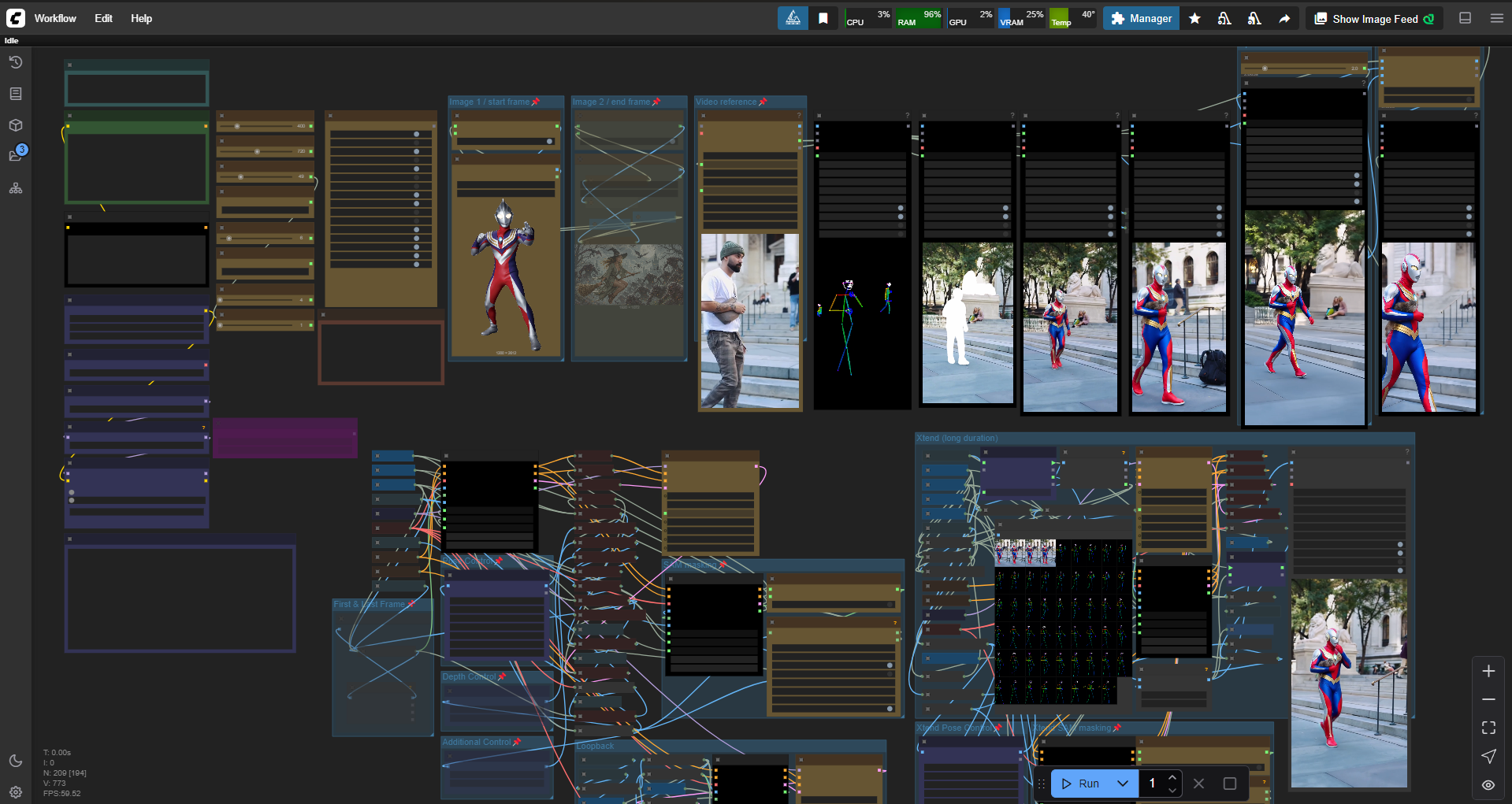
Comfyui workflow for text to video, image to video, video to video, video stylize, video character replacement, clothes swapper, long video generation, low VRAM, 6 steps, all in one simple ULTIMATE workflow.
