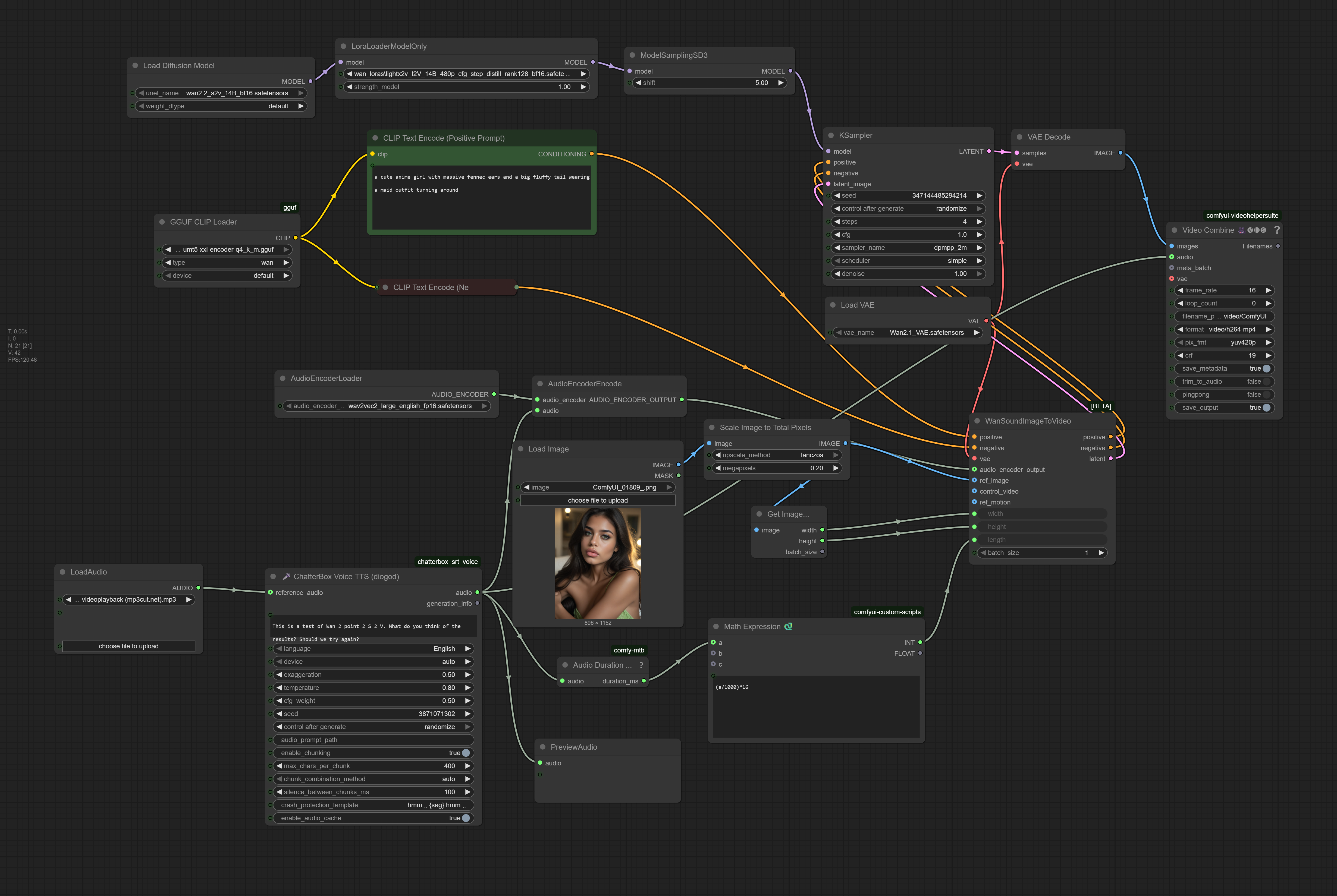
Welcome to the next generation of audio-driven animation. This isn't just an update; it's a complete optimization overhaul. Building on the revolutionary concept of using sound to direct video motion, V2.0 focuses on speed, stability, and accessibility.
This workflow is a masterpiece of efficiency, designed to leverage the WAN2.2 S2V 14B model's capabilities without the traditional hardware constraints. Whether you're creating talking-head videos, music visualizers, or dynamic narrations, this suite provides a professional, reliable, and incredibly fast pipeline.
What's New in V2.0? (Key Updates)
⚡ Lightning-Fast Generation: Integrated the
Wan2.2-Lightning_I2V-A14B-4steps-lora. This cuts the generation steps from 20+ down to just 4, drastically reducing render times while maintaining impressive quality. This is the biggest performance upgrade.💾 Massive VRAM Optimization: Replaced the standard CLIP loader with a
ClipLoaderGGUFnode, using a quantizedumt5-xxl-encoder-q4_k_m.ggufmodel. This significantly reduces memory usage, making the workflow accessible to users with less VRAM.🖼️ Smart Image Handling: Added an auto-image scaling and dimension detection pipeline (
GetImageSize+ImageScaleToTotalPixels). The workflow now automatically reads your input image's dimensions and scales it optimally (to 0.2 megapixels by default) before animation, ensuring consistency and saving you manual steps.🔧 Streamlined Sampling: Updated the
KSamplerto usedpmpp_2m, which pairs perfectly with the Lightning LoRA for fast, high-quality results in just 4 steps.🎯 Improved Integration: The final
VHS_VideoCombinenode is now properly linked to the generated TTS audio, ensuring the final MP4 has perfect audio-video sync out of the box.
