JonXL's DirectWan V6.0f - Wan 2.1 (+VACE Stand-In) + 2.2 Advanced V6 Workflow - T2I T2V I2V FLF2V (Trim, Extend, Upscale, Interpolate, Overlay)
Please do not redistribute this workflow or significant parts of it without my consent.|
If for some reason download links are unavailable, please visit https://huggingface.co/JonXL to find a copy of the relevant files, use at your own risk)
A multipurpose workflow for generating text to video, text to image, image to video, first-last frame to video, with support for 2.1 VACE Controlnets + Stand-in, including a useful trimming feature. (64GB RAM + 16GB VRAM recommended)
Configure all models once (download links and folder paths in notes) and then switch between generation modes.
Additional information can be read in the surrounding notes, explaining all features and configuration details.
Feel free to post your SFW generations on this page.
Happy prompting! - JonXL
Features:
Everything explained in notes with download links provided!
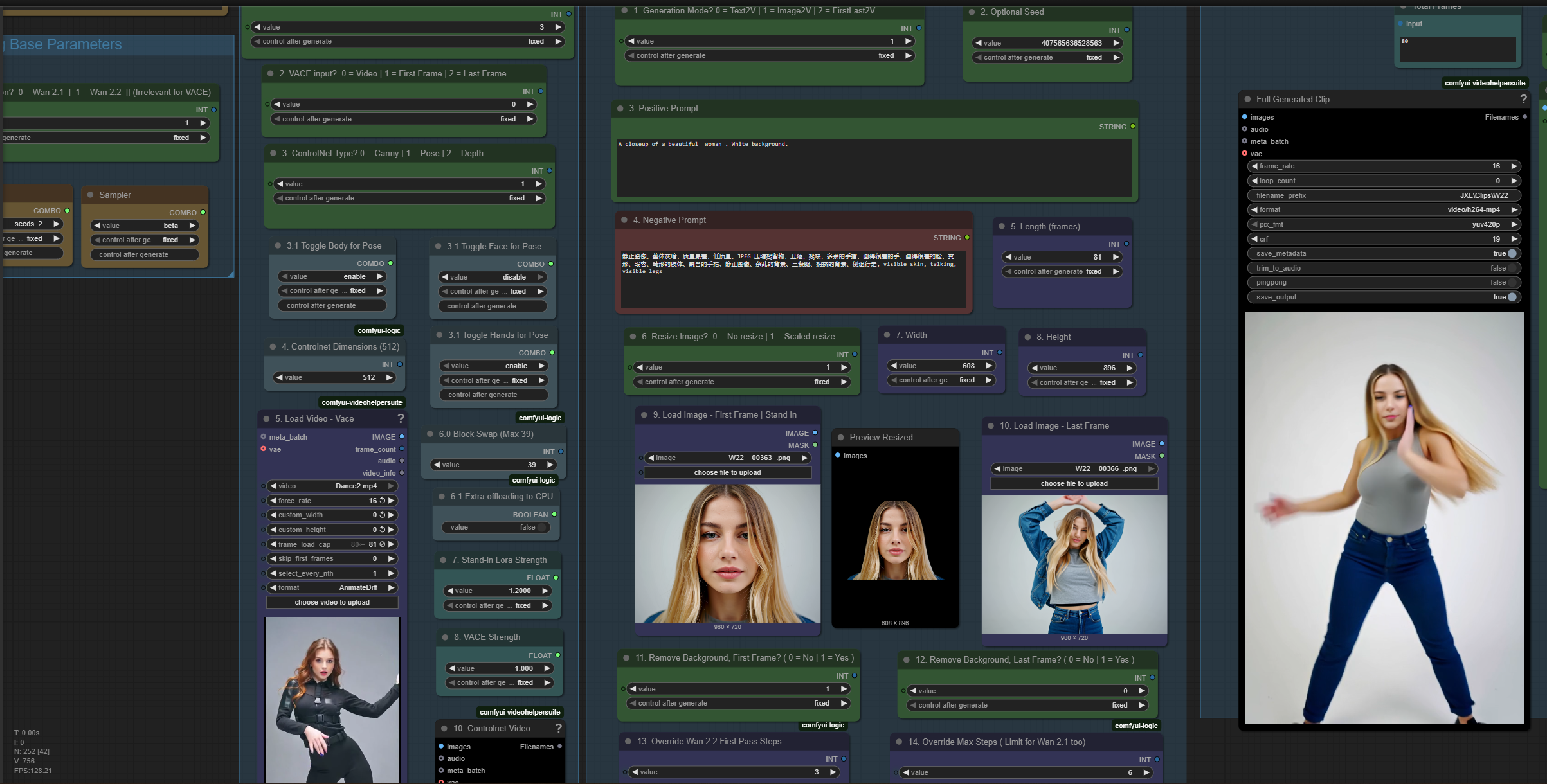
Allows for Wan 2.1, Wan 2.1 Vace + Stand-In (any combination), and Wan 2.2 Generation inside the same workflow. Canny, Pose (Face, Body, Hands) and Depth can be toggled with a single switch (!))
