New feature: seamless looping
ComfyUI Frontend Compatibility Notice
Affected versions: ComfyUI_frontend 1.40.x – 1.42.9 (known good: <= 1.39.19 or >= 1.42.10)
Recent ComfyUI frontend updates have introduced significant issues with subgraph functionality that affect this workflow.
If you are affected, this message appears in your ComfyUI console right after you start a workflow run:
Failed to validate prompt for output 499:
* ColorMatch 587:586:
- Required input is missing: image_target
* Basic data handling: IfElse 598:
- Required input is missing: if_falseThe workflow may appear to run correctly, but only parts of it will actually produce output. It won't finish with a properly joined video.
If you see this warning and the workflow isn't running as expected, downgrade your ComfyUI frontend to 1.39.19 or upgrade to 1.42.10, and reload a fresh copy of the workflow.
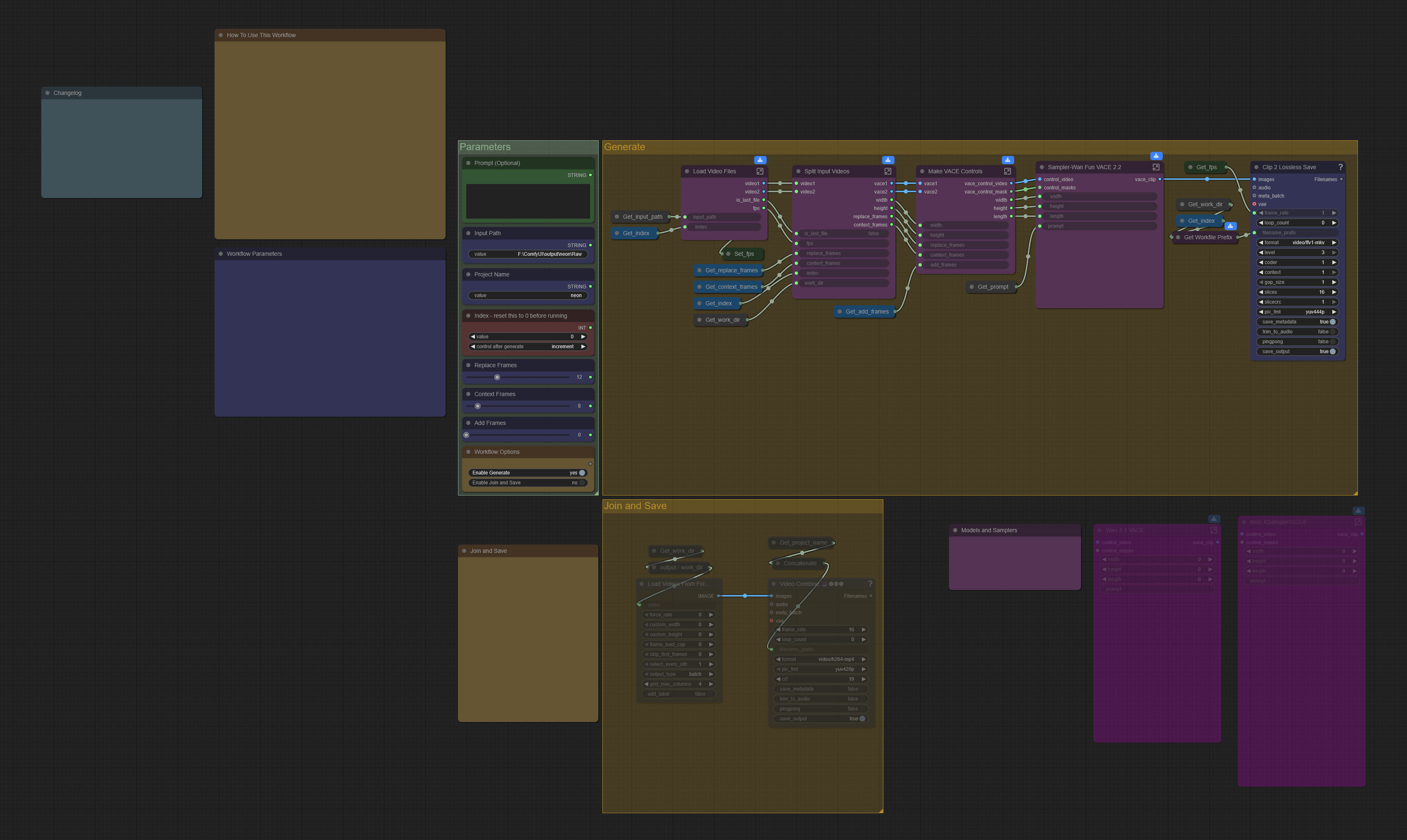
What it Does
Point this workflow at a directory of clips and it will automatically stitch them together. It's designed to work well with a few clips or dozens. At each transition, Wan VACE generates new frames guided by context on both sides, replacing the seam with motion that flows naturally between the clips. Noisy or artifacted frames at clip boundaries get replaced in the same pass. How many context frames and generated frames are used is configurable.
