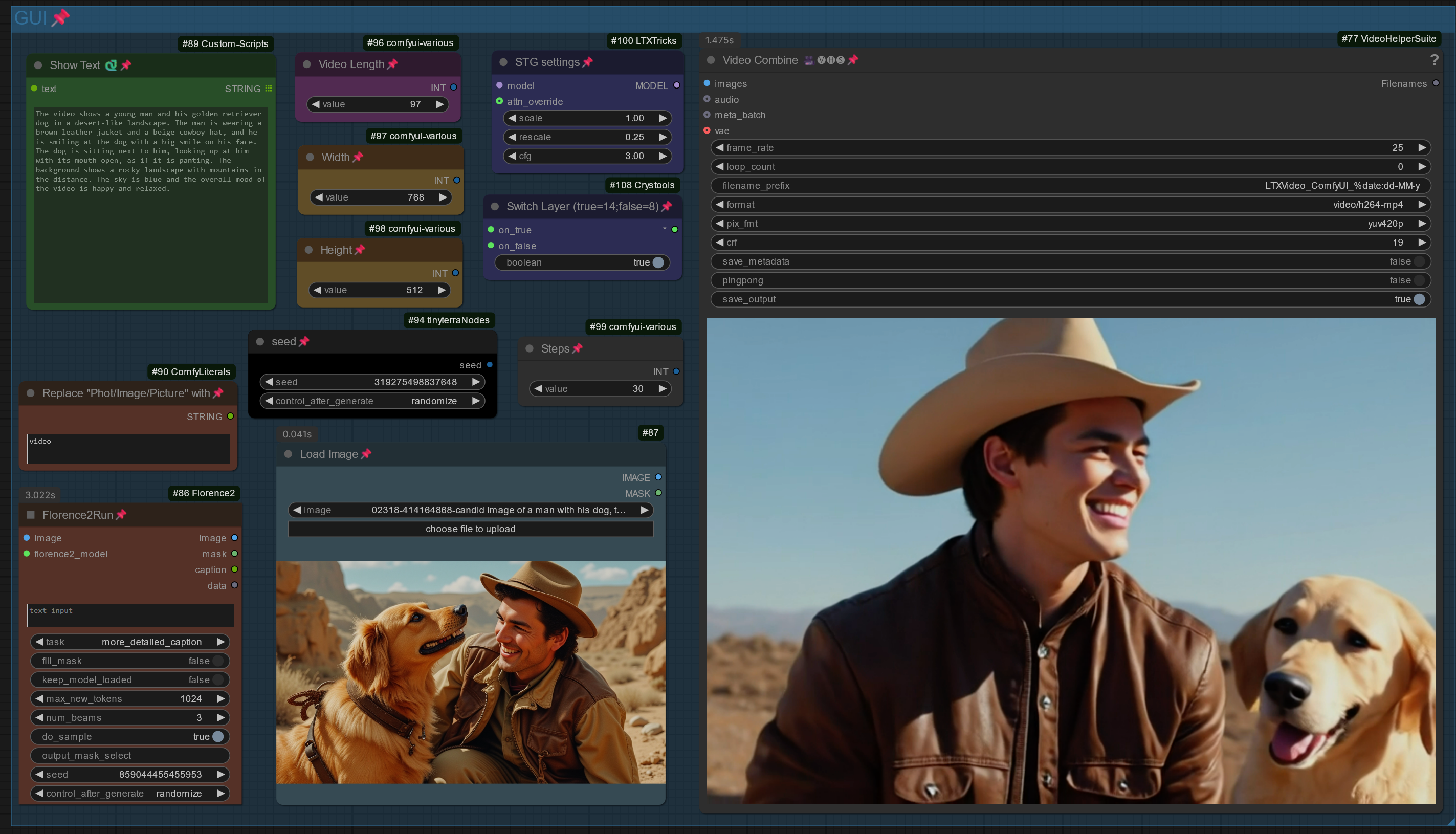
Workflow: Input Image (or prompt) -> captioning to a text prompt -> prompt is used for LTX TEXT to VIDEO (this is a Text to Video workflow, see my other workflow for Image to Video)
V5.0: Support for LTX 0.9.5 GGUF Models and Wavespeed/Teacache
LTX 0.9.5 GGUF Model and VAE: https://huggingface.co/calcuis/ltxv-gguf/tree/main
(vae_ltxv0.9.5_fp8_e4m3fn.safetensors)
(Clip Textencoder): https://huggingface.co/city96/t5-v1_1-xxl-encoder-gguf/tree/main
Worklfow supports Florence caption and LTX Prompt enhancer and works with all models (0.9 / 0.9.1 / 0.9.5)
(see notes in workflow for more details)
V4.0: Support for GGUF Models
GGUF Model, VAE and Textencoder can be downloaded here:
(Model&VAE): https://huggingface.co/calcuis/ltxv-gguf/tree/main
(Clip Textencoder): https://huggingface.co/city96/t5-v1_1-xxl-encoder-gguf/tree/main
(includes a GGUF Version and a GGUF+TiledVae Version for low Vram)
V3.1: Support for model 0.9.1
V3.0: GUI Clean up, reduced no. of custom nodes, feature to use your own prompt.
