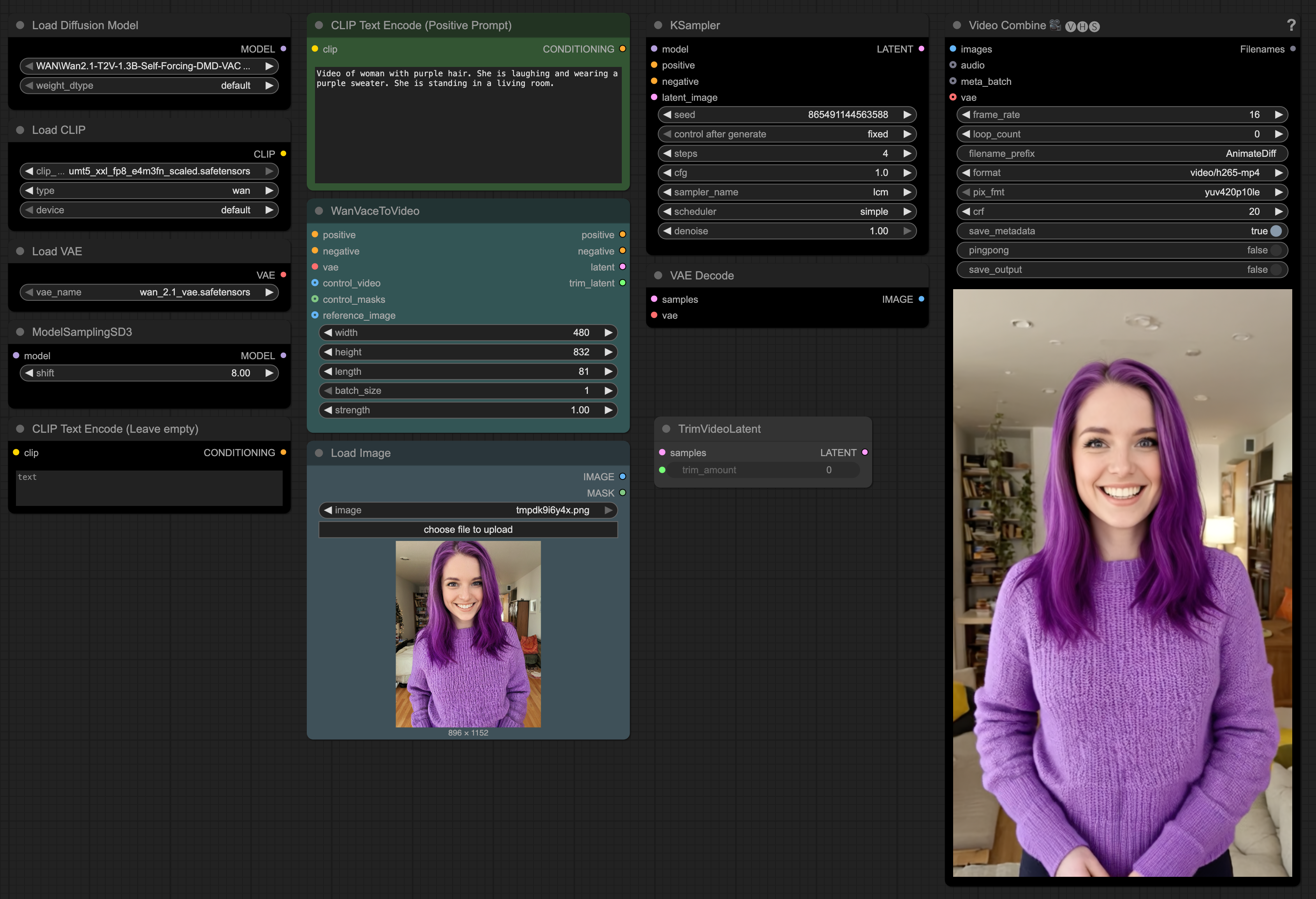
Simple WAN T2V Workflow for Self Forcing
Self Forcing trains autoregressive video diffusion models by simulating the inference process during training, performing autoregressive rollout with KV caching. It resolves the train-test distribution mismatch and enables real-time, streaming video generation on a single RTX 4090 while matching the quality of state-of-the-art diffusion models.