The workflow runs with either Wan 2.1 VACE or Wan 2.2 Fun VACE. Input clips can come from anywhere - Wan, LTX-2, phone footage, stock video, whatever you have.
If you want the result to loop cleanly, there's a toggle for that.
Usage
Put your input clips in their own directory, named so they sort in the order you want them joined.
Configure the workflow parameters. The notes in the workflow have full details on each one.
Set the index to 0.
Queue the workflow. You need to queue it once per transition. That's N-1 times for N clips, or N times if looping is enabled.
Setup
This is not a ready to run workflow. You need to configure it to fit your system.
What runs well on my system will not necessarily run well on yours. Configure this workflow to use a VACE model of the same type that you use in your standard Wan workflow. Detailed configuration and usage instructions can be found in the workflow. Please read carefully.
Dependencies
I've used native nodes and tried to keep the custom node dependencies to a minimum. The following packages are required. All of them are installable through the Manager.
ComfyUI-Wan-VACE-Prep v1.0.12 or higher
Note: I have not tested this workflow under the new Nodes 2.0 UI.
Configuration and Models
You'll need some combination of these models to run the workflow. As already mentioned, this workflow will not run properly on your system until you configure it properly. You probably already have a Wan video generation workflow that runs well on your system. You need to configure this workflow similarly to your generation workflow.
Wan 2.2 Fun VACE
Wan 2.1 VACE
Kijai’s extracted Fun Vace 2.2 modules, for loading along with standard T2V models. Native use examples here.
The Sampler subgraph contains KSampler nodes and model loading nodes. Inference is isolated in subgraphs, so it should be easy to modify this workflow for your preferred setup. Replace the provided sampler subgraph with one that implements your setup, then plug it into the workflow. Have your way with these until it feels right to you.
Just make sure all the subgraph inputs and outputs are correctly getting and setting data, and crucially, that the diffusion model you load is one of Wan2.2 Fun VACE or Wan2.1 VACE. GGUFs work fine, but non-VACE models do not. An example alternate sampler subgraph for VACE 2.1 is included.
Enable sageattention and torch compile if you know your system supports them.
Troubleshooting
The size of tensor a must match the size of tensor b at non-singleton dimension 1 - Check that both dimensions of your input videos are divisible by 16 and change this if they're not. Fun fact: 1080 is not divisible by 16!
Brightness/color shift - VACE can sometimes affect the brightness or saturation of the clips it generates. I don't know how to avoid this tendency, I think it's baked into the model, unfortunately. Disabling lightx2v speed loras can help, as can making sure you use the exact same lora(s) and strength in this workflow that you used when generating your clips. Some people have reported success using a color match node before output of the clips in this workflow. I think specific solutions vary by case, though. The most consistent mitigation I have found is to interpolate framerate up to 30 or 60 fps after using this workflow. The interpolation decreases how perceptible the color shift is. The shift is still there, but it's spread out over 60 frames instead over 16, so it doesn't look like a sudden change to our eyes any more.
Regarding Framerate - The Wan models are trained at 16 fps, so if your input videos are at some higher rate, you may get sub-optimal results. At the very least, you'll need to increase the number of context and replace frames by whatever factor your framerate is greater than 16 fps in order to achieve the same effect with VACE. I suggest forcing your inputs down to 16 fps for processing with this workflow, then re-interpolating back up to your desired framerate.
IndexError: list index out of range - Your input video may be too small for the parameters you have specified. The minimum size for a video will be
(context_frames + replace_frames) * 2 + 1. Confirm that all of your input videos have at least this minimum number of frames.If you can't make the workflow work, update ComfyUI and try again. If you're not willing to update ComfyUI, I can't help you. We have to be working from the same starting point.
Feel free to open an issue on github. This is the most direct way to engage me. If you want a head start, paste your complete console log from a failed run into your issue.
Changelog
v2.5
Seamless Loops - Enable the
Make Looptoggle and the workflow will generate a smooth transition between your final input video and the first one, allowing the video to be played on a loop.Much lower RAM usage during final assembly - Enabled by default, VideoHelperSuite's Meta Batch Manager drastically reduces the amount of system RAM consumed while concatenating frames. If you were running out of RAM on the final step because you were joining hundreds or thousands of frames, that shouldn't be a problem any more. Additional details in the workflow notes.
v2.4 Minor tweaks. Adjust sage attention, torch compile defaults.
v2.3 This release prioritizes workflow reliability and maintainability. Core functionality remains unchanged. These changes reduce surface area for failures and improve debuggability. Stability and deterministic operation take priority over convenience features.
