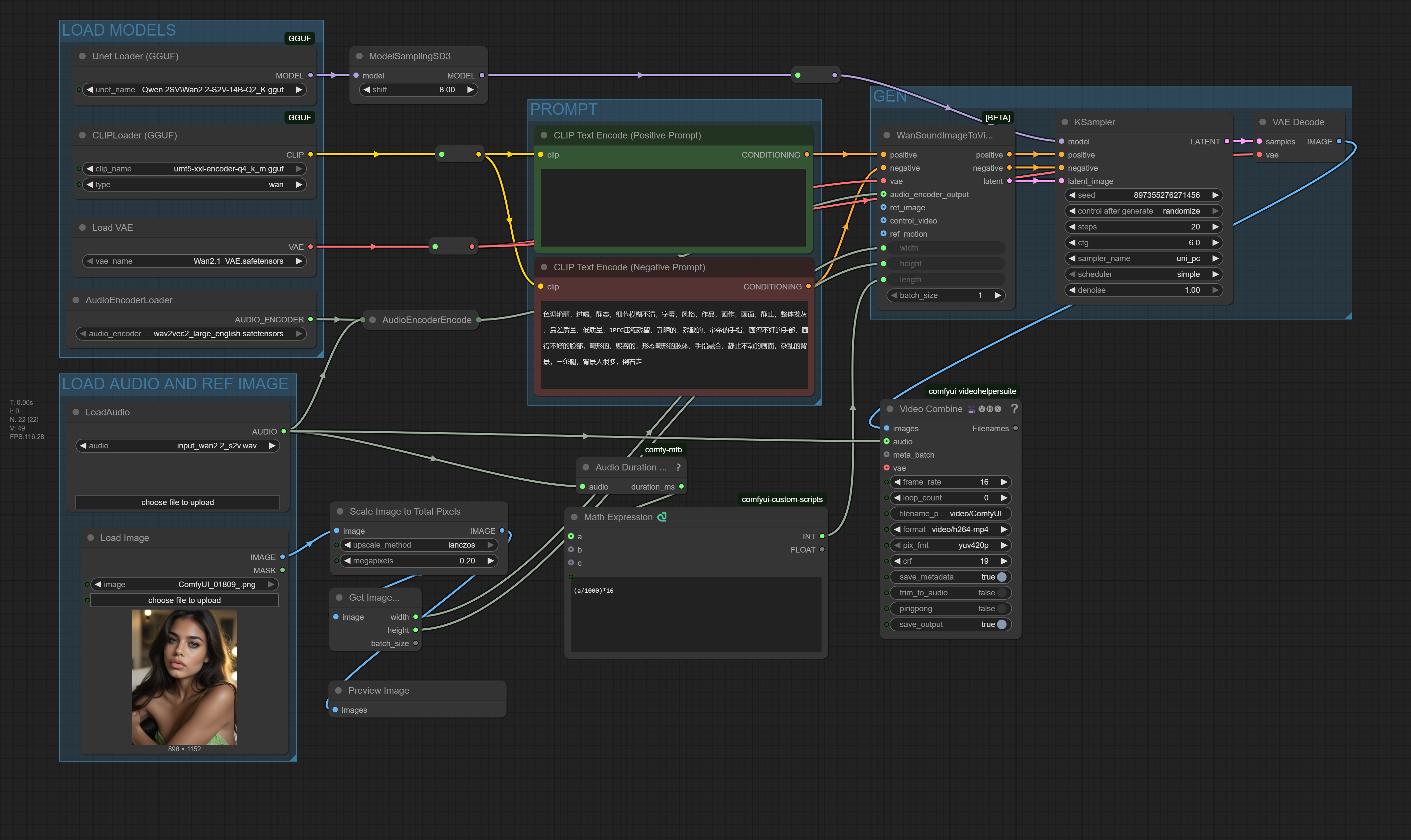
Breakthrough efficiency for Sound-to-Video. This revolutionary workflow runs the massive 14B parameter WAN2.2 S2V model on consumer hardware by leveraging fully quantized GGUF models for the UNET and CLIP. Experience true audio-driven animation with drastically reduced VRAM requirements, making high-end S2V generation accessible to everyone. CPU/GPU hybrid execution enabled.
Workflow Description
This workflow is a technical marvel, designed to democratize access to the powerful WAN2.2 Sound-to-Video 14B model. By utilizing the ComfyUI-GGUF plugin, it loads both the UNET and CLIP models in highly compressed, quantized GGUF formats. This translates to:
Massive VRAM Savings: The Q2_K quantized UNET allows the 14B model to run on GPUs with as little as 8-10GB of VRAM, or even on capable CPU systems.