Update (i2v):
To use Vace, you will need to use a different checkpoint: https://huggingface.co/lym00/Wan2.1-T2V-1.3B-Self-Forcing-VACE/blob/main/Wan2.1-T2V-1.3B-Self-Forcing-DMD-VACE-FP16.safetensors
Download self_forcing_dmd.pt from https://huggingface.co/gdhe17/Self-Forcing/tree/main/checkpoints and use it as the t2v checkpoint.
Project website: https://self-forcing.github.io/
Description
Added ability to create videos with images using Vace
FAQ
Comments (20)
nice, runs in 120 sec (170 sec for i2v) on my 8gb business laptop with a 4070 mobile chip. using only 80% vram and 56% of the 32GB RAM
Tested this out. Likeness is very consistent, but prompt adherence and loras are quite bad. Loras seem to be just ignored/not applied or create messes.
1.3b loras seem to work fine for me with i2v
@powerpuff Indeed, many people will be using the much more common large model loras, not understanding their mistake. And 'bad' prompt adherence, or poor performance with certain types of image, goes with the territory. These accelerant methods are not a panacea for general video generation, and cannot be. Instead they are very specific tools, and users need to experiment to discover when they work usefully.
most of your loras are likely 14b tuned
A complete miracle for a certain type of use case- and a fantastic example of the evolution of highly specific workflow tools. Like any tool, it is great when used to its purpose, but will obviously disappoint people who are silly enough to think video generation is ever one-size-fits-all.
I'm looking forward to trying this, but I'm getting an error with i2v if I load the checkpoint you linked in the description (Wan2.1-T2V-1.3B-Self-Forcing-DMD-VACE-FP16.safetensors). From the KSampler node:
"AttributeError: 'float' object has no attribute 'to'"
If I load another checkpoint it runs but gives a garbage output, so it has something to do with that checkpoint. Any remedies you know of? Thanks!
I'm not sure why you are getting an error, that's the exact checkpoint I am using. Have you updated Comfy?
Excellent workflow! This is a complete gamechanger on my M1 mac - it makes i2v feasible. Thank you so much!!
Nice works, very fast.
2 q's
How long can one make the videos and what does it mean with when you are using it with i2v and it is not doing a pure i2v but making a video of something VERY similar, almost the same but different, is it an issue with the original pictures size or something? I tried with one picture and it pretty much did what I asked for but the second one it kinda did an 'inspired' version from the image and my prompt?
Thanks
same issue here
I'm not 100% sure but I noticed this with the Phantom 14b model as well until I resized the input images to the same size my final output would be. Never hurts to try.
@funscripter627 Yeah that's what I was thinking. I'm not that familiar with knowledgable with comfyi but from other workflows I've used and seen image resize nodes, is it just a case of adding a resize node between the image and the vace nodes?
@beepbopbip You can look at the workflow below from Kijai for an example. Basically you add a image resize node with a ImagePad node. You attach a width and height input node to the image resize node and to the ImagePad node and it should automatically resize them and pad any leftover space with a white background.
This way they keep the same size and aspect ratio. You should be able to just copy the nodes and paste them in your own workflow. You could also just resize the images manually in an image editor of course.
Adding just a resize node can also work, but if your images have a different aspect ratio than your final output, they could get stretched or badly cropped.
https://github.com/kijai/ComfyUI-WanVideoWrapper/blob/main/example_workflows/wanvideo_phantom_subject2vid_example_01.json
Nice !! It's quick and works without any issues, I have a request, can you please make a self forcing vace controlnet workflow with lora support ? (something like VACE CONTROLNET simple workflow) Thanks !
This is absolutely Fantastic!! I'm using the T2V workflow but am eager the try the I2V :) This is Brilliant and the future for sure.
Great model, great workflow! I used it for a YT clip, Dragons worked well: https://youtu.be/ZHCccxvu2Ts
1024x576@81frames 4 steps takes 3-4min with sage and causevid with my 3060 :)
Can anyone help with the KSampler values, like the sampler names, schedular and CFG, Gereat workflow, waiting for the 1.4b