Looping workflow discontinued – While still functional, the loop-based approach obscured workflow status and complicated targeted reruns for specific transitions. The batch workflow provides better visibility and control.
Reverted to lossless fv1 intermediate files – The 16-bit PNG experiment provided no practical benefit and made addressing individual joins more cumbersome. Returning to the proven method.
New custom nodes for cleaner workflows – WAN VACE Prep Batch and VACE Batch Context encapsulate operations that are awkward to express in visual nodes but straightforward in Python. Load Videos From Folder (simple) replaces the KJNodes equivalent to eliminate problematic VideoHelperSuite dependencies that fail in some environments.
Enhanced console logging – Additional diagnostic output when
Debug=Trueto aid troubleshooting.Fewer custom node dependencies
The Lightweight Workflow has moved to its own page. Check it out if you just need to quickly join two clips without the overhead required by the full workflow.
v2.2 Complexity Reduction Release
Removed fancy model loader which was causing headaches for safetensors users without any gguf models installed, and vice-versa.
Removed the MOE KSampler and TripleKSampler subgraphs. You can still use these samplers, but it's up to you to bring them and set them up.
Custom node dependencies reduced.
Un-subgraphed some functions. Sadly, this powerful and useful feature is still too unstable to distribute to users on varying versions of ComfyUI.
Updated documentation.
v2.1
Add Prune Outputs to Video Combine nodes, preventing extra frames from being added to the output
v2.0 - Workflow redesign. Core functionality is the same, but hopefully usability is improved
(Experimental) New looping workflow variant that doesn't require manual queueing and index manipulation. I am not entirely comfortable with this version and consider it experimental. The ComfyUI-Easy-Use For Loop implementation is janky and requires some extra, otherwise useless code to make it work. But it lets you run with one click! Use with caution. All VACE join features are identical between the workflows. Looping is the only difference.
(Experimental) Added cross fade at VACE boundaries to mitigate brightness/color shift
(Experimental) Added color match for VACE frames to mitigate brightness/color shift
Save intermediate work as 16 bit png instead of ffv1 to mitigate brightness/color shift
Integrated video join into the main workflow. It will run automatically after the last iteration. No more need to run the join part separately.
More documentation
Inputs and outputs are logged to the console for better progress tracking
v1.2 - Minor Update 2025-Oct-13
Sort the input directory list.
v1.1 - Minor Update 2025-Oct-11
Preserve input framerate in workflow VACE outputs. Previously, all output was forced to 16fps. Note, you must manually set the framerate in the Join & Save output.
Changed default model/sampler to Wan 2.2 Fun VACE fp8/KSampler. GGUF, MoE, 2.1 are still available in the bypassed subgraphs.
Description
v1.2:
sort the input directory list
FAQ
Comments (71)
OK, I only used the VACE wan2.1 but it gives really nice results with the defualt settings and also, kudos for the amazing modularity in this wf, will definately try it out with the vace2.2 as well
I'm glad to hear it works well for you. And thanks for the kudos. :)
When I've compared 2.1 results against 2.2, I haven't been able to see any significant differences. I'd be interested to hear if your experience is different.
Wan 2.2 Fun VACE seems pretty good at frame interpolation. It seems not so good at other VACE tasks like video-to-video stuff.
why are your updates dated in 2026 ? we are in 2025
Nice WF. Everything go fine until ksamler. i bypasseg sage node but i always have this error : free_upper_bound + pytorch_used_bytes[device] <= device_total INTERNAL ASSERT FAILED at "C:\\actions-runner\\_work\\pytorch\\pytorch\\pytorch\\c10\\cuda\\CUDAMallocAsyncAllocator.cpp":563, please report a bug to PyTorch.
This means you're running out of VRAM. If you're not already, try a low-quant GGUF model like Q4. If that works, try higher quantizations until you find the highest level your system can handle.
@__Bob__ is it possible to use block swap for this workflow? If it's possible can you help me how to add it into the workflow?
@axymhd I think block swap is a technique used in WanVideoWrapper, yes? If so, it's not compatible with this workflow because this workflow uses native, not wrapper, nodes.
You may want to try the ComfyUI-MultiGPU loader nodes instead. Despite the name, these nodes work with a single GPU as well, and they allow you to specify an amount of system RAM to supplement your VRAM for model storage.
Hi, really looking forward to trying this. But I attempted to drag the 1.2 workflow into Comfy, and immediately got an error which prevents the workflow from showing at all. Can you confirm you uploaded the intended file?
