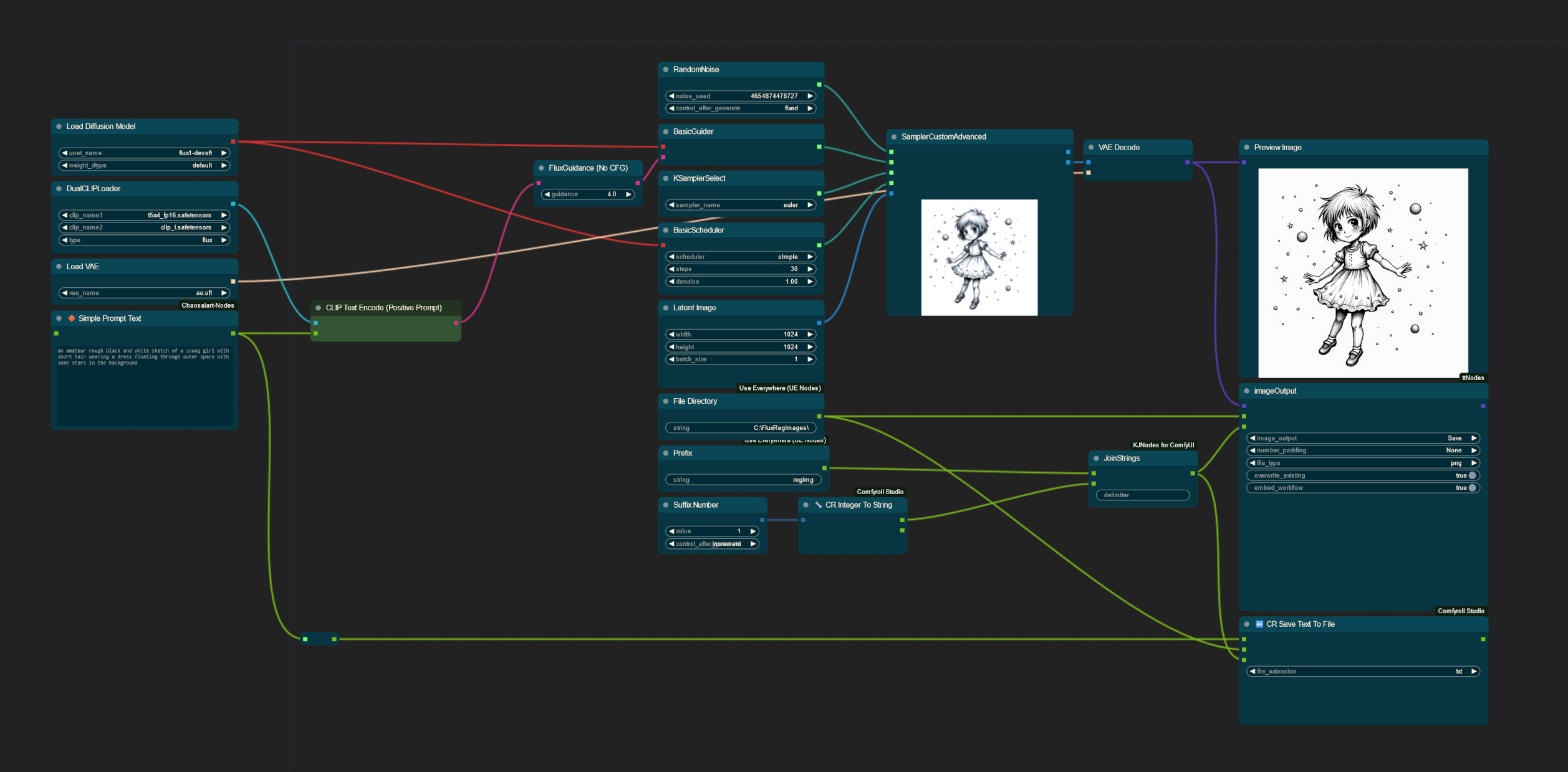


Resource to help creators with making better FLUX models
With many getting into FLUX, people have started to notice that some LoRAs will impact other elements of the model in less than desirable ways; failure to differentiate between male and female characters, character elements bleeding into background characters, and completely losing the ability to prompt different styles when using particular LoRAs.
This is almost always the result of a lack of regularization images in a dataset!
Flux is particularly sensitive to forgetting elements of it's original training depending on the dataset used to train it, and thus regularization images are far more important than they were in Stable Diffusion models, and should make up between 20-50% of your dataset.
But I fully understand why regularization images have been avoided by many; natural language captioning is already annoying as is for large datasets, which is why I developed the following workflow!
The workflow is based on 2 key principles:
Regularization images and their corresponding captions should be as close to what the original model would generate as possible to preserve it's weights
It is far less tedious to prompt an image for generation than it is to caption an existing image, and far more reliable than current auto-captioning methods
With this in mind, my workflow will allow you to generate an image using Flux with ComfyUI, and then will save a corresponding .txt file containing the caption used alongside it. Whilst not included in the workflow as is, you could also using auto-prompters for Flux to further automate the process! It also includes 40 regularization images in 1024x1024 (can be bulk-resized using chaiNNer or other programs as needed) I have already generated for use in my own datasets to get you started.
