Release Note
(v1.0 -> v1.1)
Speed improvement (10% to 20%) through the use of sage-attn and torch compile nodes
Continuity assurance (the last frame in each loop process is not used in the next loop
About
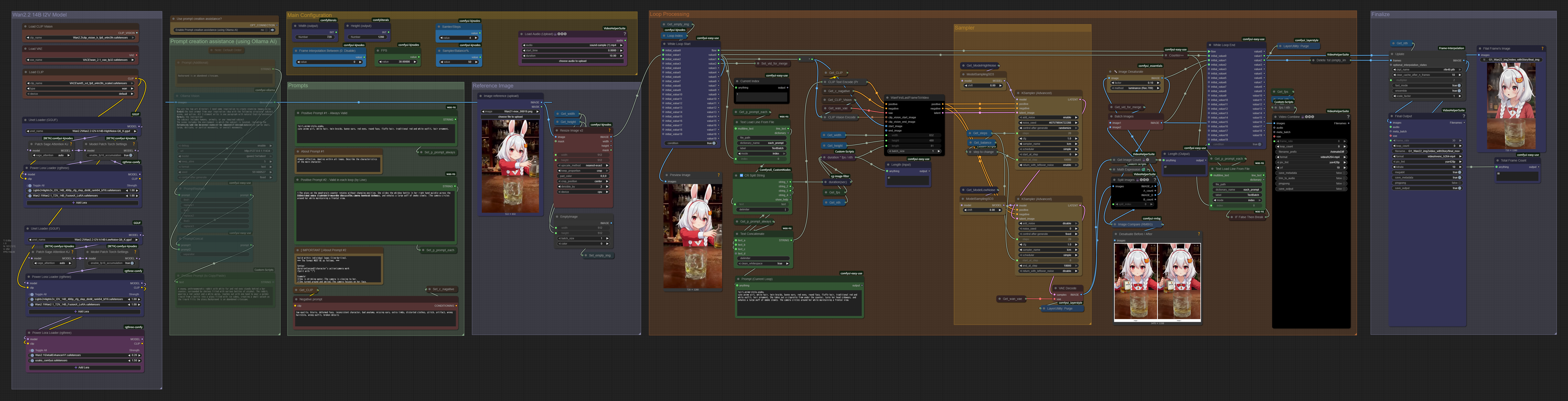
This is an I2V workflow created for Wan2.2.
By utilizing the high reliability of the start frame of the “FLF2V” mechanism and connecting the video output created in the loop processing, it is possible to generate videos of any length.
[2025.8.10 Add]
This workflow does not use "end_image" for FLF2V node.
If you want to use, download similar version.
Features
Express one scene in a single prompt line. The number of prompt lines you set will be the number of scenes (number of loop processing times).
[IMPORTANT]
There are rules for writing prompts. Please use the following format:
duration (seconds) | character action | camera work(separate each item with a “|” symbol)
The number of frames per loop (Length) can be expressed by the following formula and the number is variable for each loop.
(Duration [seconds] × FPS) ÷ (Frame interpolation count + 1) + 1If the number of loop iterations is high, issues with color changes in the reference image may occur. In such cases, adjust the value of “🔧 Image Desaturate.”
Description
Speed improvement (10% to 20%) through the use of sage-attn and torch compile nodes
Continuity assurance (the last frame in each loop process is not used in the next loop)
FAQ
Comments (23)
Hello! Excellent workflow, thank you! What about sage attention and torch compile? Could you add them to speed up generation?
Hello! I tried connecting Sage Attention and Torch Compile, but it didn't seem to be very effective, so I removed it. However, it may speed things up in some cases, so please give it a try.
I tried connecting these. In my environment (RTX5060Ti), it became about 10% to 20% faster, so I will release it in Version 1.1.
Hello, In Version 1.1, have made a correction to remove the last frame from the generated video.
Hi, Do you remove the last frame from the generated video? Since it will be the starting frame of the next video, and you get two identical frames in a row, it makes the video merging a little worse.
Indeed, theoretically, the transition appears unnatural (approximately 1/30 sec?). We will improve this in the next version.
Usako_USA More, you use frame interpolation, in total you get 2 identical frames + 2 interpolated frames, total 4/30, this is what catches the eye. I also noticed that Image Desaturate works better with a factor of 0.05 on long videos, but this is probably individual.
Very nice wf from a technical standpoint. However, I'd recommend adapting the concept to flf2v. daisy-chained i2v always suffers from significant degradation in character consistency and general image quality after just a few iterations.
Thanks for the advice. Do you have any good ideas on how to decide on the last frame (end_image)?
Usako_USA I think the only realistic approach would be to plan out the scene beforehand and provide the pre-generated transition images along with the prompt iterations.
It's less freedom than your concept, of course, but I think it's the only viable way to create longer sequences without accumulated quality decay currently.
Your wf is perfectly fine for like 3 iterations, so if that's the goal, then feel free to dismiss my suggestion. Oh, while I'm at it, I think being able to set individual loras to specific iterations would also be helpful for controlling the action.