ComfyUI Error Report
## Error Details
- Node ID: N/A
- Node Type: N/A
- Exception Type: Loading aborted due to error reloading workflow data
- Exception Message: TypeError: Cannot set properties of undefined (setting 'value')
## Stack Trace
```
TypeError: Cannot set properties of undefined (setting 'value')
at http://127.0.0.1:8188/assets/index-DJ5igR8b.js:403624:49
at Array.forEach (<anonymous>)
at ComfyNode.onConfigure (http://127.0.0.1:8188/assets/index-DJ5igR8b.js:403623:34)
at ComfyNode.configure (http://127.0.0.1:8188/assets/index-DJ5igR8b.js:123971:23)
at ComfyNode.configure (http://127.0.0.1:8188/assets/index-DJ5igR8b.js:128556:11)
at ComfyNode.configure (http://127.0.0.1:8188/assets/index-DJ5igR8b.js:402862:15)
at Subgraph.configure (http://127.0.0.1:8188/assets/index-DJ5igR8b.js:136633:34)
at LGraph.configure (http://127.0.0.1:8188/assets/index-DJ5igR8b.js:407231:26)
at LGraph.configure (http://127.0.0.1:8188/extensions/comfyui-custom-scripts/js/reroutePrimitive.js:14:29)
at Subgraph.configure (http://127.0.0.1:8188/assets/index-DJ5igR8b.js:136776:22)
```
I just downloaded the 1.2 archive from Civitai and dragged it into ComfyUI on two different systems, a PC and a Mac. It loaded fine on both.
If you haven't already, maybe try updating ComfyUI? I'm running these versions:
- ComfyUI 0.3.64
- ComfyUI_frontend v1.27.10
- ComfyUI-Manager V3.37
@__Bob__ Thanks for trying that out. Hrm. I am on latest comfy everything, same exact version as you. Not sure what's going on.
@EnragedAntelope Subgraphs are still buggy as hell, that's what is going on. I'm sorry I'm not more help.
Found mention of this exact issue here, which indicates I need latest front end. Which I had... but then I tried loading in Edge browser instead of Brave, and it loaded. Very bizarre as I've used Brave for like a year with Comfy. But I think I'm on my way now, thank you again for trying to troubleshoot.
https://github.com/comfyanonymous/ComfyUI/issues/10299
Great workflow.
Modified it a little bit:
1. Had to delete the 2 "TorchCompileModelWanVideoV2" Nodes, they gave me an error, my model is not compatible or something like that.
2. Added an Image Loader Node
3. Added some Color Match Nodes in front of each "Clip Save" (Inside "Split Input Videos" and "Make VACE Controls").
What does it do:
In this Video (Sleeping Dragon) you can see a color shift between the transitions, it gets lighter then darker again, that was before i modified the workflow, now this colorshift no longer exists.
This is the Image with the Workflow embedded.
Thanks. VACE is known to sometimes slightly alter the brightness or saturation of the clips it generates. It was a problem in 2.1 also. I'm glad you found an easy solution for your video! It can be worse when there is more motion.
Color matching doesn't always work across the entire video clip. I've found that interpolating to a higher framerate can reduce the perceptibility of the shift. Also, ensuring the same loras are used for VACE as were used for the clip generations helps.
@__Bob__ I did some quick tests and I feel like a good solution is to color match in multiple steps of decreasing/increasing strength.
First color match the first 9 images of the "middle" clip with the last image if the first clip, starting at strength 1.00 then decreasing by 0.1 each time. Then you color match the last 9 images of that middle clip with the first image of the following clip, starting at strength 0.1 with an 0.1 increase getting you at 1.00 for the last image.
With that even before any interpolation my few tests were already pretty much perfect.
Thought to be fair I only tried with 4 replace frames, 8 context frames, 16 add frames. Would probably need a more flexible solution to work with any lenght of frames (?).
Loving the workflow btw.
@kinai_ This is interesting! I wonder if the amount of color variance is constant for different videos, or if a different match strength might be required depending on the input. I am sad that I won't have time for at least two weeks to look into this myself, but if there's a possible solution or solid mitigation, it's a high priority for me.
What color match method did you use?
Thanks for mentioning this!
@__Bob__ I only tested a simple KJnode color match ( uOc2ZPc.png).
{kind=link}
I do have ( mostly vibe coded ) custom color match nodes, based on 3-point curve color match tutorial I previously followed for photoshop (HStBA4f.png ). But I don't think it would be that useful here, since it's mostly a manual thing where you want to color pick 3 point for both the source and target.
{kind=link}
Ideally rather than a fixed number of frame, we'd need (a custom node?) where we would color match from strart to end the middle clip, where the middle point of the clip average the LUT based on the last frame of the previous clip, and the first frame of the next Clip. So rather than play with the strength of the color match, we'd play with how much of the color of the last/first frame impact the color of each frame. On a 10 frame clip, that would go 100%/0%, 90%/10%, [...], 0%/100%. And a slower/faster transition of that proportion based on the number of frames.
