







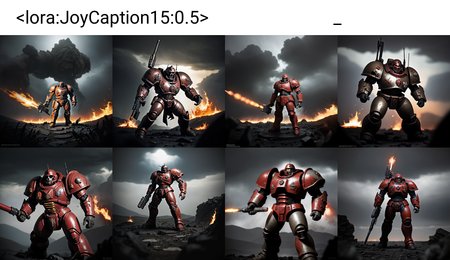
After seeing the new detailed prompting methods flux uses to generate images, I decided to see if it was possible to train other models to accept JoyCaption style prompts. I will attempt to train multiple common non-Flux checkpoints like Pony, SDXL, and SD15 to accept more advanced prompts. Check each version's version details to see what it does and how it should be used.
Description
Very rough beta version for SD1.5 trained on about 20 images at 512X512 res on kohayaSS at a relatively high strength for about 1500 steps. Seems to be a bit overtrained, so I recommend lower strengths of around 0.4 to 0.6, but you can go higher if you are upscaling. Results at 712 res seem to be good, and I recommend using DPM++ 2M SDE Karras as the sampler unless you are upscaling. Sadly doesnt seem to be any better at generating text than default SD1.5, but its prompt adherence to detailed prompts seems a bit better.
FAQ
Looks like we don't have an active mirror for this file right now.
CivArchive is a community-maintained index — we catalog mirrors that volunteers upload to HuggingFace, torrents, and other public hosts. Looks like no one has uploaded a copy of this file yet.
Some files do get recovered over time through contributions. If you're looking for this one, feel free to ask in Discord, or help preserve it if you have a copy.