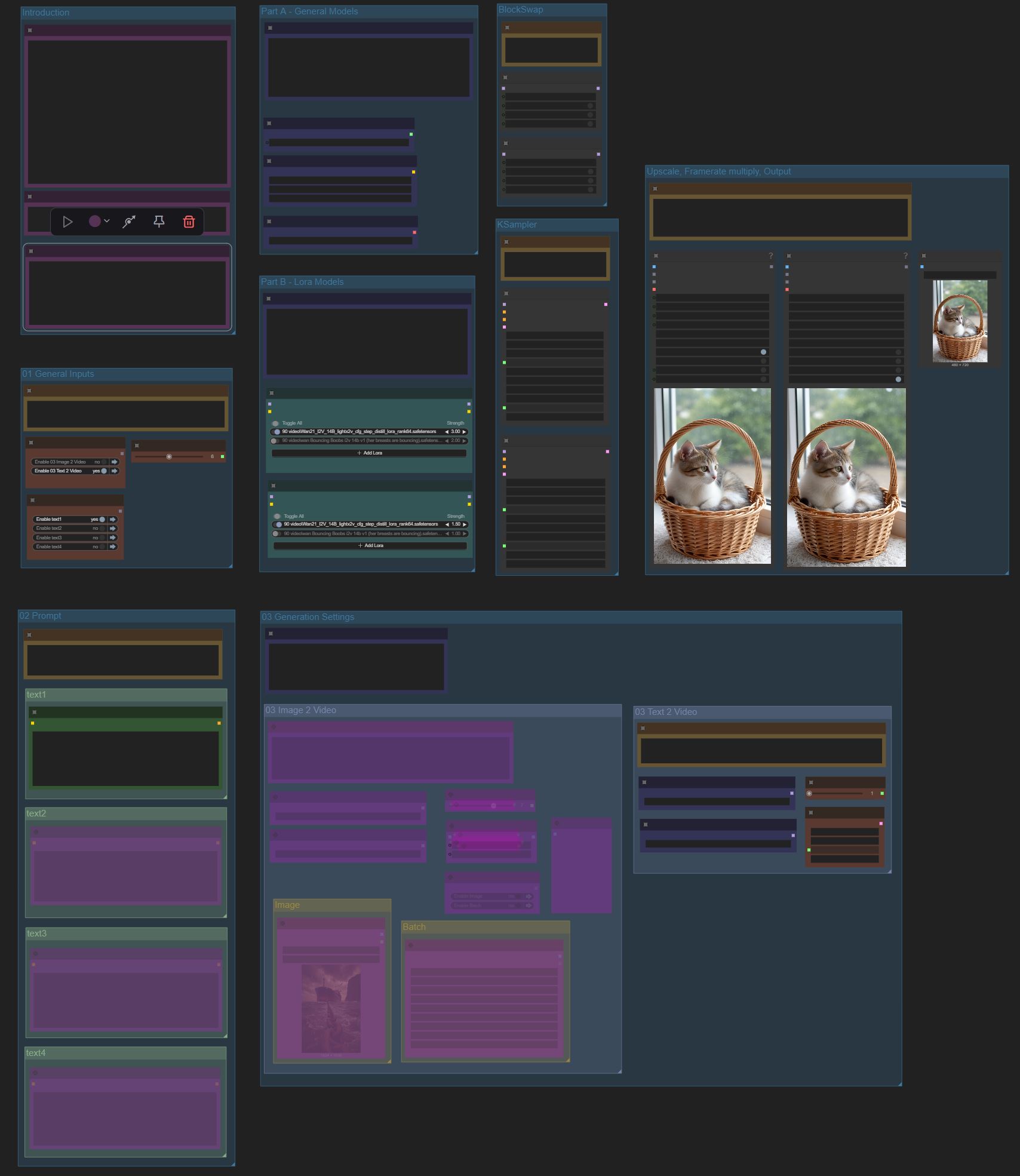
[Edit:
Version v5.0 works with latest comfyui (v0.15.0).
If you have any problems, please refer to the FAQ at the bottom of the page or have a look in the comments.