I might give it a try, even if I have no idea if it would work. ^^" Or who know maybe something like that already exist and I just don't know about it.
Thank you so much. You are God!
Great workflow, clean and clear. Thus I have some issues with the binder part (join & save) that got a
```module 'D:\...\ComfyUI\custom_nodes\comfyui-videohelpersuite' has no attribute 'load_video_nodes'````
Sorry you're having trouble. Check that your KJNodes and VideoHelperSuite packages are up to date. I have KJNodes 1.1.7, and VHS 1.7.7.
@__Bob__ Yep I have the same version too. I did update KJN directly from git so it's the latest update. Still got the issue.
@feloxxx75 Well dang. There is something weird and inconsistent about the way custom nodes are loaded in ComfyUI. I encountered a similar problem with the LoadVideosFromFolder node recently and traced the problem to the fact that sometimes modules are loaded with a simple name, like "comfyui-videohelpersuite", and sometimes they're loaded with a full pathname, like "F:\ComfyUI\custom_nodes\ComfyUI-VideoHelperSuite.videohelpersuite". The latter case was preventing the node from functioning for me. Although my python is not strong, with help from Claude.ai I vibe coded a small patch (https://github.com/kijai/ComfyUI-KJNodes/pull/397) that worked around my specific problem. Kijai accepted the patch, so now my particular problem is solved in the current KJNodes releases.
But none of this rambling helps you with your problem. I bring it up because the error you cite feels adjacent to the problem I was encountering. I could be wrong, by maybe there's a similarly easy solution that you could find, with help from an LLM if necessary.
Alternatively, you could just use your favorite video editor to join the vace-work clips together. Nothing fancy happens there, it's just concatenating the clips in order. I use Final Cut Pro on my Mac for this, but I'm sure it's just as easy with DaVinci Resolve, Adobe Premeire, or some other tool I haven't heard of.
Sorry I can't offer a more direct solution! The Join & Save part of this workflow was kind of an afterthought. I'll think about replacing it with something more robust.
@feloxxx75 Hey, I noticed that there's a recent bug report(https://github.com/kijai/ComfyUI-KJNodes/issues/399) in the KJNodes repository that appears to be the same as your issue. Or maybe that's your bug report! In which case, I don't need to be telling you any of this.
Last week someone opened a pr (https://github.com/kijai/ComfyUI-KJNodes/pull/428) that purports to solve this issue. It's not approved yet, but if you're so inclined you could apply it manually and see if it solves your problem, or watch the pr until it's approved, then update your KJNodes package.
The results I get are not even using a single frame from the two videos I give it, entirely unrelated. Took me around half an hour to finish the entire gen, on a 5090(192gb ram), too.
All models are loaded and I've given it the same prompt that I used for the original gens, rest on default settings.
Would love to make this work.
Can you say what model is being loaded? After one run, what does the Make VACE Controls->Control Video Preview node look like?
Using the q8 version of wan 2.2 fun. The previews show frames from the two clips and the inbetween masking frames are all black.
@RavagedCherry
I'm sure you have already done this, but please check the model loader nodes and confirm you are loading the Wan Fun VACE models and not Wan Fun InP or something else by accident.
The in-between frames are black? Not gray in the Control Video Preview and white in the Control Mask Preview? The previews should look like this: https://imgur.com/a/xhiRcRO
If they are black and not gray and white, what values are in the "generate gray frames" and SolidMask nodes? https://imgur.com/a/029eg10
@__Bob__ I did indeed pick the wrong model, lol. Been so used to the wan video model loader, which loads standard as well as gguf models, so I picked the inpaint fun model..
It's working fine now, thank you for the workflow, it's great 👌
Extremely useful tool. Thank you!
Is there anyway to only use 1 clip and create a more seamless loop instead?
This workflow is for creating a transition between two or more clips. Creating a loop isn't the focus here.
I am sure there are workflows for creating seamless loops, but I have not used them.
@__Bob__ Yeah I've been using it for just that and it works great, think you can apply the same logic for seamless looping, replacing x frames from the start and end of a single clip. I just can't figure it out
@__Bob__ Update! I found a workflow that gave me a perfect seamless loop, I was very surprised by the lack of quality change/contrast shift. I converted the workflow to vace 2.2 and noticed some nodes near the output that are cross fading with the original content, I suspect this is how this is achieved. I'm not 100% sure but maybe you could apply this to the frames that are replaced? https://pastebin.com/8swekzm7 Heres the workflow if you have the spare time to try this node on your workflow it could be really cool, I'm not competent enough to transfer it over sadly.
this is exactly what i was looking for, thank you so much!
sadly, i too am having trouble with the kj node in "join and save". it is not recognizing the VHS. since the input clips are trimmed and saved in order with the stich clips (index000_input_trimmed, index000_stich, index001_trimmed, index001_stitch etc.) then we can just drop that whole folder in our video editor without having to find the exact transition frames. i do wish my version of premier accepted mkv
Sorry about the mkv format. It's the only wrapper format available for the lossless ffv1 codec. If I didn't use that, saving the work files would degrade your input video.