Allows for T2V, T2I, I2V and FFLF2V generation. Easily switch between T2V, I2V and FFLF2V per toggle.
Supports simple resize and rescaling of input images instead of cropping (using a single toggle)
Allows for infinite video generation, when loading the last generated input image manually (auto saved in a separate folder).
Includes a subproces of clip trimming, choosing the start and endframe of a generated video before saving the video.
Saves a comparison video for VACE generated clips (left: input video, right: output video)
Includes optional post processing upscaling and frame interpolation of the generated clip. (easy enable / disable through control panel)
Multi Lora loading
Sage Attention for performance (easy enable / disable through control panel) - recommended, but maybe hard to install.
Block Swap for 2.1 VACE enabled by default (21) - Useful for low VRAM GPUS (consider '39' for low VRAM and less for higher end GPUs)
Bonus: Overlay one image on top of another image (with auto background removal).
Bonus: Seperately load a video for upscaling or frame interpolation
Bonus: Join two videos together into a single video
Bonus: Separate workflow for joining up to 10 videos at once (with option to upscale and interpolate as well)
Possible future updates:
Rework of Wan 2.1 (Non-Vace) and 2.2 to use WanVideoWrapper instead of basic K-Sampler (as for now Wan 2.1 Vace needs non quantized Safetensors and Wan 2.1 / 2.2 is based on GGUF)
Other cool features
Extremely useful workflow to do everything you want with Wan 2.1 and Wan 2.2.
Please take your time to read the notes if necessary, or check out my less advanced workflows on CivitAi as well:
https://civarchive.com/user/JonXL
Note:
(!) When loading this workflow, make sure to load a random image in both Load Image nodes, and a Video in the Load Video node, regardless of whether you think the workflow actually needs them.
(the zip archive came with images and videos that you can use).
(while the image is not needed, ComfyUI likes to complains about it)
For T2I it is recommend to install the following custom_node to use "res_2s" + "bong tangent" sampler: https://github.com/ClownsharkBatwing/RES4LYF
Recommended usage:
Start using this workflow by zooming out and going from left to right.
(Initial setup)
0. Determine if you have Sage Attention installed, or try installing it following the notes.
1. Download and configure the necessary models (I2V, T2V, VACE, Clip, Vae, Loras etc), use the download links and put in the correct folder as mentioned in the notes.
(Normal use)
2. Decide whether to use regiular Wan 2.1 or Wan 2.2, or Wan 2.1 Vace + Stand-in.
Configure which Wan version to use, which prompt, set video parameters.
Read the notes for additional information.
3. After generating, trim the video optionally, by selecting first and last frame, by using a starting frame index and amount of frames to add from that point.
Press "Run" (or CTRL+ENTER) in ComfyUI to generate a preview of the trimmed clip.