Features & Technical Details
🧩 Core Components:
Model:
wan2.2_s2v_14B_bf16.safetensors(The specialized Sound-to-Video model)Speed Booster:
Wan2.2-Lightning_I2V-A14B-4steps-lora_LOW_fp16.safetensors(For 4-step generation)VAE:
Wan2.1_VAE.safetensorsCLIP (GGUF):
umt5-xxl-encoder-q4_k_m.gguf(VRAM-efficient)Audio Encoder:
wav2vec2_large_english_fp16.safetensors
🎙️ Integrated Voice Cloning (TTS):
Node:
ChatterBoxVoiceTTSDiogod- Generate narrated audio from any text.Auto-Duration: The workflow still automatically calculates the perfect video length for your audio.
🎬 Professional Output:
Primary Output:
VHS_VideoCombinenode creates a finalized MP4 video with synchronized audio.High Efficiency: The entire pipeline is built for speed and lower resource consumption.
How to Use / Steps to Run
Prerequisites:
The Specialized Model: You must have the
wan2.2_s2v_14B_bf16.safetensorsmodel.The Lightning LoRA: Ensure you have
Wan2.2-Lightning_I2V-A14B-4steps-lora_LOW_fp16.safetensorsin yourwan_lorasfolder.GGUF CLIP Model: Download
umt5-xxl-encoder-q4_k_m.gguffor the GGUF loader.ComfyUI Manager: To install any missing custom nodes (
comfy-mtb,gguf,comfyui-videohelpersuite).
Instructions:
Load Your Image: In the
LoadImagenode, select your starting image. The workflow will automatically handle its size!**(Optional) Voice Clone: Provide a reference audio file for the TTS node to clone.
Write Your Script/Prompt: Change the text in the
ChatterBoxVoiceTTSDiogodnode and the positiveCLIPTextEncodenode to match your desired content.Queue Prompt. Watch the workflow generate a video in a fraction of the previous time.
⏯️ Output: Your finished video will be saved in your ComfyUI output/video/ folder as an MP4 file with perfect audio sync.
Tips & Tricks
Quality vs. Speed: The Lightning LoRA is set to strength
1. For potentially higher quality (but slower generation), try lowering the LoRA strength to0.7-0.8.Prompt Power: The audio drives the motion, but your text prompt still defines the character's appearance and style. Use it to guide the visual output.
Resolution Control: The
ImageScaleToTotalPixelsnode is set to0.2megapixels for speed. Increase this value (0.4,0.6) for higher resolution input, which may improve final detail but will use more VRAM.First Run: On the first execution, ComfyUI will cache the GGUF model. This may take a few minutes, but subsequent runs will be very fast.
Tags
WAN2.2, S2V, Sound2Vid, ComfyUI, Workflow, V2, Lightning, 4-Step, Fast, Optimized, GGUF, VRAM, Efficient, Audio-Driven, Voice Cloning, TTS, I2V, Animation, 14B, Talking Head
Final Notes
V2.0 transforms this workflow from a technical showcase into a practical, daily driver for content creation. The combination of the Lightning LoRA and GGUF loading makes it arguably the most efficient and accessible way to experiment with and produce high-quality sound-to-video content.
Experience the future of AI video generation, optimized for speed and simplicity.
Description
FAQ
Comments (5)
1. The models should NOT take space in VRAM- and then they do not need to be silly tiny quants! They need to be in RAM, and streamed as needed.
2. There is a high price for the gofaster LoRA approach. Most motion vanishes, and lip motion is acceptable, but not as good as without the LoRA.
In the coming days split sampler workflows will appear, to try to get the best of both worlds- motion, lip quality and SOME speedup from a gofaster LoRA. It seems as if this model MAY be capable of working as a low noise stage with the conventional high noise Wan2.2 model - allowing slow motion generating iterations and gofaster iterations for frame refinement.
Unlimited S2V should be enabled, but more than 100 frames causes a memory error. How do I fix it?
Don't bother. This doesn't work. I downloaded everything exactly as it says and I get:
"The size of tensor a (23) must match the size of tensor b (22) at non-singleton dimension 3"
Other S2V workflows are totally fine for me, my friend gets the same problem on his machine.
Wasted a ton of time with this.
You just set the wrong resolution; S2V is quite particular! This WF is working perfectly fine.
Tried this out. It works well, and it's fast. But the quality is not awesome. There is a flash at the start of every video. A little fine tuning, and larger output would help this tremendously.