus a switch to change between two layers of the model to be skipped (8 or 14 (default), chose "true" for layer 14 or "false" for layer 8)
I copied a note in the workflow with further info and usable values/limits. Feel free to experiment. In my testing, I kept the values within STG settings as default and just used the switch.
Node "Modify LTX Model" will change the model within a session, if you switch to another worklfow, make sure to hit "Free model and node cache" in comfyui to avoid interferences.
V1.0: ComfyUI Workflow: LTX IMAGE-to-TEXT-to-VIDEO Using Florence2 Caption
This workflow transforms the input images into a prompt (Florence2 for captioning) and uses the LTX Text to Video model for video generation (Image -> Prompt -> Video)
Description
V5.0 Support for Model 0.9.5 with Wavespeed/Teacache
FAQ
Comments (2)
If LTX Prompt Encancer with V5 is causing issues (Error: "Expected all tensors..."), see below thread for solution, might occur with <16gb vram:
https://civitai.com/models/995093?modelVersionId=1511863&dialog=commentThread&commentId=727932
more infos: https://civitai.com/models/995093?modelVersionId=1511863&commentId=722660&dialog=commentThread
can i get any help, please? where should i write the prompt? On "your own prompt", right? Thats what i did but i nothing showed =[