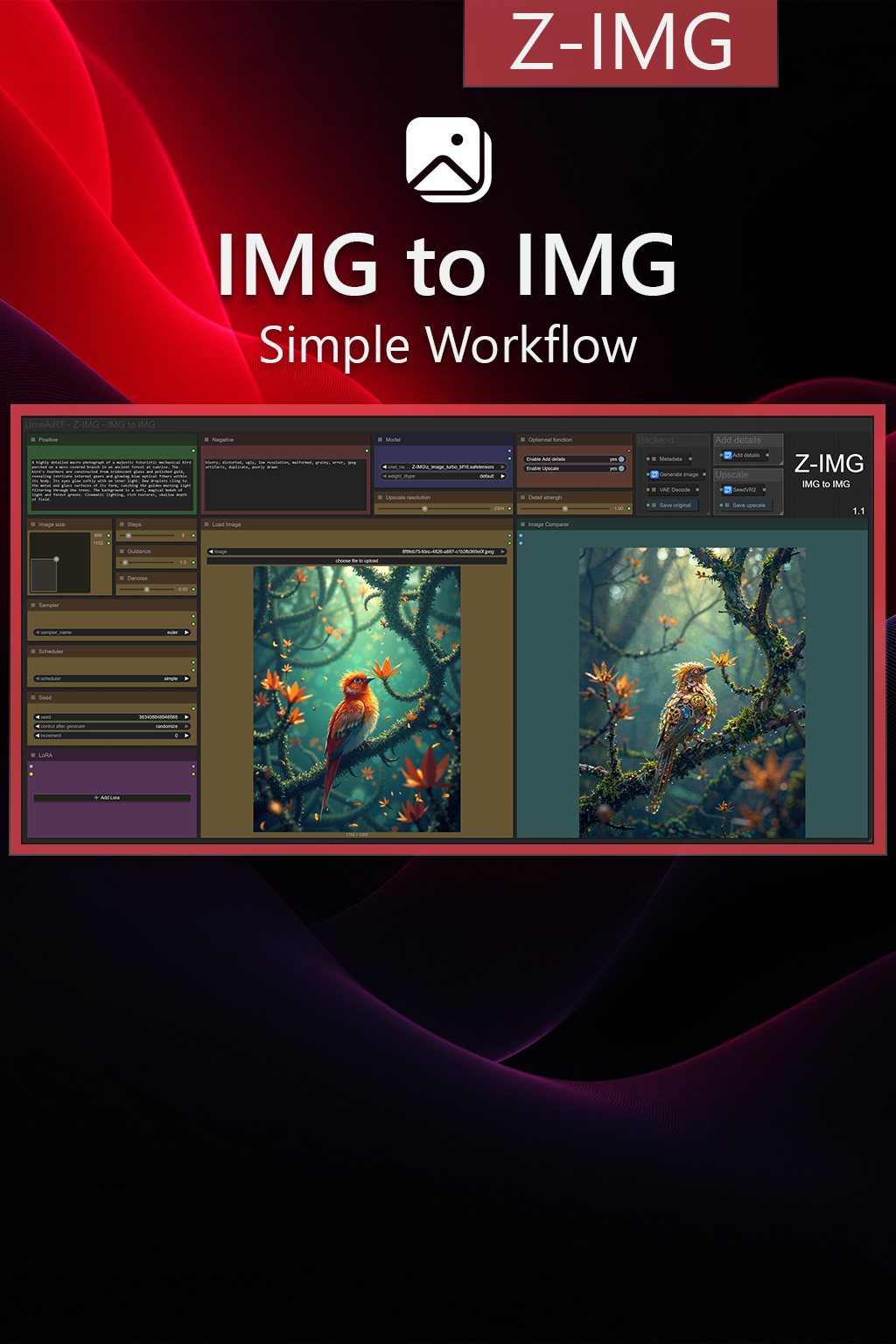

✨ Z-IMG — Image to Image — Simple Workflow
A clean, all-in-one Z-IMG image-to-image workflow built entirely with the UmeAiRT Toolkit for ComfyUI.
Only 8 nodes. No spaghetti wires. Just load your model, write your prompt, and hit generate.
⚠️ IMPORTANT — Nodes 2.0 Required
This workflow is built for the Nodes 2.0 (Vue) interface of ComfyUI. If you don't enable it, the workflow may have display problems.
How to activate Nodes 2.0:
Open ComfyUI
Go to Settings (⚙️ icon, bottom-left)
Find "Use Nodes V2 (Vue)" and toggle it ON
Refresh the page
Load the workflow
If you prefer the classic interface, check out my Legacy version of this workflow instead (link).
🎯 Features
Text-to-Image generation
Automatic download of models in auto version
Lighning LoRA included
Detail Refiner sampler
Built-in SeedVR2 upscaler — high-quality tiled upscaling (toggleable on/off) Slower than a classic upscaler, but significantly better quality
Full metadata embedding — your images are saved with all generation parameters, ready for online publishing and remixing
3 LoRA slots — with individual on/off toggles and strength control and you can connect as many other lora modules to each other for as many LoRA as you want.
📦 Custom Node Required
Only one custom node to install:
Install via ComfyUI Manager (search "UmeAiRT") or use the UmeAiRT Auto-Installer.
The Toolkit packages everything internally — upscaler, face detailer, metadata saver. No other custom nodes needed.
📂 Files you need (in manual version)
📂for "base" version :
Model : z_image_turbo_bf16.safetensors
in ComfyUI\models\diffusion_models
CLIP : qwen_3_4b.safetensors
in ComfyUI\models\clip
📂for GGUF version :
Model : Q8, Q6, Q5, Q4, Q3
in ComfyUI\models\unet
CLIP : Q6
in ComfyUI\models\clip
📂Common
VAE : ae.safetensors
in ComfyUI\models\vae
Description
New "add detail" fonction,
Add SeedVarianceEnhancer,
Change upscaler to SeedVR2.
FAQ
Comments (4)
I'm trying to run it, but it gives me this error:loader with Name (Image Saver) Error(s) in loading state_dict for NextDiT: size mismatch for x_embedder.weight: copying a param with shape torch.Size([3840, 64]) from checkpoint, the shape in current model is torch.Size([2304, 64]). size mismatch for x_embedder.bias: copying a param with shape torch.Size([3840]) from checkpoint, the shape in current model is torch.Size([2304]).
I launched it, but for some reason the quality is super bad, although I'm using the full model, without GGUF, can you tell me the settings? 👉👈
@JolyBelle My settings are in the workflow. Maybe a problem with the base image? Or your Comfy because i dont have any of this error on mine.
is there a way to set clipSkip ?