Optionally use the "Dump frames" option in the Control Panel, to dump all frames to make it easier to find your start and end frame.
4. When you are happy with the trimmed video, save it by putting "SAVE TRIMMED CLIP" to 'true' and then "Run" ComfyUI once more.
Now, optonally choose to enable Step 4.2 "Upscale and Interpolate (trimmed clip)" to also save the video but upscaled and interpolated.
(You can also do this later, if you joined all your clips together in a final pass I guess)
5. Set "SAVE TRIMMED CLIP" to 'false' and either:
- Change the seed in the KSampler of step 2 for a new generation on same prompt
- Change the prompt in step 2 (different prompt) for a new generation on antoher prompt
- Change the image (if in Image to Video mode) in "Load image" and optionally change the prompt to generate from another frame.
Load the last frame from the ComfyUI\output\JXL\LastFrames\ folder to continue generating from the last frame of the clip you just generated.
Folder structure:
Output\JXL\Clips\ - All initial generated clips, untrimmed
Output\JXL\FirstFrames\ - First Frames (can be used
Output\JXL\LastFrames\ - Last Frames (useful for the Load Image node to continuing clip generation)
Output\JXL\Trimmed\ - Trimmed videos when saved
Output\JXL\Processed\ - Processed videos (based on the trimmed videos), upscaled and interpolated
Output\JXL\Compare\ - Saves VACE generated compare videos with input video (left) and output video (right)
All files are prefixed with 'w22'.
Please leave a like, comment and feel free to upload any SFW content you made using this workflow on the workflow's CivitAI page.
Happy prompting!
- JonXL
(https://civarchive.com/user/JonXL)
Pro tip:
Go to settings (cog wheel) -> Keybindings -> Search for 'Canvas Toggle Link Visiblity', set a keybinding (SHIFT + [+] ) and press it to toggle the node's lines.
Description
FAQ
Comments (22)
Thanks - I get an error about the ComfyUI-NeuralMedia, but it seems the github link is down, do you have a mirror? https://github.com/YarvixPA/ComfyUI-NeuralMedia
That's unfortunate! How dare they delete their repo :0
Which node in the workflow is affected?
Apparently, cough cough, a mirror can be downloaded here:
Probably just extract to custom_nodes folder and do the requirements install thingy if necessary.
Let me know if it works out.
I think I already found a workaround for not using that repository dependency.
You can either install the custom_node manually or better yet try out a fresh download (Version 6c + )
Please let me know if it works :)
Thanks for the quick reply! After I updated the other items using the ComfyUI manager the NeuralMedia error went away, which is strange.... because it wasn't one of the updates that ComfyUI said it was going to update.
Another question - under the "wan Stand In" note (below Node #383), the workflow defaults to Ace Plus/ComfyUI_portrait_lora64.safetensors. I downloaded the KJ standin for VACE, but the node is called "Primitive" and it doesn't see the Stand in file downloaded... only other Loras. Should I leave as is, or is there something I need to do to get the stand in to work?
Thanks again!
Welp, scratch that last question - turns out after I installed the missing NeuralMedia node, it was able to see my Stand In file... not sure if it's related, or was just a ghost in the machine (I had tried refreshing comfyui with 'r' and also restarting it prior, but that didn't help to reveal the stand in file)
@fancypantzzz
If it works it works :)
Glad it worked out for you!
Let me know if you have any other errors or questions.
Happy prompting!
Is there a way to use Stand-In with Wan 2.2 without a reference video / VACE? I just want to maintain a consistent character using a reference image for my I2V and/or T2V prompts but without requiring a reference video. It seems all your examples are using a reference video.
Thanks for your question. The examples use VACE Video + a picture for Stand-In of the character.
Right now, Wan 2.2 has no release yet with VACE / Stand-in integration .
So Wan 2.1 with either/both VACE + especially Stand-in is the way to go for consistent characters right now.
