

Create images of a character in other positions for LoRa training
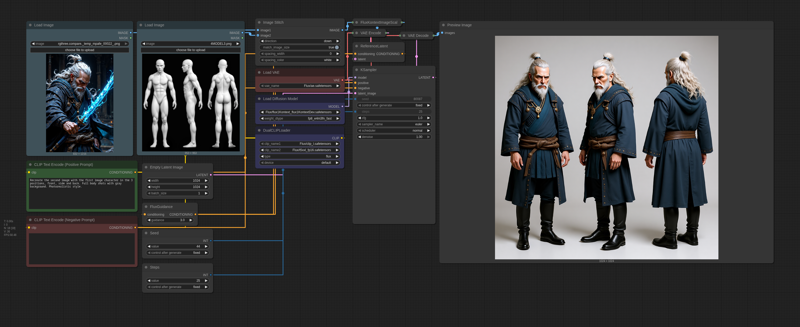
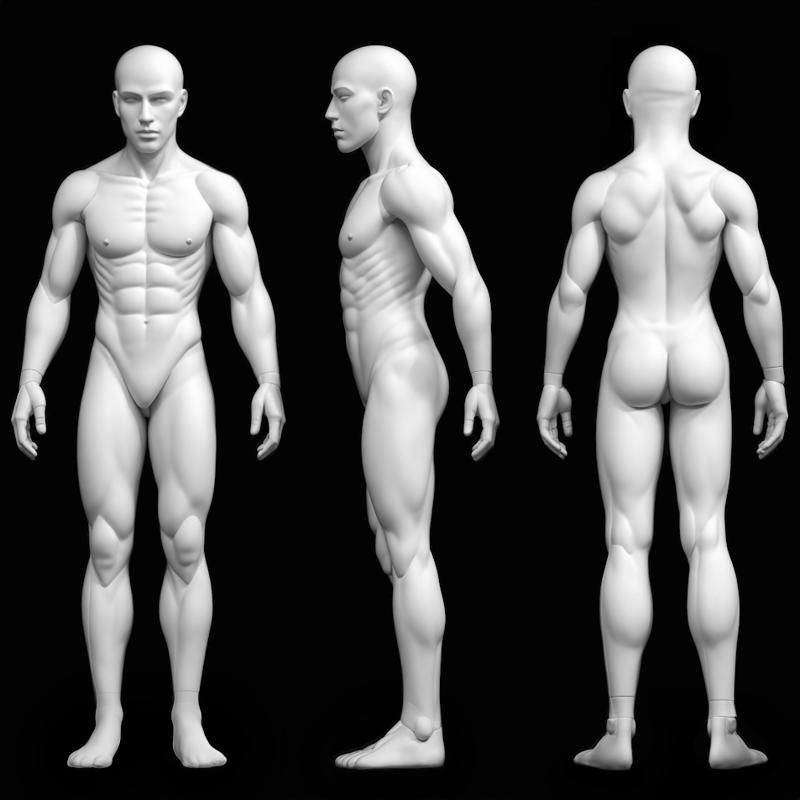


