






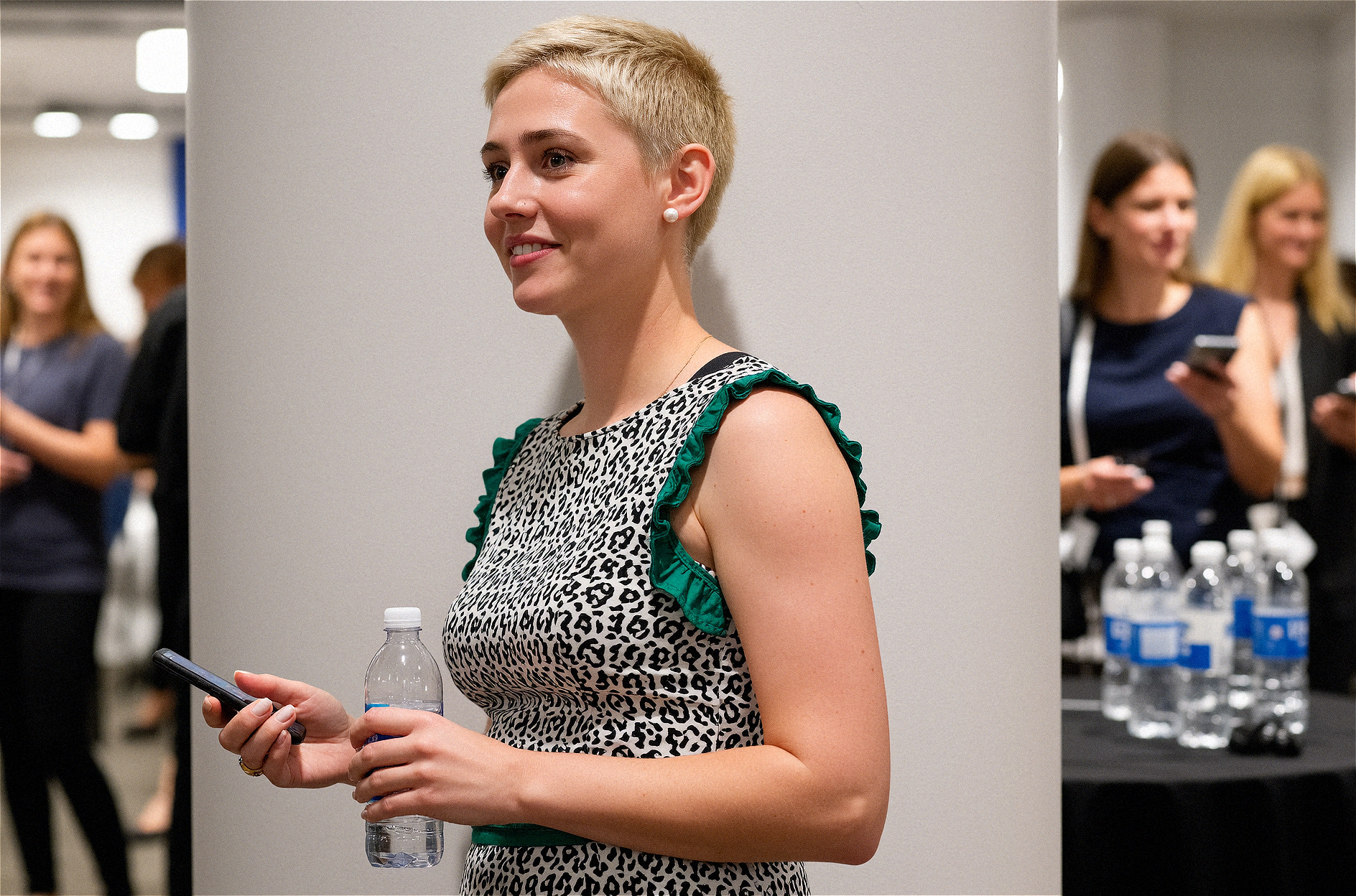
V1: Civitai is not showing metadata. Please download any image and drag and drop it in Comfyui to get the full workflow
Before I dive in—Wan 2.2 is insane. Training this LoRA was such a blast. Unlike the usual amateur LoRAs I’ve made for Flux Dev, this one was trained on high-quality photos. No point in hiding imperfections when Wan 2.2 handles training so well—it spits out pure gold and works beautifully with character LoRAs.
