





clip 2, vae on, hypernetwork strenght 1.
1-Install Monkeypatch Extension and reload the ui
https://github.com/aria1th/Hypernetwork-MonkeyPatch-Extension
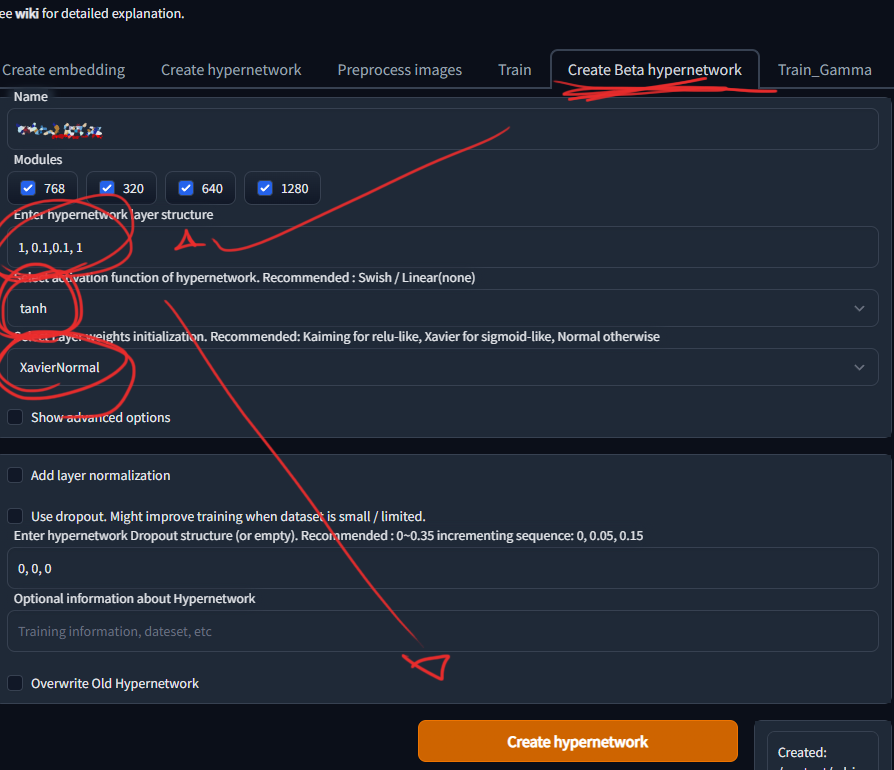
2-Go to create Beta hypernetwork in your train section.
3-Place this layer structure 1,0.1,0.1,1 //thanks queria!, i personally like this so much.
4-Select activation function of hypernetwork:tanh
5-Select Layer weights initialization:xavier normal
6-and finally, create the hypernetwork.
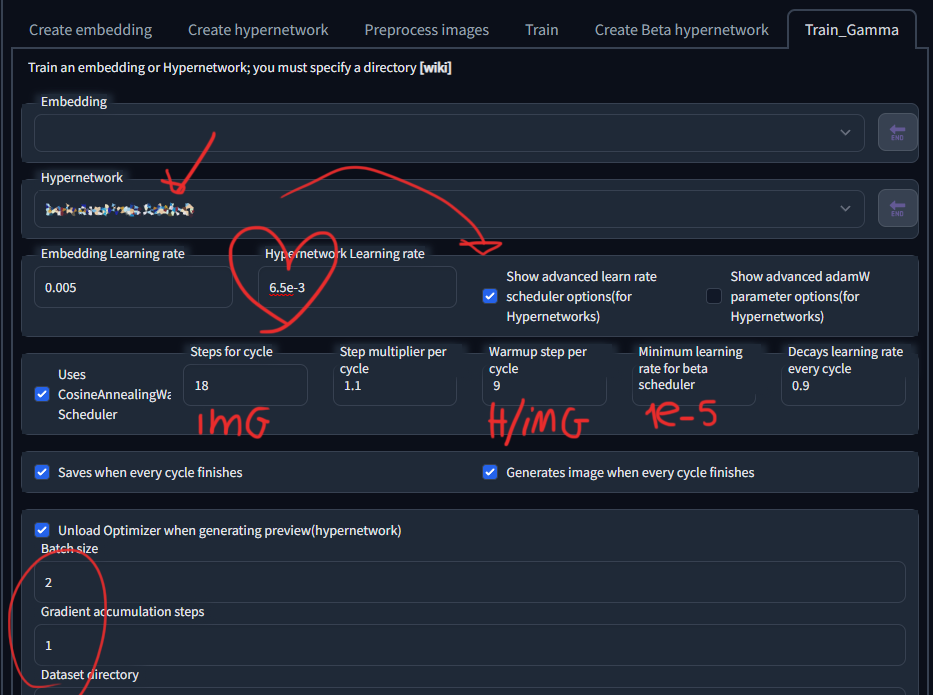
7-now in Train_Gamma, select your new hypernetwork.
