

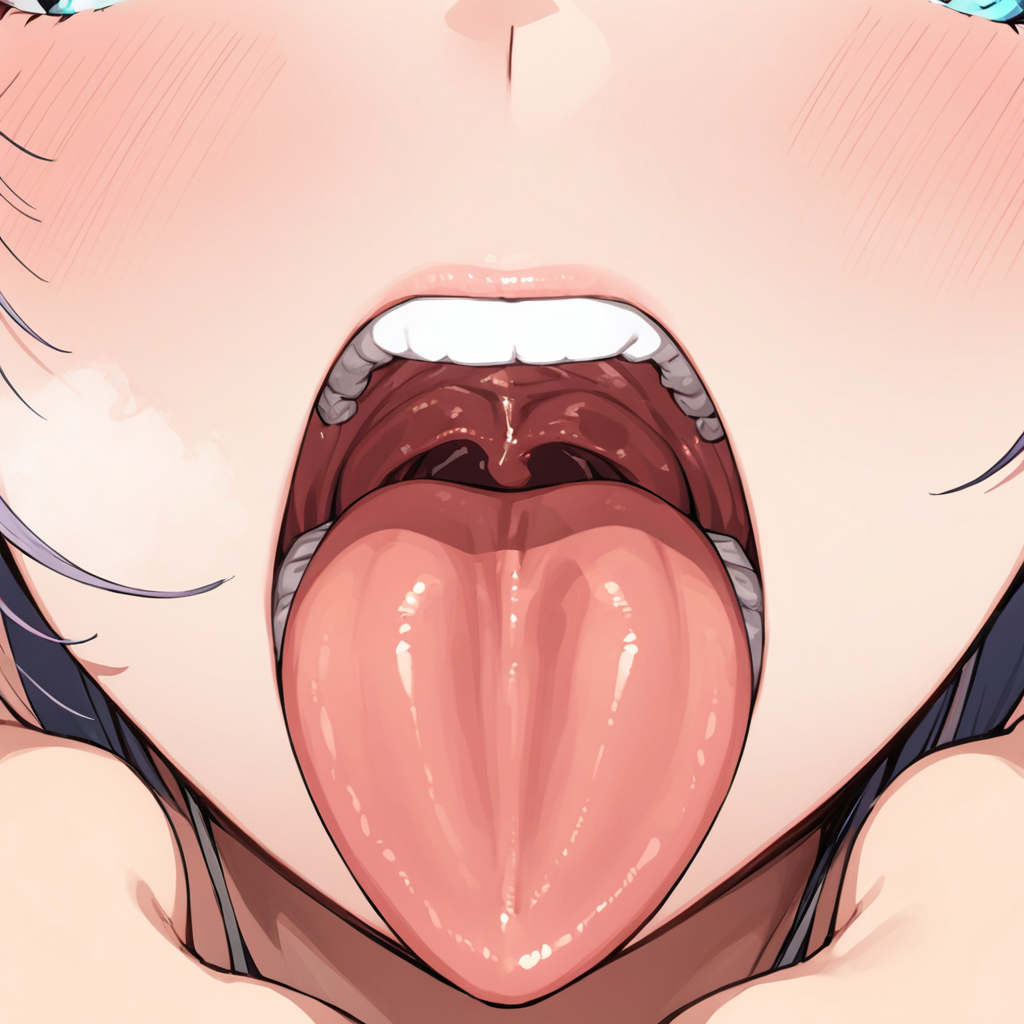
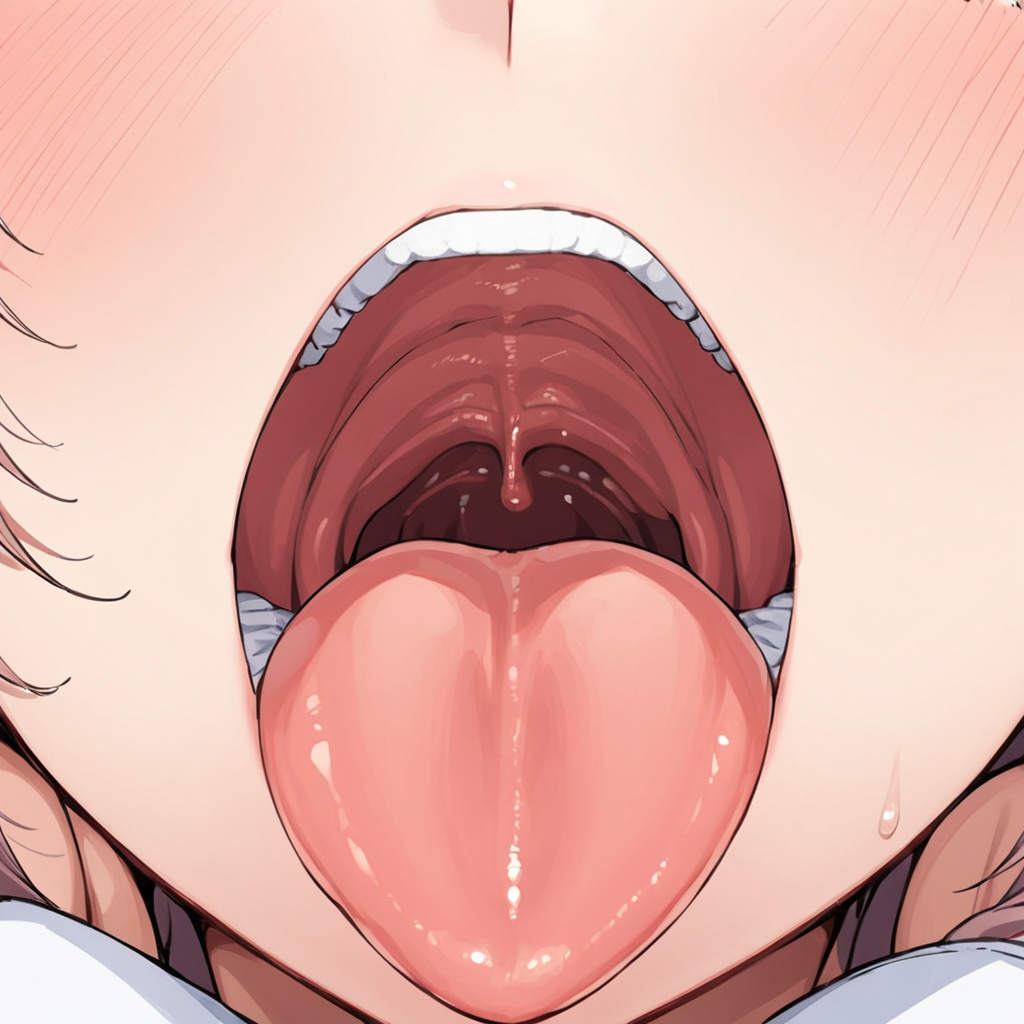
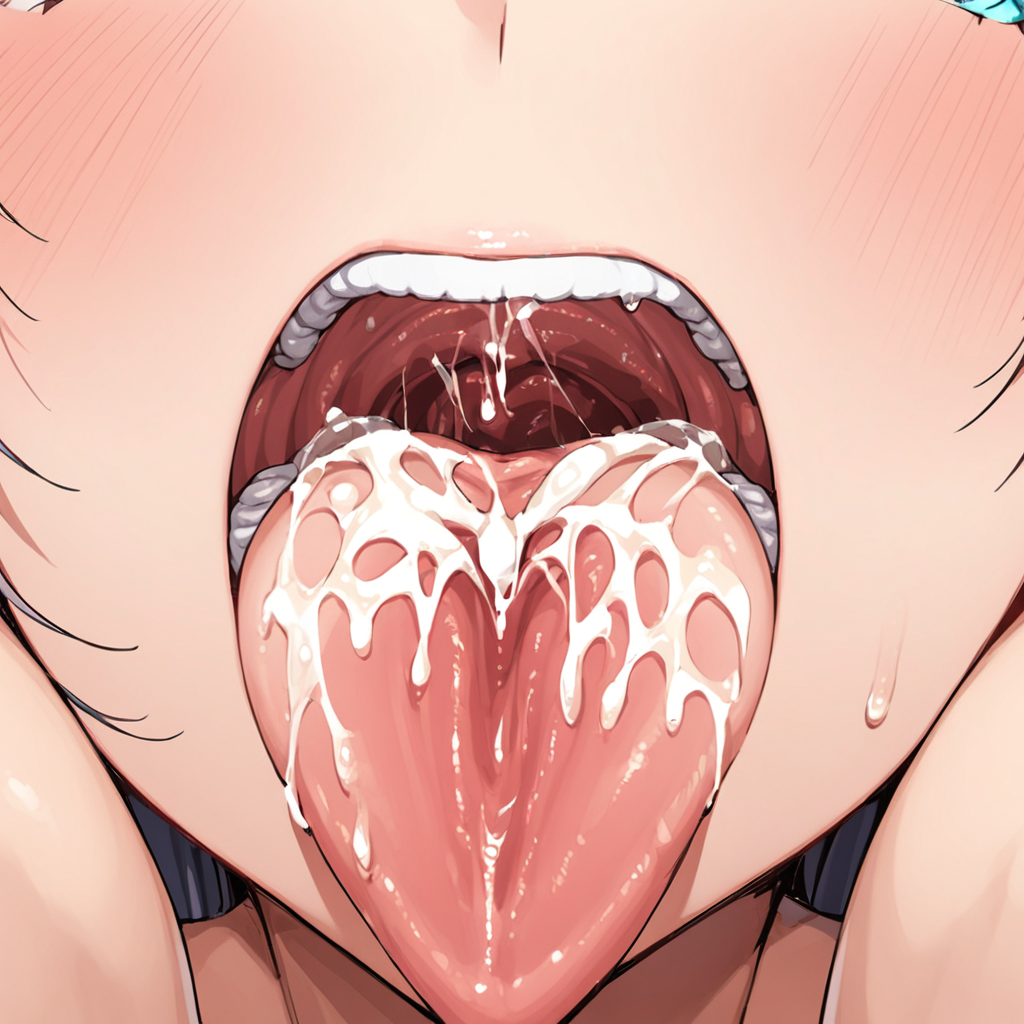




Works with illustration models. Lora is for focusing on the inside of the mouth.
Describes the inside of the mouth that would collapse without Lora.
No trigger word is required, but an auxiliary prompt is required.
Example, (mouth zoom up:1.3),(mouth close up:1.3),(oral invitation:1.3),(oral zoom up:1.3),(uvula:1.2)
It may be difficult to display the entire face.
This is the learning model. animagineXLV3_v30
If you have a good image, please publish it here.
Description
FAQ
Comments (6)
Could you make one for SD 1.5?
I'll try making it. I'll publish something good once it's completed.
such amazing
Challenging to use, but shows some good results sometimes. Need to test more. Hard to get teeth right. Link
Thank you for posting. Since it mainly learns from images of the mouth, it may often be deformed if a face is reflected. Discover good prompts.
This Lora works extremely well without (which is super impressive) totally fucking up the likeness of my LoRAs. I trained a girl for example yesterday with about 200+ pictures (Dreambooth > LyCORIS extraction). And there were very little to no pictures with open mouth. And your LoRA well does it. Fucl. That's a great job.
I'm only training faces and bodies for the moment. But I'd sure would love to know more about the dataset behind your results. Would you please consider sharing the dataset and eventually (might not be necessary if you don't want that) a json (Kohya, OneTrainer, etc. )
I see so many shitty LoRAs in here that when someone manages something that definitely works better than others, I'm very interested in being able to train similar results with my next training attempts (I use OneTrainer now, soooo cool UI and finally a resume that actually works perfectly).
I hope you'll consider sharing the dataset so that others can eventually learn sthg from the way you did it. That'd be great!
Anyway. Thanks for the share. Great LoRA really.
Cheers (b^-^)b