It's too bad that the VHS import is so problematic! I wish there was some alternative to KJNodes' LoadVideosFromFolder node, but I haven't found one, and so far I've been too lazy to come up with my own solution.
Good news, though: Last week, someone submitted a pr to improve VHS module loading in this node. (https://github.com/kijai/ComfyUI-KJNodes/pull/428) It hasn't been approved yet, but any interested parties could apply this manually and hopefully begin joining trouble free!
It looks like it works until creating the masks, but it never generates the clips in between.
Somehow all I get out is the original input videos again and not an interpolation.
Could you check if there is something broken in your flow? Would be much appreciated!
To recreate:
Created folder with video1 - video4.
Ran workflow
Second workflow join together and save, also has a problem, it cant find "output/neon/vace-work/" folder even though it is in the comfyui folder created by the other flow correctly
Hi, please try this:
- restart ComfyUI
- delete (or rename) any existing vace-work directory in your output/project_name directory.
- set index to 0 in the workflow
- set replace_frames, context_frames and add_frames to sane values like 8, 8 and 0.
- Enable Generate=yes, Enable Join & Save=no
- Queue the workflow to run once
If the workflow fails to run, please show me what error messages you see, and the output in your console.
If the workflow completes, tell me what files you see in your vace-work directory. There should be two, named index00_clip1_00001.mkv and index00_clip2_00001.mkv. clip1 will be the first part of your first video. clip2 will be a small last part of your first video, plus generated frames, plus a small first part of your second video.
Ignore the Join workflow for the time being.
@__Bob__ Thank you! i ran out of memory at the moment even with 24GB, but at least I can confirm it works properly. I was just stupid and used Vace and not Vace Fun model
@metaigirls If you have a Wan setup that works for your system, try to match that in this workflow and you should avoid memory issues.
Ksampler error: mat1 and mat2 shapes cannot be multiplied (77x768 and 4096x5120) - my input videos are 512x384
Hi, please double check that you are loading the correct models.
If your Load CLIP node has a "type" selector on it, please ensure it is set to "wan".
@__Bob__ yep it is, I'll try digging into it more later
Looks like this is caused by using a bf16 tokenizer (CLIP), even though my other models are bf16 also I have to use an fp8 CLIP model.
@frosty639 Were you accidentally loading a CLIP model meant for use in a WanVideoWrapper workflow? I do that sometimes. The wrapper models are named with enc in the name, like umt5_xxl_enc_bf16.safetensors instead of just umt5_xxl_bf16.safetensors. Easy to overlook that in a long list of similarly-named models.
Hi! Great workflow! It was working nice for me, but today I get an error message saying:
KSamplerAdvanced
The size of tensor a (11439) must match the size of tensor b (11718) at non-singleton dimension 1
I cheked my videos - the resolution is the same and picked correctly in Get Image Size & Count node.
I tried to change models, VAE and etc, nothing helps
Hi,
- are both dimensions of your videos divisible by 16?
- are the frame count parameters (context, replace, add) all divisible by 4? The workflow controls enforce this, so they should be, but double check that you haven't manually set something.
- please double check that you are loading the correct models (Wan Fun VACE, not Wan Fun InP or something else).
- Please confirm your CLIP loader node has "type" set to "wan", and that you're loading a native-compatible text encoder model (umt5_xxl_fp5 or fp8, not umt5_xxl_enc or t5xxl or something else)
If all else fails, try starting over from scratch. Download a fresh copy of the workflow and begin again. Something must have changed--you bumped a parameter somewhere or your input data is off in a way you haven't noticed yet. If you can't pinpoint what went wrong, methodically starting over is probably your best option.
Good luck!
@__Bob__ Hi! Thanks for the reply. Loading the previously generated .mkv file into Comfy still causes the same error. I’ll test it with GGUF models and see if that fixes it.
@troubletro777855 Just ran into this error today, and it was due to one of my video dimensions not being a multiple of 16. Cropped it slightly so it was divisible by 16 and then it worked just fine.
@carte247 yeah! Figured it out too.. we need to be carefull :)
It looks incredible. I'm one of the many for whom it didn't work following the instructions. I'm using Comfyui portable Ram: 64GB Video: 16GB 4080. You need to make a YouTube video. I think it will take you less than an hour to create it since you designed the workflow.
Hi. The most important thing is to configure this workflow the same way your regular Wan video generation workflow is configured. For example, if you normally run Wan 2.2 Q4 GGUF, then you should set up this workflow to run with Wan Fun VACE Q4 GGUF. If your system isn't set up to use sage attention or torch compile, disable the sage attention and torch compile nodes in this workflow.