Many thanks to everyone who tested this workflow. Thank you very much for the many inquiries and, of course, for all the knowledge and experience you have contributed. here👍🙂
Special thanks to:
@SeoulSeeker for the "Dead Simple MMAudio" workflow wich are the basis of the audio part here,
@taek75799 for the really well working enhanced models
@Bakazaya pointing to the color issue in version v3.0 and running lots of tests,
@bluntfeather sharing latest experiances with installing Comfyui-Easy-Install,
@nitrovtx for remain persistent in matters of quality and running a lot of tests,
@Icey64 for providing the link to "Comfyui-Easy Install",
@boinobin730 for asking for a First to Last Frame option, running pre tests and responding fast as hell 🙂 and
@SnowShoes311 thank you so much again for all your buzzing 😋]
Features:
Optimized Wan 2.2 workflow, runs perfect on RTX 3060 12 GB VRAM GPU and 32 GB RAM,
"Text to Video", "Image to Video" and "First/Last Frame 2 Video" generation in one workflow, all with easy audio generation,
easy installation/model downloading, all necessary sources are specified,
easy to use workflow, clearly structured, all necessary steps are explained,
easy switches for mode selection,
easy prompt selection for fast prompt creation/testing,
easy switching between "standard" and "enhanced" models,
very fast and smoth high quality outputs up to aprox. 1440 x 960 with 60fps,
2x fast upscaler,
4x fast framerate multiplier,
MMAudio Sampler (generates sound accordingly to the video action),
Triton and Sage Attention option,
A 5 Second long high quality video generation takes about 10 - 15 minutes (see below).
Tested generation times:
As a rough guide value for RTX 3060 GPU: generating a 5 second long high quality 1440 x 960 60 fps video with 6 steps it will take:
t2v: around 10 - 12 minutes,
i2v: around 15 minutes.
Comfyui-Easy-Install with Triton + SageAttention:
This workflow should work with any latest comfyui version >v0.6.0 (Desktop, Embedded, Windows/Linux).
However, comfyui is developing rapidly, and it often happens that some of the custom nodes used are not updated quickly enough or not updated at all. Manual workarounds are sometimes necessary. Furthermore, care must be taken to ensure that there are no conflicts with other nodes.
If you're having difficulties with your existing comfyui system or if you want to run video generation on a separate (parallel) comfyui system, like I do, I would recommend you the following installer: https://github.com/Tavris1/ComfyUI-Easy-Install.
Complete installation of comfyui including manager and some pre configured custom nodes is just one click - really 🙂
Installation of Triton + SageAttention is just a second click - really 🙂 And since it's so easy now, I would definitely recommend it to you for video generation.
Cause it is an embedded version, you can install it parallel to your existing comfyui version without the risk to ruin your working system.
After installation just configure the "extra_model_paths.yaml" file to use your existing models.
After a fresh installation of Comfyui-Easy-Install you might have some issues too, but there are known workarounds - please see the FAQ below.
For testing/understanding/experimenting/changing the workflow:
Click "Toggle Link Visibility" to see the links.
click the Subgraph symbols to open the Subgraphs.
for quick testing you may lower the settings for: steps, clip lenght and video resolution,
be really carefull with modifying Groups or Subgroups (even Titel or Color) cause they are essential for switching,
feel free to try and test other models. Just give me a hint if you find models which deliver better results and fitting the 12 GB VRAM limit.
And as usual: Have Fun 🙂🙂
Short Conclusion:
This workflow is based on elements of a variety of allready published workflows. My "job" was only to put things together, optimize it for a small machine and create a most simple and hopfully user or even "beginner" friendly workflow.
I`m not an "expert" - just a user who wants to get it running on "available" hardware.
There are many things I don't really understand. If you find mistakes or better solutions please give me a hint.
And I really hope that even "beginners" have a chance to go the first steps...
Frequently Asked Questions (FAQ):
For quick and better overview I will try to merge all known issues here - step by step (please be patiant). If your issue is not listed here, please have a look in the comments first. Most issues have been allready discussed.
Comfyui Nodes 2.0:
Turn off Nodes 2.0 in comfyui (use comfyui menue). Actually not all custom nodes are supported.