For best results, use both the high model and the low model together. On my RTX 4060 Ti with 16GB VRAM, generation takes about 4 minutes. Stick to 1888x1248 resolution. If you flip it to 1248x1888, expect body horror nightmares.
This is just the first version, and there’s definitely room for improvement. A few issues I noticed during testing:
The text generation may be pretty rough (I might’ve butchered it).
Hands can get weird, especially with complex poses.
Prompt adherence can be a little shaky, but if you phrase things the way it “likes,” it works surprisingly well.
Feel free to drop comments if you notice other issues—I’ll try to address them in the next update. All the images that I am showcasing have workflow included.
I’m not using the Civitai LoRA trainer anymore, so please don’t send buzz. Use it for yourself. :)
If you’d like to support my work and help fund future releases, feel free to contact me directly.
Enjoy generating!
Description
HIGH NOISE V1
FAQ
Comments (17)
Can we get some prompt examples?
Hi, you can drag and drop any image in comfyui. All images have metadata included, not sure why civitai doesn't show it.
@peterkickasspeter Thank you. Have you noticed significant improvements from having separate prompts for the high and low noise models, compared to having a combined prompt for both.
@BinaryBottleBake Nothing major to be honest (just a tiny bit quality improvement). Some of the images, i sent empty positive prompt to low noise model because I forgot to connect the right node 😂 but it works just fine. You can remove it and test with your prompts
Is possible to use wan 2.2 loras with Wan 2.1?
I don't know 😆 sorry
100%.. but low noise only. thats all thats needed.
Wow! This work looks FANTASTIC! Just looking at the example images, this Lora takes Wan 2.2's realism to a NEXT LEVEL! Is that right? Is there a specific keyword/prompt, or is it unnecessary? Was it trained solely with images, or did you use videos as well? If not, do you think it would be feasible to add high-quality videos of various everyday situations to the next version? I think it would take this model to an even higher level of excellence!
Hello, no need for any trigger words. I only trained using images. Videos I have no idea sorry
Does it only work for T2V?
T2V models will have some effect on I2V workflows, just not as much as intended without the specific training. I think in the actual Civitai generator, yeah, but on a different runner you could use this in an I2V or T2V or whatever workflow
Quickly tested at Strength 1.0/1.0 for WAN2.2 T2V. As i use WAN mostly as a random-slot-machine and don't describe people too well, this Lora works great, all the usual WAN-faces and curly hairstyles disappear and everything has a touch of candidness/realness to it. Good Work.
I just tried it, it's really amazing
It's really good! I'm noticing some ghosting/double images at .80. I'm able to reduce by lowering strength of course, but lower than .6-.7 loses the magic. However, I'm only use the low model as part of a Qwen+Wan workflow—so that's likely the culprit
will you train one for qwen image?
This workflow and LoRA are just excellent, thank you!
Z IMAGE version, please! Thanks!
Details
Files
stock_photography_wan22_HIGH_v1.safetensors
Mirrors
CandidPhotography_HIGH.safetensors
stock_photography_wan22_HIGH_v1.safetensors
stock_photography_wan22_HIGH_v1.safetensors
stock_photography_wan22_HIGH_v1.safetensors
stock_photography_wan22_HIGH_v1.safetensors
stock_photography_wan22_HIGH_v1.safetensors
stock_photography_wan22_HIGH_v1.safetensors
CandidPhotography_HIGH.safetensors
Available On (1 platform)
Same model published on other platforms. May have additional downloads or version variants.