Notes for Regularization Images:
As stated earlier, regularization images should make up 20-50% of your dataset
Should primarily consist of a variety of different types of the class you're training
For a person, regularization images should primarily consist of people of both sexes, various races, ages, hair colors, clothing, image styles, poses, etc
Elements not directly attributed to your image class should also make up a portion (10-20%) of your regularization images (setting, background elements, props, etc)
When training, it is best practice to include some sample prompts not containing your subject in order to judge whether your model is being overfit
Description
Initial Version
Includes Workflow + 40 Images & Corresponding Caption Files
FAQ
Comments (13)
Thanks very much for this. Two questions:
1. When you're training with regularization images, do you just put them along with their captions in the same folder as the dataset containing the concept/subject you're training? And I assume the training script treats regularization images and concept images agnostically, so there's no special settings which make the training behave differently for regularization images?
2. When training a concept that the model does not know - such as pussy - do we have to train the text encoder as well? I've seen guides that say to leave text encoder training off. If we're not training the text encoder how does the modified unet associate the introduced concept with the words in the caption?
Thanks
1. As far as I'm aware at the moment, yes. I never looked too much into regularization images for SDXL training just because the impact seemed marginal due to the architecture, but from what I understand regularization images functioned differently (though largely produced similar outcomes) than dataset images when training SDXL models. This might be subject to change in the future, at which point I'll update the info
2. The T5 encoder cannot be trained currently, and likely wouldn't benefit much, if at all, from training due to how it functions more like an LLM, unlike CLIP. The CLIP model should be capable of training, but the impacts of the CLIP model with FLUX seem to be largely marginal, as you can test by swapping out the default CLIP model for FLUX with various other SDXL CLIPs that have been trained on entirely different data. Again, this could be subject to change in the future.
I'll also just add that FLUX does not use a UNet architecture, but rather DiT. I'm truthfully not informed on the differences between these architectures.
@TheGreatOne321 Thanks for the reply!
I got the same question. seems like nobody wants to answer or nobody knows
@Postmeta Just to update since I've done a bit more research since my first reply, training the text encoders is unnecessary. Training the CLIP model results in extremely marginal changes, usually relating to composition, smaller details, and background elements. It's really just not worth the effort.
Similarly, even though T5 training has recently been implemented, training it seems pointless; the simplified explanation of the way T5 works is that it constructs a context in arbitrary latent space from a given text prompt in a similar way that LLMs do. From there, when you train an image generation model like Flux, what you're essentially doing is taking the latent space that the context gives you, and adjusting the weights in the image generation model to match the context given by T5 based on your training data.
This is why the T5 still needs to be loaded alongside the image model when training even though it's not being trained itself, and it's also why Flux can be rather prone to over-fitting if you don't use regularization images and/or masked training.
Thank you for your valuable work! If I may ask, when training a specific individual, would generating diverse characters like you do be the best approach? Alternatively, how would it work if I just removed trigger words from my dataset, such as changing 'ohwx man' to 'man', in order to generate regularization images?
For regularization images specifically, having the most diversity possible is a best practice. Reason being is that Flux training has a tendency to overwrite existing model weights, and a diverse set of regularization images prevents that from happening.
For the character itself, having the widest variety of angles, poses, expressions and such is generally good practice so that it minimizes the degree to which the model has to guess on aspects it wasn't trained on.
I don't recommend either practice. The tagging of subjects with phrases like "ohwx man" at the beginning of a caption is a practice is carried over from CLIP training, and tends to result in worse prompting flexibility.
Similarly, removing all captions/replacing the caption with the class will result in overfitting without regularization images, and underfitting without.
Instead, just caption the image as you would prompt it. If the subject is named "Dave Davidson", caption the image as "a photo of a man named Dave Davidson", "a photo of Dave Davidson", or "a photo of Dave Davidson, a man..."
Thanks a lor for sharing. It is really great work for some lora training. Could you tell me how to generating Regularization Images for painting style lora training
Haven't trained style LoRAs so can't really say. The process shouldn't be any different unless you're training the style LoRA without keywords, but I'd recommend against that.
Either way, double checking with people who have trained style LoRAs would probably be your best bet.
Nice workflow! Is there any particular reason you use guidance at 4.0? Isn't flux's default 3.5?
Guidance at 4.0 tended to result in text being followed more closely and more reliably without impacting image quality much. With guidance at 3.5 there were more images that had to be redone with different seeds or scrapped altogether.
Thank you for sharing this. Unfortunately, after training a model comprised of ~40% regularization images, I found that it completely failed to learn the character's likeness.
Maybe YMMV depending on your training settings, but for me 40% regularization is way too high.
Great, thanks!