What works on my system probably won't work on your system, so it is crucial that you configure it properly for your system. That part is up to you.
@__Bob__ Excellent response, I will look into it more carefully and calmly. You give me hope that I can get it to work on my PC.
@dg3duy377 Good luck! I don't mean to put anyone off. I am happy to help when I can, but you know your system better than I do. :)
I have the same setup and was getting an OOM error just after loading the wan models. After many hairs being pulled out I discovered If I replace the load model nodes it works beautifully. I don't know what is the problem or is it only a problem on my end, but after deleting and putting again the Load Diffusion model nodes it's working!
@spellweaverbg Hi, can you say more about this? Was this problem and fix using the new v2.0 workflow? And did you replace the entire Load subgraph, or just the load model nodes inside it?
@__Bob__ Hello, sorry for the late reply. First let me thank you for the amazing workflow, when I finally managed to make it work on my PC it works flawlessly. I was using the v1.2 version of your workflow and I kept getting OOM errors even if my VACE models were fp8 and they are usually fine on my 16GB VRAM card with offloading. Even 640x480 videos would not load without OOM. Then I deleted your Load Diffusion model nodes from the Models subgraph and replaced them with the same nodes just taken from my Comfyui. It is very strange because I do not use custom node to load it, just native Comfyui. Nevertheless, the problem was fixed just with replacing the model loader nodes which loaded my fp8 files. Really strange.
Also I love your v2.1 workflow, but I hit a snag in it as well. It turned out it kept looking for GGUF models even though I disabled the toggle, but the workflow would just interrupt with error in the console about the missing GGUFs. So I entered the subgraph and deleted everything that was connected to the GGUF and bam! - problem solved, it works beautifuly.
Again, I want to reiterate how grateful I am for your work and wrote this essay just to make sure you have enough info to work with in the next versions. So - thanks again and I'm looking forward to more joiner workflows xD
@spellweaverbg Thanks for sharing that information. Knowing the problems people encounter helps me improve the workflow. I’m glad you find it useful!
how heavy this workflow is?
i'm using comfy on vast ai.
i had bunch of problem to make the workflow work but i finally did for 3 continuous video.
then i tried 8 video, i put it set that path and set the output.
i never changed the fps forced to 16( i only did one test) if i want to which node i should set? first and second video loader in first subgraph?
i used fp8 and q8 but still doesn't work and i went out of vram for my 8 video (set index to 7)
i just wanted to know this is normal or am i doing something wrong?
and also i really cant use save and join because of a error( icant gave it to u right know but it's same problem as in other comments seems like doesn't find it's path)
is there a way to not save my videos by mkv? i have to convet them since i cant import them in priemer.
and is this okay to use other video ai gen? because i'm using my kling's videos
thanks for amazing workflow
Hi mahmadzade7777777758. Properly configured, this workflow shouldn't put any more strain on your system than your regular Wan workflow does. The key is to make sure you set it up the same way as your Wan workflow. If you normally load fp8 models in your Wan workflow, use the Wan Fun VACE fp8 models here, etc.
The same rules that apply for Wan video generation apply here: VRAM usage grows with video resolution and number of frames. In this workflow, VACE will generate (replace_frames * 2) + (context_frames * 2) + add_frames +1 frames per run. Usually this number should be well under the 81 frames that is the optimal upper limit for Wan generation. If these parameters are too high, or your input resoutions are too big, you may run into memory issues.
I suggest reducing your framerate to 16 fps outside of this workflow. Setting the "force_rate"=16 on the "Load First Video" and "Load Second Video" nodes should work in this workflow, but it's untested. Better to set up a simple Load Video -> Video Combine workflow to convert your framerates first.
Save and Join doesn't seem to work for everybody due to weirdness in the Load Videos From Folder node. It imports code from VideoHelperSuite, and that is apparently imperfect. See other comments here for more details. I'm sorry for this. I hope to offer a better solution soon. But for now, using any other video editor is the best option.
Output video clips use the lossless ffv1 codec, and mkv is the only container format that supports it. Unfortunately, saving to another format will degrade your videos slightly. If you don't care about this, you can find the three "Clip x Lossless Save" nodes and choose a different output format.
This workflow doesn't care where the input videos came from, as long as their dimensions are divisible by 16.
Good luck.
@__Bob__ thanks for response i run it and get some result but it seems mine wasn't smooth enough i should work better better with context frame and replace frame and play with them (first run was 12 and 8)
one more question , i should put all file i get in the output folder together in editing software or just those which are non false?
@mahmadzade7777777758 I am not sure what you mean by "non-false". If you are going to join the output files in a video editor, you should take all the files from your vace-work directory and join them in sorted order.