Comfyui crashes after generation while vae decode, upscaling or frame rate multiplying (Rife VFI) without any error report:
This is a RAM problem (not VRAM). Increase your swap file (min. 64 to 128 GB) or set it to automatic management on a fast drive with at least 100 GB free space.
JW Nodes (JWFloatToInteger, JWIntergerDiv, JWImageResizeByLongerSide), soundfile missing:
For the workaround look here and here:
python -m pip install soundfileFresh Comfyui-Easy_Install Installation (missing soundfile and Pytorch v2.9.0 issue with SageAttention on Windows:
For full conversation look here.
Open cmd in python_embedded folder:
python -m pip install soundfile python -m pip uninstall -y torch torchvision torchaudiopython -m pip install torch==2.8.0 torchvision==0.23.0 torchaudio==2.8.0 --index-url https://download.pytorch.org/whl/cu126Slider Nodes - how can I modify the "default" values:
Right click the slider node, choose Properties and set the values you like 🙂🙃
Description
FAQ
Comments (47)
I guess there is no room for vace to fit in anyway?
Sorry, I don't have a clue about vace. Is there any advantage?
arkinson vace gives you a ton options - start/end frame, reference image, many types of control like depth/openpose/normal/edge/etc
it became my usual workflow to generate base video with good movement etc on low resolution, convert it to normal map, apply some blur and then use it to generate high res video or even reuse it many times on different start images, works great
TurboCoomer thank you for your explanations. Sounds very interesting and I had a short research at ComfyUI Wan2.1 VACE Video Examples - ComfyUI. If I got it correctly vace uses special models and special nodes to manage the "multi-modal inputs" like videos, masks, etc...
Please can you give me a hint why/how you are looking for an integration in my workflow.
Do the vace models run with 12 gb vram? How long does a generation need? Have you eventually tested the vace workflows with the LightX2V Lora? Or is your intention just to run the "high res video generation" with my workflow? I´m not shure, but I believe there is now way to run a "video 2 video" generation with "standard" wan 2.2 right now.
arkinson Im not like looking for integration into your workflow, just was wondering if vace fits in said specs in case you tried, I also have 12 vram and 32 ram
For 2.1 wan I use Q4 with lighx2v and vace from here
https://huggingface.co/QuantStack/Wan2.1_T2V_14B_LightX2V_StepCfgDistill_VACE-GGUF/tree/main
quality is mediocre because of Q4 gguf I guess, but using vace itself was very fun. For now I switched for 2.2 5b and it gives impressive results with giant resolution like 960x1280, but im still waiting for 2.2 14b with vace merged to try. And 5b seems good for upscaling too.
TurboCoomer ahh ok - got you completely wrong 🙄
Do you perhaps have a link to a working wan 2.2 5b workflow or could you provide your own? Maybe I`m blind, but googling I found only a lot of confusion. Which GPU do you use and how long does a generation last with a 960x1280 resolution? And of course thanks again for your interesting inputs 👍
arkinson if your comfy is up to date, you can grab "official" simple workflows from there, Workflow -> Browse templates, I only added sage attention patch to it
I have 3060, 48 frames 20 steps takes like 8 min irrc
TurboCoomer Thank you for the hint to the workflow (I had never used that) 🙄 A generation time of 8 minutes sounds unbelievable . I will test it soon.
TurboCoomer I did some tests with the 5b model, but the results are sobering. The official workflow with 1280x704 is hard at the limit and needs a lot more than 12gb vram for VAE Decode. Ok - with some additional tweeks that my work but the main problem is: without Sage Attention a 5 second video needs definately more then 30 minutes.
I also tested low resulution generation with final upscaling but the output quality is usually quite poor. In addition the 5b model seems to be hard at prompting or needs a different style of prompting. Finally I`m out here.
It seems users that have a working Sage Attention installation may have more luck. I tried it on a windows machine but I never got it running without errors and I would say many users have the same problem....
arkinson I use 5b daily with my 3060 12gb and 32gb ram, mentioned that already. Posted few videos made with it recently btw. Make sure your vae is at fp/bf16 and that you use tiled vae decode. This model was trained on high resolution and doesent work at all on lower than 960x960 or so. Prompt adherence is definetely worse than 14b, but that should not be a problem for i2v with loras, control is likely upcoming soon too.