Hybrid Execution: Seamlessly offloads layers between GPU and CPU to maximize performance on any hardware setup.
Full Fidelity Functionality: Despite the compression, you retain the complete S2V feature set: audio-driven motion, high-quality output, and professional video encoding.
This is the ultimate solution for users who thought the 14B S2V model was out of reach. Now you can run it.
Features & Technical Details
🧩 The Quantized Stack (The Magic Sauce):
UNET (GGUF):
Wan2.2-S2V-14B-Q2_K.gguf- The core video generation model, quantized to 2-bit for extreme efficiency.CLIP (GGUF):
umt5-xxl-encoder-q4_k_m.gguf- The text encoder, quantized to 4-bit for optimal performance.VAE:
Wan2.1_VAE.safetensors- Loaded normally for maximum visual fidelity.Audio Encoder:
wav2vec2_large_english.safetensors- Encodes the input audio for the model.
🎬 Core Functionality:
True Sound-to-Video: The generated animation is directly influenced by the characteristics of your input audio.
Auto-Duration: Automatically calculates the correct number of video frames (
length) based on your audio file's duration.Smart Image Preprocessing: Automatically scales your input image to an optimal size (0.2 megapixels) while preserving its original aspect ratio for animation.
Professional Output: Uses
VHS_VideoCombineto render a final MP4 video with perfect audio sync.
⚙️ Optimized Pipeline:
Clean, grouped node layout for easy understanding and operation.
Efficient routing with reroute nodes to keep the workflow organized.
How to Use / Steps to Run
Prerequisites (CRITICAL):
ComfyUI-GGUF Plugin: You MUST install the
ComfyUI-GGUFplugin from its GitHub repository. This is non-negotiable.GGUF Model Files: Download the required quantized models:
Wan2.2-S2V-14B-Q2_K.gguf(Place inQwen 2SV\folder)umt5-xxl-encoder-q4_k_m.gguf
Standard Models: Ensure you have
Wan2.1_VAE.safetensorsandwav2vec2_large_english.safetensors.
Instructions:
Load Your Image: In the
LoadImagenode, select your starting image.Load Your Audio: In the
LoadAudionode, select your.wavor.mp3file.Craft Your Prompt: Describe your scene in the Positive Prompt node. The negative prompt is pre-configured.
Queue Prompt. The workflow will encode your audio, process it through the quantized 14B model, and generate the video.
⏯️ Output: Your finished video will be saved in your ComfyUI output/video/ folder as an MP4 file.
Description
FAQ
Comments (13)
Maybe actually link to the required models.
For heaven's sake, follow the relevant Reddit forums, and maybe use Google!
Gofaster (lightx wan2.1) LoRAs work, BUT really damage motion. If you only need the lips to match the speaking, gofaster is great.
And, of course, generating more than the usual 5secs of video (this model supports 15sec?) will badly stress your VRAM if your rez is too high.
But, praise the lord, at last we have a clean native solution that runs as fast as normal vid gen, and works great with 16GB of VRAM (remember you need 64GB of RAM, ideally more).
PS this workflow uses tiny brain-damaged models- because it does it WRONG. You want your models kept in RAM (via the Windows file cache system) and streamed across your PCIe bus each iteration. That way you can use the fp8 versions (or even fp16 if you have enough system RAM- which is what matters, not VRAM).
Where is your workflow? can I try it? Sounds reasonable.
Curious, what models are you using?
I have an RTX 4070TI Super with 16gig of VRAM and 64 gigs of system RAM. What model sizes do you recommend for that kind of setup to run this workflow?
I literally have all of the models you listed loaded correctly, but when I try to run a generation, this old friend pops up...
"The size of tensor a (29) must match the size of tensor b (28) at non-singleton dimension 4"
Yes, this model is particular about resolutions. Please also double-check VAE and CLIP.
@zardozai VAE is standard wan_2.2.vae, clip is definitely the Q4KM umt5...
The width is being controlled by the Maths Expression node, and the height is set to what it is in the workflow by default (480?)
Any idea how I can fix the resolution to prevent the model from throwing a fit?
@Seeker360 change the resolution of the image you load into it, it picky about it
@Seeker360 You should use wan_2.1.vae
@zardozai Sorry, I meant wan_2.1.vae - that's the one I have loaded.
@kcir100 What resolutions does it work best with? I'm going in blind here
I was stuck the same. There is an easy fix: connect "scale image" with "Resize image" node and then make sure to enable "divisible by: 16". Then connect width and height to the "WanSoundImageToVideo" Sampler. Then you don't have to manually change anything.
Anyway. Just make sure the resolution is divisble by 16 and you hopefully won't see the error again. At least it worked for me.