
Please see our Quickstart Guide to Stable Diffusion 3.5 for all the latest info!
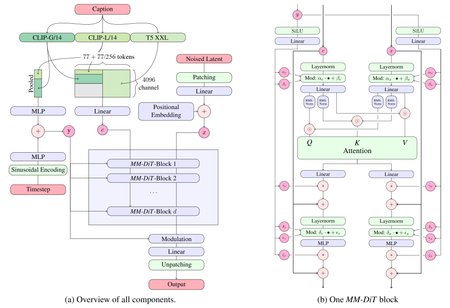
Stable Diffusion 3.5 Large is a Multimodal Diffusion Transformer (MMDiT) text-to-image model that features improved performance in image quality, typography, complex prompt understanding, and resource-efficiency.
Please note: This model is released under the Stability Community License. Visit Stability AI to learn or contact us for commercial licensing details.
Model Description
Developed by: Stability AI
Model type: MMDiT text-to-image generative model
Model Description: This model generates images based on text prompts. It is a Multimodal Diffusion Transformer that use three fixed, pretrained text encoders, and with QK-normalization to improve training stability.
License
Community License: Free for research, non-commercial, and commercial use for organizations or individuals with less than $1M in total annual revenue. More details can be found in the Community License Agreement. Read more at https://stability.ai/license.
For individuals and organizations with annual revenue above $1M: please contact us to get an Enterprise License.
Implementation Details
QK Normalization: Implements the QK normalization technique to improve training Stability.
Text Encoders:
CLIPs: OpenCLIP-ViT/G, CLIP-ViT/L, context length 77 tokens
T5: T5-xxl, context length 77/256 tokens at different stages of training
Training Data and Strategy:
This model was trained on a wide variety of data, including synthetic data and filtered publicly available data.
For more technical details of the original MMDiT architecture, please refer to the Research paper.
Description
FAQ
Comments (44)
我想你肯定会提供下载的,我就一直看着你,果然。。。。
我们会有一个sd3.5的训练排行榜吗?
Excited for this and the upcoming medium version which is supposedly smaller than SDXL (unet) while again, supposedly, delivering close to SD 3.5 Large Turbo aesthetics and prompt adherence.
I'd see this as a win anyway for the low vram community if 3.5 Medium is even just a bit better than sdxl. (as you can probably tell, my focus is more on medium than large 😉)
Well, that was quick
Hands are EXTREMELY UGLY (sometimes ...), try to do more closeup portraits if you want "great" results out-of-the-box!
... and this is again = NOT the skill issue ;)
Man I'm downloading with all haste. Hopefully it can do hands and round eyes.
Will you add the Large Turbo version as well? I'll be using that one, as the regular Large takes way too long on my hardware.
Possible to run in Forge?
Much better than SD3. I have a lot of hope again that the community can achieve great things here! <3
Unable to import this in to DrawThings. Any suggestions?
Has the license been fixed such that people can train a PonyXL equivalent for this? SDXL only surpassed SD 1.5 finetunes after lots of people worked really really hard to fix it.
It worked! 2080 Super 8Gb - 64Gb RAM - 240 sec with ComfyUI!
It does nudity better than FLux
We are so back
MacBook M3 Pro Max
10/20 [04:11<03:26, 20.70s/it]
Seems like the make or break for an open model is community adoption. Apparently Flux still beats this, so Im pessimistic the community will adopt SD3.5 large when Flux exists. So Im still waiting on SD3.5 medium. Thats where the real magic happens. Just small enough for the community to fine tune. Currently there is extremely slow progress on Flux fine tunes because its so huge and expensive to fine tune. The current Flux fine tunes are actually devolving in quality, like the recent ones have gone back to early SDXL low quality, so its going to take years to train. Its taken SDXL fine tunes many months to get this far and the currently SDXL fine tunes are amazing now, but thats a small model compared to Flux. A 2 billion parameter model like SD3.5 medium will be much more affordable to fine tune.
Finally!!! This is what SAI should have released from the get-go. Being non-distilled, fine tunes and controlnets should be easier to train than Flux too. I am so stoked!
Forge version when 😍
CAN IT BE USED IN WEBUI?
Is it really fp32?
I think it's possible to fine-tune it with a single consumer-grade GPU like 3090 or 4090, but it'll take some time, also I don't understand if text encoders are included in the model itself or you need to load them separately like you do with Flux?
Finally!
Well this won't run for me (8GB) with it's huge size and i will not bother downloading it, but the good news is 3.5 medium will be released 29oct.
Good job, it's uncensored and atleast skin textures are way better than Flux.
Let's goooo!
I just started testing SD3.5, but I already like it very much! It seems that a small failure with SD3.0 led to a new big success! What I love about SD models is that they are always creative, they can do oil and watercolor, they know many styles of artists (you can conduct fascinating research) and all this out of the box. For example, Flux is not capable of such and despite its size, it has a narrow outlook, which is why the generation process becomes quite boring.
Still trouble with the hands, and yes the anatomy in general can be weird, but it's clearly a step forward. Good work on the stylistic colouring, looking forward to the finalised community models.
To be honest, not bad. Many of us were so disappointed last time that remain skeptical at first, but SD3.5 do have something this time. In my own experience, it's not much worse than flux, even leads in aesthetics variety. Though you can still see some problem of anatomy, it is not a bad place to start.
Am I the only one whose site doesn't show SD3.5 images uploaded less than 15 hours ago?
Not as good as Flux. Worth trying briefly though.
looks good, even better than Flox
Hands still shit
if we refine flux images with Sd3 will it be illegal to licence?
How the hell do I download the clip encoders??
All of the files on huggingface for this model seem to be unavailable and cannot be downloaded right now.
Mine 6gb rtx 3060 crying ;-;
Will a RTX 3060 12GB run it?
its hard to say if its better than flux . Its doing faces better than flux. It does text a little worse. And everything else seems about the same.
Am i wrong?
How do i run this with swarmUI?
hi i have AssertionError: You do not have CLIP state dict!... i have installed al Clip Text Encoders and paste it to text encoder folder in my webuiforge but still this error is this working with forge or only comfyui?
anyone did a speed test compared to flux? i'm interested in same stuff test, like fp8 vs fp8 or same gguf
As far as I can tell SD3.5 has a much better Promt Adherance than Flux also Artstyle/Artist knowledge. You get what you promt for :-). Flux makes nice Images but not always what I was looking for, SD3.5 Large delivers.
So sad that img2img upscale or latent upscale are not working for now :-(. The only workaround would be UltimateSD Upscale - or upscale with an img2img SDXL workflow - which is time consuming...
AssertionError: You do not have CLIP state dict!
Are there any forks of Forge that support 3.5 large? Which fork are people even using now? I'm still using a really old build from lllysviel cause I'm a script kiddie ;_;
So much praising, but final output is mediocre, if character is ok-ish backgrounds heavily simplified, style is not consistent, one image can be in photo style, next image in cartoon style.
Yes is absolutely has no clue about human bodies (are humans ever exists?), better make images of elephants and cosmonauts on bicycles in funny hats... Pathetic.
More expensive buzz than flux
buzz cost 85 blue buzz,
dead
sd_models.py