Sage attention installation can be problematic, not by itself but because you very likely need to mess up with windows setttings you have no clue about. That forced me to reinstall windows recently, on fresh system and fresh comfy its much easier to install, spend less than an hour for all of that.
TurboCoomer uhhh - my last window reinstallation took several days and a couple of month to get 80 - 90% working again 😂🤣
Thank you for explaining why the model runs poorly at low resolutions. I know that you work with "small" hardware too. My comment was just, that it make no sense to run a higher model without Sage Attention.
And no - I don't give up that quickly. I´m pretty sure I will that f...ing Triton and Sage Attention get running some day - just for "research"🧐 I even thought about to install a small Linux test inviroment.... But at the moment, I'm getting along fine with my stripped-down workflow too.
arkinson you can try this video Faster Wan 2.2 - Install Triton + Sage Attention (Comfy UI Guide)
I tried lots of other video but they didn't work for me.
But this one worked https://youtu.be/-S39owjSsMo?si=I7B8tQL8dYwCNvCu
so just try using it and also i have same RTX 3060 12 Gb oc.
I haven't tried your workflow but i will give it try
uzaxpro414 Hi - thank you for the link 👍Seems it is based on a comfyui portable istallation? Could you give me a hint wich comfyui version you are using? My working invironment is Comfyui Desktop and for testing Sage Attention I had allready installed the non portable version of comfyui....
[edit: ok it is comfyui portable. I will try to get it running..... ]
uzaxpro414 Finally I got it running 🙂🙃🙂 Thank you so much again for your advise and link 👍 The video is sometimes a little bit confusing but the linked steps and the test file for Triton working pretty well. I didn't know that Comfyui Portable with embedded Python could be installed so easily as a second/test/working environment without destroying the running system. I will probably try to explain this briefly in a new workflow version soon. First speed tests looking very well 🙂
@arkinson Sorry for late reply. Glad it worked out for you 😊 yeah that video is a bit messy but gets the job done. Looking forward to your new workflow version 👍. portable really makes testing much easier.
@uzaxpro414 Thank you for your reply. I`m nearly ready with testing and prepairing the workflow. I just have to write some "guidelines" and hope I can publish it in the next hours....
@uzaxpro414 It`s published now 🙂
@arkinson I will check it
Дякую за цей робочий процес. Мені він надзвичайно сподобався. По часу - все так як і написано. Якість мене також влаштовує.
Hi - thank you for your review 👍 greatly appreciated
Awesome / Easy to understand workflow that works and super fast! Thanks man! :-)
thank you for your review 👍🙂
This workflow is absolutely awesome. Thank you very much to share such a hard work!
Hi - I`m really glad you like it and thank you so much for buzzing 😋🙂🙂
I'm using the same card as yours, but I'm using a full-fledged model, and I'll tell you by speed - 5 sec 15 min maximum, this is with sageattention, what's the point of these GGUF ?
I had tryed a lot for myself, even tested an installation with Sage Attention, but either I got "out of memory" errors quickly or generation times not less than 30 - 60 minutes. Maybe you can give some more specifically information about the workflow and the model you used.
I'd also be interested to know. I run a 3060 12GB card and cannot get any workflow to work for me.
WaifuAIDegenPrompter Have you tried mine here? It shoud run without any problems.
arkinson arkinson I attempted to but comfyManager wouldn't download the correct Nodes. I have updated and will try again.
arkinson Regular models - wan2.2_i2v_high_noise_14B_fp8_scaled - wan2.2_i2v_low_noise_14B_fp8_scaled, I wrote two nodes to free up WRAM, put one after the first KSample, put the second after the decoding node, everything is clear, there are no problems, I use sageattention + Lora for speed - https://huggingface.co/Kijai/WanVideo_comfy/tree/main/Wan22-Lightning
soyv4 Thank you for your information. Ok - with a working Sage Attention installation you may have luck - but without you can forget about it. I tried to get it running on a windows machine - but unfortunately without success. You may have a look in the converation with TurboCoomer too.
arkinson I'm attempting to use your workflow but to me it's very confusing. I am not sure which Wan models to download and where to put things. I understand that WAN go into the lora location (my COMFYUI and A1111 Forge share a folder path), but all this other stuff is confusing AF.