=====================
v2 Coming soon
add prompt progression/scheduler
add xtend existing video
add 2 image reference
=====================
v1.20250724 Ultimate
add xtend long video generator (with controlnet+masking available)
add loopback feature
better upscale and uprte method
higher resolution for the same VRAM
Framepack killer
=====================
READ ME‼️‼️
Adjust only parameters in YELLOW nodes
prompt the GREEN node in detail
read the MUTER SWITCH GUIDE and MODEL GUIDE
check additional switchs/adjustment in YELLOW nodes
leave the BLACK nodes intact
bypass SAGE ATTENTION node if you don't have it installed
====================
MODEL GUIDE
Use VACE model + CauseVid and/or Self-Forcing lora
14B for quality
1.3B for faster inference
Change GGUF Loader node to Load Diffusion Model node for .safetensor files
===========================================================
14B VACE model GGUF + CauseVid lora (6 steps only)
https://huggingface.co/QuantStack/Wan2.1_14B_VACE-GGUF/tree/main
or
14B FusionX VACE GGUF (CauseVid merged)
https://huggingface.co/QuantStack/Wan2.1_T2V_14B_FusionX_VACE-GGUF
===========================================================
1.3B VACE Self-Forcing model used (6 steps only, no CauseVid needed)
https://huggingface.co/lym00/Wan2.1_T2V_1.3B_SelfForcing_VACE/tree/main
*1.3B VACE GGUF fails to give good result
===========================================================
Use https://openmodeldb.info/models/4x-ClearRealityV1 for upscaling
=====================
SWITCH GUIDE
Text to video = all OFF
Image reference to video = Image1 ON
Image to video = Image1 + FLF ON
First & Last Frame to video = Image1+2+FLF ON
FLF video control = Image1+2+VidRef+FLF+control ON
V2V style change = Image1+VidRef+controlnet ON
V2V subject change = Image1+VidRef+control+SAM ON
V2V background change = same as above+invert mask
Switch ON Xtends switches according your needs (monitor progress in the group)
Loopback ON to make looping video
Description
Add Xtend (long duration) and loopback feature.
Better upscaler and uprate method.
Generate higher resolution with the same VRAM.
Simpler settings with more features.
FAQ
Comments (23)
this is currently the best workflow for long video for me so far. awesome job.
Thanks, post some of your vids here please
The installation of ComfyUI-Crystools fails on windows because it can't install one of its Python dependencies (fcntl), I googled a bit and it seems this library is not available for Windows, is there any workaround?
I made this workflow on windows11. Maybe, use lower version of crystools? FYI, if I remember correctly, all nodes in this workflow are all from the custom nodes manager. But maybe crystools has it own method. I don't recall fcntl as one of the pip install.
i got a wan error. What happened? I touched nothing other then putting in video and image. Are these not connected properly? But i am not using Txt Vace i use Just normal Vace or fusionx vace. Does Txt Vace mess with anime videos?
Try with the model on the guide 1st. You might use only the VACE lora hence the error.
Or maybe try the 1.3b vace in the model guide. If it's OK the the 14B should be OK. Remember, use vace model, or t2v wan+vace lora
kukalikuk shouldnt i be using Img wan vace?
In the notes for Model Guide (both here and in flow), the link under "1.3B VACE Self-Forcing model used (6 steps only, no CauseVid needed)" goes to a Page Not Found. Though looks as though it's not really recommended to use anyway?
Thanks for the info, lym00 changed his project folder to
https://huggingface.co/lym00/Wan2.1_T2V_1.3B_SelfForcing_VACE/tree/main
1.3b still good for some use case such as generating simple talking head. It also gives good t2v result for prompts it understand.
这个工作流特别棒,但是我在运行完一次文生视频后,Enable SAM masking就自动打开,并且关不掉,然后再次生视频时候会出错,这个怎么解决?
出错信息:# ComfyUI Error Report ## Error Details - Node ID: 58 - Node Type: LayerMask: LoadSegmentAnythingModels - Exception Type: RuntimeError - Exception Message: PytorchStreamReader failed reading zip archive: failed finding central directory
xhxlt0820 try download related sam model and put it in model/sams folder. But if it related to pytorch problem then maybe this workflow is not for you, sorry, can't troubleshoot it all
Hello I got everything working, but I wonder if there is an option to keep model loaded? I found few nodes where I unchecked "purge model" option, but still every generation gives:
Requested to load WanTEModel
loaded completely 7071.406279373169 6419.477203369141 True
Requested to load WAN21_Vace
loaded partially 3749.8792356872555 3749.876953125 0
which takes quite some time...
Remove the purge VRAM node. It offload at every end process and onload in every sampler. I use it because I made this with 12gb VRAM. If you use ssd for with 33gb++ swap file this will only takes a few secs rather than having a OOM.
kukalikuk It's not enough to just click the off button in the node? How would I go about using SSD instead for swap?
had to come back here to drop a compliment, this is my most used workflow so far, at first it looks very cumbersome but you did a good job describing what to do for each flow and it just works great ! I cant imagine how much time youve put into it, so thanks for sharing !
Thanks, please show some of your work here. I might upload the update with xtend prompts progression, just need some motivation. LOL
And check my wan2.2 workflow. It has better t2v and i2v results.
@kukalikuk sure thing, I want to start uploading some stuff soon, will credit your workflow when I upload. already started playing around with the 2.2 workflow, also looks great, good job on keeping a similar interface
Hi,
I got an issue here... your latest workflow, i can only use it with a video reference... in the muter if i want to make T2V and disable all of them, i got errors failed samples for output nodes...
it will give error message coz no controlnet output, but stil making the the video for T2V. I haven't try it again with the newest update, but I think it won't be a problem.
@kukalikuk Well i found the problem. The KSampler is going above the SAM Masking when you already did one (because of the preview frames since i enable it by default).
Since it's going above SAM Masking, when you disable it, the KSampler is disabled too. I just dragged it somewhere else and there was no issues afterwards.
Thank you anyways.