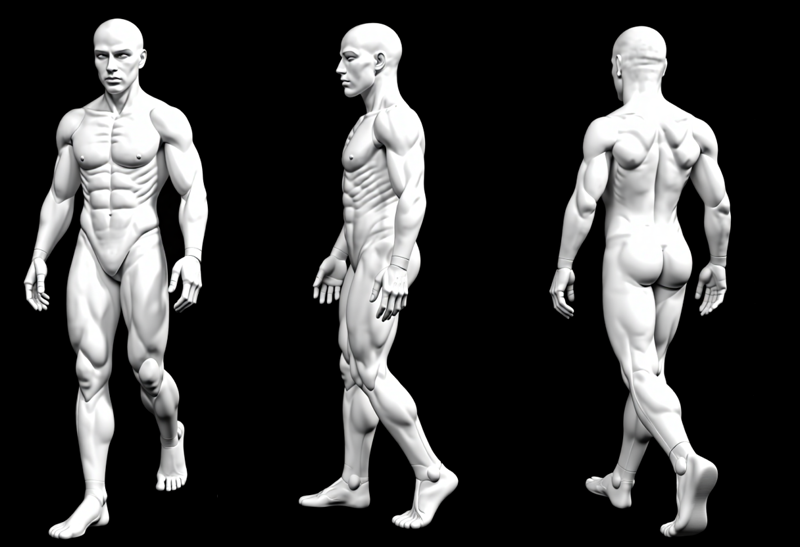




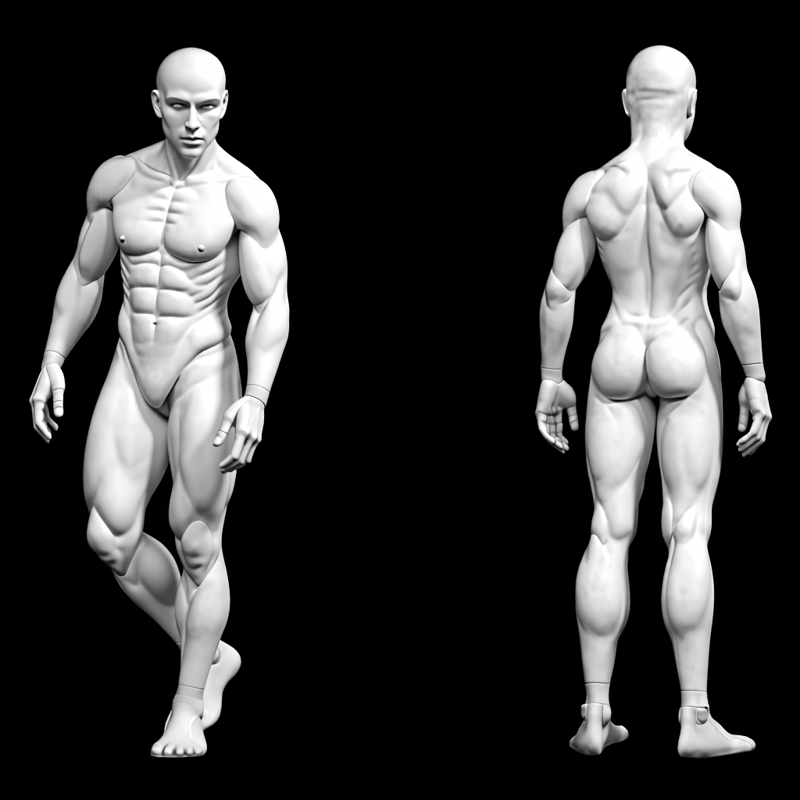 Some examples of prompts that I used to test.
Some examples of prompts that I used to test.
Recreate the character from the first image in three anatomical views: front, side (profile), and back, matching the exact pose and perspective of the reference model on the second image. Maintain full consistency in the character's identity, including facial features, hair, clothes and accessories. Preserve the style, lighting, rich textures, and realistic anatomical proportions. Ensure that each new pose captures the same costume flow and detail placement from the original character design.
Reposition the fantasy warrior character into a new distinct dynamic pose while preserving all original details, including his face, hair, clothes and accessories.
Maintain the original style, lighting, and rich texture quality throughout all poses. Character anatomy, costume elements, and personality must remain consistent.
Walking Calmly:
Show the character walking forward at a relaxed pace, with a neutral or thoughtful expression. His hands can rest naturally at his sides casually. Clothes and hair flow subtly with the motion.
Standing with Arms Crossed:
Depict the character standing in place with his arms crossed over his chest, conveying patience or contemplation. Keep the body relaxed but firm, expressing wisdom or calm authority.
Looking Over Shoulder:
Show the character in a slight twist, glancing back over one shoulder as if reacting to a sound or presence behind him. This should be a subtle motion—no combat stance—just curiosity or awareness. Maintain natural posture and relaxed expression.
Sitting Pose:
Depict the character sitting on a stone throne or ancient bench, maintaining a powerful and composed expression. Clothes should flow naturally around the seated form.
Jumping Pose:
Show the character mid-air in an action-oriented leap, clothes and hair flowing dynamically to convey motion, and a focused, intense expression.
Running Pose:
Display the character in full stride, running with determination. The clothes trailing behind, and the body leaning slightly forward for momentum. Ensure proper motion blur or implied movement for realism.
Pointing:
Show the character with one hand extended forward, pointing to the camera.
Kneeling:
Depict the character in a solemn kneeling position and both hands resting on his lap. His expression should be calm or contemplative, suggesting honor, memory, or ritual. Maintain detailed costume flow and realistic weight distribution.
Defensive Stance:
Show the character in a guarded, battle-ready pose, feet planted wide, and body turned slightly sideways. His expression should be alert and prepared, with clothes and hair positioned naturally to reflect a tense, ready posture.




Description
Create images of a character in other positions for datasets.
FAQ
Comments (21)
Works great!!
Thank you @rvn10 I'm glad you liked
😎🙌🏻🔥
Edit: The below comment was from testing with standing full body or near full body references. On a character that's seated or in a dynamic pose, it produces weirder results with prompt alone than the mannequin stitch. So it does seem to help.
I feel like stitching the mannequin image doesn't really improve prompt adherence any better than just using a single reference image and describing the character poses in the prompt. The rate of facing the right way vs the wrong way feels about the same.
how to copy or imitates one complicated pose like openpose, tried many times but failed
What's the point of this? You could do this with basic control nets for years, and with 10x the performance..
It's another tool with its own pros and cons. The 'not my method' comments are foolish. AI advances when more pathways are explored. We are literally in the infancy of this tech, from a software, hardware and model POV. Or perhaps you think no-one needs more than 64KB of RAM, or no-one will ever need a computer that sits on their desk (both actual comments from highly placed so-called industry 'experts' back in the day!)?
If nothing else, it can be another set of images made by a different model if you're trying to train a custom lora.
in this workflow we don't use lora just 1 input lol and results awesome
Ease of use? No need for learning how to use control net?
We could do this with pencils for years, at 1/100 the cost😅.
All we truly need is IP-Adapter FACE ID for flux. More people need to be pushing this guy over here to make it: https://huggingface.co/h94/IP-Adapter-FaceID
this is better quality.
Doesn't work for me.
Error message:
KSampler
Sizes of tensors must match except in dimension 1. Expected size 128 but got size 64 for tensor number 1 in the list.
usually thats when you have either wrong sized images where they need to be the same size, where youre using the wrong models together (i.e. flux model but sdxl vae), or something similar. make sure all your models are the correct ones intended to work together. the text encoders, the model, the vae, the images.
@PookieNumnums I just tried again with version 2 and it worked. Maybe I made a mistake there. Thanks, PookieNumnums!
Great job. I think I need more "4MODEL3.png" models, kids, adults, women, anime characters, and even one-armed models, and I believe Kontext can do that. Or tell me where to pick it up.
Added some more pictures on the description and on the zip file, some prompts and examples also.
@alcaitiff Unbelievable!Thank you so much for your work.
@GMSSSCCC I'm glad you liked
Check out PoseMyArt for a good way of creating more model reference cards. I did a few for a chibi character and it worked out great.
@Shikamari great! I find the way ! https://posemy.art/