Hi !
If i have 10 videos and wanted to splice all, can i just use this workflow to join 2 video by 2 video ? or i need to put all video once ?
Ex:
- 2 video = 1 generation video
- Take last 5s (i guess) of first generated video to splice with third part
- Take 5s of second generated video to build the fourth part ?
Or do i need to put all part once and generate 1 video with all part ?
Hi @xpz971 ,
This is how the workflow works:
- You queue the workflow once for each pair of videos you want to splice.
- Each run creates one generated video, saved as separate parts in a work directory.
- After all desired generations are complete, you run the Join part of the workflow, which splices all of the parts found in the work directory.
Your suggested approach (if I understand correctly), to join A+B, then AB+C, then ABC+D, etc, would work for awhile, but the joined ABCD video might eventually become so large that there isn't enough system RAM for the workflow to run. Better to generate transitions for the small clips and then join them at the end.
@__Bob__ Re, just a quick question regarding the replace frame and context frame functions: how do I use them? How does this part work? I think it's a big area of confusion for me. Thanks in advance.
@xpz971 Context and replace frames are the frames at the end of video1 and the start of video2, which this workflow uses to generate the smooth transition.
Replace frames are the very last frames of video1 and the very first frames of video2 that will be replaced with new frames. So this parameter specifies how many frames should be replaced on each side. replace_frames=8 means the last 8 frames of video1 and the first 8 frames of video2 will be regenerated.
Context frames are frames from your videos that the model uses to generate the replace frames. These are frames just before and just after the replace frames. If you're familiar with first-last frame generation, it's kind of like that, only more sophisticated. Context frames tell VACE how the motion in the frames it generates should start and end, so it can smartly generate the motion in between.
I hope that helps.
Hopefully you're still checking for questions on this workflow. First off, thank you so much for taking the time to put this together. The workflow shows that you have really good knowledge of Comfy.
I am able to run Wan 2.2 using Native nodes on my 12GB card (64GB RAM) without any issues, but this workflow gives me OOM when I use Wan 2.2 Fun and it takes forever and a day when I use Wan 2.1 Vace—not really sure you have any suggestions for that, but it's whatever.
I was able to eventually get it to complete successfully for my three-clip test, but the two "false" clips it made were entirely unrelated to my videos. One was a clip of a red panda in a tree and another was just a woman standing outside. My videos were of a snowy cabin scene at Christmas. LOL. So, I'm guessing that the "Prompt" node isn't REALLY optional? What am I supposed to put there? Since I have three separate clips that I'm splicing together, which clip prompt should go there?
Prompt is totally optional. I'm not sure I've ever used a prompt in this workflow. VACE relies on motion cues in the context frames much more than on the prompt. You can still use prompt here, but it is definitely not required.
If you are getting output that has nothing to do with your inputs, the most likely explanation is that you are accidentally using the wrong models. Please double check that you are loading Wan Fun VACE and not Wan Fun InP or something else by mistake.
As for OOM issues, try to use the same size models as you use for normal Wan generation. If you run Wan I2V with fp8 models, use the VACE fp8 models here. Beyond that, the same rules apply: resolution and frames drive VRAM requirements. With reasonable parameters (config:8, replace: 16, add:0) this workflow should require less VRAM than a normal 81 frame Wan generation.
I believe your naming of output files is flawed somehow in the latest workflow. I tried to follow the workflow to find the mistake, but it's a bit over my head.
I found the following when running the wf for a three clip video I was putting together. The first output videos are correctly named index000_clipfalse_00001.mkv and index000_clip1_00001.mkv.
The second set of output videos has a problem. I get index001_clipfalse_00001.mkv—which I believe to be correct—and index001_clip1_00001.mkv—which I believe to be INCORRECT. I think that second file SHOULD be named index001_clip2_00001.mkv.
The third set of output videos also has a problem. I get index001_clip3_00001.mkv which I believe SHOULD be index002_clip3_00001.mkv.
With these names being incorrect, using your video splicing workflow generates a final video that is out of order.
Let me know if you see this same issue in your testing.
Thank you for this great workflow.
index001_clipfalse_00001.mkv indicates something's not right. false should always be a number 1, 2, or 3, depending on the source of the clip.
The clip names are generated by a subgraph named Get Workfile Prefix. There are three of these, each feeding one of the Clipx Lossless Save nodes. The clip_id parameter on the node is where the 1,2 or 3 (or in your case, 'false') value comes from.
The ComfyUI subgraph implementation still being a buggy mess, I suspect an input value has somehow gone wrong in one of these. Maybe you're running a slightly older frontend than me or something. Try uncollapsing each of these Get Workfile Prefix nodes and see if you can spot one without a valid clip_id value. Each one should match the Video Combine node it's connected to.