8-Hypernetwork Learning rate: 6.5e-3 "this is for the math" so is perfectly normal ,also, 6.5e-4 will cause less damage to original image.
9-enable Show advanced learn rate scheduler options(for Hypernetworks) and Uses CosineAnnealingWarmupRestarts Scheduler.
10-Steps for cycle = number of images in your dataset.
11-Step multiplier per cycle: 1.1 or 1.2
12-Warmup step per cycle = the half of number of images.
13-Minimum learning rate for beta scheduler = 1e-5 [ or 6.5e-7 , will get less style from dataset, but more control ]
14-Decays learning rate every cycle = 0.9 or 1
15a-batchsize 2, grad 1, steps 1000.
15b-you can also do this [ batchsize 2, grad(number of image in dataset divided by two) but for that you only will need something like 250 steps, but personally i don't like it.
16- your prompt file need to be style.txt.
17- you can also try to "Read parameters (prompt, etc...) from txt2img tab when making previews" to see results with the style in your prompt, for example, mine is "girl in a red kimono".
Note: i train with 2 clip skip, none hypernetwork, and 1 hypernetwork strength.
18- and i'ts that! 5 MB of hypernetwork trained in under 10/20 minutes.
Description
this is one of my first trains using this method
FAQ
Comments (15)
Looks interesting!! Are the results better than Lora or Dreambooth? What is the usecase of Hypernetwork over these 2?
Dreambooth creates a full model, Lora I haven't used yet.
Hypernetwork is more akin to training the model, but without training the entire model or being limited to keyword and classes like Dreambooth and embeddings.
Also, if you train a hypernetwork in a model, it should be compatible with models that are similar. Example, training on waifu diffusion and then using the hypernetwork in other waifu diffusion based models.
cool, thanks
Nice tutorial, I would like to point out that this is good for complete style changes hypernetworks. If you want to create hypernetworks that only activate with certain keywords, you have to train it slightly different.
You can use this entire tutorial, just change weight decay to something like 50 or more. It will somewhat preserve the original composition and words not used in the hypernetwork training.
For longer training and less drastic networks, I recommend these settings:
Size: 1, 1.5, 1.5, 1
(You can change these if you want, 1, 0.1, 0.1, 1 is perfectly fine for targeted hypernetworks, the default 1, 2, 1 also works alright.)
Activation: softsign, mish, or tanh
(Softsign and tanh are safe, they wont explode or vanish, mish is faster running however, by around 1 iteration per second depending on your hardware and hypernetwork size)
Initialization: Normal or xavier
(Normal if you want to be 'safe', xavier might give better results for style changes.)
Learning rate: 5e-6, or cosine: 5e-5 to 5e-7 minimum, following the rest of the tutorial cosine guides
(You can fine tune the learning rate as well, using the suggested by the tutorial also works and is faster, it depends on the results you're looking for.)
Under the advanced AdamW options:
Weight Decay: 0.1 or higher
(0.1 is a safe value for regular training, to maintain the model's own style and composition you want to use higher values, some people even use 200.)
Beta2: 0.1
(This makes the training more 'agile' towards details. Careful when using high learning rates however, if it messes up, leave it as default and only change weight decay.)
what is beta2? don't see this option anywhere
Like the tutorial said, you need Monkeypatch installed. Then under Train_Gamma tab, enable show advanced adamw options.
did not work for me on vanilla sd 1.5 sadly, result is a mush
that's sad, the dataset needs to be conditioned by booru if u are training style.
also, try a version without piratekitty tip, just to see what happens, a normal one with 2 batch, 1 grad, 1000 steps.
Thank you very much for this tutorial! What is the minimum amount of VRAM required to train an hypernetwork, please? Would a RTX 2060 with 6 GB VRAM work?
you can adjust vram settings under your auto1111 settings, to optmize, but with low vram, you needs to run in 1 batch.
idk much because i tweak with colab.
Thank you! 🙏
@luisa_pinguin Mind sharing your colab? I've been looking for an up-to-date colab for training a hypernetwork, and or embedding. 🙂
Does it work for sexual poses? I was thinking about making a hypernetwork for sexual poses. To work, I have to extract the poses without background, like PNGs? Or just JPEG with normal background might work?
Help! i got this error after hit the train hypernetwork button:UnboundLocalError:local variable 'hypernetwork' reference before assignment