You can set the mode for "only" stand-in here, group "2.2 Config Wan 2.1 Vace / Stand In"
the first toggle " 1. VACE + Stand-in Mode? 0 = Neither | 1 = Stand-in | 2 = Vace | 3 = Both" .. put "1" as a value.
Also.. you could also try to use Qwen Edit to generate keyframes for your characters and use Wan 2.2 First-Last Frame to Video to fill in the movement between the keyframes.
Hope this helps, otherwise let me know.
Can you explain more about your workflow?
To get of someone to dance like video I provide the following configuration.
I only have Sample Wan 2.1 Vace Stand in node enabled
2.2.1 I pick 3 (Both Vace and Stand In)
2.2.2 i pick 0 (Video)
2.2.3 i pick (1 Pose)
In 3. Prompt & Generate Mode
1. I pick 1 (Image2V)
9. I load the image of the person that I want it dance (First Frame)
10. I load the same image as 9.
I manage to extract the dance poses from video. But the video output, person, background and clothes are all changed. What did I do wrong?
Hi there chimprocket! Thanks for your comment!
Based on what you wrote it should work.
For VACE json workflow it should work out of the box, you only should need to load a video (set aspect ratio correct width / height ), and two images and hit generate.
(try doing this once more and see if it works out)
Do you otherwise have Discord?
You can join this AI related Discord server and find me under the name Jonko XL:
https://discord.gg/99bkaXwQ
By the way, I am also working on an updated workflow, which should be more user friendly and less clogged, so you could wait for that too :)
@JonXL Thank you for your responsive reply. I shall try again. Great workflow! Your effort is commendable.
@chimprocket You are welcome, let me know if you need to. Thank you as well, I appreciate it!
Hi JonXL!
Thanks for your workflow! I'm trying to make it work with wan 2.1 and stand-in only for now (t2v)
I have a 4090 mobile with 16 GB VRAM and when I hit Run it starts a T5 encoder routine that runs very slow (55s/it, 24 iterations). I notice that while this happens, my VRAM is only 11% used, so I think maybe the low speed comes from a misuse of the GPU? Is there any setting I should change? I'm using gguf models. Thanks!
Hi there pep!
Yeah, I found out later that it's possible to run the Text Encoding on GPU too, though never changed it since it could bottleneck lower end GPUs.
You can find a 'Device' switch for ' CPU/GPU' in a red-brown colored Text Encoder node, it's located on the center lowest point of the workflow ( zoom out).
You may even be able to disable 'Disk cache' too while you are at it.
Send me your Discord tag if you can't find it, I can help you out.
@JonXL thanks for answering so fast and clear! I'll try it later and I hope the generation speed will improve. I'll get back to you if I'm stuck ;-) have a nice day
@peptrunic2 Thank you Pep! Let me know if there is anything. Have a nice day as well!
@JonXL @JonXL Hi Jon! Me again... I modified the CPU/GPU switch and the text encoding ran like a charm. Yesterday at the end of the day I even could generate a video with stand-in. However, when I tried to replicate the success this morning with the face that in want and the prompt, all I get are output videos that are a complete blur, like a giant blurry stain with some movement. I tried all the Wan models I have, the ones that I downloaded from your workflow and others, but I couldn't obtain other results, it's always the blur. Any ideas? I tried with Wan2.1_14B_VACE-Q6_K.gguf, with Wan2_1-T2V-14B_fp8_e4m3fn.safetensors, nothing worked. I'm clueless... Thanks in advance!
@peptrunic2
Hi there Pep!
Glad to hear that the Text Encoder toggle worked out well for you!
About your issue, I can only refer you to these options:
1. Reload the downloaded workflow again and configure the models + load images and video, but don' t touch other settings.
2. Try dragging your output image or video into ComfyUI webbrowser tab and see if it shows you the settings you used for that workflow.
I think either of those should fix your issue, maybe you inadvertently touched the step count or changed the light lora? Could also be a CFG /denoise issue but I doubt that you changed that.
Let me know if this helped :)
Note: In this workflow only safetensors file of Vace can be used.