V2.0: Introducing STG (Spatiotemporal Skip Guidance for Enhanced Video Diffusion Sampling).
GUI includes two new nodes in blue:
STG settings, showing CFG, Scale and Rescale. Plus a switch to change between two layers of the model to be skipped (8 or 14 (default), chose "true" for layer 14 or "false" for layer 8)
I copied a note in the workflow with further info and usable values/limits. Feel free to experiment. In my testing, I kept the values within STG settings as default and just used the switch.
Node "Modify LTX Model" will change the model within a session, if you switch to another worklfow, make sure to hit "Free model and node cache" in comfyui to avoid interferences.
V1.0: ComfyUI Workflow: LTX IMAGE-to-TEXT-to-VIDEO Using Florence2 Caption
This workflow transforms the input images into a prompt (Florence2 for captioning) and uses the LTX Text to Video model for video generation (Image -> Prompt -> Video)
Description
V2.0 Including STG feature (Spatiotemporal Skip Guidance for Enhanced Video Diffusion Sampling)
FAQ
Comments (7)
I cannot reproduce anything image2video
with this new STG workflow.
Everything looks not matching at least in the default workflow V2.
Using this method also introduces full censorship of male & female anatomy (NSFW).
The non STG LTX Workflow
is offering this, same as it is with the official LTX v0.9 workflows.
The non STG workflow replicates a input picture 1:1 if you care to always add the input picture resolution in the workflow.
This is very confusing.
Hey, the STG workflow includes a node, that modyfies the model within a comfyui session,thus making a non STG workflow in same session behave fancy, as you describe it. if you hit the „free node and model cache“ within cmfyui, it should solve the issue. Not sure, if I understood your point correctly tho.
@tremolo28
Thx for your quick reply.
This is not working.
- I updated comfy ui portable today after like 4 days to
ComfyUI: 2893[8af9a9](2024-12-06)
Manager: V2.50.1
- i added your workflow v2.0
- I clicked install missing nodes
- i restarted
So what i tried now is that i reinstalled comfyui portable
clean with version:
ComfyUI: 2893[8af9a9](2024-12-06)
Manager: V2.50.1
It is behaving identical not reproducing anything image2video as seen in the picture.
Then i tried it with
ComfyUI: 2880[57e8bf](2024-12-02)
Manager: V2.50.1
and it is same behaving.
Once i load the "non STG" Workflows including yours it works perfect again.
@tremolo28 I think he's saying it doesn't produce results like you show in the examples above. Imputing an NSFW image of a naked chick will cause it to output a completely different looking one in the video than the one you entered. Tried this myself the other night while trying to make some boobas bounce up and down and the output hid the boobas, and the lady in the output vid looked deformed and nothing like the one i inputted.
@Tsterbta This workflow is setup as a TEXT to VIDEO workflow, where the Input image is just used to create the prompt as TEXT and uses it to create the video, therefore I named it IMAGE to TEXT to VIDEO. If you want to reproduce the image, you can try my other workflow for a pure IMAGE to VIDEO. This one works with NSFW content. https://civitai.com/models/995093/ltx-image-to-video-with-autocaption-workflow
@tremolo28
So now that you explain it is set to be used for TEXT to VIDEO all is clear.
Thx for explaining.
Your other workflow has no STG Support so i was overall happy to see you released a STG Workflow
but i did not realize this is not the same image2video process as it is in the other.
And the non STG Workflow also uses Florence in first place to receive the prompts and then output the image2video.
Your non STG imag2video is awesome.
I am also impressed how all the motion data is included in a png picture if you save this beside your video and that the seed in the png metadata can recreate the exact same animation with it.
@LVNDSCAPE glad it works now for you