Personally when I play around with stitching together a scene, I generate a fixed background and then separately generate the character(s) in front of a simple background which I then "color-key" out in photoshop. Then I compose the transition images out of the various start, transition and end image(s) with the fixed background. It's quite a bit of extra effort, but I don't see another way, honestly.
xnapx "set individual loras to specific iterations would also be helpful for controlling the action"
It would be incredible, I did something like this for WAN2.1, I am not very experienced in optimization, so my workflow is quite primitive. There was such terrible spaghetti and I can't imagine how to do it for WAN2.2 because there are 2 samplers, all this spaghetti will be multiplied at least 2 times. Have you seen a workflow with a similar implementation for WAN2.1, can you share it?
mag225658920 From my testing so far on it w/ separate loras & separate prompts, it has been a lot about what sampler/scheduler you end up using. Then if you go too hard on the helper lora like the light/causvid/fusionx, it can bring negative results. in my own workflow, my best experience (so far) has been with euler + beta57, +.3 strength on light lora on low noise, 1 strength on causvid low noise. I still need to try out OP's workflow. It has some cool things I didn't think of incorporating in my own! Didn't even realize you could split a prompt like that.
If you want real long chains, the higher def vods you'll want. Like let's say you start with a 480x480 image, then that first iteration will ref your high quality image, subsequent iterations will reference that 480x480 low quality end image. If you have a real high def image, you'll have better references esp for things like eyes. That said, it will take a LOT longer to generate. It also matters a lot on your starting prompt and what you're trying. If you have a person let's say from stomach to face, the eyes/face will be more clear in frame, so the details will preserve for future iterations.
Something I want to experiment with sometime to see if it's even possible is to take an image last frame, apply a super heavy control net on it in a t2i workflow, and then use that as reference to the next iteration. So like Last frame -> t2i + control net -> next iterations refs image. Could probably smooth out some differences with FLF too. But I need to experiment with this to see if it's even possible. Would probably get complicated fast.
gumpbubba721291 [Something I want to experiment with...]
From my experience, FLF really struggles with changing backgrounds, even with small differences. It will often generate some kind of transition effect or unnaturally rotate or pan the background instead of focusing on the character. I have not been able to achieve background consistency with either controlnet or ipadapter and I think it might be a lost cause because a model's similarity standards, i.e. what it "sees", are of course much higher than our eyes'. For a "static" scene, meaning some character does action A then B then C in the same environment, I thin there's always some manual composition necessary, if one want's a seamless result.
mag225658920 both gumpbubba's and this (https://civitai.com/models/1845620/wan22-i2v14bgguf-kijai-wf-with-for-loop-lightxv2) wf implement per-iteration loras well, both for 2.2.
xnapx I was messing around with some control net + upscale at the end right before the next iteration. I was hoping to see if I could get something to restore some details. It worked... somewhat, kind of. The problem is, it doesn't work well enough to where it's a seamless transition, so there is going to be some loss (like maybe hair color very slightly changes, or a shadow slightly changes), and when you try to downscale the image back from the upscaled size, it will often shift things slightly. At that point, it kind of begs the question why not to take the quality loss that would happen normally. Yeah... it may be a lost cause for now until technology improves.
gumpbubba721291 Yes, I noticed these deformations, here you either need to have the character's face very close, or increase the original resolution, which affects the generation speed. Another problem is if the character turns his head or covers it with something on the last frame.
This workflow is great for selfie videos or videos that don't have much action, but if you're making staged videos, then a lot of problems apears.
xnapx Thanks for suggesting another interesting workflow. I didn't manage to use loops in my WF, thanks to this WF I hope I will figure out how to do this.
I try the v1.1...I think the v1.0 is better.
Can anyone tell me why there might be a long delay between iterations? It's as if WF reloads all models after generating the first video. Although I disabled purge_cache and purge_model in the layerutility nodes.
I'm sorry for making this myself.
I want to remove the background from the reference image (Remove REMBG, etc.), but it doesn't work with WanVideo's processing system and causes an error (it says that the expected input and dimensions are different). Is there a good way to do this?
The goal is to change the reference image background to the one specified in the prompt (#1, Always).
hmmm. I mean... be greedy - its monopoly money. I don't know enough but it seems like I read somewhere that there is a different engine - maybe "Hunyuan" that just released a model that does this. if I find it I'll post it in this thread. thanks for shooting for the moon. Nice work - keep it up and we'll be making an AI song with video in one step lol!
That work is incredible. Really perfect.
Can you add multitalk to it ? i know is a challenge, i am myself a workflow dev and i didn't found a way to add it. tricky. there is another thing there is some empty value in the workflow can you increase this to make more longer video with a single image input ?cause afer a certain number of seconds it lost the initial image. but with that will be the most perfect workflow ever made !!!
Why does the characters in merged video sometimes speed up or slow down at the joints? How can I make all the loops go at the same speed? This workflow is really good, a godsend, but I still don't understand how to remove these speedups/slowdowns. Maybe some kind of global synchronization is needed here or it already exists, but I don’t see it, unfortunately I’m not an expert in such things :(
Maybe this is an aspect of the cropping of end frames of the previous segment to avoid using marred images as the start frame. idk I haven't even used it yet I like to "read the manual" before diving in. just my two sense: if the crop shortens the frames in the stitched section then there would be a slowdown to match the overall fps. i.e. 30fps overall but the first sewcond of a loop is cropped to 25 frames so that would be "stretched" to match the overall 30 fps... like I wrote idk just a guess. Maybe try adding a similar number of extra frames to each loop that matches the amount cut during the stitching process. maybe.
I've been looking for this exact thingy so thanks in advance - ill keep reading know and then post in the gallery when I've ripped something. followed.