WaifuAIDegenPrompter I know - starting is allways a little bit confusing and sometimes frustrating 😥But fortunetely it is easier than you think 😉
Please read the notes in the workflow - you get there even the path informations:
1. have look at the pink note: "First Preparation / Model downloads"
2. read the 3 blue notes (Part A,B and C) with the download links and the path informations for every model. From the sources just choose the exact same filename you see in the node.
Ok - step by step. Your main path is .....\models\
Part A:
...\models\upscale_models\
...\models\clip\
...\models\vae\
Part B:
...\models\lora\
Part C (download all 4 gguf models):
...\models\unet\
If a path not exist, just create it. That`s it. I hope it helps, otherwise jask ask 🙂
arkinson I actually got it to work last night!
arkinson In your workflow, do you support landscape images?
WaifuAIDegenPrompter Hi - nice to hear that you got it running 👍
You can try any resolution you like - even for landscape. You only have to pay attention that the longer side is max. 720 - otherwise you have the risk to run in "out of memory" errors or extreme generation times. In my experiance 720 x 720 is at the limit - but feel free to test it yourself😉
In the i2v part you also can play with the value in the "Image Rezise by Longer Side" node. You can use any image here (portrait or landscape) - it will automatically rezised to the longer side value without any cropping.
i cant use
Wan21_I2V_14B_Lightx2v_cfg_step_distill_lora_rank64.safetensors lora
keep getting lora key not loaded Error
any idea how to fix this ?
By the way thanks for this awesome workflow
appreciate the effort !
These error messages are "normal" cause the Lora is wan2.1. However, the higher Lora weights (3 and 1.5) ensure that it still runs smoothly. Does the generation process otherwise run without problems?
arkinson Thanks for the info !
For now everything seems to be good , except some bad motion and blury results ,
and i cant really understand what the "blockswap" for , and what will happen if i disable it or perhaps remove it
one more thing , it would be helpful if you make a v1.1 with first & last frame image to video feature added to it
Thanks A LOT !! 🌹
mamontagefiles I´m glad you get it running 👍
BlockSwap reduces the usage of vram drastically. You can play with the value. For a 12 GB GPU and a 5 - 7 second video with 1 or 2 Loras a value of 30 seems optimal. For a 10 second video I use a value of 40 for example. You can even bypass both nodes to test. But with 12 GB VRAM you will be hard at the limit. On my machine I can`t run any other tasks at the same time without BlockSwap. Even open a web browser can result in an "out of memory" error.
What do you mean with: "first & last frame image to video feature"? All last frame images are stored in your output folder. You simply can grab these images to start a i2v generation.
Really love this workflow. Very easy to setup and use. Only problem is I can't figure out how to change the aspect ratio of the output in i2v. No matter what aspect ratio of image I upload it produces 480 x 720 video and wherever the control for that is hiding I'm too dumb to find it.
It`s very simple - just change the value in the "Image Rezise by Longer Side" node from 720 to 640 for example 🙂
Keep in mind, the node just rezises your input image without cropping, so the aspect ratio of the output is allways the same as your input image.
I´m glad you like the workflow 😋
arkinson Yeah that was the behavior I was expecting but it wasn't working. Turns out (and I have no idea how) the connections to set the height and width from the preview image in WanImagetoVideo had gotten unhooked. Just checked and it seems to be there in the original template so I somehow managed to break it without ever expanding either node until like 5 minutes ago. Anyway confirmed that this was me being dumb and the template works great!
Random_Noise argh - such little "mistakes" are sometimes frustrating 😝 Good luck and happy creating 🙂
Random_Noise I had the exact same thing happen. I don't think I even touched that part of the workflow. Very peculiar.
Edit: Just re-downloaded the workflow and indeed the dimensions are not connected to anything. After I connected them to the WanImagetoVideo the dimension and aspect rations worked as expected.
uglimus you are right!. My mistake - I forgot tho set these connections and didn't notice it because I never changed the resolution. I will publish a version 1.1 soon. Thank you so much for testing and commenting 👍
Random_Noise It was really my mistake - just forgot the connections 🙄 Please see my comment to "uglimus". And thank you too for pointing that out.