東北ずん子プロジェクトより ずんだの妖精 ずんだもん です。
素材はすべて生成AIによる30枚の画像です。
Qwen-Imageは解像度1024で学習する場合、Vram24Gbに収まらないためブロックスワップを使わないといけなくなり、そのため非常に学習時間がかかってしまいました。
そこで解像度512ではどうかと思いテストをするためにデータセットを作りました。
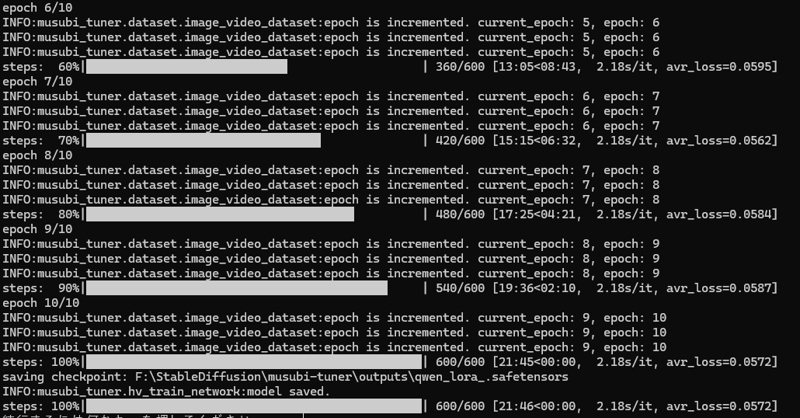
Vram22Gbで収まりブロックスワップを使わないため素早く学習できます。
600ステップを21分程度で完了でき、まぁまぁな出来になってるのではないかと思います。
test03 配布データセットはキャプションのみ(画像はtest01と同じです)
キャプションを普段制作しているダンボールタグ由来のいわゆる部族語に変更して学習。
これでも zundamon ではもちろん出ない。
トリガーワードとして置いた zundamon もほぼ機能していないです。
XLモデル同様特徴をつらつらと書きだせば出てくるのですが理想はそうじゃないんですよね…。
次はトリガーワードを zundamon にして特徴を全消ししての学習を試します。
test02 配布データセットはキャプションのみ(画像はtest01と同じです)
キャプションを改善できないかと思いとりあえず全キャプションを zundamon のみで学習。
すると主語がだれであったとしてもずんだもんが生成できるものが出来上がった。
zundamon というワードを使わなくても出てくる。
ただしおじさんが~とかにすると出てこないときも。
要するに大失敗である。
test01 配布データセットは画像+キャプション
キャプションはFlorence2を使った自然言語でつけています。
トリガーワードに指定したものはあまり意味が無いというのは少し前のテストでわかっていたので 彼女の名前はずんだもん(Her name is Zundamon) というものを最初に持ってきました。
結果として、これでも ずんだもん(zundamon) というワードでは出てきませんでした。
初音ミクが走っている と入れれば出てくるぐらいになるにはどうすればいいのか、というテストを今後していきたいと思っています。
と言ってもおそらくQwen-Imageは主流になるとは思いませんので今後の次期モデルにも応用できそうな知見を発見できたらと考えています。